linux-tools 包含了一系列性能分析工具和调试工具,用于监视和分析 Linux 系统的性能、内核活动以及其他性能相关信息。具体包含的工具可能因不同的 Linux 发行版和版本而有所不同。以下是一些常见的工具,可能包含在 linux-tools 或相关的包中:
perf:perf工具集,包括perf record、perf stat、perf report等,用于性能分析、系统调用跟踪、硬件性能计数器分析等。oprofile:性能分析工具,用于 CPU 使用情况分析、性能瓶颈诊断以及优化。trace-cmd:用于跟踪和分析 Linux 内核跟踪事件的工具。sysstat:包含sar、iostat、mpstat等工具,用于系统活动报告和性能监视。strace:系统调用跟踪工具,用于分析进程的系统调用和信号。ltrace:库调用跟踪工具,用于监视进程调用的共享库函数。htop:增强版的top,用于实时监视进程和系统性能。powertop:用于监视和分析电源消耗的工具。blktrace:块设备层的性能分析工具,用于分析磁盘和存储性能。strace:用于跟踪进程的系统调用。iostat:用于监视系统的磁盘和 IO 性能。numactl:NUMA(非一致性内存访问)相关工具,用于优化 NUMA 架构系统的性能。
请注意,具体的工具和版本可能会因 Linux 发行版和系统配置而有所不同。你可以使用包管理工具(如apt、yum或dnf)来查找和安装适用于你的系统的linux-tools或相关工具包。在 Ubuntu 上,你可以使用以下命令来列出可用的linux-tools子包:
apt search linux-tools
然后,使用相应的命令来安装你需要的工具包
sudo apt-get update
sudo apt-get install linux-tools-common linux-tools-$(uname -r)
perf
简单用法
# kun @ kun-KLVD-WXX9 in ~/dev-home/sysmonitor/build on git:master o [15:06:30]
$ ps -A | grep sysM
137892 pts/4 00:00:00 sysMonitor
# kun @ kun-KLVD-WXX9 in ~/dev-home/sysmonitor/build on git:master o [15:06:39]
$ sudo perf record -p 137892
上述过程会阻塞,直到用户执行ctrl+c
然后会生成perf.data在当前目录
执行sudo perf report就可以看到该进程的一些信息
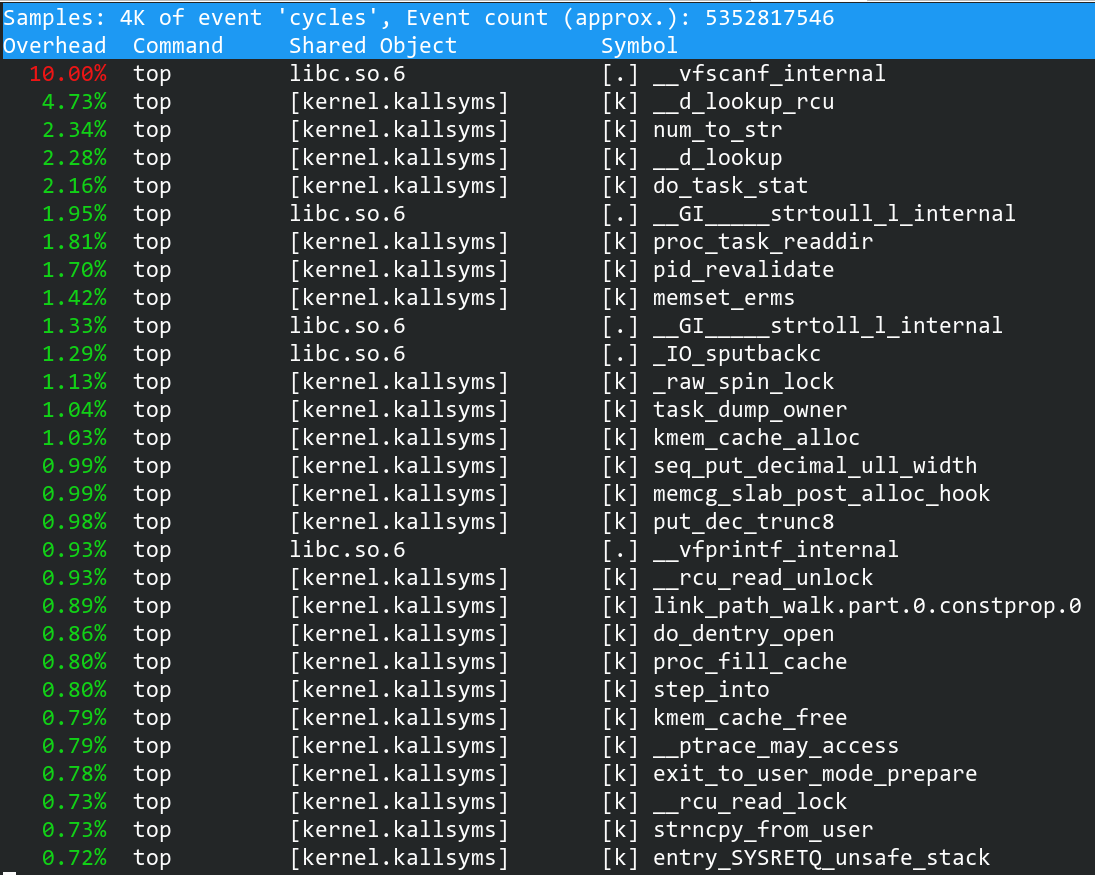
按键盘的方向键盘可以选择某个函数,回车会查看一些具体的信息
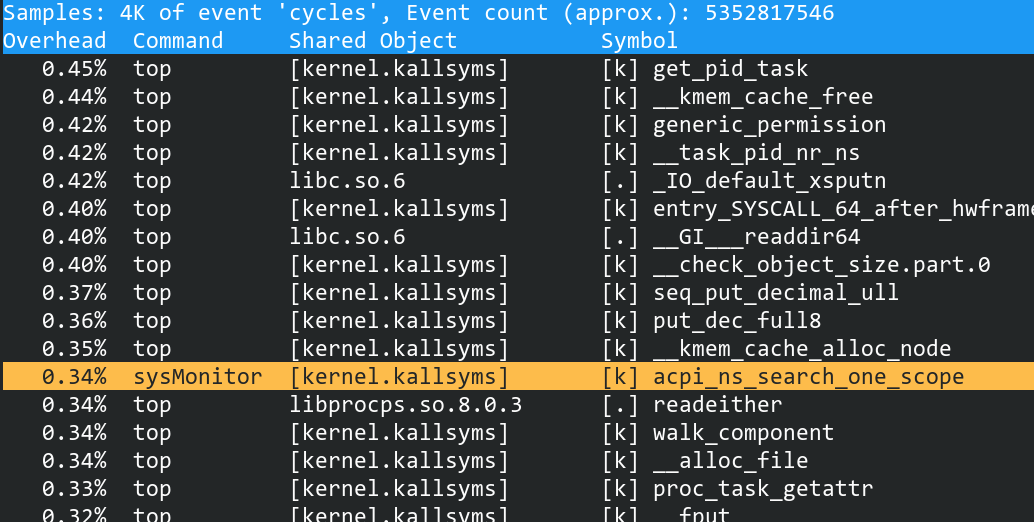
按下回车会看到这些
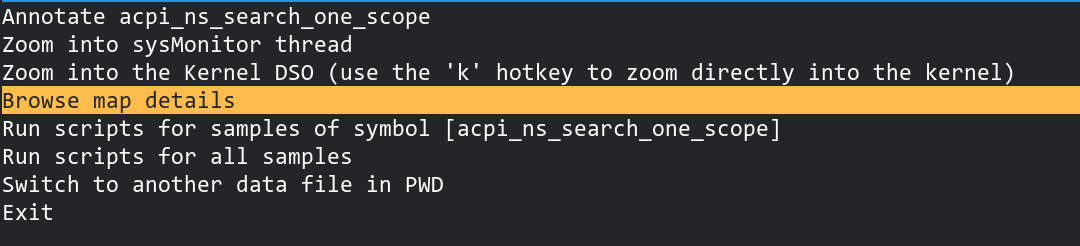
Annotate acpi_ns_search_one_scope # 这是当前的函数,回车进去可以看该函数的汇编代码
Zoom into sysMonitor thread # 聚焦sysMonitor
Zoom into the Kernel DSO (use the 'k' hotkey to zoom directly into the kernel) # 聚焦内核的性能数据
Browse map details
Run scripts for samples of symbol [acpi_ns_search_one_scope]
Run scripts for all samples
Switch to another data file in PWD
perf record支持的一些选项
-e event:指定要记录的性能事件。可以多次使用该选项来记录多个事件。
-a:记录所有进程的事件。
-p PID:仅记录特定进程的事件,使用进程 ID(PID)指定。
-c cpu:限制记录到指定的 CPU 上。
