1、需求:采集猫眼电影经典电影影片信息
url:https://www.maoyan.com/films?showType=3
采集页数 30104页
2、源代码如下:
import random import pandas as pd import requests from lxml import etree import time import re datas_list=[] def get_page(url): # 设置请求头agent池随机获取 user_agent = [ "Mozilla/5.0 (Windows NT 5.1; U; en; rv:1.8.1) Gecko/20061208 Firefox/2.0.0 Opera 9.50", "Mozilla/5.0 (X11; U; Linux x86_64; zh-CN; rv:1.9.2.10) Gecko/20100922 Ubuntu/10.10 (maverick) Firefox/3.6.10", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/534.57.2 (KHTML, like Gecko) Version/5.1.7 Safari/534.57.2 ", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.71 Safari/537.36", "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36", ] header = { 'User-Agent':random.choice(user_agent), 'Cookie': 'uuid_n_v=v1; uuid=F58B08108E8811EE8F3E256A4A5D3F84268F4EC985E54008A7FAD5729777B31D; _csrf=c2f335f74c72c574ea2cab362926d7f13e37452667ae6df65f00e2387a7814cc; Hm_lvt_703e94591e87be68cc8da0da7cbd0be2=1701242939; _lxsdk_cuid=18c19fb2782c8-0d194a29fe31fd-3e604809-144000-18c19fb2782c8; _lxsdk=F58B08108E8811EE8F3E256A4A5D3F84268F4EC985E54008A7FAD5729777B31D; Hm_lpvt_703e94591e87be68cc8da0da7cbd0be2=1701243410; __mta=147739912.1701243036257.1701243403227.1701243410264.16; _lxsdk_s=18c19fb2783-fcc-b7a-ba2%7C%7C42' } response = requests.get(url, headers=header) response.encoding="utf-8" cont=etree.HTML(response.content) if response.status_code == 200: response=response.text # print(response) # 电影titles titles=re.findall(r'<img class="movie-hover-img" src=".