pyhton解决高并发问题
发布时间 2023-08-23 20:31:46作者: yedayang
pyhton解决高并发问题
# 前端:
1.cdn加速,就是内容分发网络,简单来说就是把静态资源放到别的服务器上
2.精灵图:就是一个大的图片上面有多个我们需要的小图,用定位的方法,定位到不同的小图,满足我们的需求。这样一个请求拿到的图就可以用在多个位置。
3.前端缓存:在返回的响应头里面设置cache-control这样在一定时间内不会真的发起请求而是从缓存里面拿。
# 后端:
#1 用高性能web服务器部署我们的项目:nginx
用nginx进行请求转发,nginx性能高,把请求转发给不同的后端 一个nginx的性能是几千,用在我们普通的项目里是足够的。
如果有更高的要求,可以使用NGINX做集群(但是每个nginx都监听一个地址,前端此时如何判断地址?--》使用dns域名解析做负载均衡----》使用硬件做负载均衡(可以承受百万级的并发)
#2 动静分离:
用nginx处理静态资源的转发,用uwsgi处理动态资源的转发---nginx处理静态资源的效率非常高
#3. 集群化的部署(要借用nginx
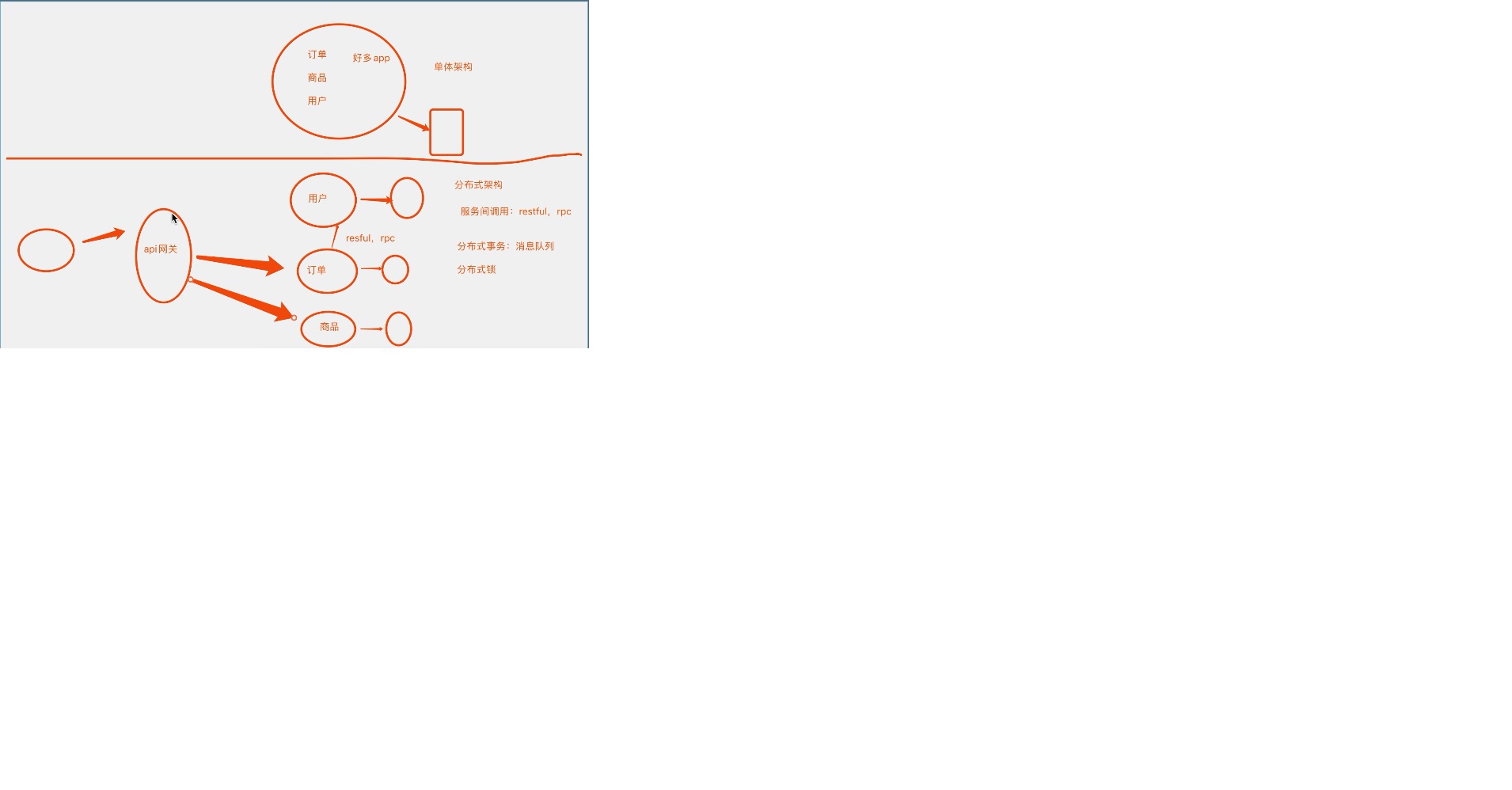
#4、 拆服务(分布式、微服务):
##############
# 项目部署层面:
#1.使用高性能的web服务器部署:gevent+uwsgi
##########
# 代码层面:
1.加缓存:使用redis服务器
2.页面静态化:(不适用与app和小程序)
对于访问量最高的首页,我们可以直接写成静态化的页面,对于首页上会改变的数据,可以每十秒钟生成一次新的页面---》用celery异步和django信号异步
3.celery异步操作,对于一个需要耗时3s的请求,设计成异步--请求来了===直接返回已发送请求:适用于商品秒杀,短信和邮件发送视频保存、后台管理中统计三个月的订单量,并生成折线图、饼状图。。。
4.优化数据库:sql优化、尽量使用逻辑外键代替物理外键、适当建立索引、读写分离、数据库集群、分库分表
5.代码优化:开多线程处理,不再for循环中操作数据库——》涉及到算法
6.换语言:使用编译型语言,更换更接近底层的语言
#加机器
C10k问题: