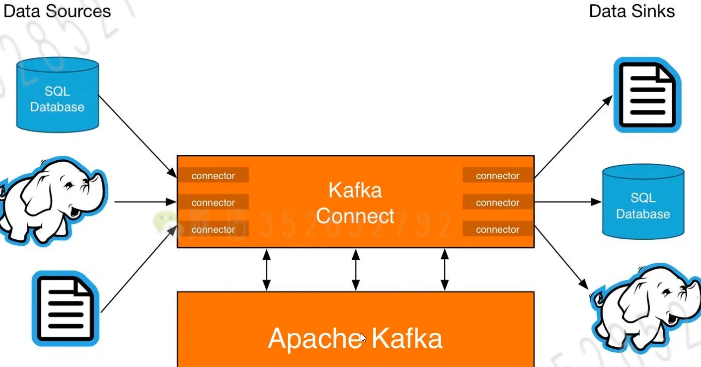
Connect基本概念
- Kafka Connect是Kafka流式计算的一部分
- Kafka Connect主要用来与其他中间件建立流式通道
- Kafka Connect支持流式和批量处理集成
环境准备
创建两个表
create table users_bak( `uuid` int primary key auto_increment, `name` VARCHAR(20), `age` INT ) create table users_bak( `uuid` int primary key auto_increment, `name` VARCHAR(20), `age` INT )
导入JDBC

安装unzip,并解压con
yum install -y unzip
将下面两个jar文件拷贝到解压后的包内
cp /opt/plugins/mysql-connector-java-*.jar ./
修改kafka配置文件(分别为集群版和单机版的配置文件,更改集群版)

更改以下内容
bootstrap.servers=192.168.75.136:9092
group.id=connect-cluster # 集群之间统一
# 默认JSON
key.converter=org.apache.kafka.connect.json.JsonConverter
value.converter=org.apache.kafka.connect.json.JsonConverter
# 打开rest.port
rest.port=8083
# 引入外部依赖
plugin.path=/opt/plugins
Kafka Connect Source 和 MySQL集成
操作命令
## connect启动命令
bin/connect-distributed.sh -daemon config/connect-distributed.properties
bin/connect-distributed.sh config/connect-distributed.properties
验证是否启动成功
# 输入网址,出现下图
http://192.168.75.136:8083/connector-plugins
# 查看connector
http://192.168.220.128:8083/connectors

Git Bash执行下列操作,添加一个topic
curl -X POST -H 'Content-Type: application/json' -i 'http://192.168.75.136:8083/connectors' \ --data \ '{"name":"upload-mysql","config":{ "connector.class":"io.confluent.connect.jdbc.JdbcSourceConnector", "connection.url":"jdbc:mysql://192.168.75.1:3306/kafka_study?user=root&password=root", "table.whitelist":"users", "incrementing.column.name": "uuid", "mode":"incrementing", "topic.prefix": "mysql-test-"}}'
# name:起名(唯一标识)
# connection.url:填数据库信息
# table.whitelist:白名单(哪些表被加载)
# incrementing.column.name:根据哪个字段判断是否是增量更新
# topic.prefix:topic前缀
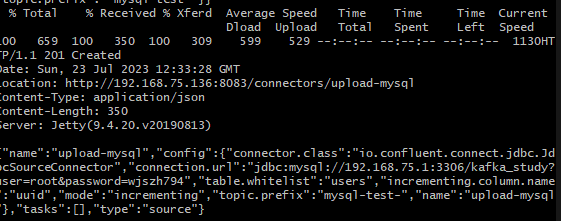
连接正常状态是201。无法连接的话需要配置一个拥有远程连接数据库权限的账号
create user 'root'@'%' identified with mysql_native_password by 'root'; ALTER USER 'root'@'%' IDENTIFIED BY 'root' PASSWORD EXPIRE NEVER; grant all privileges on *.* to 'root'@'%' with grant option; flush privileges;
然后刷新http://192.168.220.128:8083/connectors页面,得到以下结果

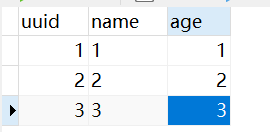
数据库插入数据
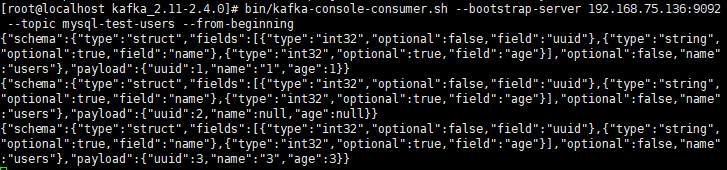
查看topic(从头开始读)
bin/kafka-console-consumer.sh --bootstrap-server 192.168.75.136:9092 --topic mysql-test-users --from-beginning
成功写入
Kafka Connect Sink 和 MySQL集成
消息如何从Kafka传递到数据库
name一定要与上面不同
curl -X POST -H 'Content-Type: application/json' -i 'http://192.168.75.136:8083/connectors' \ --data \ '{"name":"download-mysql","config":{ "connector.class":"io.confluent.connect.jdbc.JdbcSinkConnector", "connection.url":"jdbc:mysql://192.168.75.1:3306/kafka_study?user=root&password=root", "topics":"mysql-test-users", "auto.create":"false", "insert.mode": "upsert", "pk.mode":"record_value", "pk.fields":"uuid", "table.name.format": "users_bak"}}'
# topics表示从哪个topic读数据
# auto.create:是否自动创建表
成功
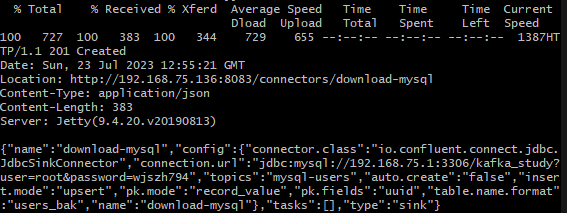
可以成功读入。第二行读入的是null,为什么会数据丢失不是很懂。

