1、HBase定义
HBase(Hadoop Database)是一个分布式、可扩展的NoSQL数据库。基于Big Table,为Hadoop框架当中的结构化数据提供存储服务,是面向列的分布式数据库。这一点与HDFS是不一样的,HDFS是分布式文件系统,管理的是存放在多个硬盘上的数据文件,不支持随机修改,而Hbase管理的是类似于key—value映射的表。
2、HBase数据模型
Name space:关系型数据库中表放在database中,而Hbase的表放在命名空间中,自带的命名空间分别是hbase(存放hbase内置的表)和default(用户默认使用的命名空间)
Region:按行切分,叫作表的切片。最初创建的一张表就可以视为一个Region,只需要定义列族CF
Row:每行数据由一个RowKey和多个或一个Column组成
Column:每个列由CF列族和CQ(Column Qualifier)列限定符(就是列名)确定
Time Stamp:标识数据的不同版本
Cell:region --> row key --> CF --> CQ --> time stamp,就可以确定具体的数据,又称为cell(单元格),存储的时候都以字节码存储,不区分类型
一个列族下的列可以随意添加,不受限制。HBase的Key由RowKey(行键)+ColumnFamily(列族)+Column Qualifier(列修饰符)+TimeStamp(时间戳–版本)+KeyType(类型)组成,而Value就是实际上的值。
3、HBase基本架构
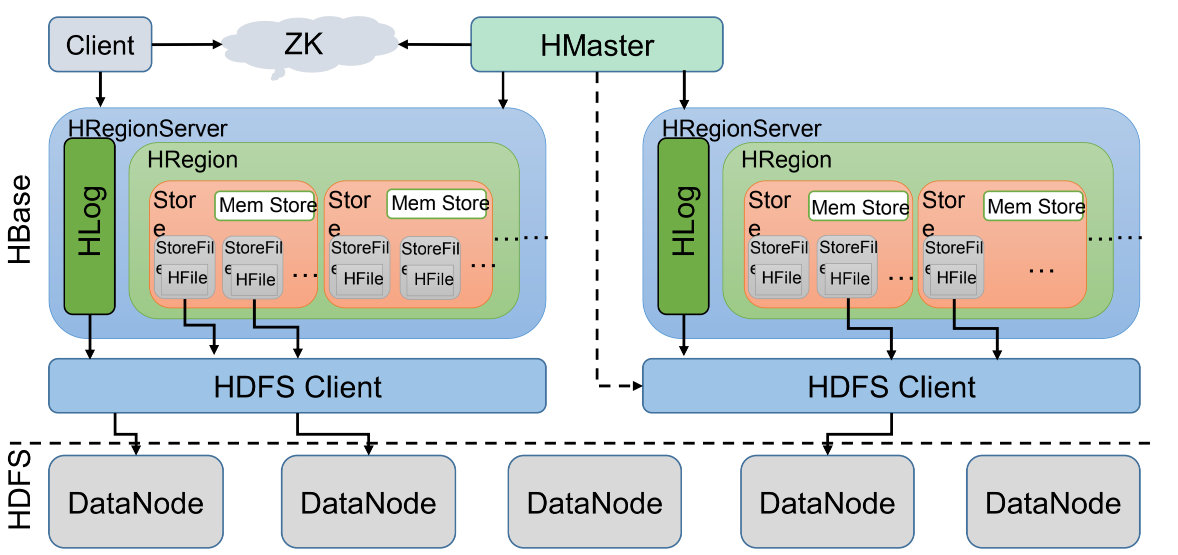
ZooKeeper:存储了HBase的元数据(meta表),处理请求需要取ZK中的元数据表才能知道到哪个服务器处理(根据Region id等信息组成的rowKey,在meta表中确定RegionServer)
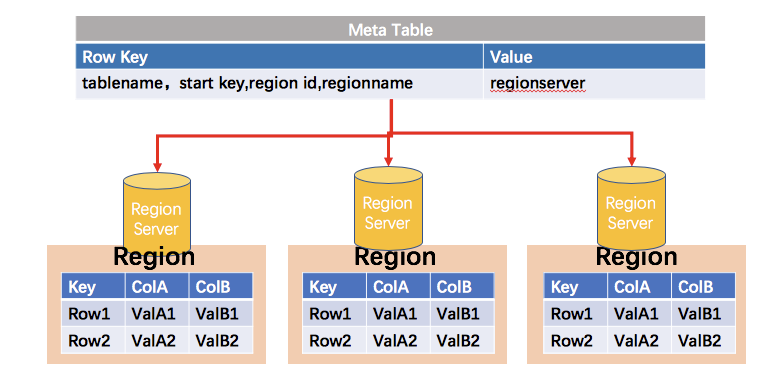
meta 表的地址信息保存在 zk 的 /hbase 路径下的 meta-region-server 节点上:

参考:https://lihuimintu.github.io/2019/06/30/HBase-Meta/
HMaster:管理表级服务,如创建、删除、修改表。分配region到各个RegionServer,监控各个RS状态,可以控制RegionServer的故障转移和Region的切分
HRegionServer:数据节点,用来存储数据,管理对数据的操作。负责与HDFS的交互
一张HBase表会根据RowKey进行横向切分,切分到不同的HRegion中。所以一个HRegion可以看作一个表的一部分。而Store是存储一个列族的数据。
HBase性能测试
1、YCSB安装
YCSB全称为:Yahoo! Cloud Serving Benchmark,是一个常用于测试比较NoSQL数据库管理系统性能的开源程序。
Github地址:https://github.com/brianfrankcooper/YCSB
本实验测试的是HBase的系统性能,所以选择下载ycsb-hbase12-binding-0.17.0.tar.gz,并解压即可。
2.YCSB测试
创建表:
根据官方文档,在测试之前要先在HBase中创建表,并设置Pre-splitting策略(HBase默认只分配一个region给table,也就是说相关读写请求都只会让一个regionServer承担,会导致测试结果很差,无法体现真正性能)。本实验预分区的个数为30(10*regionServer)个
创建表:create 'usertable','family',{SPLITS => (1..16).map {|i| "user#{1000+i*(9999-1000)/16}"}}
加载workload:
该阶段负责生成测试数据。
bin/ycsb load hbase12 -P workloads/workloada -cp /opt/module/hbase-1.4.13/conf/ -p table=usertable -p columnfamily=family
运行workload:
该阶段进行实际的读写测试,生成测试报告。
