一个最小化的Ceph集群需要三个组件MON MGR OSD.上一章我们部署了MON,本章节我们完成剩下MGR 和OSD 的部署。在文末我们将重点介绍下什么是FileStore和BlueStore,并详细分析其特点,来说明为什么Ceph社区放弃了FileStore,直接采用了BlueStore.
1、MGR 部署
- 创建mgr工作目录
sudo -u ceph mkdir /var/lib/ceph/mgr/ceph-mon01
- mgr 授权
#例子 ceph auth get-or-create mgr.$name mon \
# 'allow profile mgr' osd 'allow *' mds 'allow *'
# allow profile mgr 表示允许管理和配置mgr 的权限
ceph auth get-or-create mgr.mon01 mon \
'allow profile mgr' osd 'allow *' mds 'allow *' \
> /var/lib/ceph/mgr/ceph-mon01/keyring
- 修改目录的属主和属组为ceph用户,并启动ceph-mgr 进程
chown -R ceph:ceph /var/lib/ceph/mgr/
systemctl restart ceph-mgr@mon01
systemctl enable ceph-mgr@mon01
4、检查集群状态
[root@mon01 tmp]# ceph -s
cluster:
id: 51be96b7-fb6b-4d68-8798-665278119188
health: HEALTH_WARN
mon is allowing insecure global_id reclaim
1 monitors have not enabled msgr2
services:
mon: 1 daemons, quorum mon01 (age 44m)
mgr: mon01(active, since 1.5342s)
osd: 0 osds: 0 up, 0 in
data:
pools: 0 pools, 0 pgs
objects: 0 objects, 0 B
usage: 0 B used, 0 B / 0 B avail
pgs:
此时发现mgr: mon01 显示active 为活动状态表示部署成功。 但是Ceph 集群的状态还是显示为HEALTH_WARN。
- 问题1 : 1 monitors have not enabled msgr2
msgr2协议 是Ceph中的新消息传递协议,它带来了一些性能和安全性方面的改进。在集群中,所有的监视器都应该启用msgr2以确保它们之间使用最新的消息传递协议。
总结:
-
msgr是MON用来消息传递的协议,目前有两个版本V1 和V2 ,V1版本使用6789端口,
V2版本使用3300端口。 -
ceph mon enable-msgr2开启V2版 消息传递协议。

【思考】:做过ceph运维的小伙伴肯定会遇见一种情况就是执行ceph -s 或其他ceph命令时命令一直卡住,很长时间都没有反应,第一次遇见此情况的小伙伴甚至怀疑集群宕机了。
【实验】 禁止本机3300端口
#使用iptables 规制禁止了3300端口的访问
iptables -A INPUT -p tcp -m tcp --dport 3300 -j DROP

现在我们使用ceph -s 命令背后的逻辑
- 先确定其进程编号
- lsof 查看其命令访问的端口号

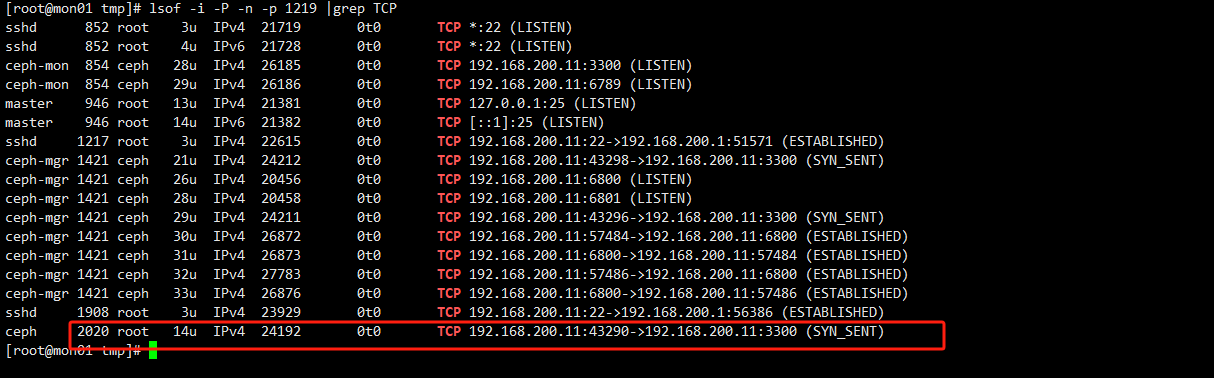
从上图中发现其确实访问的3300端口。因此我们得出结论,当执行ceph命令时,进程卡住了,先检查下3300 和6789 端口是否能正常访问。 iptables -F 清空filter 表后恢复正常
- 问题2: mon is allowing insecure global_id reclaim
#关闭非安全的集群id 回收
ceph config set mon \
auth_allow_insecure_global_id_reclaim false
2、OSD 部署
OSD的安装可以分两步:初始化、激活,也可以一步到位。
#初始化
ceph-volume lvm prepare --data /dev/sdb
ceph-volume lvm list
#来获取osd.id 和 osd fsid
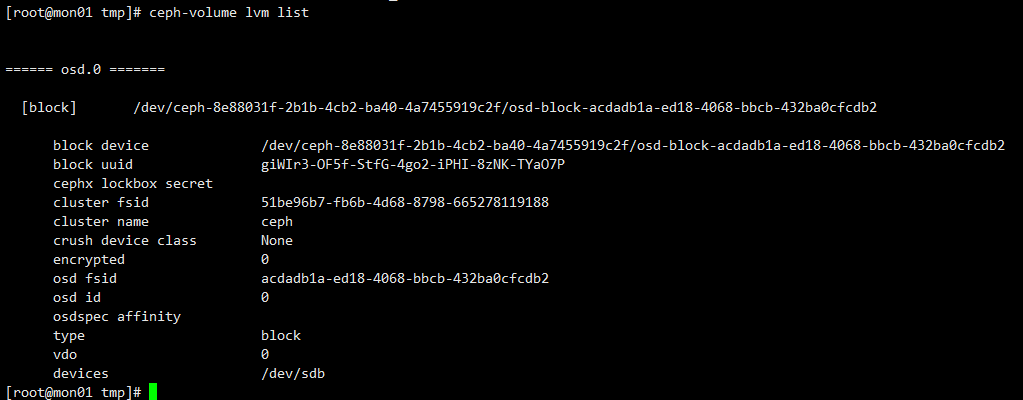
#激活
ceph-volume lvm activate 0 acdadb1a-ed18-4068-bbcb-432ba0cfcdb2
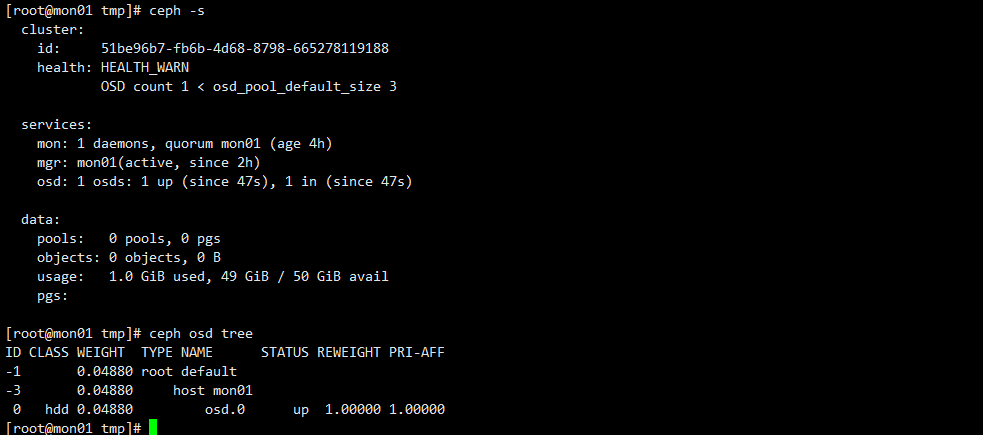
验证第一个osd
第二个osd 和第三三个osd 安装使用create 等于上面的两步
ceph-volume lvm create --data /dev/sdc
ceph-volume lvm create --data /dev/sdd
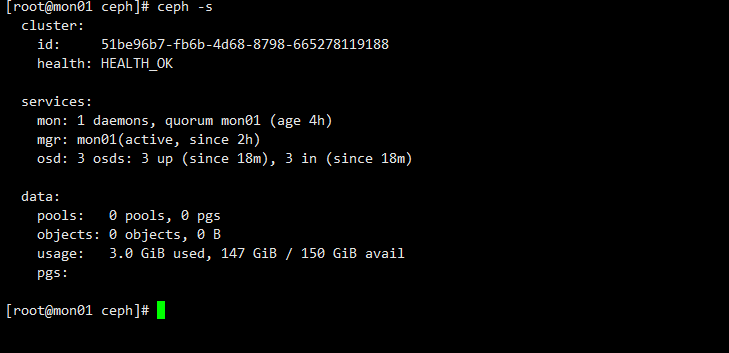
到此整个ceph 集群就部署完成了,一个MON ,一个MGR 和3个OSD 组成了一个最小化的Ceph集群。
不过上述的部署方式仅限于测试环境,生产环境切勿直接使用上述命令。为什么?
对ceph 有过生产经验的小伙伴都知道,Ceph是需要日志盘的。这里我们只使用了数据盘,那日志盘了?
