Exact Feature Distribution Matching for Arbitrary Style Transfer and Domain Generalization
论文源码:https://github.com/YBZh/EFDM
1. Introduction
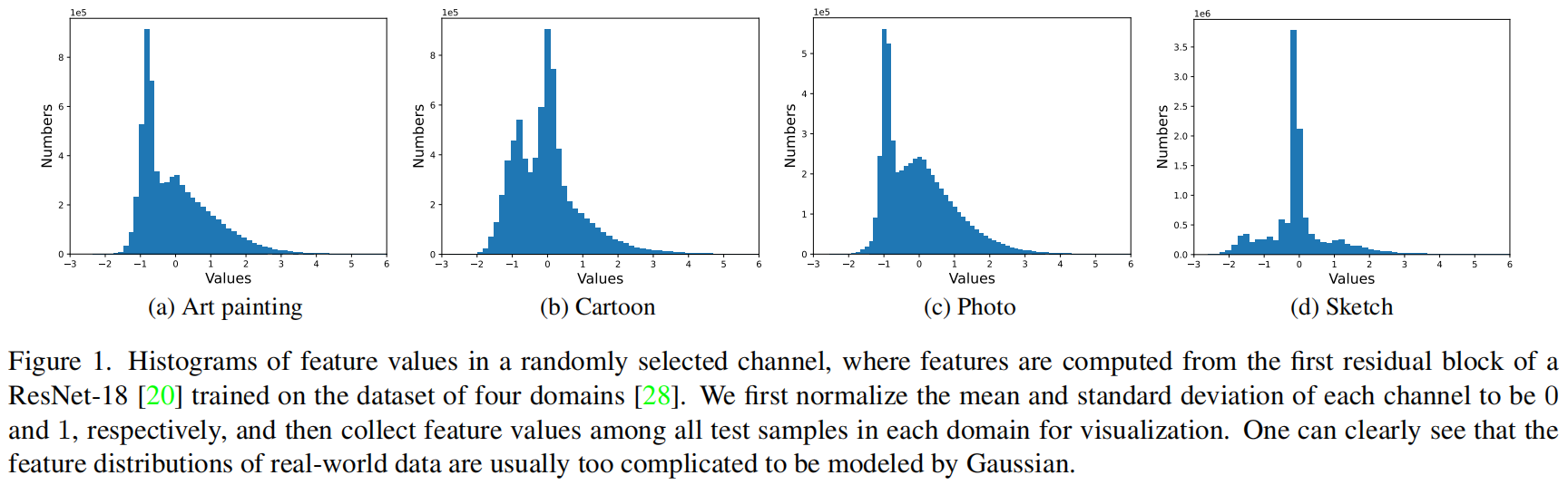
传统的特征分布匹配方法通常假定特征遵循高斯分布,通过匹配特征的均值和标准差来实现。然而,现实世界中的数据特征分布通常较复杂,不能简单地用高斯分布来建模,因此仅匹配均值和标准差的方法准确性有限。因此,需要更有效的方法来精确特征分布匹配(Exact Feature Distribution Matching, EFDM)。
EFDM的直观理念是通过匹配特征的高阶统计信息来实现。虽然已经有方法在匹配分布时引入了高阶统计信息,但这通常会引入大量计算开销。此外,EFDM通常只在理论上才能通过匹配无限阶的中心矩来实现,这在实际中是不可行的。
为了解决这一问题,文中提出了一种新的EFDM方法,它通过准确匹配图像特征的累积分布函数(eCDF)来实现,从而精确匹配特征分布和各种统计信息。这种精确匹配eCDF的方法可以通过在特征空间中应用精确直方图匹配(EHM)算法来实现。EHM通过区分等效特征值并应用逐元素变换来更细粒度、更准确地匹配eCDF,比传统的直方图匹配方法更好。EFDM还通过将EFDM扩展为生成混合样式的特征增强,从而提供更多多样性的特征增强,适用于DG应用。
这种方法在多个AST和DG任务中取得了新的最先进的效果,并具有高效性。它通过提供更稳定的样式迁移图像和更多多样性的特征增强,为计算机视觉任务带来了明显的改进。
3. Methodology
3.1. AdaIN, HM and EHM
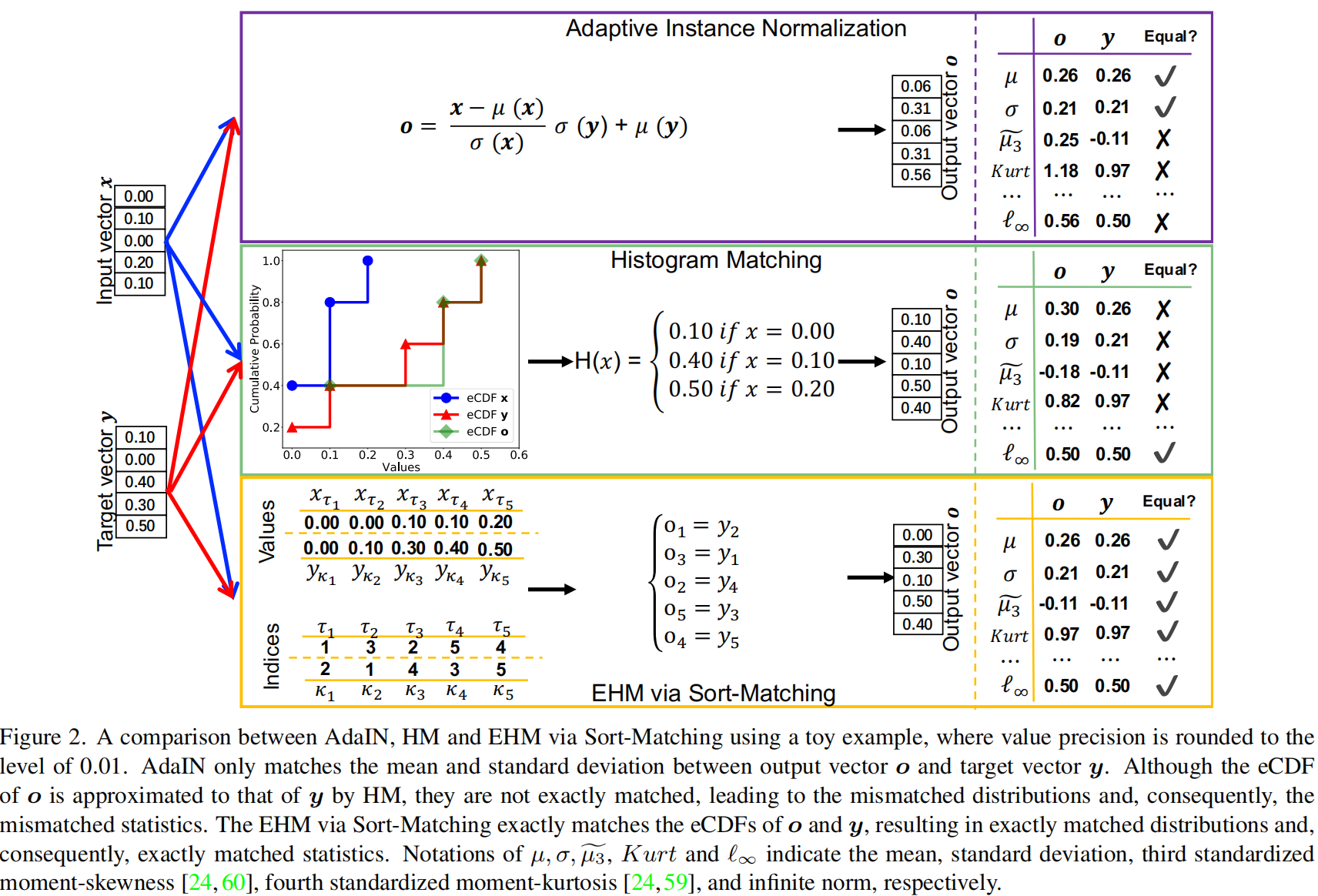
Adaptive instance normalization (AdaIN) [21]将从随机变量\(X\)中采样的输入向量\(\boldsymbol{x} \in \mathbb{R}^n\) 转换为一个输出向量\(\boldsymbol{o} \in \mathbb{R}^n\),其均值和标准差与从随机变量\(Y\)中采样的目标向量\(\boldsymbol{y} \in \mathbb{R}^m\) 的均值和标准差相匹配:
其中\(\mu(\cdot)\) 和 \(\sigma(\cdot)\) 分别表示所涉及数据的均值和标准差。假设\(X\)和\(Y\)遵循高斯分布,而\(n\)和\(m\)趋向于无穷大,AdaIN可以通过匹配特征的均值和标准差来实现EFDM [32,37,41]。然而,实际数据的特征分布通常远离高斯分布,如图1所示。因此,通过AdaIN来匹配特征分布的准确性较低。
Histogram matching (HM) \([16,58]\) 的目标是将输入向量\(\boldsymbol{x}\) 转换为一个输出向量\(\boldsymbol{o}\),使其经验累积分布函数(eCDF)与目标向量\(\boldsymbol{y}\) 的eCDF相匹配。\(\boldsymbol{x}\) 和 \(\boldsymbol{y}\) 的eCDF定义如下:
其中\(\mathbf{1}_A\) 是事件\(A\)的指示符,\(x_i\)(或\(y_i\))是\(\boldsymbol{x}\)(或\(\boldsymbol{y}\))的第\(i\)个元素。对于输入向量\(\boldsymbol{x}\) 的每个元素\(x_i\),我们找到满足\(\widehat{F}_X\left(x_i\right)=\widehat{F}_Y\left(y_j\right)\)的\(y_j\),从而得到转换函数:\(H\left(x_i\right)=y_j\)。值得一提的是,匹配eCDF等同于匹配无穷小宽度的直方图条,但由于用于表示特征的位数有限,难以实现这种匹配。
理想情况下,HM在连续情况下可以完全匹配图像特征的eCDF。不幸的是,当输入中存在等效特征值时,HM只能近似匹配eCDF,因为HM将等效值合并为单个点并应用逐点转换(请参考图2中的示例)。
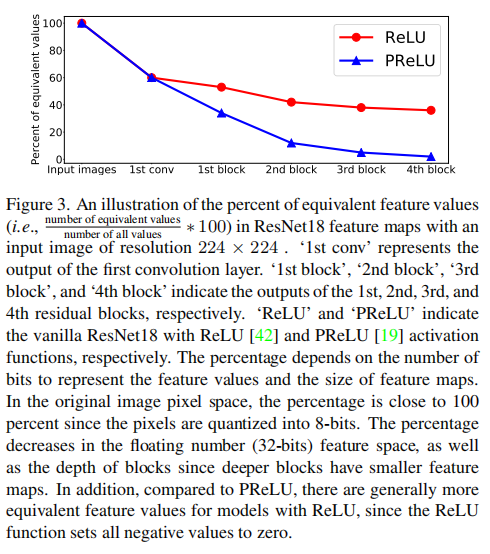
对于由深度模型生成的特征来说,由于它们依赖于离散的图像像素和激活函数的使用,例如ReLU [42] 和 ReLU6 [26],等效特征值是常见的(请参考图3以获取更多详细信息)。所有这些事实都妨碍了通过HM实现EFDM的有效性。
Exact Histogram Matching (EHM) \([7,18]\) 旨在完全匹配图像像素的直方图。与HM不同,EHM算法区分等效像素值并应用逐元素转换,从而可以实现更准确的直方图匹配。我们采用了Sort-Matching算法 [47],通过匹配两个已排序的向量实现,其索引用一行符号 [2] 表示如下:
其中\(\left\{x_{\tau_i}\right\}_{i=1}^n\) 和 \(\left\{y_{\kappa_i}\right\}_{i=1}^n\) 是按升序排列的\(\boldsymbol{x}\) 和\(\boldsymbol{y}\) 的值。换句话说,\(x_{\tau_1}=\min (x)\),\(x_{\tau_n}=\) \(\max (\boldsymbol{x})\),并且如果\(i<j\),则\(x_{\tau_i} \leq x_{\tau_j}\),\(y_{\kappa_i}\) 也是类似定义的。根据等式(3)中的定义,Sort-Matching输出\(\boldsymbol{o}\),其\(\tau_i\)-th元素\(o_{\tau_i}\)如下:
简而言之,就是 \(x\) 中第 \(i\) 小的元素替换成 \(y\) 中第 \(i\) 小的元素
与AdaIN、HM和其他EHM算法[7, 18]相比,Sort-Matching还假设要匹配的两个向量具有相同的大小,即\(m=n\),这在我们关注的AST和DG应用中得到满足。在其他应用中,如果要匹配的两个向量大小不同,可以进行插值或丢弃元素以使\(y\)和\(x\)的大小相同。
3.2. EFDM for AST and DG