-o filename:指定输出文件的名称,将记录的性能数据保存到文件中。
-F frequency:设置事件记录的频率,通常以 Hz 为单位。
--call-graph:指示记录调用图信息,用于分析函数调用关系。
--no-samples:禁用采样,只记录事件计数。
--no-inherit:禁止子进程继承父进程的事件记录。
--switch-output:切换输出文件,以便定期将数据写入不同的输出文件。
--overwrite:覆盖已存在的输出文件。
--append:将记录追加到已存在的输出文件。
--time:记录事件时采用时间戳。
--time-out:设置事件记录的时间限制。
--no-buffering:禁用缓冲,直接将数据写入输出文件。
--filter:根据进程、线程或事件名称进行过滤。
--exclude-perf:排除 perf 工具自身的事件。
strace
分析进程的系统调用和了解应用程序与操作系统之间的交互
# 指定pid
sudo strace -p xxx
# 直接启动程序
sudo strace ./xxx
strace的输出是目标进程的系统调用、参数、返回值等信息:
read(4, "cpu 724574 230290 3584138 87049"..., 1024) = 1024
close(4) = 0
openat(AT_FDCWD, "/sys/devices/system/cpu/online", O_RDONLY|O_CLOEXEC) = 4
read(4, "0-7\n", 1024) = 4
close(4) = 0
newfstatat(AT_FDCWD, "/etc/localtime", {st_mode=S_IFREG|0644, st_size=561, ...}, 0) = 0
write(1, "2023-10-20-15-26-03, CPU usage: "..., 89) = 89
newfstatat(AT_FDCWD, "/etc/localtime", {st_mode=S_IFREG|0644, st_size=561, ...}, 0) = 0
openat(AT_FDCWD, "/sys/devices/system/cpu/cpu0/cpufreq/cpuinfo_cur_freq", O_RDONLY) = -1 ENOENT (没有那个文件或目录)
write(1, "2023-10-20-15-26-03, CPU freq(MH"..., 37) = 37
openat(AT_FDCWD, "/sys/class/net/wlp0s20f3/statistics/rx_bytes", O_RDONLY) = 4
newfstatat(4, "", {st_mode=S_IFREG|0444, st_size=4096, ...}, AT_EMPTY_PATH) = 0
read(4, "2207176195\n", 4096) = 11
close(4) = 0
openat(AT_FDCWD, "/sys/class/net/wlp0s20f3/statistics/tx_bytes", O_RDONLY) = 4
newfstatat(4, "", {st_mode=S_IFREG|0444, st_size=4096, ...}, AT_EMPTY_PATH) = 0
read(4, "336795948\n", 4096) = 10
close(4) = 0
newfstatat(AT_FDCWD, "/etc/localtime", {st_mode=S_IFREG|0644, st_size=561, ...}, 0) = 0
write(1, "2023-10-20-15-26-03, net usage, "..., 58) = 58
openat(AT_FDCWD, "/sys/devices/system/cpu/online", O_RDONLY|O_CLOEXEC) = 4
read(4, "0-7\n", 1024) = 4
close(4) = 0
