前言
本文提出了一个基于集群的数据去重存储系统
GOLD
1. 高吞吐量
2. 可扩容
3. 高数据去重
问题
-
以何种粒度路由数据
提出原因:块大小的减小,数据去重速率会增加,但是对于更大的块大小,由于流和文件间的局部性,吞吐量会增加
方法:构建超级块
-
如何将超级块分配给节点
方法:使用称为bin的间接级别,使用mod函数将超级块分配给bin,将每个bin映射到给定的节点。
-
路由数据到节点,如何保持负载均衡
提出原因:系统可能向单个节点路由过多的数据导致其过载
方法:
(1) 有 bin 迁移无状态路由技术 (2) 有状态路由技术
以何种粒度路由数据-超级块
-
组成:由连续的块组成
-
平均超级块的大小
(1) 平均超级块大小会严重影响数据去重,节点的负载平衡和吞吐量
(2) 探究:从备份数据集上实验了从8KB-4MB的平均超级块大小。
(3) 结果:
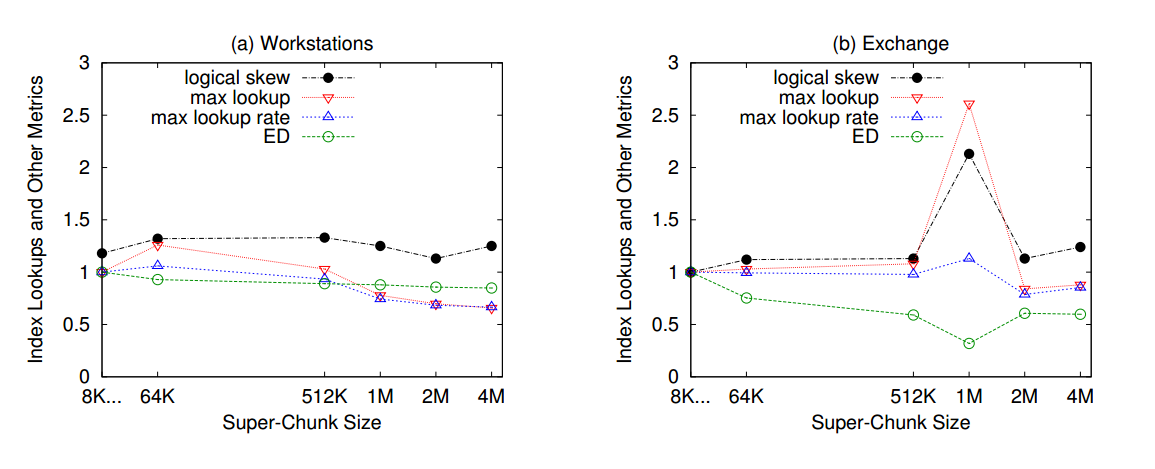
对于Workstations数据集:随着超级块大小的增加,磁盘上索引查找的最大次数会减少(提高吞吐量),有效的数据去重会减少 Exchange数据集比较特殊,存在某些数据模式可能导致数据分配不均匀,严重影响数据去重。 认为Exchange数据集在实际情况中很少出现,所以确定超级块的最佳平均超级块大小是1MB
如何将超级块分配给节点-中间级别bin
-
Bin Manager运行在主节点上
-
工作流程
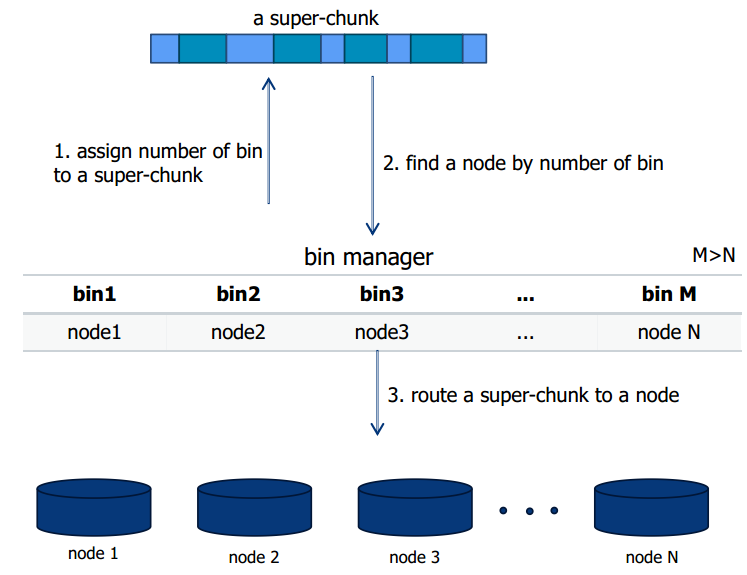
首先为Bin分配一个超级块,然后将每个bin映射到给定的节点,最后将超级块路由到节点。
如何保持负载均衡
-
有bin迁移无状态路由技术
(1) 仅基于当前超级块的内容进行路由
(2) 轻量级
(3) 适合大多数平衡的工作负载
-
有状态路由技术
(1) 基于现有块的位置信息进行路由
(2) 提高数据去重
(3) 避免数据倾斜
有bin迁移无状态路由技术
-
基本技术
(1) 为每个块创建一个指纹