在本节中,我们将EFDM应用于AST和DG的任务。我们通过在图像特征空间中使用Sort-Matching的EHM算法来进行精确的eCDF匹配。为了在深度模型中进行梯度反向传播,我们通过修改等式(4)来实际执行EFDM,如下所示:
其中\(\langle\cdot\rangle\) 表示停止梯度操作 [6]。我们停止了梯度传播到样式特征\(y_{\kappa_i}\),这遵循了文献\([21,72]\)的做法。给定输入数据\(\boldsymbol{X} \in \mathbb{R}^{B \times C \times H W}\) 和样式数据\(\boldsymbol{Y} \in \mathbb{R}^{B \times C \times H W}\),我们按通道方式应用EFDM,其中\(B, C, H, W\) 分别表示批大小、通道维度、高度和宽度。
所提出的EFDM不引入任何参数,可以以插拔方式使用,只需几行代码和最小的成本,如算法1所总结的。

EFDM for AST
在这个架构中,我们采用了一个简单的编码器-解码器架构,其中我们将编码器\(f\) 固定为预训练的VGG-19 [51]的前几层(直到relu4_1)。给定内容图像\(\boldsymbol{X}\) 和样式图像\(\boldsymbol{Y}\),我们首先将它们编码到特征空间,然后应用EFDM以获得样式迁移后的特征,如下:
然后,我们训练一个随机初始化的解码器\(g\),将\(\boldsymbol{S}\) 映射到图像空间,得到风格化图像\(g(\boldsymbol{S})\)。根据[10,21],我们使用内容损失\(\mathcal{L}_c\)和样式损失\(\mathcal{L}_s\)的加权组合来训练解码器,从而得到以下目标函数:
其中\(\omega\)是平衡两个损失项的超参数。
具体而言,内容损失\(\mathcal{L}_c\)是风格化图像\(f(g(\boldsymbol{S}))\) 特征和样式迁移后的特征\(\boldsymbol{S}\) 之间的欧几里得距离:
样式损失\(\mathcal{L}_s\)度量了风格化图像\(g(\boldsymbol{S})\) 特征和样式图像\(\boldsymbol{Y}\) 之间的分布差异,它是风格化图像\(\phi_i(g(\boldsymbol{S}))\) 特征和其样式迁移目标\(\operatorname{EFDM}\left(\phi_i(g(\boldsymbol{S})), \phi_i(\boldsymbol{Y})\right)\) 之间的欧几里得距离之和,如下:
根据[21],我们将\(\left\{\phi_i\right\}_{i=1}^L\) 实例化为VGG-19中的relu1_1、relu2_1、relu3_1和relu4_1层。
EFDM for DG.
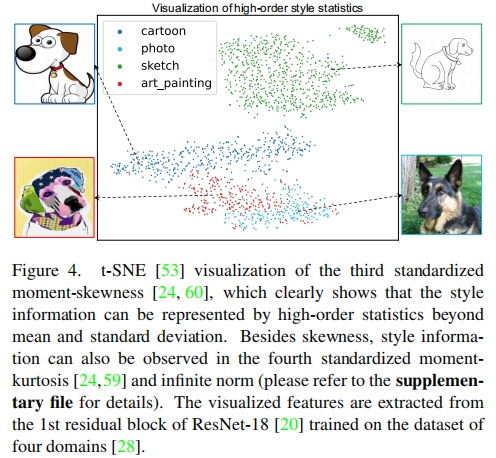
