还不是被我妹妹给气的.jpg
要掌握的库
数据挖掘
request
BeautifulSoup
数据处理
Pandas
决策树,梯度提升问题
参考2020c109论文
决策树构建用包
xgboost 梯度提升
sklearn 回归聚类随机森林决策树等
spss因子分析降维
https://www.youtube.com/watch?v=TkKCA2daJdw

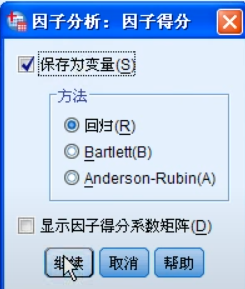
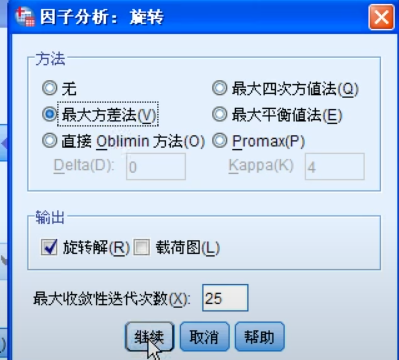
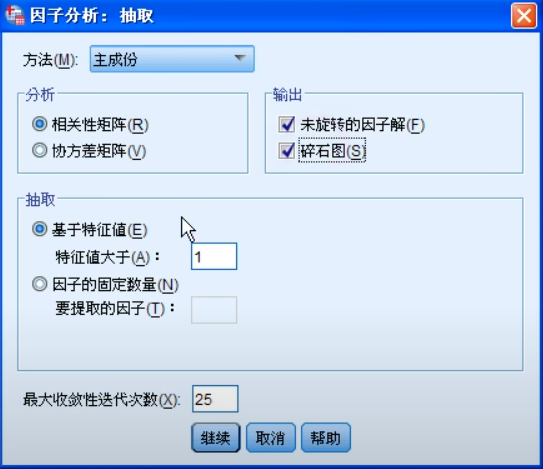
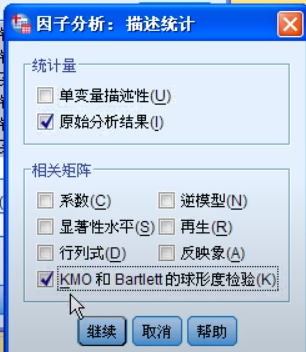
看旋转成分图估计每个成分含义
KMO大于0.5,相关性小于0.1或0.05
spss归一化
http://www.datasoldier.net/archives/505
分析方法
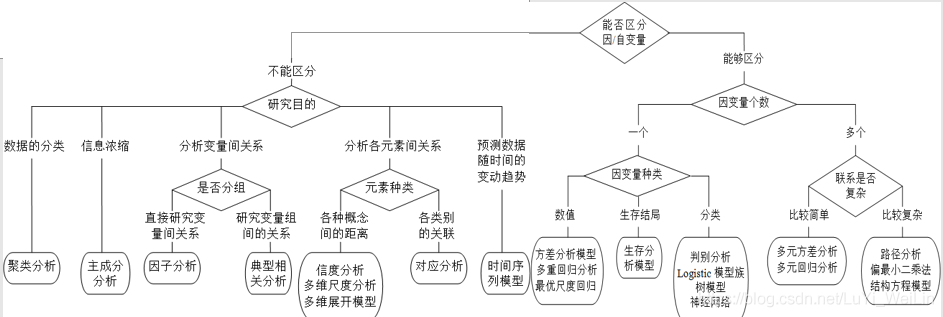
上图个人觉得仅供参考
主成分分析
https://blog.csdn.net/LuYi_WeiLin/article/details/90452437
主成分分析不需要考虑共线性问题,他就是来解决这个问题的
logistic回归
https://blog.csdn.net/LuYi_WeiLin/article/details/90322121
但是在现实情况中,发生率P为因变量,它与自变量之间通常不存在线性关系(一般是两边不敏感,中间敏感,比如收入与轿车拥有率),而且上面表达式不能保证在自变量的各种组合下,因变量的取值仍限制在01内,所以数学家们为了解决遇到的这两个问题,将想方设法想找到一种变量变换,能让上式的发生率限制在01内,而且两边不敏感,中间敏感,到最后找到了一种变换,将上式的因变量进行如下转换,就能解决我们遇到的问题