(2) 选择具有代表性的指纹
(3) 为超级块分配一个bin(例如用函数 mod # bins)
-
怎样创建超级块指纹
(1) 计算整个数据块的 Hash 值(也称Hash(*))
(2) 计算数据块的前 N 字节的 Hash 值(也称Hash(N))
(3) 使用SHA-1哈希函数
-
如何选择有代表性的指纹
第一个块、最大块、最小块或最常见块的 hash 值
-
优缺点
(1) 优点
减少了记录节点分配的开销 减少了系统故障后重新恢复这些状态的需求(2) 缺点
可能会导致去重效果的损失 若所选的特征不均匀分布,可能导致数据倾斜的增加
有状态路由技术
-
算法描述
(1) 使用Bloom filter计算在给定节点上已存储的每个超级块中每个指纹的出现次数
(2) 据每个节点的相对存储利用率来加权匹配数
(3) 如果具有最高权重的选票超过了一个阈值,那么选择该节点作为路由目标
(4) 如果没有节点获得足够的加权选票,那么可以考虑以下两种情况:
对第一个块计算前64字节的哈希值,并且选择的节点没有过载,那么可以将数据路由到该节点 否则将数据路由到负载最轻的节点解释静态阈值:这就要求节点匹配块的数量必须明显超过平均水平,而不仅仅是稍微多于其他节点,才能成为目标。这有助于确保节点被选中是因为它们真正具有足够的匹配块,而不仅仅是因为它们匹配块的数量多。
-
投票阈值:
本文设置的投票阈值为1.5意味着一个节点至少要匹配1.5*C/N个块才被视为候选节点。
(其中C是匹配数,N是总块数)任然存在的问题:数据分布不均,比较高的数据倾斜
改进:
加权投票:为每个潜在的目标节点分配一个权重,节点的权重与匹配块数量和存储使用率有关。例如
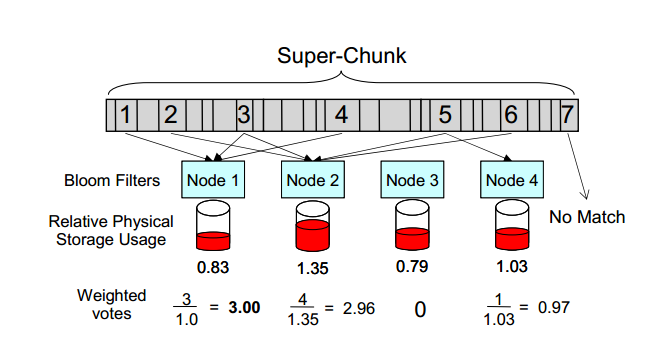
投票权重 = 匹配数/物理存储使用率
-
容量阈值(1.05):排除高出容量阈值的节点(高于平均值5%的容量)
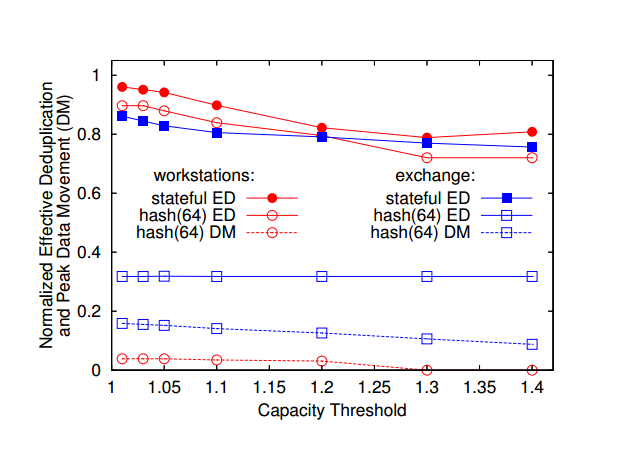
当容量阈值从1到1.05,ED会发生明显的变化,所以确定容量阈值为1.05。