*?" alt="(.*?)" />',response,re.S) # # 电影评分(需字符串拼接) # fenshu1=re.findall(r'<span class="score channel-detail-orange"><i class="integer">(.*?)</i><i class="fraction">.*?</i></span>',response,re.S) # fenshu2=re.findall(r'<span class="score channel-detail-orange"><i class="integer">.*?</i><i class="fraction">(.*?)</i></span>',response,re.S) # fenshu3=re.findall(r'<div class="channel-detail channel-detail-orange">(.*?)</div>',response,re.S) # fenshu4=cont.xpath("//div[@class='channel-detail channel-detail-orange']") # print(fenshu4) # 电影类型(需去除空字符) types=re.findall(r'<span class="hover-tag">类型:</span>\n(.*?)\n.*?</div>',response,re.S) # 电影主演(需去除空字符) actors=re.findall(r'<span class="hover-tag">主演:</span>\n(.*?)\n.*?</div>',response,re.S) # 电影上映时间(需去除空字符) sy_times=re.findall(r'<span class="hover-tag">上映时间:</span>\n(.*?)\n.*?</div>',response,re.S) # 电影id # https://www.maoyan.com/films/1479147 电影超链接id拼接 ids=re.findall(r'<div class="movie-item-hover">.*?<a href="/films/(.*?)" target="_blank" data-act="movie-click" data-val="{movieid:.*?