受到研究启发,即样式信息可以通过图像特征的均值和标准差来表示[21,33,37],Zhou等人[72]提出了为DG问题生成样式转移和内容保留特征增强的方法。如前所讨论,高斯以外的分布具有高阶统计量,而不是均值和标准差,因此可以更准确地使用高阶特征统计来表示样式信息。图4中的可视化演示了 third standardized moment-skewness\([24,60]\)可以很好地表示相同对象的四个不同领域。这激发了我们利用高阶统计量进行特征增强。
由于高阶特征统计可以通过我们提出的EFDM方法高效而隐式地匹配,因此将AdaIN替换为EFDM以进行DG中的跨分布特征增强是一个自然的想法。为了生成更多具有混合样式的特征增强,我们遵循[72],通过插值排序的向量扩展等式(5)中的EFDM,得到了精确特征分布混合(EFDMix),如下:
我们采用基于Beta分布的采样来确定每个实例的混合权重\(\lambda\):\(\lambda \sim \operatorname{Beta}(\alpha, \alpha)\),其中\(\alpha \in(0, \infty)\)是一个超参数。除非另有说明,我们设置\(\alpha=0.1\)。显然,当\(\lambda=0\)时,EFDMix退化为EFDM。
4. Experiments
4.1. Experiments on AST
We closely follow [21] to conduct the experiments \({ }^1\) on AST. Specifically, we adopt the adam optimizer, set the batch size as 8 content-style image pairs, and set the hyperparameter \(\omega=10\). In training, the MS-COCO [35] and WikiArt [44] are adopted as the content and style images, respectively. We compare EFDM with state-of-the-arts in Fig. 5. One can see that our EFDM works stably across the style transfer (top two rows) and the more challenging photo-realistic style transfer (bottom two rows) tasks. By conducting feature distribution matching more exactly, it preserves more faithfully the image structures and details while transferring the style, and produces more photorealistic results. In contrary, the competing methods may introduce many visual artifacts and image distortions. More visual results can be found in the supplementary file.
