第四次作业
一、作业内容
作业①:
要求:
熟练掌握 Selenium 查找HTML元素、爬取Ajax网页数据、等待HTML元素等内容。
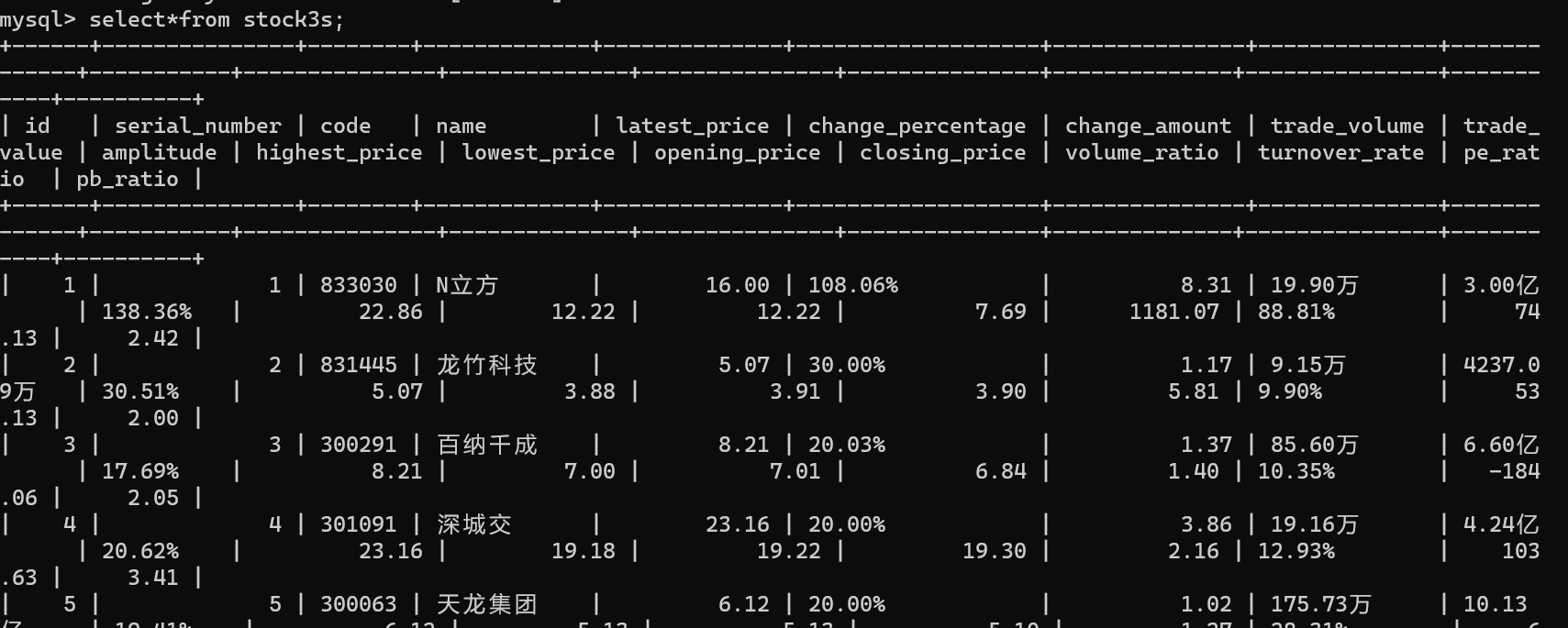
使用Selenium框架+ MySQL数据库存储技术路线爬取“沪深A股”、“上证A股”、“深证A股”3个板块的股票数据信息。
候选网站:东方财富网:http://quote.eastmoney.com/center/gridlist.html#hs_a_board
输出信息:MYSQL数据库存储和输出格式如下,表头应是英文命名例如:序号id,股票代码:bStockNo……,由同学们自行定义设计表头:
Gitee文件夹链接
代码如下:
点击查看代码
from selenium.webdriver.support import expected_conditions as EC
import mysql.connector
import pandas as pd
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.common.exceptions import ElementNotInteractableException, StaleElementReferenceException, TimeoutException
from io import StringIO
import time
from selenium.webdriver.support.wait import WebDriverWait
config = {
'host': 'localhost',
'user': 'root',
'password': 'gr4th123456',
'database': 'stock',
'auth_plugin': 'mysql_native_password'
}
def setup_database(cursor):
cursor.execute(
"""CREATE TABLE IF NOT EXISTS stock3s (
id INT AUTO_INCREMENT PRIMARY KEY,
serial_number INT,
code VARCHAR(10),
name VARCHAR(100),
latest_price DECIMAL(10, 2),
change_percentage VARCHAR(10),
change_amount DECIMAL(10, 2),
trade_volume VARCHAR(20),
trade_value VARCHAR(20),
amplitude VARCHAR(10),
highest_price DECIMAL(10, 2),
lowest_price DECIMAL(10, 2),
opening_price DECIMAL(10, 2),
closing_price DECIMAL(10, 2),
volume_ratio DECIMAL(10, 2),
turnover_rate VARCHAR(10),
pe_ratio DECIMAL(10, 2),
pb_ratio DECIMAL(10, 2)
)"""
)
def clean_value(value):
if isinstance(value, str):
if value == '-':
return 0.0
value = value.replace(',', '') # Remove commas
value = value.replace('%', '') # Remove percentage symbol if present
