1.安装JDK
https://www.cnblogs.com/whiteY/p/13332708.html
2.安装hadoop2.7
下载hadoop2.7.1安装包
链接: https://pan.baidu.com/s/1saGhaKbcvwrE4P3F5_UhZQ
提取码: 1234
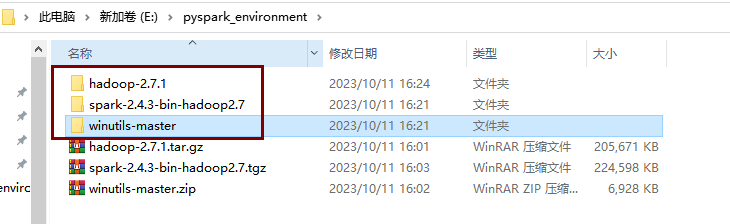
解压到指定位置
3.下载winutils
链接: https://pan.baidu.com/s/1L1iRZQcmaw9voQEJzO4bmA
提取码: 1234
解压到指定位置
下载完成后找到相应的Hadoop版本,这里我们安装的是2.7.1
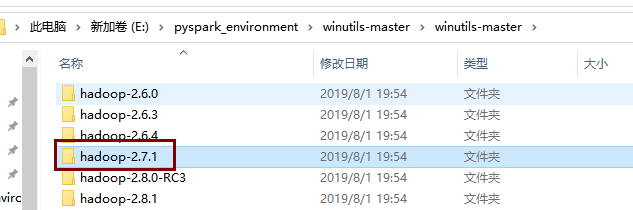
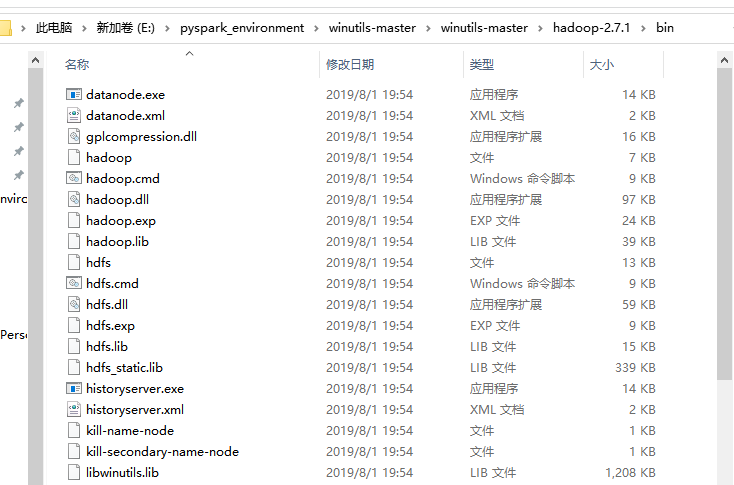
进入该目录,将bin目录下的所有内容复制,粘贴到Hadoop安装目录的bin目录下,添加或替换一些文件
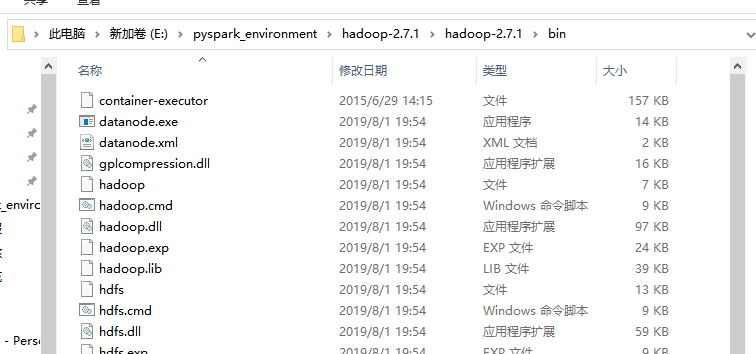
配置Hadoop环境变量
首先配置HADOOP_HOME
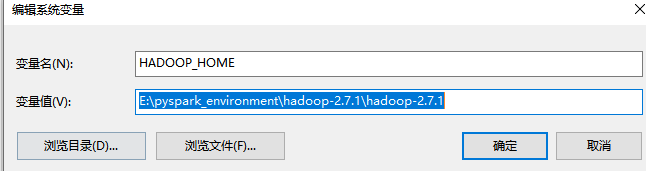