4.1. AST实验
Content-style trade-off in the test stage.
内容和样式之间的权衡可以通过调整等式(7)中的超参数\(\omega\)来实现。此外,我们还可以通过在内容特征和样式特征之间插值来操纵内容-样式权衡,这可以通过等式(10)中的EFDMix来实现。当\(\lambda=1\)时,预期得到普通的内容图像,而当\(\lambda=0\)时,模型将输出最风格化的图像。我们在图6中举了一个例子。我们可以看到,通过从1变化到0来调整\(\lambda\),图像会平滑地从内容样式过渡到目标样式。

Style interpolation
根据[21],我们插值特征图以插值\(K\)个样式图像\(\boldsymbol{Y}_1, \boldsymbol{Y}_2, \cdots, \boldsymbol{Y}_K\),对应的权重为\(w_1, w_2, \cdots, w_K\),如下所示:
其中\(\sum_{k=1}^K w_k=1\)。如图7所示,可以通过这种样式插值来获得新的样式。

4.2. Experiments on DG
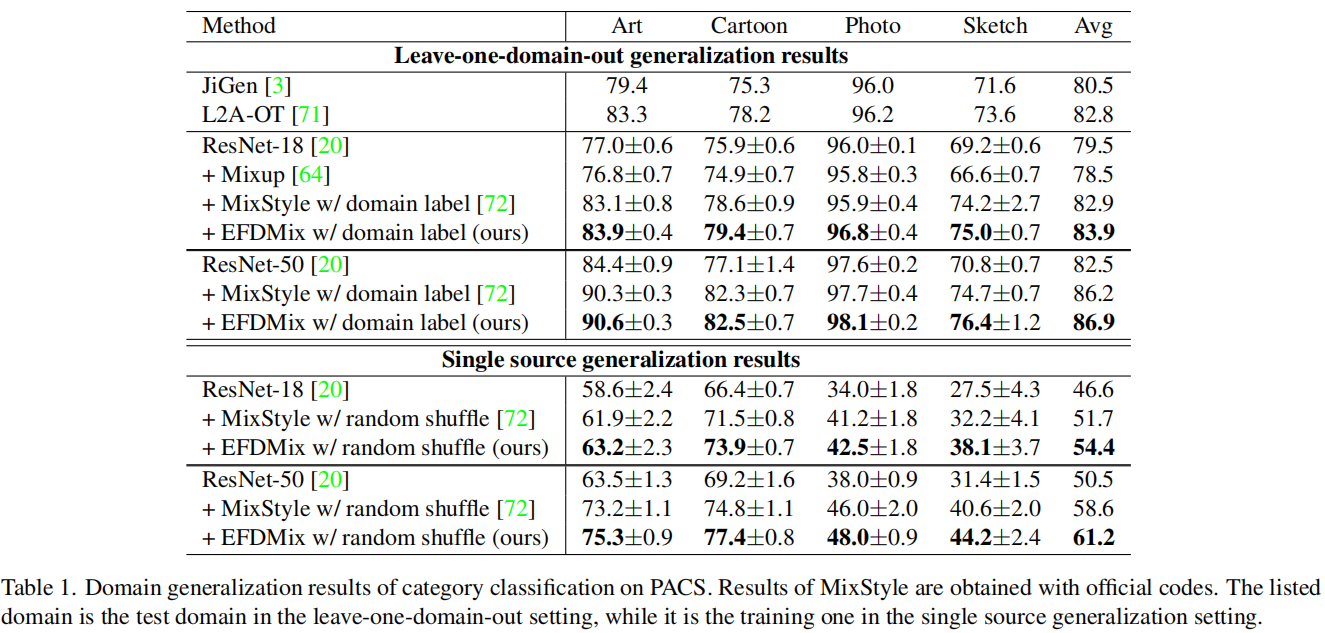
Generalization on category classification
在“leave-one-domain-out”设置中[28],我们在三个领域上训练模型,然后在剩下的一个领域上进行测试。在 single source DG [45, 56]中,模型在一个领域上进行训练,然后在剩下的三个领域上进行测试。
Generalization on instance retrieval

4.3. Discussions
The role of different orders of feature statistics
为了进一步研究不同特征统计阶数的作用,我们实现了只匹配特征均值和标准差的AdaIN,得到了其AdaMean和AdaStd变种(详细信息请参见补充文件)。图8展示了AST上的定性结果,图9展示了DG上的定量结果。

从图8中,我们可以看到,AdaMean大致匹配了基本色调。AdaStd保留了内容图像的结构,但颜色偏差。通过同时匹配均值和标准差,AdaIN保留了更多的细节和正确的色调。通过隐式匹配高阶特征统计,EFDM保留了最多的内容细节。
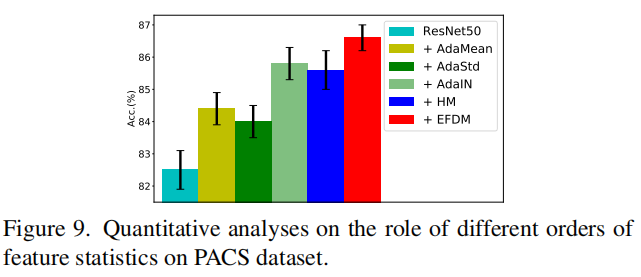