if value.endswith('%'): # If percentage, convert to decimal
return float(value.rstrip('%')) / 100
return float(value)
elif isinstance(value, float):
return value
else:
raise ValueError(f"Unexpected data type: {type(value)}")
def scrape_and_store(url, page_limit=None):
driver = webdriver.Edge("D:\msedgedriver.exe")
driver.get(url)
page_scraped = 0
db = mysql.connector.connect(**config)
cursor = db.cursor()
setup_database(cursor)
while True:
table = driver.find_element(By.XPATH, '/html/body/div[1]/div[2]/div[2]/div[5]/div/table')
table_html = table.get_attribute('outerHTML')
df = pd.read_html(StringIO(table_html), header=0)[0] # Wrap table_html with StringIO to avoid FutureWarning
page_scraped += 1
if page_limit is not None and page_scraped >= page_limit:
break
for index, row in df.iterrows():
values = (
row['序号'], row['代码'], row['名称'], clean_value(row['最新价']), row['涨跌幅'],
clean_value(row['涨跌额']), row['成交量(手)'], row['成交额'], row['振幅'], clean_value(row['最高']),
clean_value(row['最低']), clean_value(row['今开']), clean_value(row['昨收']), clean_value(row['量比']), row['换手率'],
clean_value(row['市盈率(动态)']), clean_value(row['市净率'])
)
cursor.execute(
"""INSERT INTO stock3s (
serial_number, code, name, latest_price, change_percentage, change_amount, trade_volume,
trade_value, amplitude, highest_price, lowest_price, opening_price, closing_price,
volume_ratio, turnover_rate, pe_ratio, pb_ratio
) VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)""",
values
)
next_button = driver.find_element(By.CSS_SELECTOR, 'a.next.paginate_button')
if next_button.get_attribute('disabled') == 'true':
# The "Next" button is disabled, we are on the last page
break
