首先下载并打开两个数据包
可以看到源地址和目标地址都不同,并且分为TCP和UDP协议两种
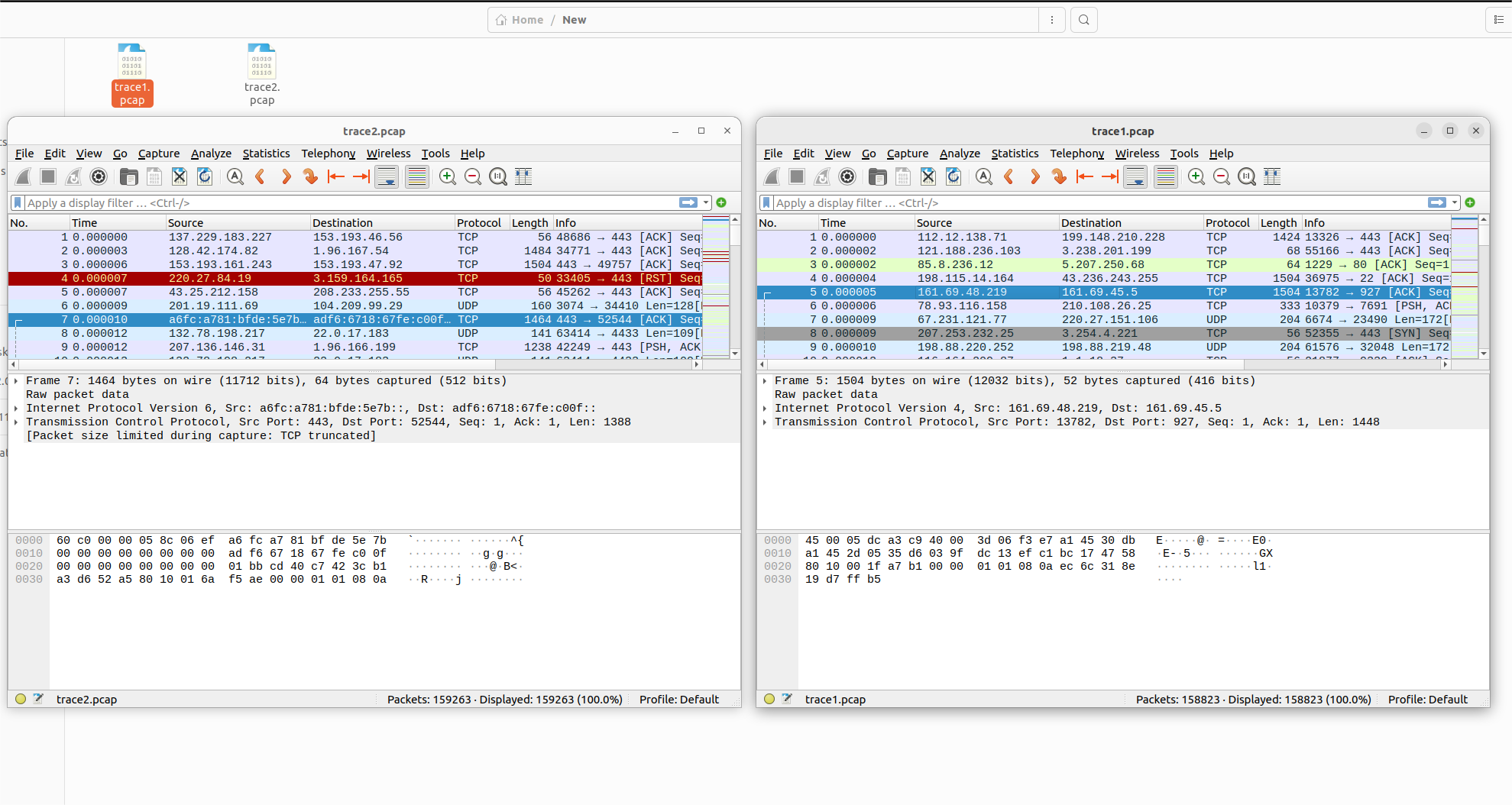
然后先学习TOP-K问题
TOP-K问题即使求数据集中频数最高的k条流
其可以拆解成两部分,第一部分是对其进行频率统计,第二部分是对其排序求其最大的k个
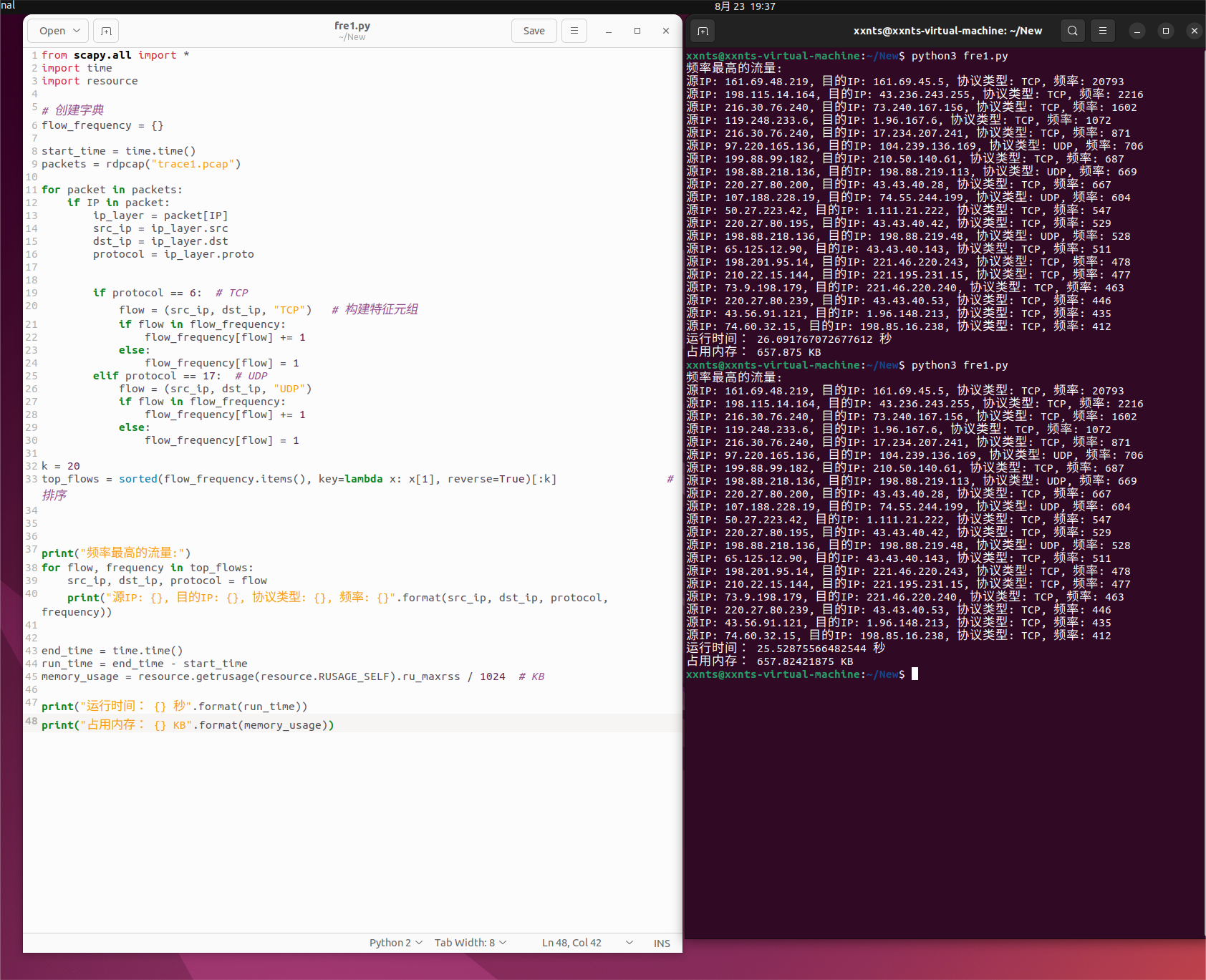
首先是依次遍历用字典统计频率+遍历排序
直接将遍历出的源IP,目的IP和协议组成特征元组,用字典统计,再排序出精确频率数