sklearn pipeline
其实就是把方法丢进管道里,然后依次进行
如:
from sklearn.ensemble import GradientBoostingRegressor
from sklearn.preprocessing import StandardScaler
from sklearn.pipeline import Pipeline
from sklearn.decomposition import PCA
regressor = GradientBoostingRegressor(n_estimators=300, random_state=0)
#先做去均值和方差归一化,再做降维,再做梯度提升
pipe = Pipeline([('scaler', StandardScaler()), ('reduce_dim', PCA()),
('regressor', regressor)])
pipe.fit(X_train, y_train)
ypipe = pipe.predict(X_test)
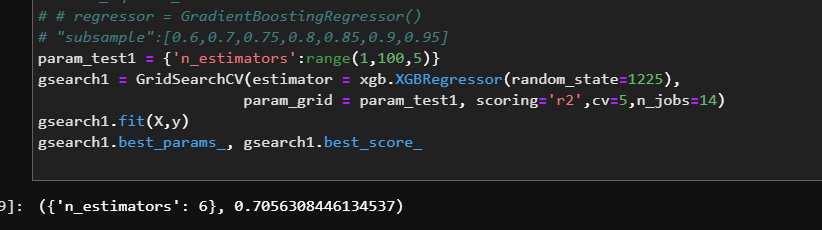
Grid Search:一种调参手段;穷举搜索
GridSearchCV
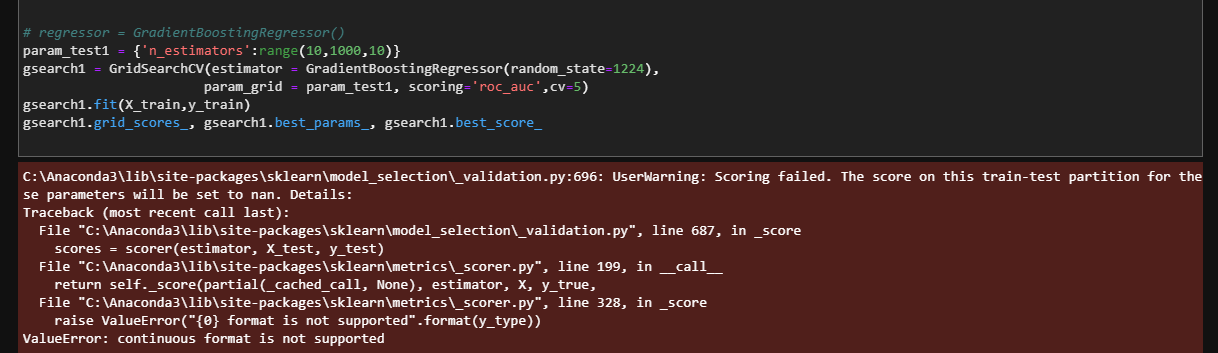
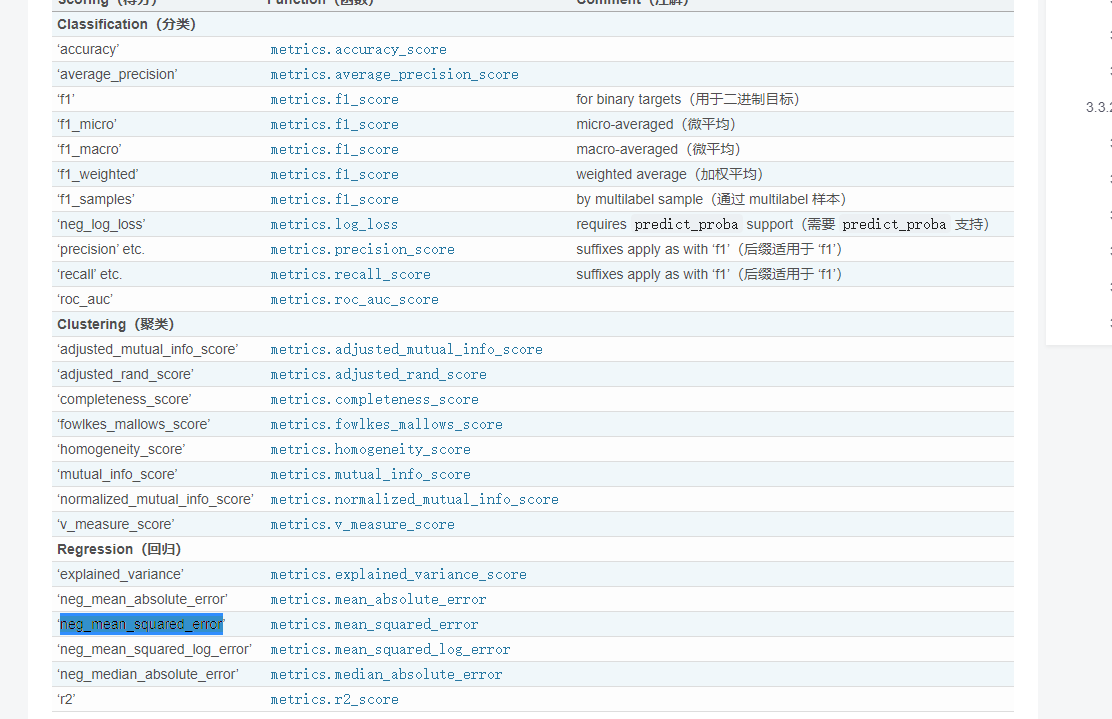
roc_auc是分类网络用的评估指标,用错指标了