try:
WebDriverWait(driver, 10).until(
EC.element_to_be_clickable((By.CSS_SELECTOR, 'a.next.paginate_button'))
)
next_button.click()
time.sleep(2)
except Exception as e:
print(f"An error occurred: {e}")
break
db.commit()
cursor.close()
db.close()
driver.quit()
urls = [
'http://quote.eastmoney.com/center/gridlist.html#hs_a_board',
#'http://quote.eastmoney.com/center/gridlist.html#sh_a_board',
#'http://quote.eastmoney.com/center/gridlist.html#sz_a_board'
]
for url in urls:
scrape_and_store(url,page_limit=100)
运行结果:
心得体会
通过这次实验,进一步掌握selenium相关方法。
作业②:
要求:
熟练掌握 Selenium 查找HTML元素、实现用户模拟登录、爬取Ajax网页数据、等待HTML元素等内容。
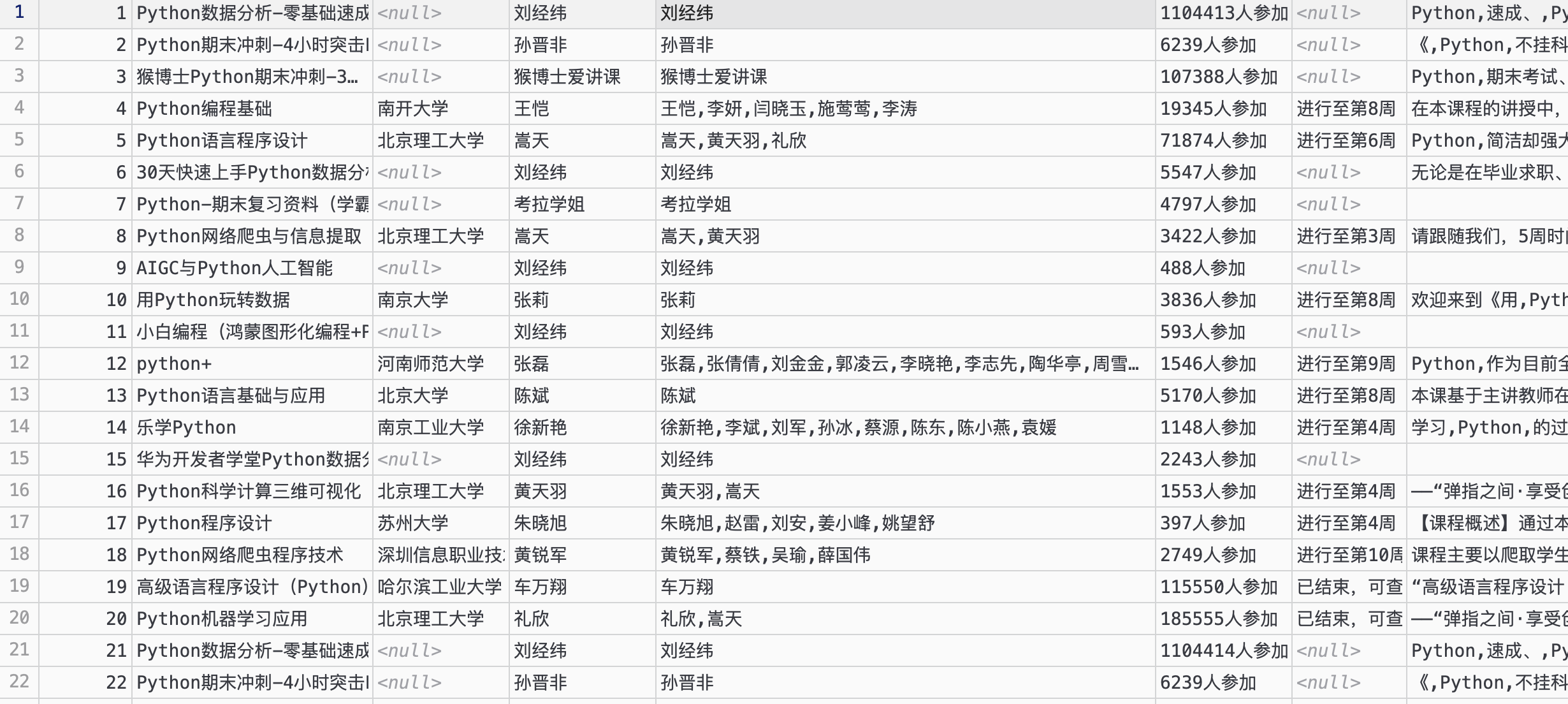
使用Selenium框架+MySQL爬取中国mooc网课程资源信息(课程号、课程名称、学校名称、主讲教师、团队成员、参加人数、课程进度、课程简介)
候选网站:中国mooc网:https://www.icourse163.org
输出信息:MYSQL数据库存储和输出格式
代码如下:
点击查看代码
import pandas as pd
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import mysql.connector
config = {
'host': 'localhost',
'user': 'root',
'password': 'xck030312',
'database': 'stock'
}
def setup_database(cursor):
cursor.execute(
"""CREATE TABLE IF NOT EXISTS mooc (
id INT AUTO_INCREMENT PRIMARY KEY,
course VARCHAR(255),
school VARCHAR(255),
teacher VARCHAR(255),
team VARCHAR(255),
number VARCHAR(255),
time VARCHAR(255),
jianjie TEXT
)"""
)
def main():
url = 'https://www.icourse163.org/'
driver = webdriver.Edge()
driver.get(url)
login(driver)
search_for_courses(driver, "java")
content = driver.page_source
driver.quit()
data = parse_content(content)
save_to_database(data)
def login(driver):
WebDriverWait(driver, 10).until(
EC.element_to_be_clickable((By.XPATH, '//*[@id="app"]/div/div/div[1]/div[3]/div[3]/div'))