然后配置Path,点击新建,浏览Hadoop目录

修改hadoop.env.cmd文件JAVA_HOME
打开Hadoop安装目录,我的是E:\pyspark_environment\hadoop-2.7.1\hadoop-2.7.1\etc\hadoop
找到hadoop.env.cmd文件,用记事本打开,修改下面的内容,可以使用相对路径,也可以使用绝对路径,这里使用绝对路径。
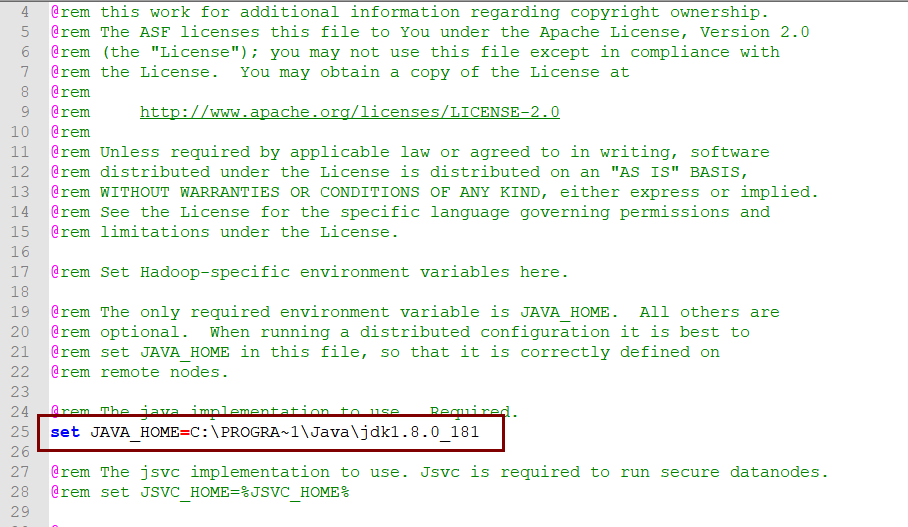
由于默认的jdk目录Program Files 有空格,所以修改为以上内容,点击保存。
4.安装python3.6
由于版本问题,使用Hadoop2.7和spark2.4版本只能使用python3.6,所以需要安装python3.6
下载路径
https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/
安装步骤
https://zhuanlan.zhihu.com/p/511233749
配置环境变量
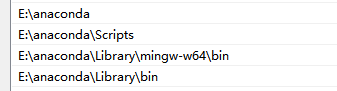
创建虚拟环境并激活
conda create -n pyspark3.6 python=3.6
