分类问题
分类问题和回归问题的区别是:分类问题的值域是离散的。
- 线性回归不能应用于分类问题。
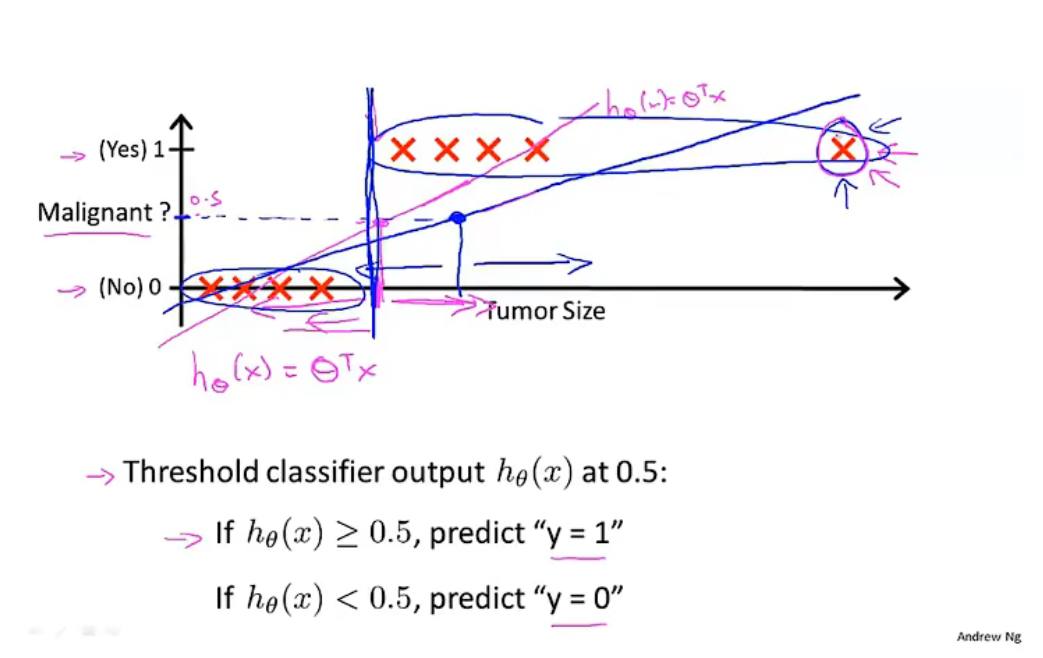
- 逻辑回归模型
(此处为一元分类问题)
预测函数:
其中:
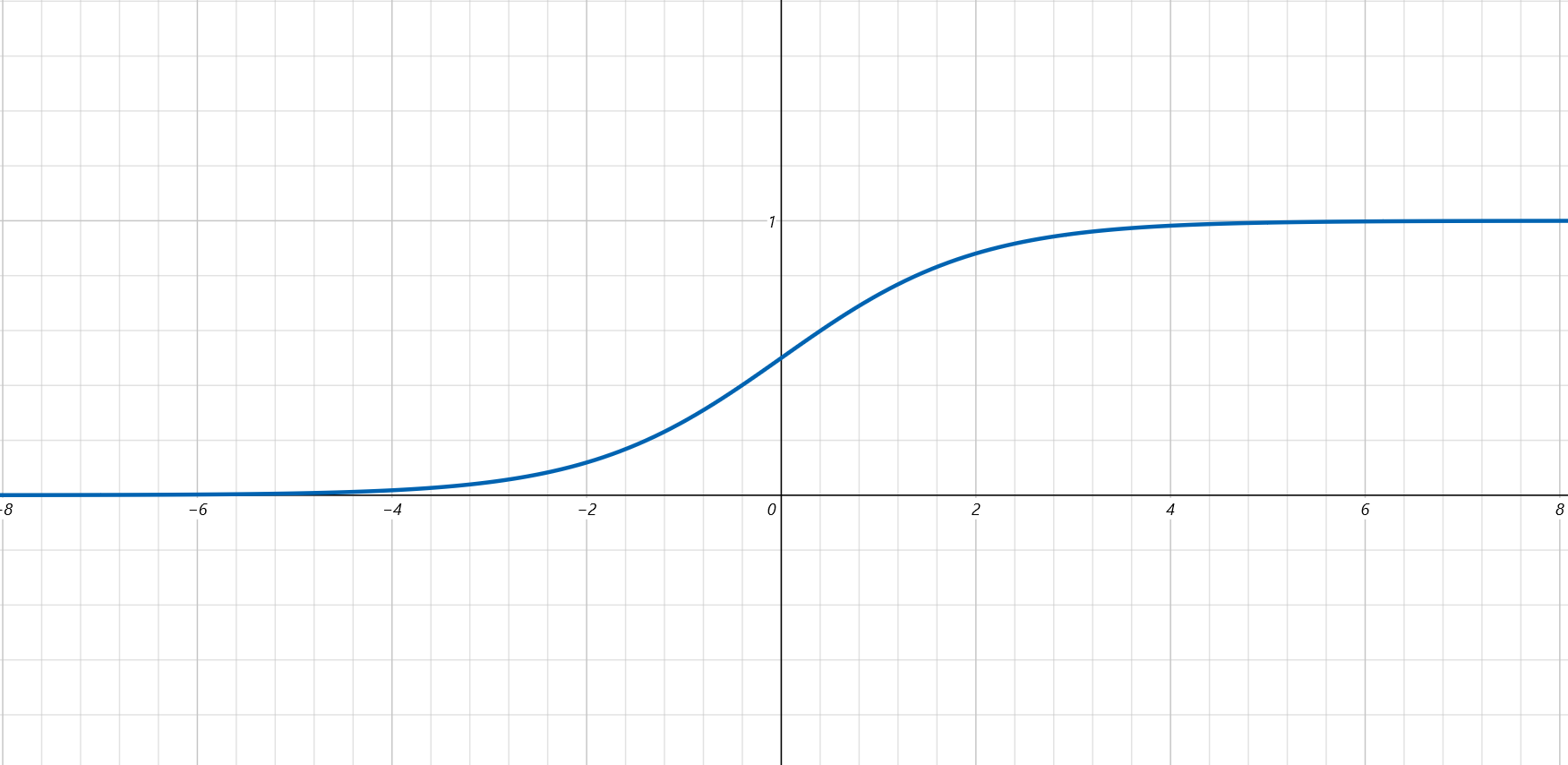
能够使得:
预测函数的函数值:
决策界限
\(y=1\ \ or\ \ 0\) 取决于 \(h_\theta(x)\ge0.5\ \ or\ \ h_\theta(x)<0.5\) ,此处的 \(h_\theta(x)=0.5\) 即为决策界限。
将其可视化后,表现为线性界限将空间分为不同类型。
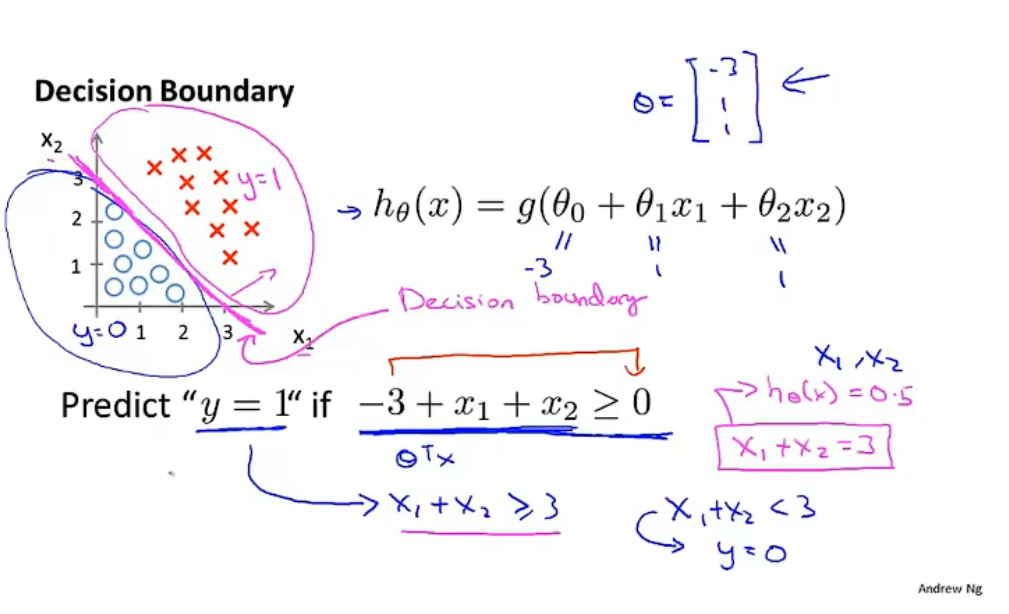
决策边界由参数 \(\theta\) 确定。参数 \(\theta\) 使用训练集来拟合。
预测函数使用高阶多项式可以得到非线性决策边界。

拟合
代价函数: \(J(\theta) = \frac{1}{m}\Sigma_{i=1}^mcost(h_\theta(x),y)\)
