原文地址:https://arxiv.org/abs/2305.07001
本文作者将用户偏好、意图等构建为指令,并用这些指令调优一个LLM(3B Flan-T5-XL),该方法对用户友好,用户可以与系统交流获取更准确的推荐。
INTRODUCTION
LLM是建立在自然语言文本上的,它不能直接适应基于行为数据的推荐系统。为了减少两者的gap,一种思路是将行为建模视作语言建模。在这种方法中,有两个关键问题:
- 如何表达推荐任务?通常来说,成功的推荐依赖对user需求的准确理解,因此需要设计一种合适的形式包含用户需求的各种信息,包括交互历史、用户偏好、用户意图等个性化因素。
- 如何使LLM适应推荐?尽管LLM能够对自然语言建模,并且它有一定的通用性,但是它还是难以处理复杂的任务,需要特定的调整策略,将LLM调整为适应推荐任务。
作者提出了一种方法InstructRec解决以上问题,其主要有两个贡献:
- 推荐指令格式说明。
- 用指令调优的LLM进行推荐。
指令中的用户偏好、意图是使用GPT3.5基于用户的历史行为生成的。
METHODOLOGY
Instruction Format for Recommendation
指令的格式。
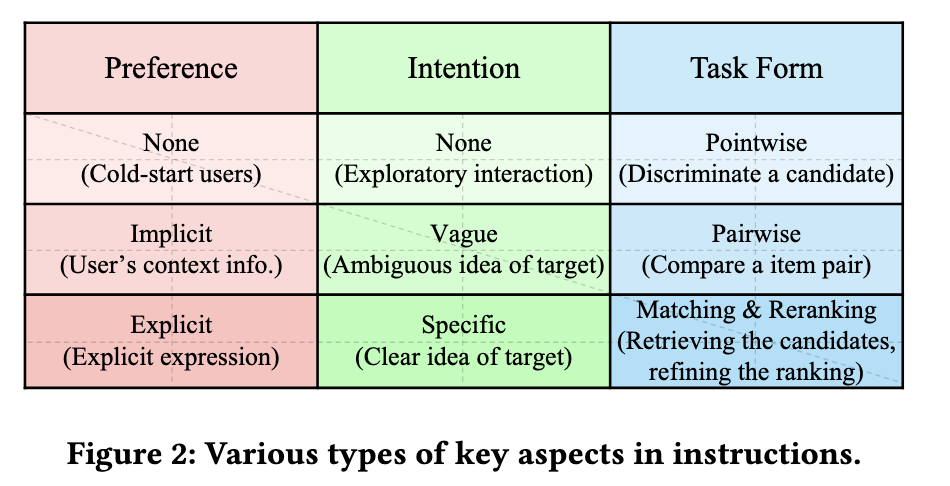
Key Aspects in Instructions
指令的关键方面有三个:用户的偏好、意图及任务形式。
-
Preference (P):用户的偏好,指用户对item的属性或特征的个性化品味。在本文的指令中,旨在捕获用户固有的长期偏好。可分为以下三类
- None (\(P_0\)):在这种情况下,没有用户偏好或信息可用。
- Implicit preference (\(P_1\)):隐式偏好,用户的个人信息和历史交互记录可用,但是没有明确表示出用户显示偏好。在使用历史交互记录时,不使用其ID,而是使用其标题作为文本信息。
- Explicit preference (\(P_2\)):显示偏好,本文主要考虑用户在文本中的表达,例如评论。
-
Intention (I):指用户对某些类型的item更直接的需求。
- None (\(I_0\)):用户缺乏明确目标。
- Vague intention (\(I_1\)):用户对需求item模糊的表述,例如“送儿子的礼物”。
- Specific intention (\(I_2\)):用户有明确的需求,例如“蓝色、便宜、IPhone13”。
-
Task Form (T):本文提出了以下几种任务形式
- Pointwise recommendation (\(T_0\)):判断当前item是否适合用户。
- Pairwise recommendation (\(T_1\)):将一对item进行比较并选出更合适的。
- Matching (\(T_2\)):从全体item中选出合适的。
- Reranking (\(T_3\)):对已检索出的item进行重排。
除上述三部分外,还可以加入一些上下文特征(时间地点等)。
Instantiation for Various Interaction Scenarios
本节介绍了几个具有代表性的实例。

- ⟨\(P_1/P_2,I_0,T_3\)⟩:在这个实例中,专注于用户的兴趣。LLM充当传统的推荐系统。
- ⟨\(P_0,I_1/I_2,T_3\)⟩:在这个实例中LLM充当检索器。
- ⟨\(P_1/P_2,I_1/I_2,T_3\)⟩:个性化搜索。
因为LLM推理成本较高,所以LLM更适合用于重拍阶段,在本文中也主要讨论\(T_3\)任务。
Instruction Generation
通过提示GPT3.5用户的历史行为和评论来为用户生成个性化信息。
Annotating the Aspects in Instructions
-
Preference annotation:对于隐式偏好取标题,显示偏好通过GPT3.5提取。

-
Intention annotation:类似于偏好提取。
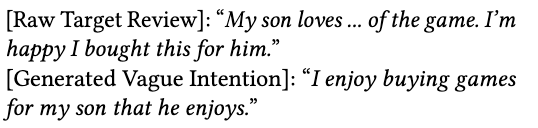
显示意图可以用标签表示。