排除存储利用率高出平均值5%的节点。
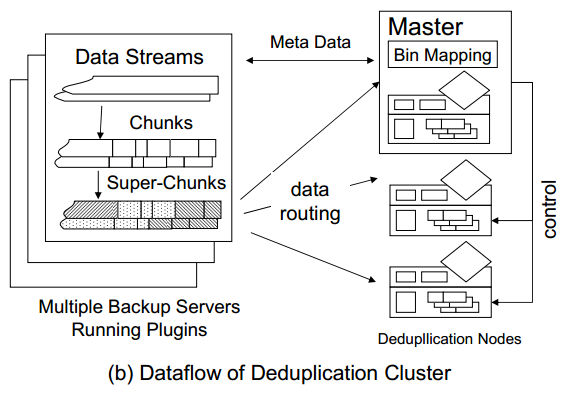
系统架构
表示超级块的四种方法的比较
表示超级块的四种方法的比较:
(1)first hash(64): 第一个块的前64字节的哈希值
(2)first hash(*):第一个块的哈希值
(3)min hash(64): 最小块的前64字节的哈希值
(4)min hash(*): 最小块的哈希值
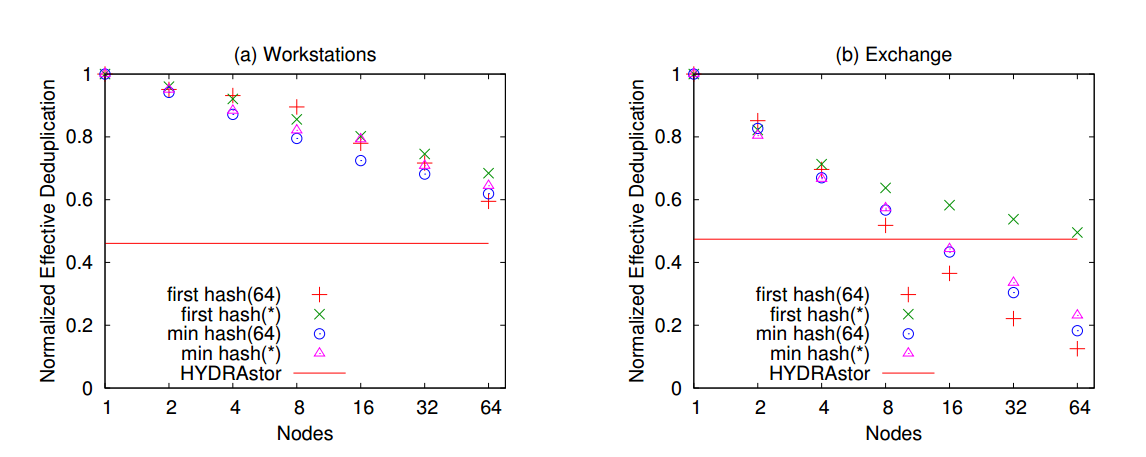
表明:
对于较小的集群,采用第一个块的前64位哈希值来表示超级块,通常效果更好
对于较大的集群,采用第一个块的哈希值来表示超级块,效果更好
数据迁移随时间的影响
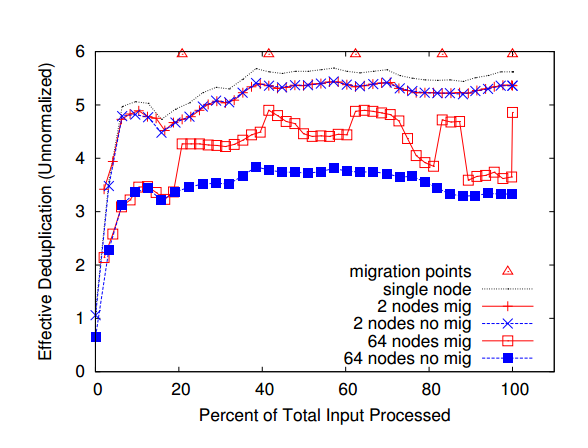
没有进行数据块迁移的曲线的去重效果(ED)较差。然而,即使进行了数据块的迁移,由于数据不均匀性逐渐增加,ED在迁移点之间也会下降。
不懂的问题
-
超级块中遇到的问题:创建重复的风险 怎么理解?
理解:每个节点都维护着数据的指纹索引,可能会出现,比如 相同的数据块a和b,两次分别路由到了节点1和节点2;在节点1和节点2都创建了指纹索引,这样其实在整个集群来说,是造成了数据冗余的,会浪费存储空间。
-
什么是 bin 迁移?
-
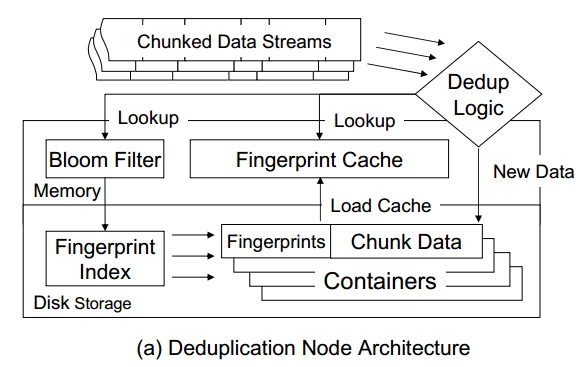
单个节点辨别重复数据块的结构图
(1) 检查它是否在段缓存中。如果它在缓存中,则传入段是重复的。
(2) 如果不在段缓存中,检查摘要向量。如果它不在摘要向量中,则该段是新的。将新段写入当前容器。
(3) 如果它在Summary Vector中,则查找段索引以查找其容器Id。如果它在索引中,则传入段是重复的;将容器的元数据部分插入段缓存中。如果段缓存已满,首先删除最近最少使用的容器的元数据部分。
(4) 如果不在段索引中,则该段为新段
(5) 将新段写入当前容器。