).click()
driver.switch_to.default_content()
driver.switch_to.frame(driver.find_elements(By.TAG_NAME, 'iframe')[0])
enter_credentials(driver, "your_phone_number", "your_password")
driver.switch_to.default_content()
def enter_credentials(driver, phone_number, password):
phone = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.XPATH, '/html/body/div[2]/div[2]/div[2]/form/div/div[2]/div[2]/input'))
)
phone.clear()
phone.send_keys(phone_number)
passwd = driver.find_element(By.XPATH, '/html/body/div[2]/div[2]/div[2]/form/div/div[4]/div[2]/input[2]')
passwd.clear()
passwd.send_keys(password)
submit_btn = driver.find_element(By.XPATH, '//*[@id="submitBtn"]')
submit_btn.click()
def search_for_courses(driver, query):
select_course = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.XPATH, '//*[@id="j-searchTxt"]'))
)
select_course.clear()
select_course.send_keys(query)
select_course.send_keys(Keys.RETURN)
def parse_content(content):
selector = Selector(text=content)
rows = selector.xpath("//div[@class='m-course-list']/div/div")
data = []
for row in rows:
course = row.xpath(".//span[@class='u-course-name f-thide']//text()").extract_first()
school = row.xpath(".//a[@class='t21 f-fc9']/text()").extract_first()
teacher = row.xpath(".//a[@class='f-fc9']//text()").extract_first()
team = ",".join(row.xpath(".//a[@class='f-fc9']//text()").extract())
number = row.xpath(".//span[@class='hot']/text()").extract_first()
time = row.xpath(".//span[@class='txt']/text()").extract_first()
jianjie = ",".join(row.xpath(".//span[@class='p5 brief f-ib f-f0 f-cb']//text()").extract())
