在 Kettle(PDI)中使用 IDEA 或 VS Code 编写自定义 Java 代码协助转换
笔者最近正在学习数据仓库课程,其中某项作业要求笔者使用 Kettle 工具来对数据进行 ETL。Kettle 是一个很强大的工具,但是对一些比较复杂的数据转换和处理操作来说,相比于研究如何利用 Kettle 的工具来进行这些转换,笔者更愿意直接上手编写 Java 代码。恰好 Kettle 就是基于 Java 构建的,向其中加入 Java 脚本自然也易如反掌。
附:本文中所使用的 Kettle 其实是 Pentaho Data Integration(PDI),版本 9.4。虽然真名是 PDI,不过为了方便称呼和网络检索,下文还是称其为 Kettle。
加入处理 Java 脚本的步骤
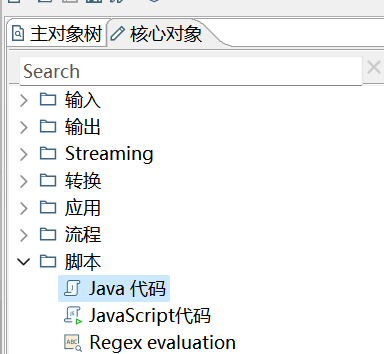
可以在这里找到 Java 代码步骤。
拖入窗口后,可以看到里面现在是空的:
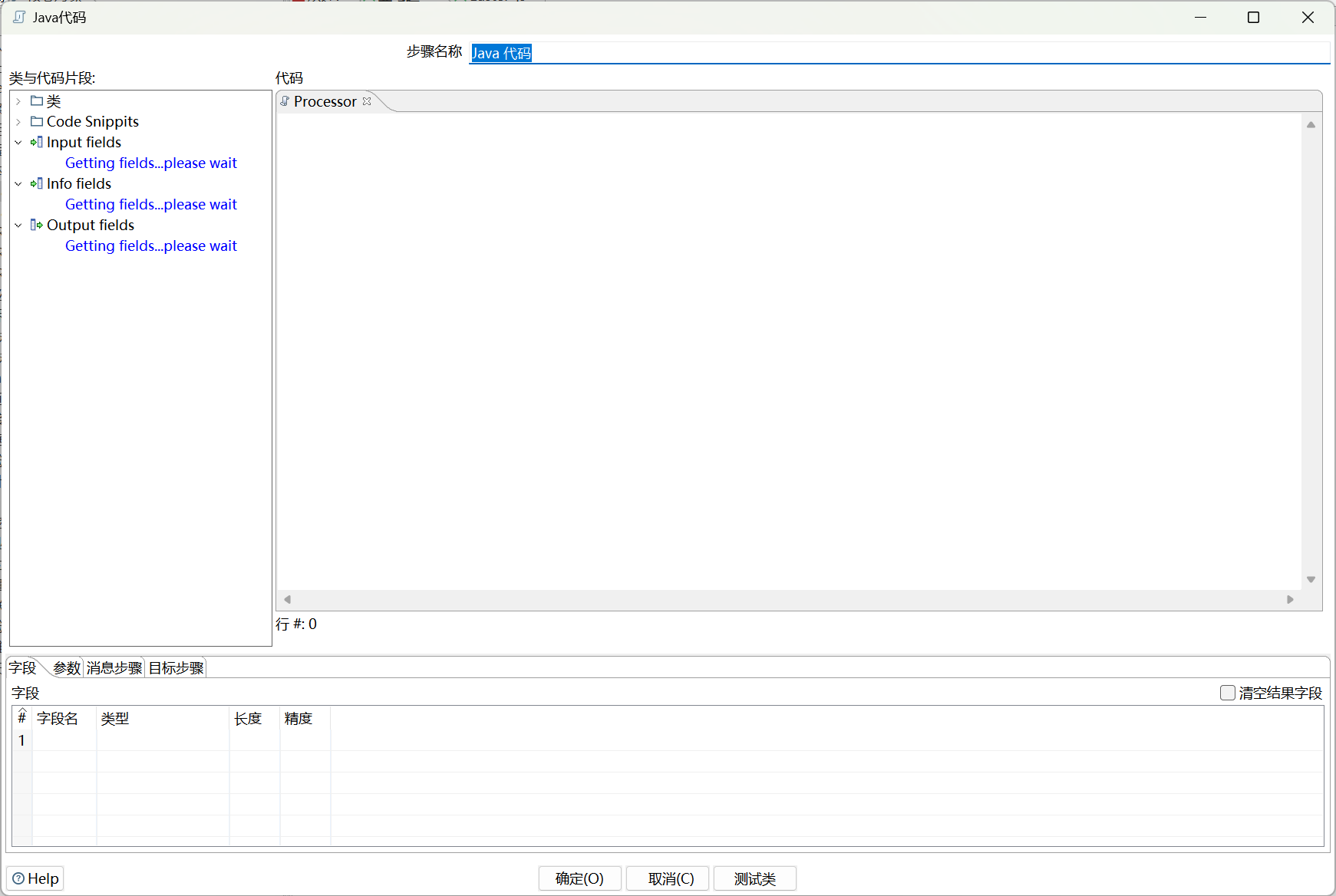
在左侧的“Code Snippits”里面,可以看到一些用于帮助我们快速开始的模板片段:
其实在 Kettle 的安装目录下,已经有一些自定义 Java 代码的官方示例了。大家也可以参考。
编写代码
关于在 Java 程序中读取、修改和插入条目中数据的方法,官方的“Calculate the date of Easter”示例里有非常详细的代码示例,接下来笔者也会提及。不过,这一节里主要讨论如何更加舒适地编写适用于 Kettle 的 Java 代码。
根据笔者的实验,有以下两种方法可以实现:
- 直接在 IDEA 等工具中用 Maven 或 Gradle 导入依赖
org.pentaho.di.pdi-libs,然后写代码。这种方法虽然可以成功导入 Kettle 对 Java 编程的官方说明里列举的包,但是编程体验不佳(Kettle 给你的编辑窗口里的代码其实是真正被编译的类的一部分),暂时不建议尝试。 - 用 IDEA 等工具编写业务代码,然后打包成 Jar 或直接粘贴进 Kettle。笔者是使用这种方法完成任务的,因此接下来会针对这种方法进行说明。
笔者出于个人喜好,使用 VS Code 完成了代码编写的工作。读者也可以使用 IDEA,只要进行相同的操作即可。笔者假定读者已经了解 Java 开发的流程,若读者不熟悉 Java 开发,建议使用 IDEA 来作为开发工具。
首先,创建项目。然后,创建一个类,编写用于处理数据的函数。为了方便读者快速确认这些函数应该如何设计和放置,笔者把自己的代码展示如下(不需要可直接跳过):