}">',response,re.S) for index, title in enumerate(titles): title = titles[index] type = types[index].strip() actor = actors[index].strip() sy_time = sy_times[index].strip() id = ids[index] url= f'https://www.maoyan.com/films/{id}' print(title+'---'+type+'---'+actor+'---'+sy_time+'---'+id+'---'+url) # fenshu = fenshu1[index]+fenshu2[index] # type = titles[index] # actor = titles[index].replace('','').replace('','') # if fenshu3[index] == '暂无评分': # fenshu = fenshu3[index] # else: # if index < len(fenshu1) and index < len(fenshu2): # fenshu = fenshu1[index] + fenshu2[index] # else: # print("Index out of range") # print(fenshu) data_dict = { '名称': [title], '类型': [type], '主演': [actor], '上映时间': [sy_time], 'id': [id], 'url': [url] } df = pd.DataFrame(data_dict) datas_list.append(df) # 合并所有数据DataFrame final_df = pd.concat(datas_list, ignore_index=True) # 保存到Excel文件 final_df.to_excel('猫眼电影经典电影信息采集.xlsx', index=False) time.sleep(1) return None # url = 'https://www.maoyan.com/films?showType=3&offset=0' # get_page(url) def main(): #总页数 for i in range(1,30104): print(f'---------------正在采集第{i}页数据---------------') m=(i-1)*30 url = f'https://www.maoyan.com/films?showType=3&offset={m}' html=get_page(url) time.sleep(1) main()
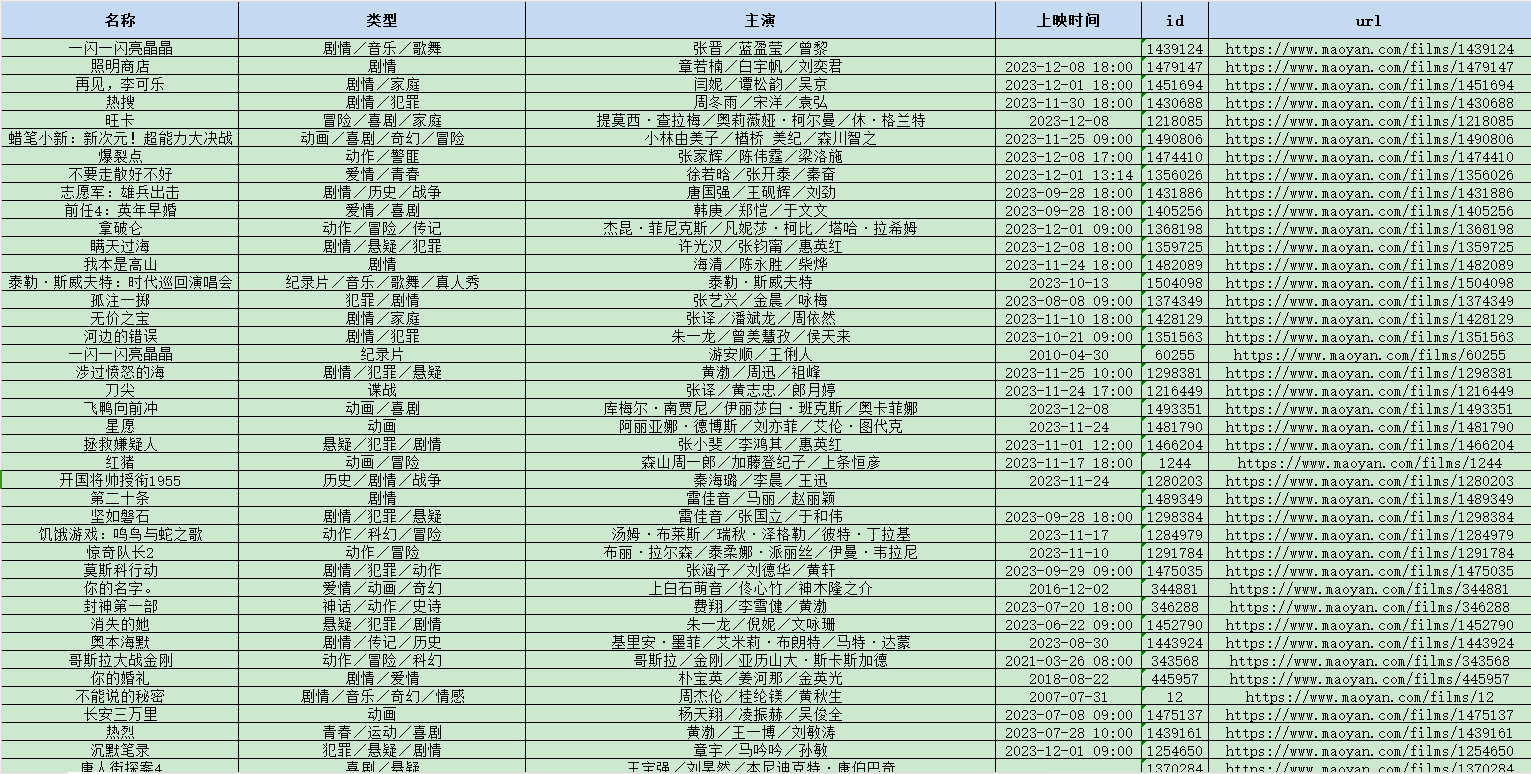
3、采集数据范例如下:
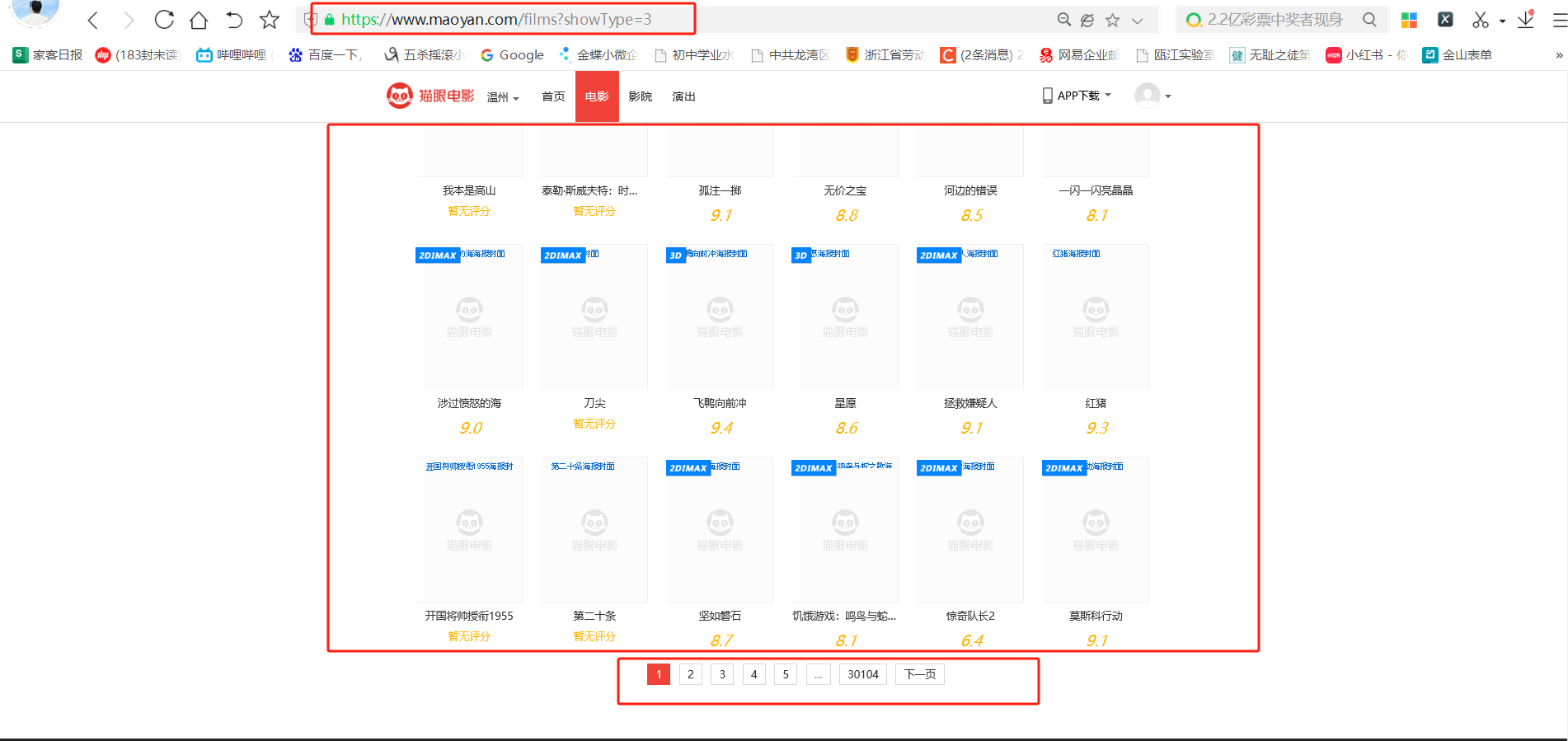
4、运行截图如下:

5、存储范例数据如下:
6、存在问题:
网站因为反爬,过多的请求就会出现滑动验证码的识别,导致数据请求中断,这边有考虑用代理ip,用免费的代理ip池随机请求去解决。