从图9中,我们可以看到,使用AdaMean或AdaStd进行特征增强可以提高ResNet-50基线的性能,其中AdaMean表现略好一些。AdaIN在精度上优于AdaMean和AdaStd超过1%,证明了利用更多特征统计的有效性。通过隐式匹配高阶特征统计,EFDM实现了最佳结果。尽管HM大致匹配了eCDFs,但它甚至不能确保均值和标准差的精确匹配,导致性能退化。
User study on style transfer.
如表3所示,我们的方法在competing AST方法中获得了最多的票数,因为它在风格化性能上表现更好。

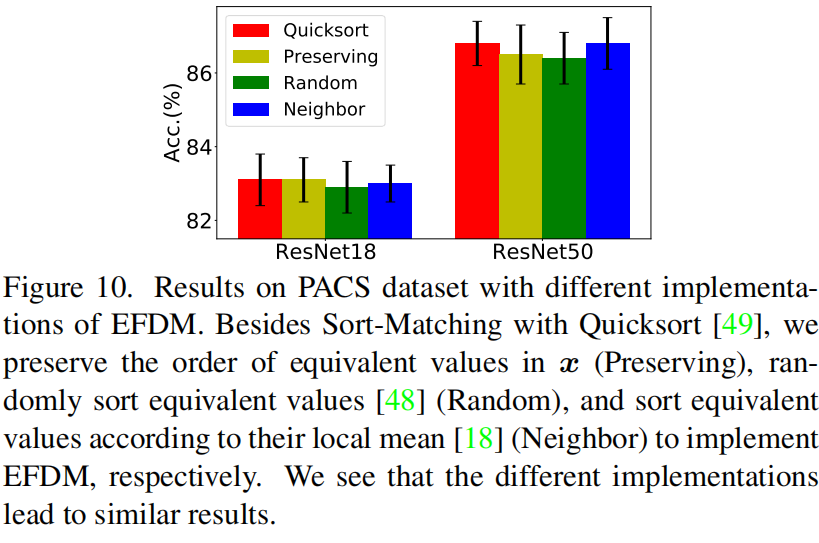
EFDM with different EHM algorithms
不同的EHM算法通过它们等效值的排序策略来区分。在图10中,我们在DG任务中使用不同的EHM算法来实现EFDM。可以看到它们在PACS数据集上产生类似的准确性。考虑到快速排序(quicksort)算法具有最快的速度,我们在我们的工作中采用了Sort-Matching算法。
Running time
运行时间。我们在AST任务上评估了EFDM方法的速度。处理一张512×512的图像的不同算法的平均运行时间列在表3中。
Limitations
与AdaIN [21]相比,EFDM的复杂度较高,为n log(n)。幸运的是,由于特征的有限大小,它在AST和DG任务上的运行时间与AdaIN相当。此外,根据[21,25,72],我们假设不同的特征通道是独立的,尽管这并不完全准确,并受到[33, 37]的质疑。
- Generalization Distribution Arbitrary Matching Transfergeneralization distribution arbitrary matching pandas distribution matching python distribution tb-nightly diffusion matching distribution matching问题found arbitrary generalization scale-arbitrary arbitrary-styled arbitrary 168b arc nim generalization contrastive proxy-based pcl