conda activate pyspark3.6
激活虚拟环境报错指南
https://blog.csdn.net/Pang_Yue__Fairy/article/details/103803645
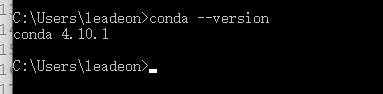
测试
conda --version
设置清华镜像
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/bioconda/
5.下载spark
解压到指定位置
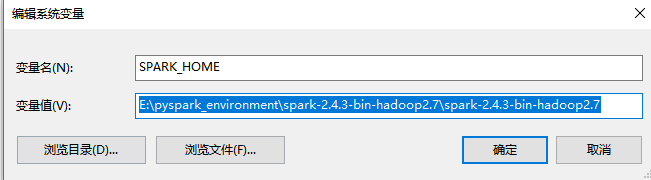
配置环境变量
同之前一样,需要配置SPARK_HOME和Path

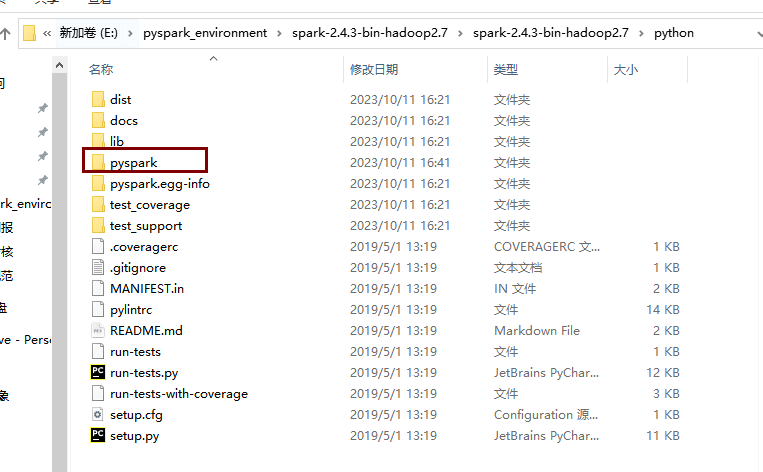
拷贝pyspark
进入spark安装目录,我的是E:\pyspark_environment\spark-2.4.3-bin-hadoop2.7\spark-2.4.3-bin-hadoop2.7\python
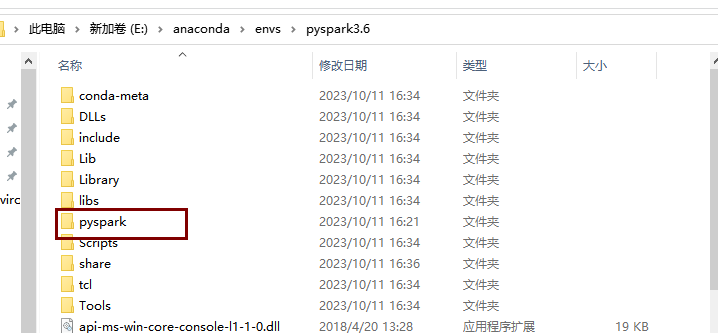
将pyspark复制到Anaconda下的pyspark3.6目录下,我的是E:\anaconda\envs\pyspark3.6
6.安装py4j
在cmd进入scripts目录,我的是E:\anaconda\envs\pyspark3.6\Scripts,安装py4j
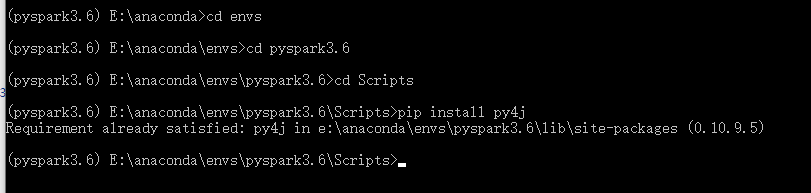
7.测试pyspark环境
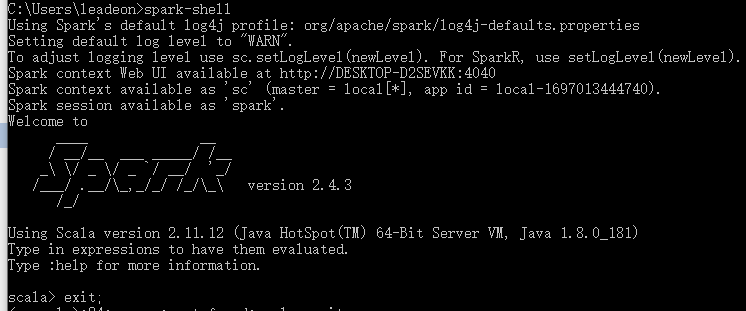
打开cmd,输入spark-shell,出现以下内容说明配置成功。
或者打开pyspark
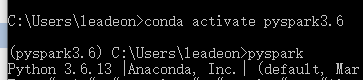
这里注意,首先要进行python版本切换,即切换到之前提到过的pyspark3.6环境
输入activate 环境名 ,可以看到左边有个括号,里面显示pyspark3.6,这就表明进入了3.6的环境
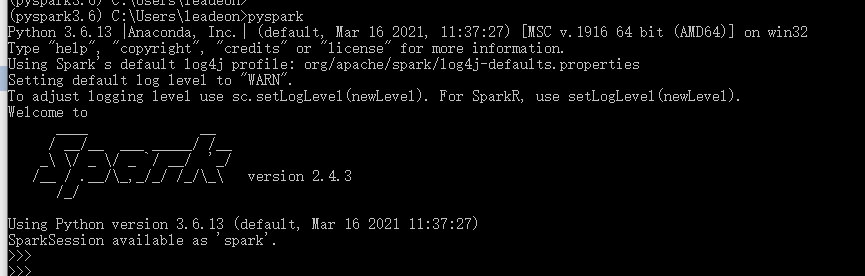
直接输入pyspark
8、PyCharm配置
创建项目
PyCharm的配置很简单,首先新建一个项目
起好名字之后,选择interpreter,这里选择Existing interpreter
找到pyspark3.6中的python.exe