bin/ycsb run hbase12 -P workloads/workloada -cp /opt/module/hbase-1.4.13/conf/ -p table=usertable -p columnfamily=family
本次workload采用的是workloada,在 ycsb/workloads/ 下存储了workloada的信息,请求比例为50%读,50%写,1000条记录数,1000条操作数:
# Yahoo! Cloud System Benchmark
# Workload A: Update heavy workload
# Application example: Session store recording recent actions
#
# Read/update ratio: 50/50
# Default data size: 1 KB records (10 fields, 100 bytes each, plus key)
# Request distribution: zipfian
recordcount=1000
operationcount=1000
workload=site.ycsb.workloads.CoreWorkload
readallfields=true
readproportion=0.5
updateproportion=0.5
scanproportion=0
insertproportion=0
requestdistribution=zipfian
测试结果:
workloada (1000条记录数,1000条操作数,读写操作各占50%):
[OVERALL], RunTime(ms), 3962
[OVERALL], Throughput(ops/sec), 252.39777889954567
[TOTAL_GCS_PS_Scavenge], Count, 4
[TOTAL_GC_TIME_PS_Scavenge], Time(ms), 105
[TOTAL_GC_TIME_%_PS_Scavenge], Time(%), 2.65017667844523
[TOTAL_GCS_PS_MarkSweep], Count, 0
[TOTAL_GC_TIME_PS_MarkSweep], Time(ms), 0
[TOTAL_GC_TIME_%_PS_MarkSweep], Time(%), 0.0
[TOTAL_GCs], Count, 4
[TOTAL_GC_TIME], Time(ms), 105
[TOTAL_GC_TIME_%], Time(%), 2.65017667844523
[READ], Operations, 526
[READ], AverageLatency(us), 1838.4657794676807
[READ], MinLatency(us), 665
[READ], MaxLatency(us), 43775
[READ], 95thPercentileLatency(us), 2959
[READ], 99thPercentileLatency(us), 9839
[READ], Return=OK, 526
[CLEANUP], Operations, 2
[CLEANUP], AverageLatency(us), 51349.0
[CLEANUP], MinLatency(us), 10
[CLEANUP], MaxLatency(us), 102719
[CLEANUP], 95thPercentileLatency(us), 102719
[CLEANUP], 99thPercentileLatency(us), 102719
[UPDATE], Operations, 474
[UPDATE], AverageLatency(us), 4070.5696202531644
[UPDATE], MinLatency(us), 2712
[UPDATE], MaxLatency(us), 62527
[UPDATE], 95thPercentileLatency(us), 5555
[UPDATE], 99thPercentileLatency(us), 10295
[UPDATE], Return=OK, 474
由测试可知:当读写请求比例一定时,随着记录条数和请求条数的增加,读写延迟会大幅度降低,同时总吞吐量也会显著提升。