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
import org.apache.commons.lang3.StringUtils;
public class GoodsMovieProcesser {
public static String englishNameAbbrParse(String name) {
name = name.replaceFirst("(Jr\\.|jr\\.)", "Junior");
name = name.replaceFirst("(Sr\\.|sr\\.)", "Senior");
return name;
}
public static void parseMainCreator(String source, List<String> director, List<String> producer,
List<String> actor) {
String[] splited = source.split("\\),");
if (splited[splited.length - 1].length() > 0) {
splited[splited.length - 1] = splited[splited.length - 1].substring(0,
splited[splited.length - 1].length() - 1);
}
for (int i = 0; i < splited.length; i++) {
var p = splited[i].lastIndexOf('(');
if (p < 0)
continue;
var title = splited[i].substring(p + 1, splited[i].length());
var name = splited[i].substring(0, p);
// 对name进行处理
var nameArray = Arrays.stream(name.split(","))
.map(GoodsMovieProcesser::englishNameAbbrParse)
.map(s -> {
var a = StringUtils.splitByCharacterTypeCamelCase(s);
return String.join(" ", a);
}).toList();
// 对title进行处理
String[] titleArray = title.split(",");
for (var t : titleArray) {
switch (t) {
case "Actor":
actor.addAll(nameArray);
break;
case "Director":
director.addAll(nameArray);
break;
case "Producer":
producer.addAll(nameArray);
break;
}
}
}
}
public static void main(String[] args) {
// 测试
var testList = new String[] {
"BurtReynolds(Actor),KrisKristofferson(Actor),MichaelRitchie(Director)",
};
for (var test : testList) {
List<String> director = new ArrayList<>();
List<String> producer = new ArrayList<>();
List<String> actor = new ArrayList<>();
parseMainCreator(test, director, producer, actor);
System.out.println("Test case - " + test);
System.out.println("Director - " + director.toString());
System.out.println("Producer - " + producer.toString());
System.out.println("Actor - " + actor.toString());
System.out.println();
}
}
}
接下来,读者可以选择将用于处理数据的静态类(在上面的示例代码中,是parseMainCreator和englishNameAbbrParse)直接复制到 Kettle 中。不过,比较现实的因素是,哪怕在笔者撰文时使用的最新版 Kettle,其内置的静态语法检查工具也不支持很多已经在 Java 8 中支持的特性。这就会导致读者使用 Java 8 甚至 17 编写的代码,不能通过 Kettle 的语法检查,尽管它们是可以正常运行的——如果读者的 Java 环境也是 8 或者 17 的话。读者可以在读完本文后试试自己是否会遇到这样的问题。
为了回避这样的问题,我们可以考虑将代码打包成 Jar,导入 Kettle。(当然,如果你的代码不会遇到上一段中说的问题的话,可以跳过这一步)
打包 Java 项目成 Jar 的方法有很多,笔者在此说明一种比较方便的方法。读者如果熟悉操作的话,可以直接跳过。首先,打开 VS Code,选中“Java Projects”:
选择“导出到 Jar 文件”:
选择“不需要主类”

勾选上所有用到的外部库。
然后就可以获得产物了:

接下来的一步很重要:把它复制进 Kettle 目录下的 lib 目录内,这样 Kettle 才能在运行时使用它。
编写 Kettle 代码,调用处理函数
接下来该在 Kettle 内完成剩下的步骤了:从条目里读数据、调用处理函数处理数据、将数据放入输出中。
先看看最终的代码:
// 导入常用的类
import java.util.*;
// 导入我们刚刚写好的业务逻辑类
import GoodsMovieProcesser;
// 定义在函数外的变量,用于记录需要读取的字段所位于的列号
int mcIndex = 0;
public boolean processRow(StepMetaInterface smi, StepDataInterface sdi) throws KettleException {
// 获取这一条目的数据
Object[] r = getRow();
// 如果获取的数据是null,说明转换完成了
if (r == null) {
setOutputDone();
return false;
}
// first是一个隐藏的类内变量,标记这个函数是否为第一次被调用。可以利用它做一些初始化工作
if (first) {
first = false;
// 获取字段“main_creator”所在的序号
mcIndex = getInputRowMeta().indexOfValue(getParameter("main_creator"));
if (mcIndex<0) {
throw new KettleException("main_creator field not found in the input row, check parameter 'main_creator'!");
}
}
// 为条目数据“扩容”,保证我们稍后添加的数据不会溢出数组的范围。
// OutputRowMeta的内容是根据我们在Kettle中填写的输出字段来确定的。
Object[] outputRowData = RowDataUtil.resizeArray(r, data.outputRowMeta.size());
// 获取输入条目的字段数量,用于之后添加新字段到尾部。
int outputIndex = getInputRowMeta().size();
// 获取所需要的字段的具体数据
String creators = getInputRowMeta().getString(r, mcIndex);
// 执行处理逻辑