-
Task form annotation:对于\(T_0\),需要构建指令类似于“基于<用户相关的信息>,用户之后会与
- 交互吗?”,系统只需要回答“是”或“否”。
对于任务\(T_2\),构建指令类似于“预测下一个可能交互的物品”。
对于任务\(T_3\),构建指令类似于“从<候选集>中选择一个物品”。 - 交互吗?”,系统只需要回答“是”或“否”。
提高指令多样性
提高指令数量和多样性有利于提高推荐效果,以下是作者提出增加指令多样性的一些策略
-
Turn the task around:对正常指令的输入输出交换。

-
Enforcing the relatedness between preference and intention:长期偏好和短期意图应该高度相关。

-
Chain-of-thought (CoT) like reasoning:在中间推理步骤中添加了额外的解释,使LLM能够执行复杂的推理任务。


Instruction Tuning for Recommendations
- The Backbone LLM:3B Flan-T5-XL
- Optimization via Instruction Tuning:本质上是一种有监督微调,根据不同的指令提供期望的系统回答。由于指令和目标输出都可以以自然语言格式化,我们可以将训练统一为sequence-to-sequence方式。
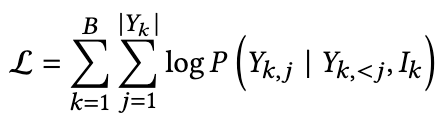
EXPERIMENTS
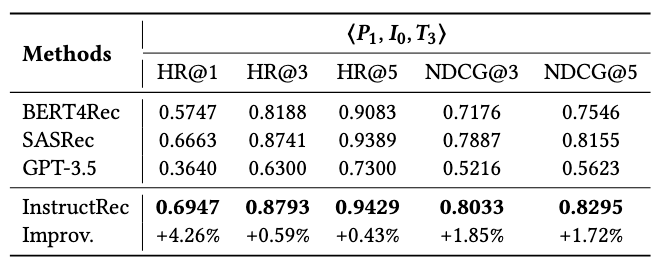
Sequential Recommendation ⟨\(P_1,I_0,T_3\)⟩:序列推荐任务上的表现
Product Search ⟨\(P_0,I_2,T_3\)⟩:产品搜索上的表现

Personalized search ⟨\(P_1/P_2,I_1/I_2,T_3\)⟩:个性化搜索上的表现

Discriminating Hard Negative Item Candidates:区分难负例的表现,模拟真实推荐中的重排通道
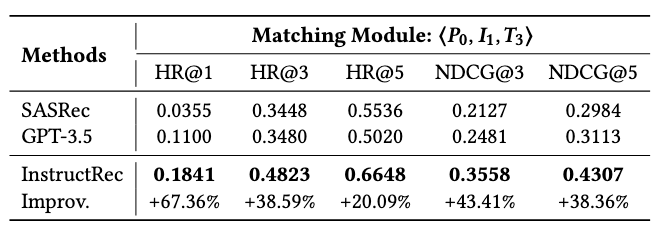
Discriminating More Candidate Items:从更大的候选集中选item,其它实验候选集大小都是10,这个实验是100
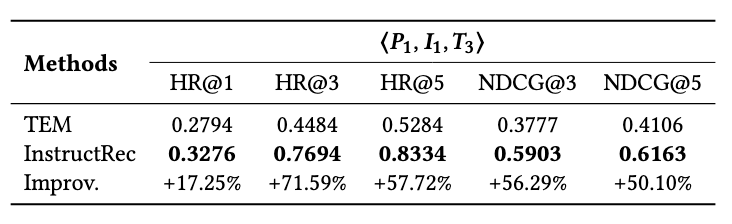
Effects of Instructions:指令的效果,不断在基础指令上叠加更多指令

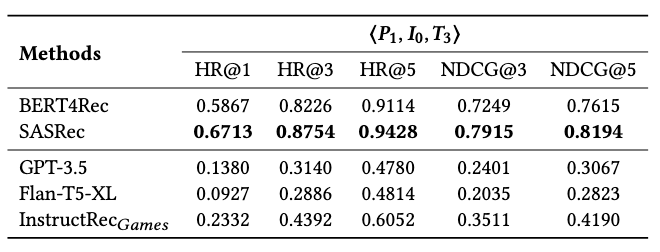
Generalization across Datasets:跨域推荐,上面两种传统的推荐方法在进行了正常的域内训练,下面的基于LLM的推荐是在亚马逊“Games”数据集上微调,在“CDs”数据集上测试
SUMMARY
本文主要讲的是通过指令微调LLM并用LLM进行推荐,经过精心设计的指令微调后的LLM在多种场景下的推荐表现出不错的效果。但是,由于LLM无法很好地处理长文本,LLM难以对用户较长的序列进行建模,文中实验生成所用的行为序列大小被限制为20,测试时重排的集合大小更是只有10,在实际中的推荐系统数据要比这些大的多。目前,微调LLM进行推荐还在初步阶段,有很多有前景的方向值得探索,包括如何生成让LLM更易于理解的指令、如何使用更长的行为序列等。
- Recommendation Instruction Following Empowered Approachrecommendation instruction following empowered instruction-following instruction-following instruction transformer empowered approach gpt-empowered computing-empowered transformer-empowered transformer multi-scale transformer-empowered gpt-empowered penetration pentestgpt empowered