在线性回归问题中,\(cost(h_\theta(x),y)=\frac{1}{2}(h_\theta(x)-y)^2\),其中的\(h_\theta(x)\)是线性的,因此\(cost()\)函数是凸函数,使用梯度下降即可求得全局最小值。
而在逻辑回归问题中,\(h_\theta(x)=\frac{1}{1+e^{-\theta^Tx}}\)是非线性的,因此\(cost()\)函数不是凸函数,使用梯度下降只能求得局部最小值,无法确认是否是全局最小值。
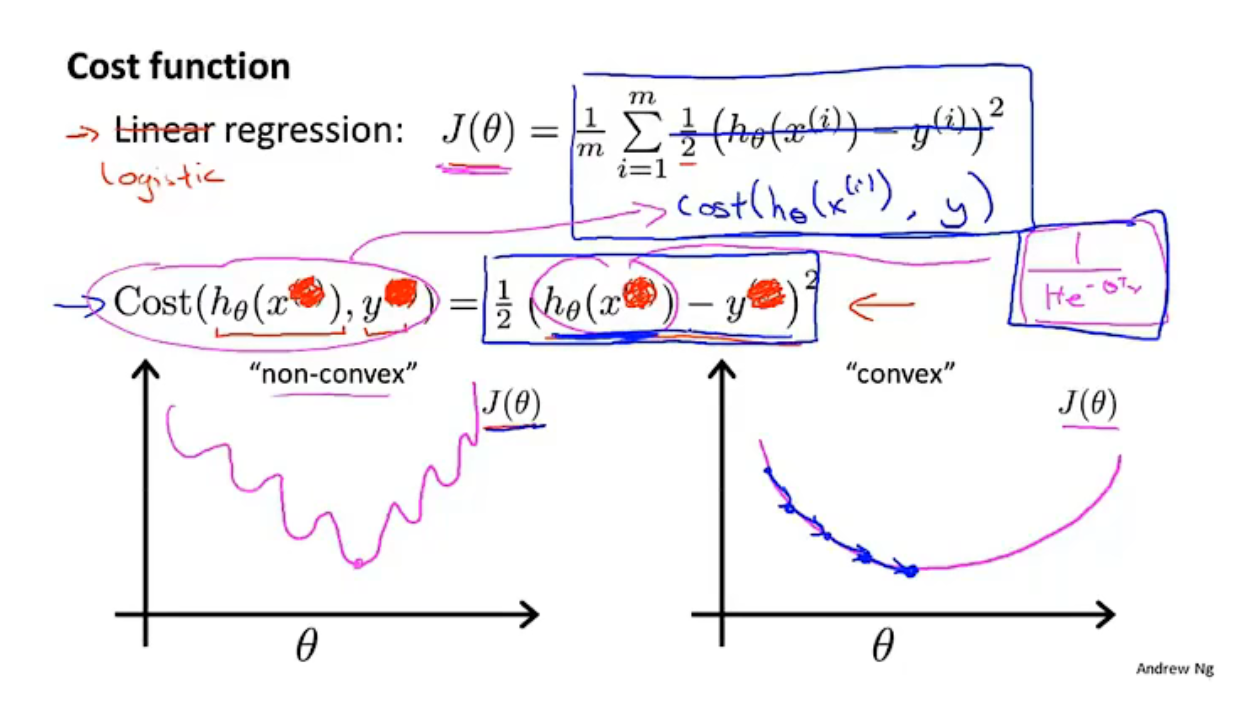
代价函数
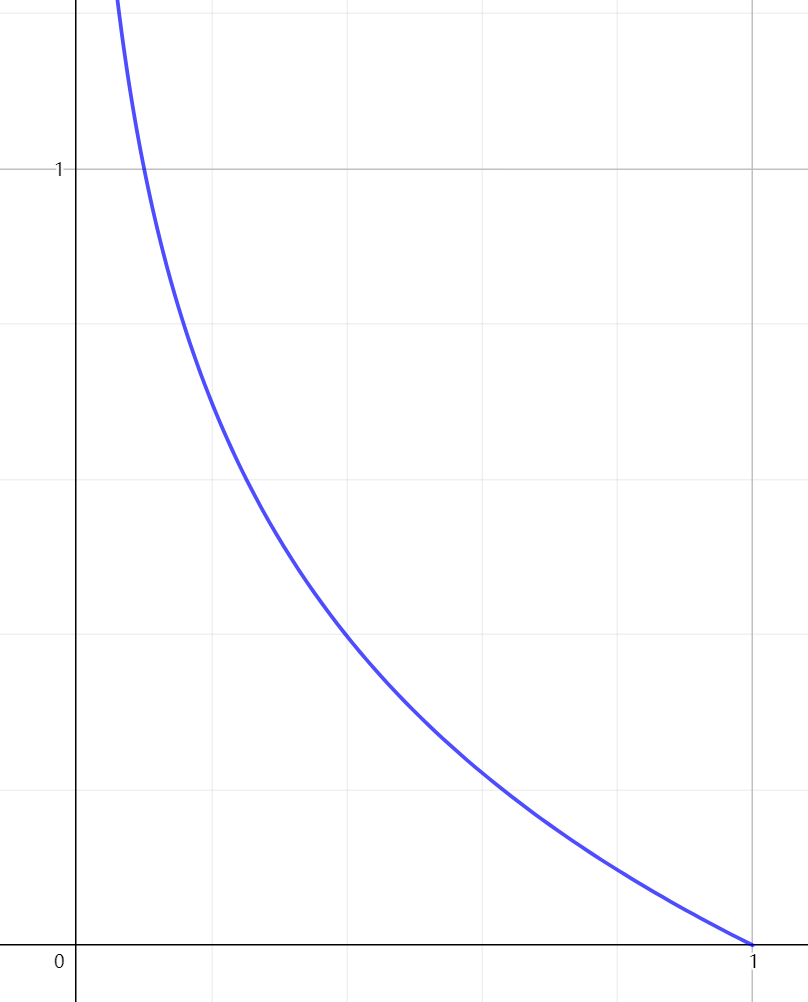
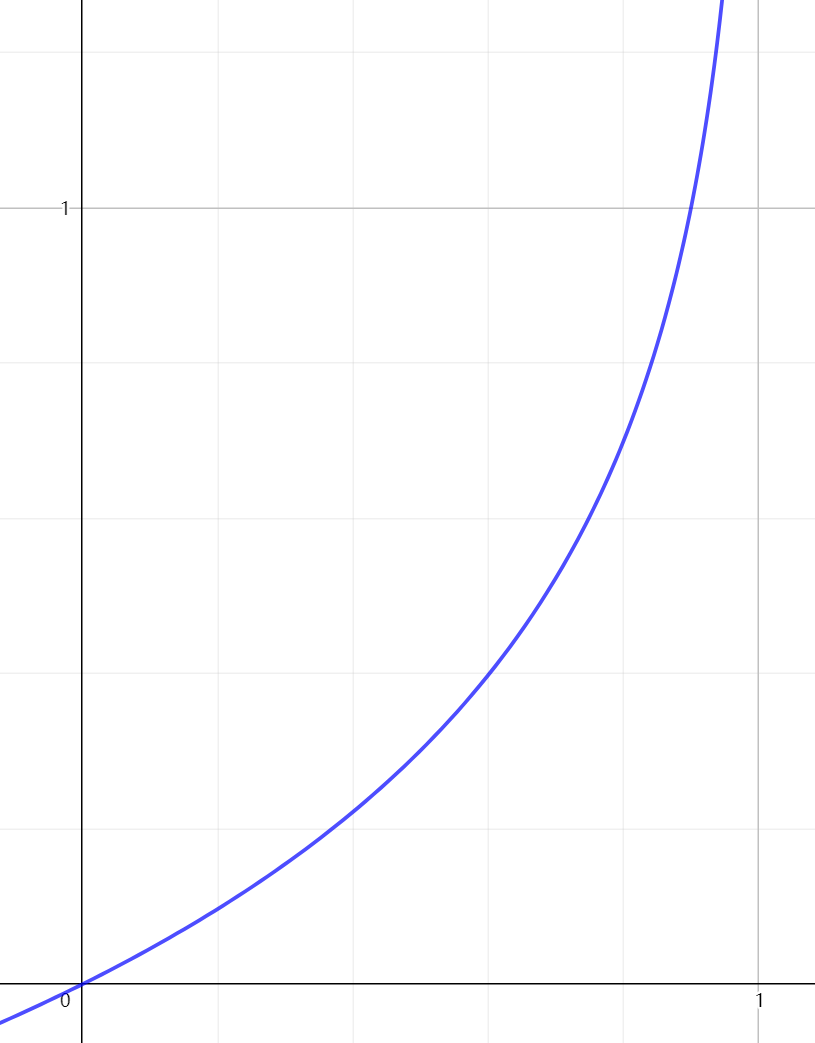
这个函数取自统计学中的极大似然法
对于\(y=1\)的情况来说:
- 如果\(x\rightarrow1\),那么表示猜测效果好,代价很低,\(cost\rightarrow0\).