删除connect指令
curl -X DELETE http://192.168.75.136:8083/connectors/download-mysql
Kafka Connect关键词
Workers
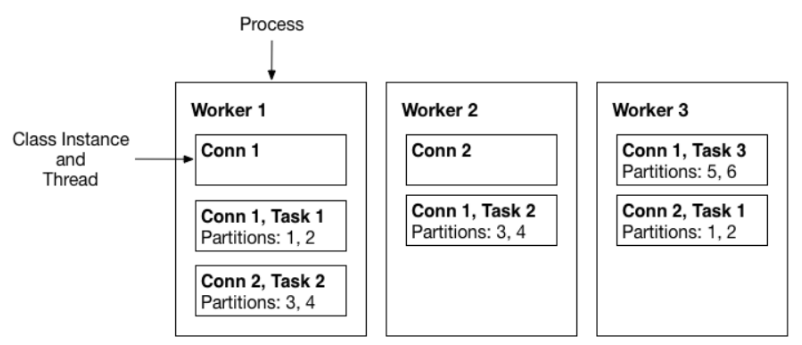
- 执行Connector和Task的运行进程。Connectors 和Task 属于逻辑单元,而Worker 是实际运行逻辑单元的进程。
- 两种模式:Standalone和Distributed
- Standalone Workers
Standalone模式是最简单的模式,用单一进程负责执行所有connector和task。适用于特定场景,如收集主机日志
-
- Distributed Workers
分布式模式为Kafka Connect提供了可扩展性和自动容错能力,使用更广。在分布式模式下,相同group.id的Worker,会自动组成集群。当新增Worker,或者有Worker挂掉时,其余的worker将检测到这一点,集群会自 动协调分配所有的Connector 和 Task(这个过程称为Rebalance)
Connector 和Task

Connectors
通过管理task来协调数据流的高级抽象。可分为两种connectors:
- Source connector
源连接器可以从多种渠道(如:数据库、静态文件、HDFS客户端等)拉取数据到kafka topic中
- Sink connector
宿连接器将topic中的数据push到多种目的端消费。将Kafka主题中的数据传递到Elasticsearch等二级索引中,或Hadoop等批处理系统中,用于离线分析。
Tasks
如何将数据复制到Kafka或从Kafka复制数据的实现。实际进行数据传输的单元,和连接器一样同样分为 Source和Sink
Task是Connect数据模型中的主要处理数据的角色。每个connector实例协调一组实际复制数据的task。通过允许connector将单个作业分解为多个task,Kafka Connect提供了内置的对并行性和可伸缩数据复制的支持,只需很少的配置。这些任务没有存储任何状态。任务状态存储在Kafka中的特殊主题config.storage.topic和status.storage.topic中。因此,可以在任何时候启动、停止或重新启动任务,以提供弹性的、可伸缩的数据管道。

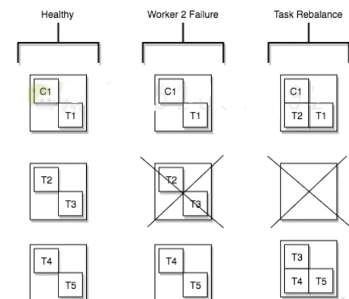
Task Rebalance
Converters
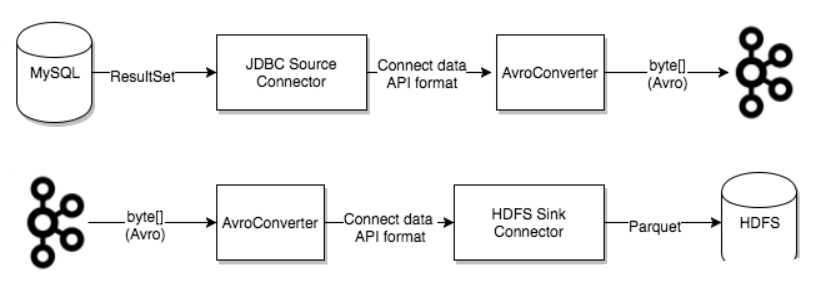
用于在Connect和外部系统发送或接收数据之间转换数据的代码。
Kafka Connect 通过 Converter 将数据在Kafka(字节数组)与Task(Object)之间进行转换。
在向Kafka写入或从Kafka读取数据时,Converter是使Kafka Connect支持特定数据格式所必需的。
task使用转换器将数据格式从字节更改为连接内部数据格式,反之亦然。
elk的logstash做迁移更好用