List<String> director = new ArrayList<String>();
List<String> producer = new ArrayList<String>();
List<String> actor = new ArrayList<String>();
GoodsMovieProcesser.parseMainCreator(creators, director, producer, actor);
String directorStr = String.join(",", director);
String producerStr = String.join(",", producer);
String actorStr = String.join(",", actor);
// 把处理完成的数据放进条目尾部
outputRowData[outputIndex++] = directorStr;
outputRowData[outputIndex++] = producerStr;
outputRowData[outputIndex++] = actorStr;
// 把处理完成的条目输出
putRow(data.outputRowMeta, outputRowData);
return true;
}
具体来说,它做了几件事情:
初始化
在 Kettle 的 Java 环境里,数据条目并不能直接按名查找——能按照字段名获取到的只有字段在数据中的序号。因此,在函数首次被调用时,我们需要获取需要的字段在数据条目中的序号,并保存在类成员变量里备用:
// first是一个隐藏的类内变量,标记这个函数是否为第一次被调用。可以利用它做一些初始化工作
if (first) {
first = false;
// 获取字段“main_creator”所在的序号
mcIndex = getInputRowMeta().indexOfValue(getParameter("main_creator"));
if (mcIndex<0) {
throw new KettleException("Year field not found in the input row, check parameter 'main_creator'!");
}
}
获取条目里的数据
借助上一步中获得的序号,我们可以很方便地利用 Kettle 提供的 API 来获取条目,并取得感兴趣的字段:
// 获取这一条目的数据
Object[] r = getRow();
// 如果获取的数据是null,说明转换完成了
if (r == null) {
setOutputDone();