代码设计的思路是用字典来遍历统计
将数据包的源ip,目的ip和协议特征构建元组来放入字典统计
最后直接用sorted函数对字典的键值对的值进行排序,再输出排序后的元组列表即可
(查top-k问题的时候,有查到各种排序方法,有各种遍历,或用数据结构中的堆来排序的,不过python内置的sorted的Timsort算法貌似是相率相对最高的,
这里就直接用了,后面会test一下用堆来估算排序的效率。)
不是很知道heavy-hitters有没有定义阈值
这里直接就将最大的20个当大流了
如果有要求阈值的化后面会加上。。
可以看到用遍历来统计,用Timsort算法计数耗时在20多秒左右
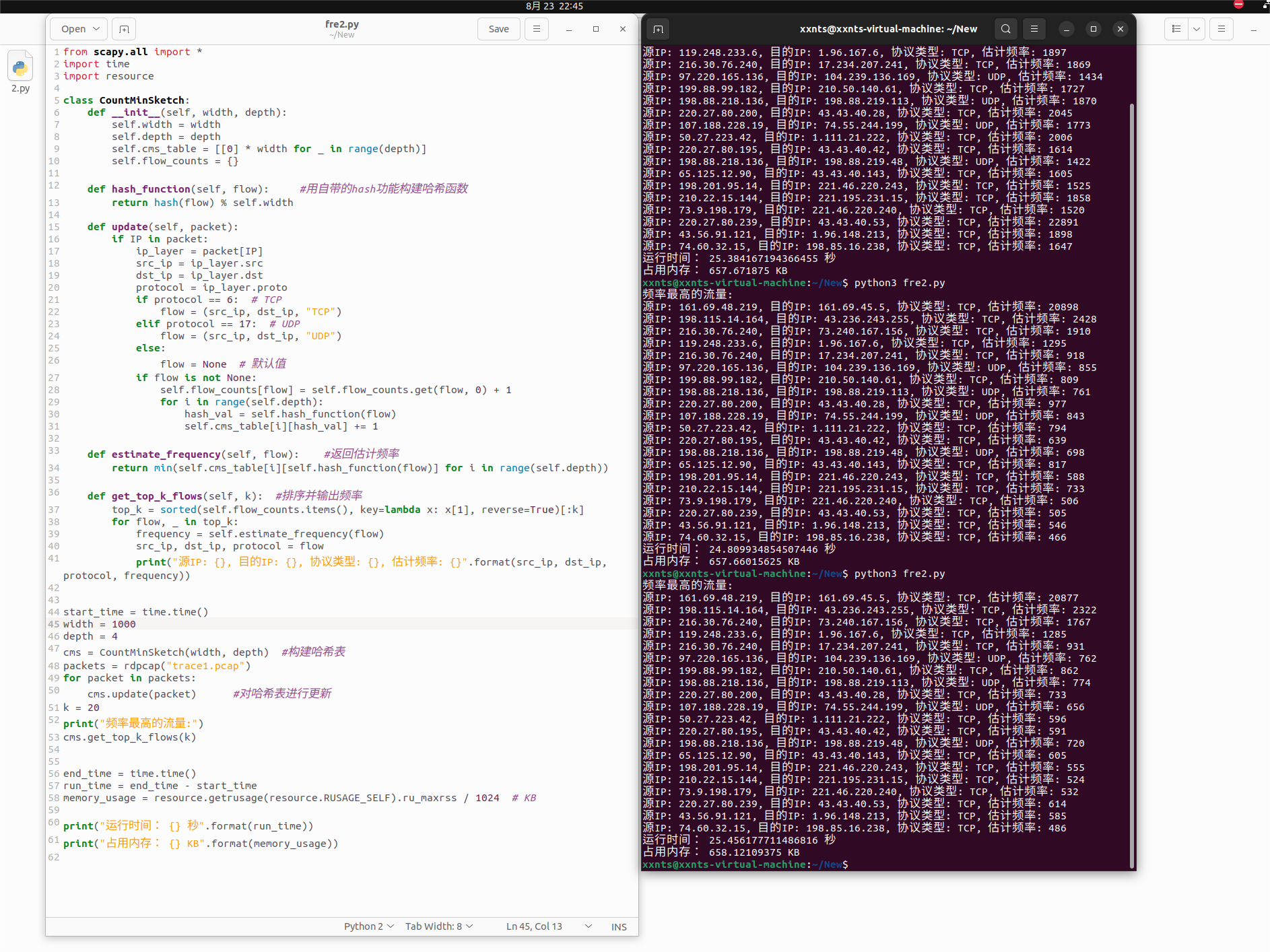
为了减少测量的时间开销并尽可能保持估计精度
通过遍历来测量会消耗大量的时间和空间,故要使用哈希表来实现测量任务
故直接整合上一次作业的count-min sketch和排序
在这里改变用python内置的hash函数来生成哈希值
来进行估算
但感觉差异并不大,并没有减少时间消耗
跟精确值存在误差,但并不大
或许该调小一下depth和width
后面是对trace2的
左边是精确,右边是估计的
不是很理解压缩sketch是什么意思
还在做