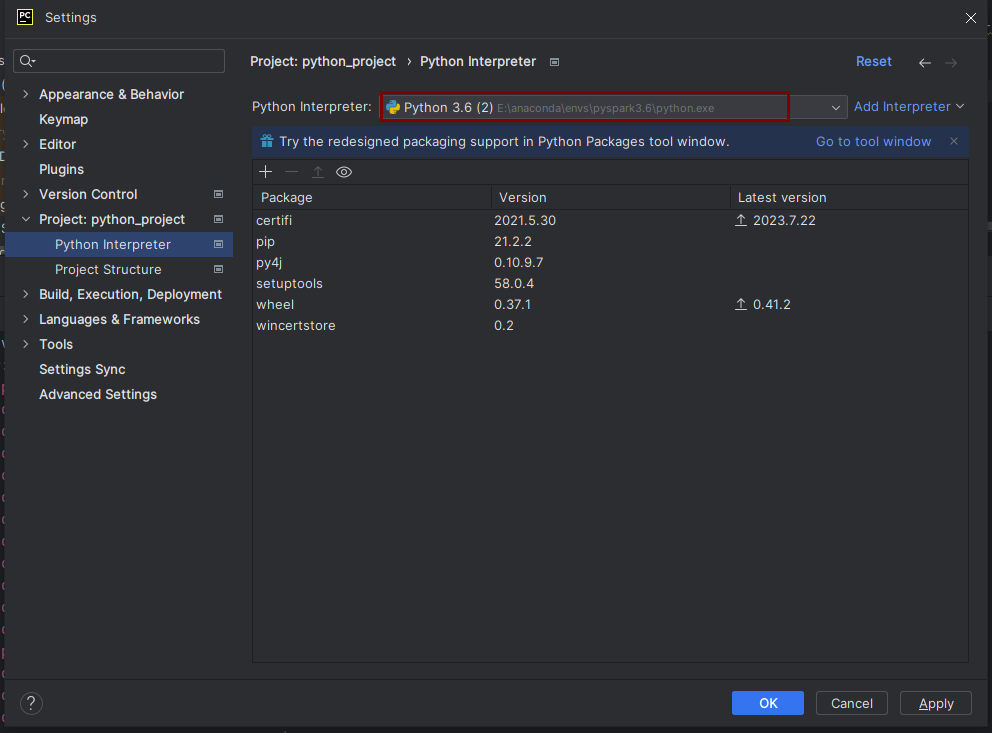
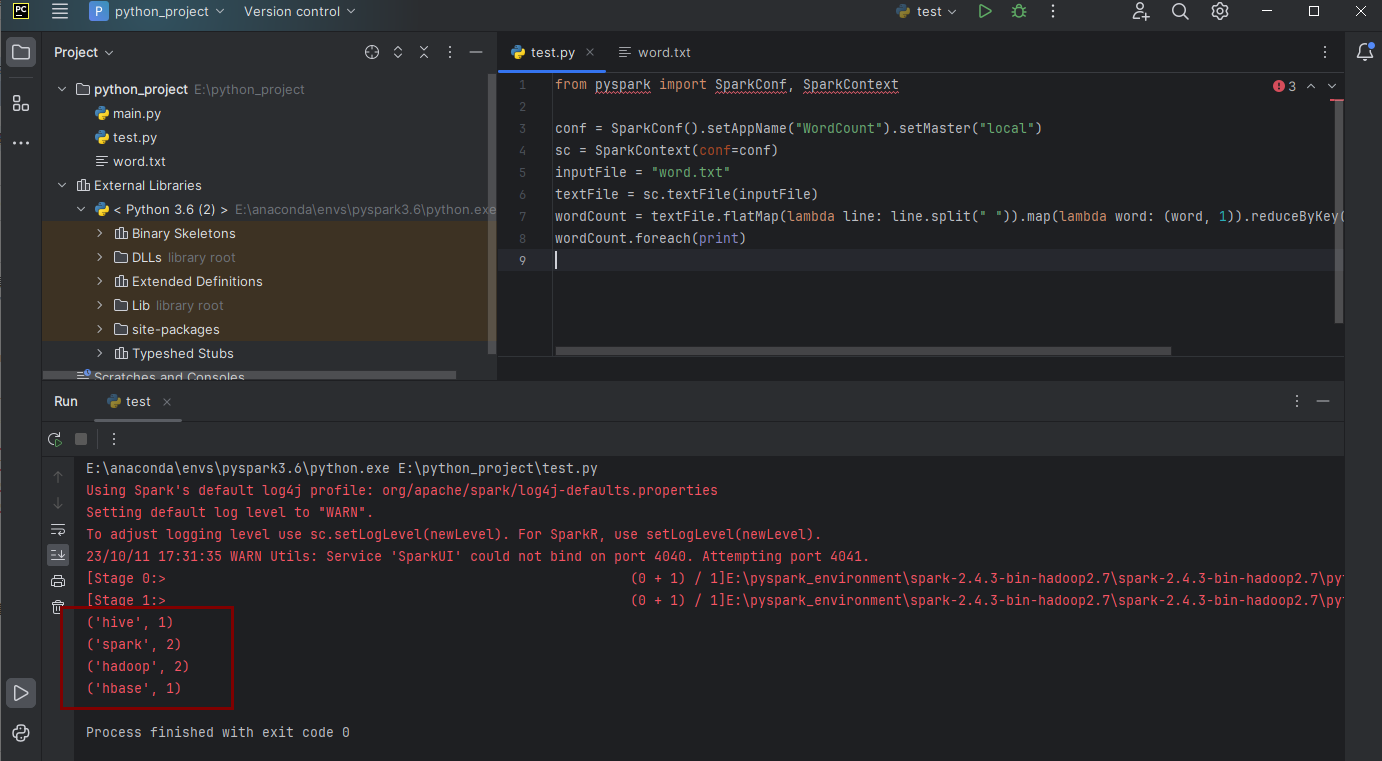
测试代码(单词计数)
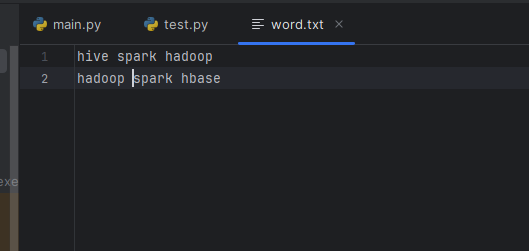
新建一个word.txt文件,里面随便写几个单词,用空格分隔
新建一个python文件,输入如下代码
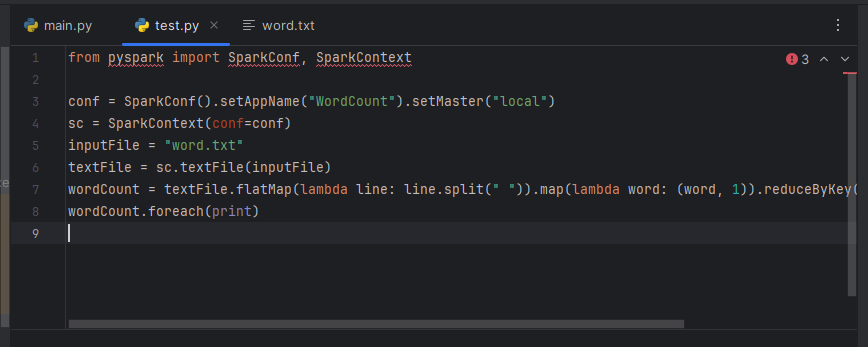
from pyspark import SparkConf, SparkContext
conf = SparkConf().setAppName("WordCount").setMaster("local")
sc = SparkContext(conf=conf)
inputFile = "word.txt"
textFile = sc.textFile(inputFile)
wordCount = textFile.flatMap(lambda line: line.split(" ")).map(lambda word: (word, 1)).reduceByKey(lambda a, b: a + b)
wordCount.foreach(print)
右键运行结果如下