return false;
}
// 获取所需要的字段的具体数据
String creators = getInputRowMeta().getString(r, mcIndex);
将处理完的字段插入条目末尾
我们可能需要向条目中插入一些新的字段,这时就可以用 Kettle 提供的 API 来“扩容”条目数组:
// 为条目数据“扩容”,保证我们稍后添加的数据不会溢出数组的范围。
// OutputRowMeta的内容是根据我们在Kettle中填写的输出字段来确定的。
Object[] outputRowData = RowDataUtil.resizeArray(r, data.outputRowMeta.size());
// 获取输入条目的字段数量,用于之后添加新字段到尾部。
int outputIndex = getInputRowMeta().size();
// 把处理完成的数据放进条目尾部
outputRowData[outputIndex++] = directorStr;
outputRowData[outputIndex++] = producerStr;
outputRowData[outputIndex++] = actorStr;
当然你也可以直接在现有的字段上做修改;这样的话就不需要这一步了。
处理完这个条目后,就可以返回给 Kettle 了:
// 把处理完成的条目输出
putRow(data.outputRowMeta, outputRowData);
配置转换过程的属性
最后,还有最重要的一步:我们需要向 Kettle 提供我们需要的字段,以及我们会输出的字段。
需要的字段在“参数”选项卡中配置。如果不配置,稍后执行getInputRowMeta().indexOfValue(getParameter("main_creator"))的时候将不能找到这个字段的序号:
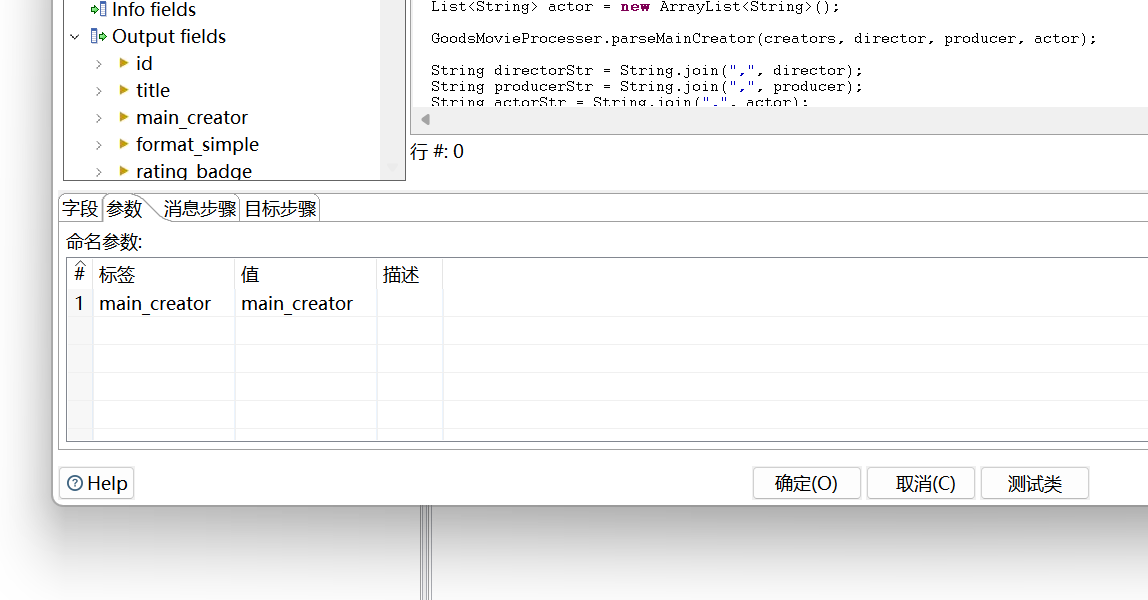
“字段”选项卡中存放的是输出的新字段,根据需要设置即可:
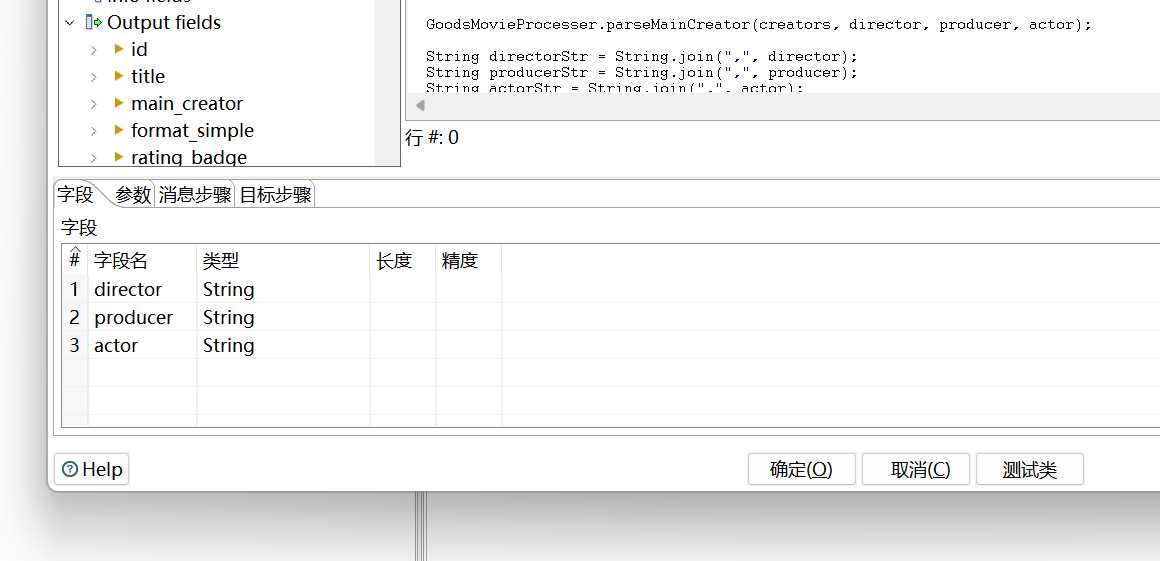
点击“测试类”,测试代码是否正常运行:
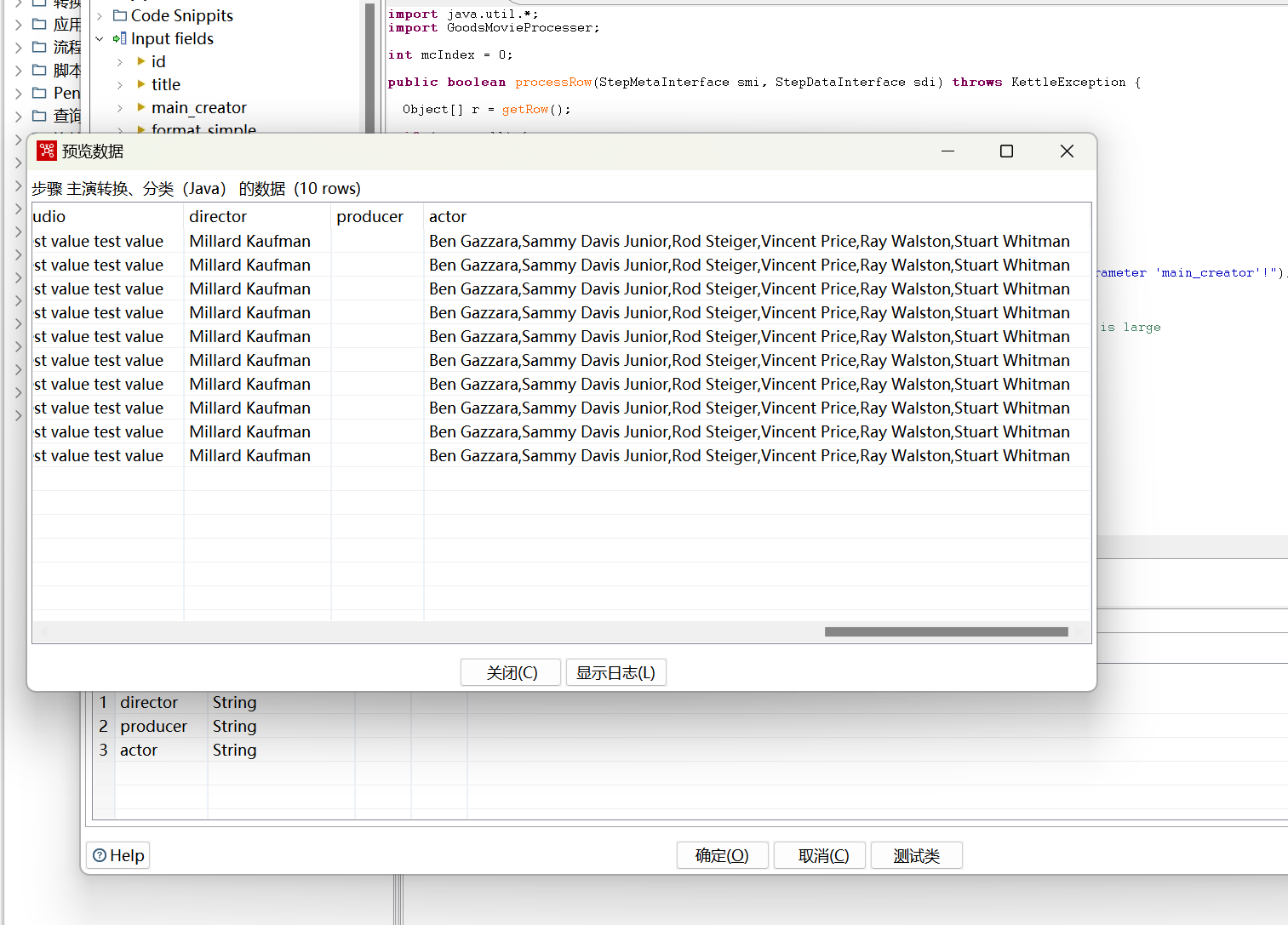
一切正常!很幸运呢。
常见问题
笔者不得不提的是 Kettle 过时的静态语法检查:
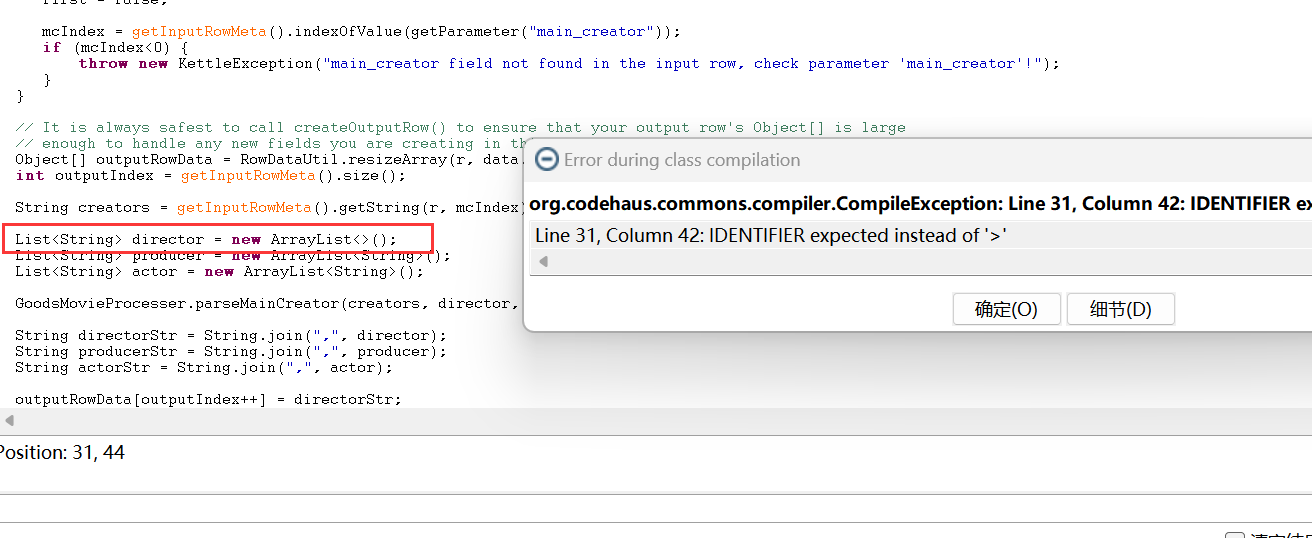
如果遇到类似的报错,按照它的要求改一改就好了。不过,不用担心 Jar 里的代码会遇到类似的问题——这些 Java 代码的运行时是和运行 Kettle 的一致的。