newfstatat(AT_FDCWD, "/etc/localtime", {st_mode=S_IFREG|0644, st_size=561, ...}, 0) = 0
openat(AT_FDCWD, "/sys/class/thermal/thermal_zone0/temp", O_RDONLY) = 4
read(4, "49000\n", 8191) = 6
close(4) = 0
openat(AT_FDCWD, "/sys/class/thermal/thermal_zone1/temp", O_RDONLY) = 4
read(4, "53050\n", 8191) = 6
close(4) = 0
ltrace
sudo apt install ltrace
# 监控pid
sudo ltrace -p ***
-S选项可以打印系统调用及其返回值
valgrind
sudo apt-get install valgrind
基本用法如下

我把程序ctrl c掉之后的输出如下:
==156612== Process terminating with default action of signal 2 (SIGINT)
==156612== at 0x4C9B7F8: clock_nanosleep@@GLIBC_2.17 (clock_nanosleep.c:78)
==156612== by 0x4CA0676: nanosleep (nanosleep.c:25)
==156612== by 0x4CD211E: usleep (usleep.c:31)
==156612== by 0x1162FC: main (main.cpp:154)
==156612==
==156612== HEAP SUMMARY:
==156612== in use at exit: 119,588 bytes in 108 blocks
==156612== total heap usage: 50,265 allocs, 50,157 frees, 15,585,583 bytes allocated
==156612==
==156612== 304 bytes in 1 blocks are possibly lost in loss record 67 of 93
==156612== at 0x484DA83: calloc (in /usr/libexec/valgrind/vgpreload_memcheck-amd64-linux.so)
==156612== by 0x40147D9: calloc (rtld-malloc.h:44)
==156612== by 0x40147D9: allocate_dtv (dl-tls.c:375)
==156612== by 0x40147D9: _dl_allocate_tls (dl-tls.c:634)
==156612== by 0x4C4B7B4: allocate_stack (allocatestack.c:430)
==156612== by 0x4C4B7B4: pthread_create@@GLIBC_2.34 (pthread_create.c:647)
==156612== by 0x4A44328: std::thread::_M_start_thread(std::unique_ptr<std::thread::_State, std::default_delete<std::thread::_State> >, void (*)()) (in /usr/lib/x86_64-linux-gnu/libstdc++.so.6.0.30)
==156612== by 0x118C05: std::thread::thread<void (&)(int, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&), int&, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >&, void>(void (&)(int, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&), int&, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >&) (std_thread.h:143)