data.append([course, school, teacher, team, number, time, jianjie])
return data
def save_to_database(data):
connection = mysql.connector.connect(**config)
cursor = connection.cursor()
setup_database(cursor)
df = pd.DataFrame(data=data, columns=['course', 'school', 'teacher', 'team', 'number', 'time', 'jianjie'])
for _, row in df.iterrows():
cursor.execute(
"""INSERT INTO mooc (course, school, teacher, team, number, time, jianjie)
VALUES (%s, %s, %s, %s, %s, %s, %s)""",
(row['course'], row['school'], row['teacher'], row['team'], row['number'], row['time'], row['jianjie'])
)
connection.commit()
cursor.close()
connection.close()
if __name__ == "__main__":
main()
运行结果:
心得体会:搞清楚了如何解决模拟登录的问题。
作业③:
要求:
掌握大数据相关服务,熟悉Xshell的使用
完成文档 华为云_大数据实时分析处理实验手册-Flume日志采集实验(部分)v2.docx 中的任务,即为下面5个任务,具体操作见文档。
环境搭建:
任务一:开通MapReduce服务
申请集群
修改安全组
实时分析开发实战:
任务一:Python脚本生成测试数据
步骤1 编写Python脚本
用Xshell 7连接服务器
用xftp7将本地的autodatapython.py文件上传至服务器

步骤2 创建目录
使用mkdir命令在/tmp下创建目录flume_spooldir,我们把Python脚本模拟生成的数据放到此目录下,后面Flume就监控这个文件下的目录,以读取数据。
步骤3测试执行
执行Python命令,测试生成100条数据
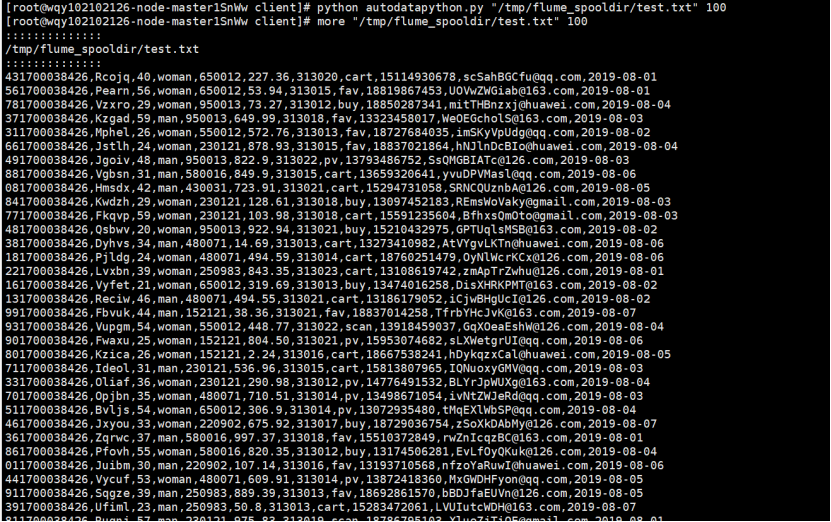
任务二:配置Kafka
步骤1 设置环境变量

步骤2 在kafka中创建topic
更换为自己Zookeeper的ip
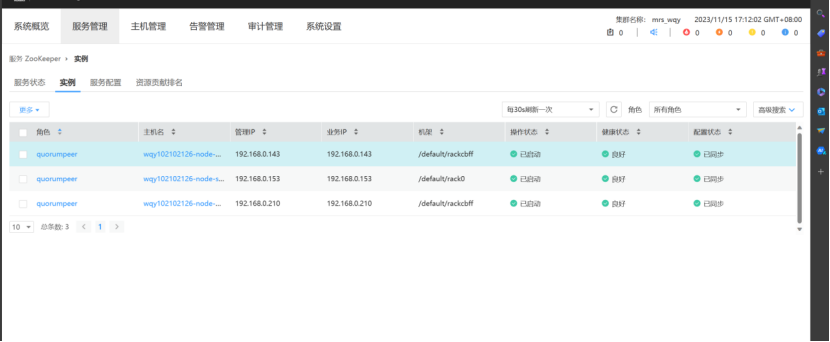
步骤3 查看topic信息

任务三: 安装Flume客户端
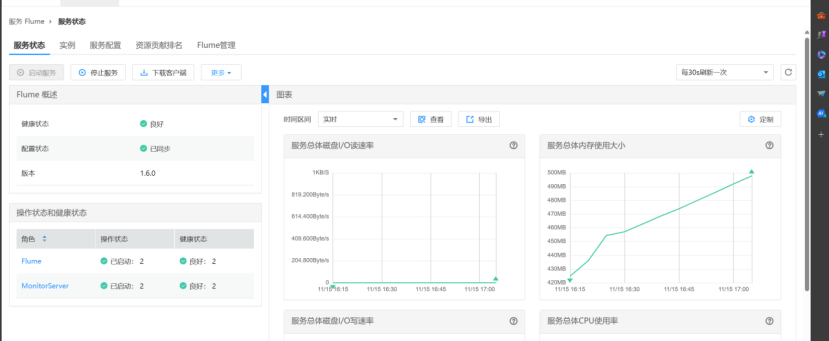
步骤1 打开flume服务界面
进入MRS Manager集群管理界面,打开服务管理,点击flume,进入Flume服务
步骤2 解压下载的flume客户端文件
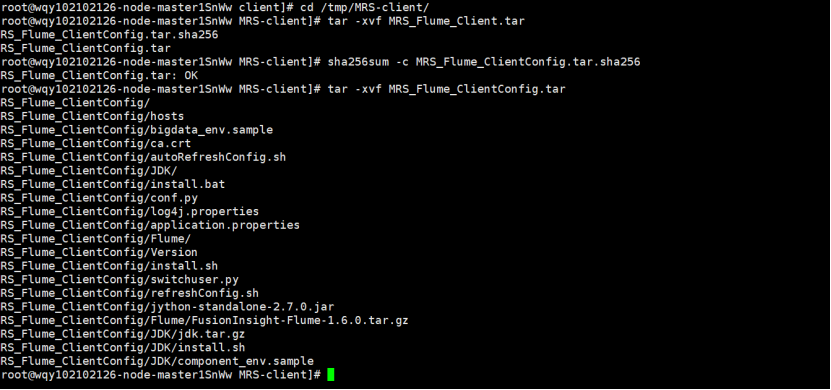
校验文件包
解压“MRS_Flume_ClientConfig.tar”文件
步骤3 安装Flume环境变量
解压Flume客户端
步骤4 安装Flume客户端
重启Flume服务


任务四:配置Flume采集数据
步骤1 修改配置文件

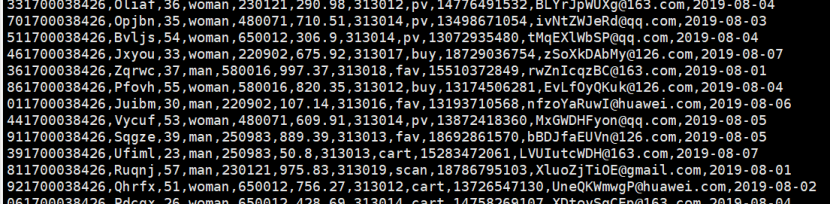
步骤2 创建消费者消费kafka中的数据
心得体会:
熟悉了华为云的功能,对mps有更深的了解。