- 如果\(x\rightarrow0\),那么表示猜测效果很差,代价很高,趋近于\(\infty\),以此来“惩罚”算法。
由于\(y\)的取值只有0和1两种情况,可以考虑合并:
- 代价函数:
-
目标:求解使得\(\mathop{min}\limits_\theta J(\theta)\)的 \(\theta\).
-
求解方法:使用梯度下降迭代 \(\theta\),使其不断趋近于最小值点。
多类别分类问题
-
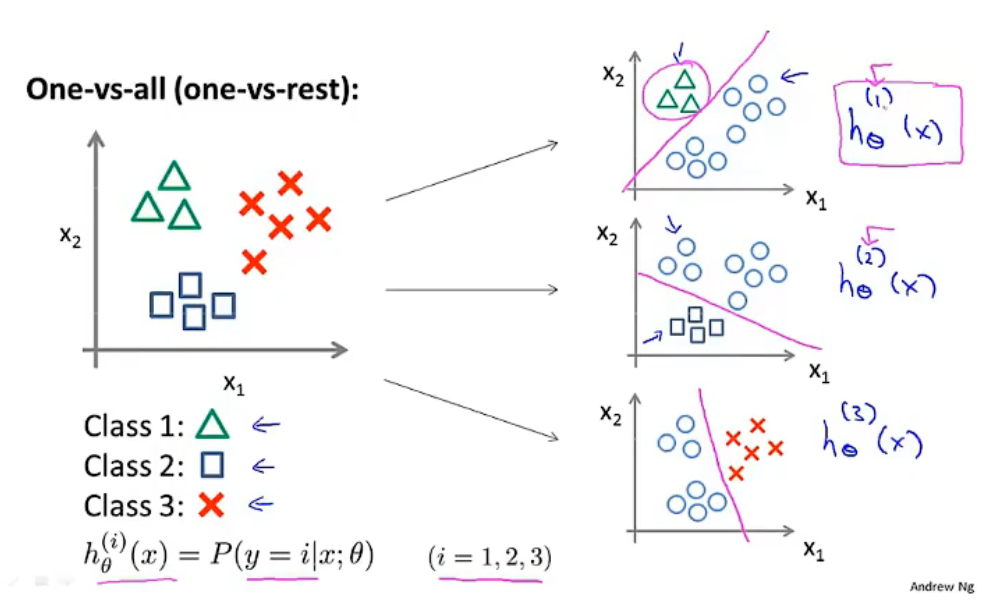
多类别分类问题可以分解为“一对余”方法。
-
将 \(n\) 类别分类问题,分解为 \(k\) 个二元分类问题,得到 \(k\) 个预测模型 \(h_\theta^{(i)}(x)=p(y=i\ | \ x;\ \theta)\),其中: \(i=(1,2,3,...,k)\) .
-
最终预测:
- 在 \(k\) 个预测模型中输入 \(x\);
- 选择一个使得 \(h_\theta^{(i)}(x)\)最大的 \(i\) ;
- 则 \(h_\theta^{(i)}(x)\) 为最终的预测结果。