==156612== by 0x1162E9: main (main.cpp:151)
==156612==
==156612== LEAK SUMMARY:
==156612== definitely lost: 0 bytes in 0 blocks
==156612== indirectly lost: 0 bytes in 0 blocks
==156612== possibly lost: 304 bytes in 1 blocks
==156612== still reachable: 119,284 bytes in 107 blocks
==156612== of which reachable via heuristic:
==156612== newarray : 352 bytes in 1 blocks
==156612== suppressed: 0 bytes in 0 blocks
==156612== Reachable blocks (those to which a pointer was found) are not shown.
==156612== To see them, rerun with: --leak-check=full --show-leak-kinds=all
==156612==
==156612== For lists of detected and suppressed errors, rerun with: -s
==156612== ERROR SUMMARY: 1 errors from 1 contexts (suppressed: 0 from 0)
HEAP SUMMARY:这一部分提供了内存的总结信息。它告诉你在程序退出时有多少内存仍然处于使用中,以及程序运行期间分配和释放了多少内存。在这个示例中:
"in use at exit":119,588 字节的内存仍然在程序退出时处于使用状态。
"total heap usage":程序运行期间共分配了 50,265 块内存,释放了 50,157 块内存,总共分配了 15,585,583 字节的内存。
304 bytes in 1 blocks are possibly lost:这一行表示 Valgrind 发现了可能的内存泄漏。具体来说,它报告了 304 字节的内存可能已经丢失。它还提供了有关问题的位置和调用堆栈。
"304 bytes":泄漏的内存大小为 304 字节。
"in loss record 67 of 93":这是错误的编号,有助于定位问题。
"at 0x484DA83":泄漏发生的地址。
"by 0x40147D9" 和以下的行:显示了函数调用堆栈,以便你可以追踪泄漏的来源。
LEAK SUMMARY:这一部分总结了内存泄漏的情况。
"definitely lost":明确泄漏的内存,但在这个示例中是零。
"indirectly lost":间接泄漏的内存,但在这个示例中是零。
"possibly lost":可能泄漏的内存,这里报告了 304 字节的内存泄漏。
"still reachable":仍然可达的内存,即程序退出时尚未释放但仍然可以访问的内存块。
"of which reachable via heuristic":仍然可达的内存块,但通过启发式方法来判断的。
"suppressed":被抑制的错误数,这里是零。
ERROR SUMMARY:这一部分提供了总体的错误概要。
"ERROR SUMMARY":检测到的错误总数。
"errors from":涉及到的上下文数(即错误的数量)。
"suppressed":被抑制的错误数。
在这个示例中,Valgrind 发现了一个可能的内存泄漏,但没有发现明确的泄漏。你可以通过查看调用堆栈信息,尝试追踪问题的来源,并在代码中采取措施来解决可能的泄漏。