
Unix实验报告
|
实验: |
实验1 同步与异步write的效率比较 |
|
专业: |
计算机科学与技术 |
|
班级: |
1班 |
|
姓名: |
姚怀聿 |
|
学号: |
22920202204632 |
2022年10月7日
目 录
实验内容描述
本实验的目的是掌握UNIX的文件I/O系统调用。
实验要求编写程序:`timewrite <outfile> [sync]`
其中,sync是可选参数,若有该参数,表示输出文件用异步模式打开;反之,用异步模式。体现在程序中就是在使用`open`函数打开文件时,第二个参数是否或`O_SYNC`。
实验有以下几点要求:
- 显示的时间要尽量接近write操作过程所花的时间,不要将从磁盘读文件的时间计入显示结果中。
- 严格按照下表的结果格式输出(BUFFERSIZE从256开始算到128K),抬头和分割线省略。
设计、实验构思
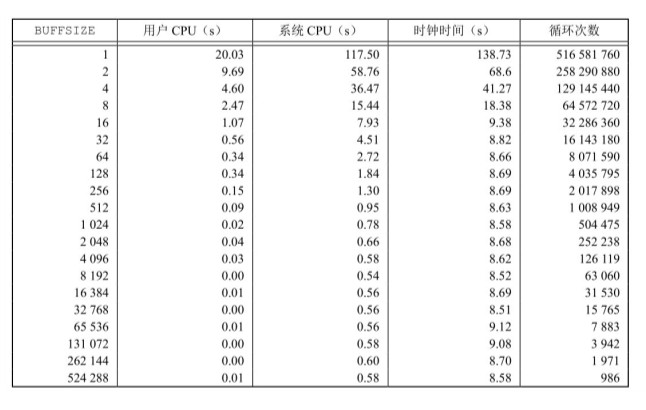
- 实验要求执行程序得到一个输出文件,该文件的名称是指定的,而该文件是否以同步模式打开是可选的,故程序至少应传入一个输入参数,至多应传入两个输入参数,我们可以利用argc判断传入参数个数是否合法。由于timewrite作为程序的名称,故体现在程序中,即为

- 为了达到显示的时间尽量接近write操作所花的时间这一要求,我们可以充分利用缓冲区来读取,具体如下:我们先把从标准输入中读入的数据放在缓冲区,计算机再直接从缓冲区中取数据,这样就可以减少磁盘的读写次数,而计算机对缓冲区的操作速度远高于对磁盘的操作速度,故应用缓冲区可大大提高计算机的运行速度。缓冲区就是一块内存区,它用在输入输出设备和CPU之间,用来暂存数据。为了准确计算write耗费的时间,很重要的一点是要避免将read的时间计入,因为I/O操作的时间通常是毫秒级的,不可以忽略。一种有效的方法是,设置一个与输入文件长度相同的缓冲区,一次性地将输入文件读入缓冲区,而后就不必再读输入文件。这样就可以有效避免计入read的时间。在程序具体实现中,我首先为缓冲区分配了一块很大的空间(1Gbit),然后一次性从标准输入中将文件读入,程序代码如下:


实验要求按照表格输出结果,且BUFFERSIZE要求从256开始算到128K(即131072)结束;对于这一要求,我们可以用一个循环来实现,BUFFERSIZE从256开始,每计算一次时间,将BUFFERSIZE乘以2,直到BUFFERSIZE计算到131072为止。在每一个循环中,我们在开始写文件之前调用times(),记录下开始时间,然后在整个输入缓冲区都复制到输出文件之后,再调用times(),两次调用times()的时间间隔,就是在这个给定大小的输出缓冲区的限制下,复制整个输入文件所耗费的写时间。至于在每一次写的时候所执行的其他语句,它们相较于I/O操作,所花费的时间极小,可以忽略不计。
程序代码如下:

实验的设计如上,程序实现流程如下:
步骤1.判断传入参数是否合法

第一种情况,传入参数个数不合法;
第二种情况,传入参数中的第二个参数不为 “sync”
步骤2.判断以哪种方式打开输出文件
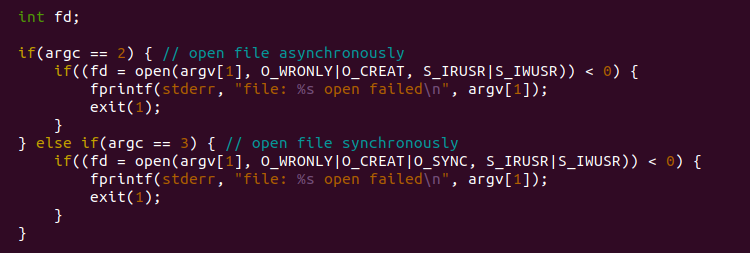
如果传入一个参数,就以异步模式打开;
如果传入两个参数,就以同步模式打开,即以O_SYNC模式打开;
若打开失败,输出失败信息,并退出(1)。
步骤3.从标准输入中读取文件到缓冲区中
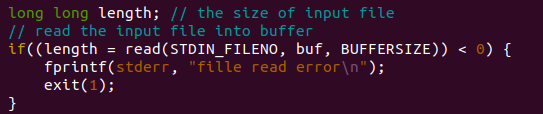
length记录了所读取的文件大小,如果失败,输出失败信息并退出(1)。
步骤4.定义时钟用于记录进程运行的时间

步骤5.循环buffersize,每次以固定的buffersize写入
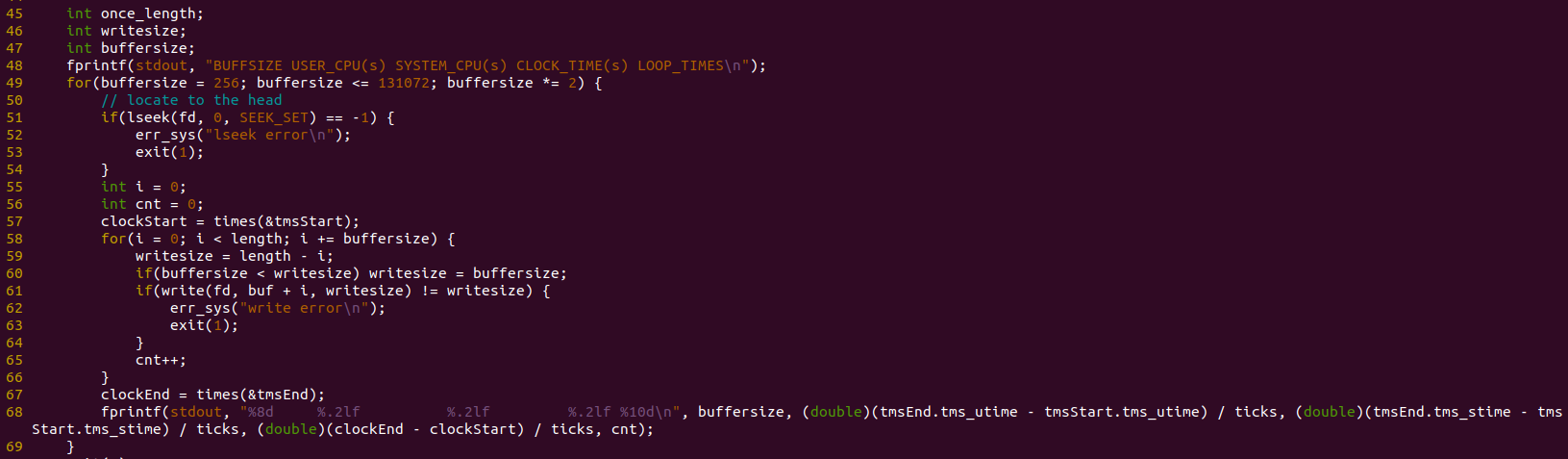
每次循环开始时,先将文件偏移量定位到输出文件的开始
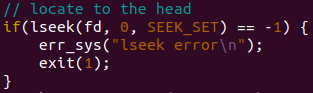
若定位失败,输出失败信息,并退出(1);
每次写入开始前,先调用times(),获得写文件开始的时间,每次写文件结束后,再次调用times(),获得写文件结束的时间,最后将两时间相减,得到写文件所用的时间。具体来说有三类时间,分别是用户调用时间、系统调用时间以及时钟时间。
#include <sys/times.h>
clock_t times(struct tms *buf);
struct tms {
clock_t tms_utime; /* 记录进程除系统调用外所使用的CPU时间 */
clock_t tms_stime; /* 记录进程的系统调用所使用的CPU时间 */
clock_t tms_cutime; /* 记录子进程除系统调用外所使用的CPU时间 */
clock_t tms_cstime; /* 记录子进程的系统调用所使用的CPU时间 */
};
调用函数times()时,向times()传入一个结构体tms的地址,函数times()会修改地址的内容,修改后得到的tms_utime便是用户使用时间,tms_stime便是系统使用时间,在本次实验中,我们只需要用到这两个,另外两个无需使用;至于时钟时间,该times()函数的返回值clock_t即为时钟时间。具体程序如下:



这里还有一个小问题,times()函数所有的值均是以”滴答”为单位的,我们需要用到函数 sysconf(_SC_CLK_TCK)来获得所运行系统每秒的滴答数,最后将两者相除,便可得到程序运行的秒数。

每次往文件中写入程序时,我们需要比较一下还未写入的长度与buffersize的大小,我们将写入的大小是较小的那个。

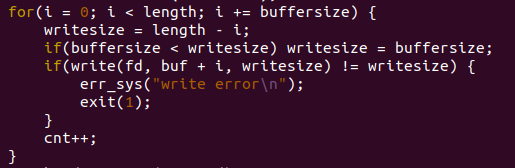
每写一个writesize长度,都需要将i加上buffersize,在最后不够一个buffersize大小的时候,将剩余的长度全部写入;每成功写入一次,将cnt加1,即为循环次数加1。
最后,在每次循环结束时,将buffersize变为原来的两倍,继续在新的buffersize下重新写入文件。
至此,程序实现流程描述完毕。
为了看出异步和同步write的差异,我另写了一个程序gen_ran()用于生成一个指定大小的随机文件(默认是100MByte)。
该程序的编译方式为`gcc gen_ran.c`
该程序的使用方式为`./a.out <input_file> [size(MB)]`


实验结果
|
源程序名 |
可执行程序名 |
|
timewrite.c |
timewrite |
|
gen_ran.c |
a.out |
编译生成可执行文件:
对于timewrite.c,使用如下指令:
`make -f Makefile`
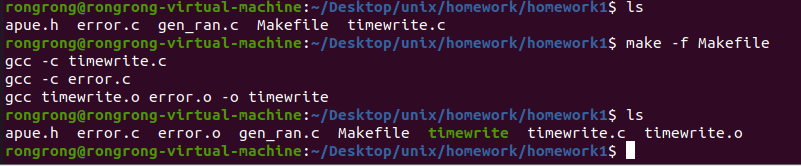
对于gen_ran.c,使用如下指令:
`gcc gen_ran.c`

运行程序:
首先生成指定大小的随机文件:
`./a.out input_file 50`表示生成一个50MB大小的名称为 “input_file”的文件。

然后执行timewrite程序查看写入程序的时间:
`./timewrite output_file <input_file`
表示以异步模式打开output_file并将input_file写入。
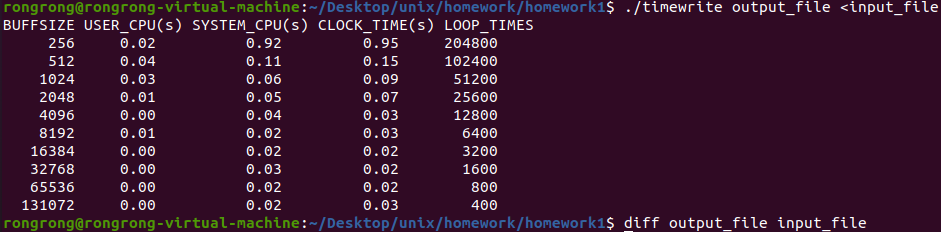
`diff output_file input_file`查看两文件是否有不同之处,未输出任何信息,表示两文件内容相同。
`./timewrite output_file sync <input_file`
表示以同步模式打开output_file并将input_file写入。

`diff output_file input_file`查看两文件是否有不同之处,未输出任何信息,表示两文件内容相同。
通过对比,我们可以看到,异步相较于同步,在写入文件比较大的情况下,异步模式打开写入所花费的时间远小于同步模式打开写入所花费的时间。
体会和建议
体会:本次实验可以说是真正意义上的第一次实验,通过本次实验,我体会到了操作系统的奥妙。以前写程序,都只是在写函数,然后调用,这次是第一次感受到了系统更深层的内容。以前写程序时,main函数中基本不会传入什么参数,在本次实验中,我体会到原理main函数中所传入的参数有这么大的作用。
建议:希望以后上机课之前,老师能提前说明实验课需要做什么,比如要用到哪些知识点,以及书上哪些程序对本次实验是比较有帮助的,我们可以通过看书本上的例程去更好的实现实验要求。
完成人姓名及完成时间
|
完成人姓名 |
完成时间 |
|
姚怀聿 |
2022年10月8日 |