要解释清楚这个问题,我们先弄清楚FileStore 和 BlueStore
3、Filestore or Bluestore
在之前的章节中我们曾介绍说,一般数据可以简单分为两部分,数据和元数据,在Ceph集群中,数据在写入集群时,将被客户端分割成4MB为单位的对象。每个对象都会写入OSD来实现落盘。在FileStore中每一个对象都需要通过FileStore的功能来实现将对象写入磁盘。
Ceph采用的是全日志系统,也就是说将所有数据存放在日志中(数据和元数据都存放在日志中),这样做的好处是Ceph可以先把一些零散的、随机的I/O请求保存到缓存中并进行合并,然后再统一向内核发起I/O请求。这样做效率会比较高,其带来的问题就是一旦OSD崩溃,缓存中的数据就会丢失。因此Ceph的日志是事务日志。事务日志不是真正去修改数据,而是记录数据修改的操作,这样当数据崩溃后,只要基于当前时间节点回放事务日志就能还原数据。
写日志有两种模式:Parallel和Writeahead。
- Parallel(并行写): 是日志和磁盘数据同时写;
- Writeahead(预写日志): 是先写日志,只要日志写成功,就返回,后台每隔一段时间会同步日志中的写操作,实现落盘。这种方法带来的好处就是,可以把很多小I/O请求合并,形成顺序写盘,提高每秒读写次数。通常在生产环境中,我们使用SSD来单独存储日志文件,以提高Ceph读写性能。
在Writeahead模式下,Ceph对象(数据和元数据)一旦写入日志盘之后,就返回给客户端写入完成,之后按照一定的同步周期来将数据同步到后端真正的数据盘中。也就是说,当用户写入了一个对象数据(Ceph 中一切皆对象)返回成功时,可能该数据仅仅只是写了日志盘,还没有真正落入后端的存储磁盘。这就引入了第一个问题,FileStore 的双写问题(数据先写了日志盘,之后按一定周期写入后端磁盘)。
其次是在ceph按一定周期将日志盘的信息写入后端数据盘时,其前端对日志的写操作是要暂停的。专门执行日志数据到文件系统的同步。日志系统空间大小代表能缓存的数据量,同步时间的设置也会影响Ceph的性能。
在从文件系统的角度来看,FileStore底层使用POSIX规范的文件系统接口,例如xfs、ext4、btrfs,无论是数据还是元数据,都需要先写入文件系统层(如图中的XFS文件系统),然后由XFS文件系统接口来实现数据的落盘操作。我们可以简单理解为其在文件系统层也有写放大的问题,增加了文件系统层IO操作。
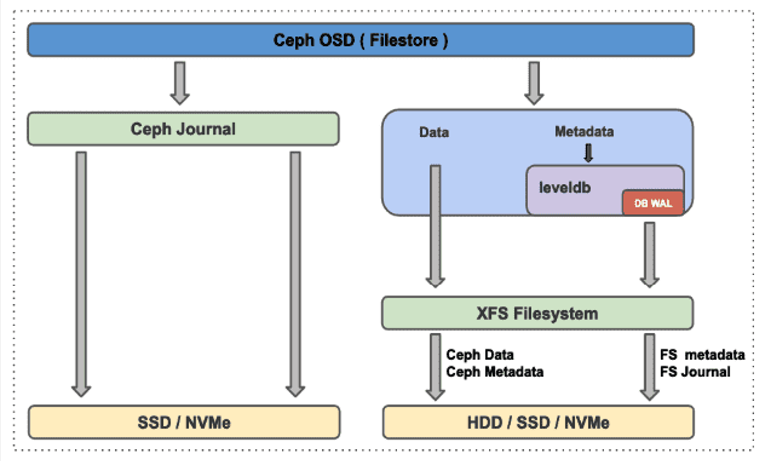
前文中我们提过,数据的元数据的一些随机的小IO,在FileStore 中使用Leveldb键/值数据库来存放其元数据,而Leveldb 为了保证自身事务的一致性,也采用事务日志来记录其操作,而不是真正的元数据进行操作。这些只是记录操作本身,而不对真正数据操作的行为都可以称为WAL(Write Ahead Log预写日志),其优点是一方面提高了效率(将随机IO变成了顺序IO),另一方面也保证事务的唯一性要求。(其思想反复应用在各种数据库中).
下面我们总结下FileSore的特点:
- 无论是数据还是元数据都是先写日志盘,再由日志盘同步到数据盘。存在数据双写问题。
- 无论是数据还是元数据都是在文件系统层之上,存在文件系统层的写放大问题。
- 日志盘同步数据到数据盘时日志盘不能写入有性能问题。
- 为加速对元数据的访问,用键值数据库LevelDB来优化其访问,LevelDB为保证事务的持久化采用WAL。
BlueStore的诞生是为了解决FileStore同时维护一套日志系统和基于文件系统写放大的问题,实现FileStore本身没有的对SSD的最优支持
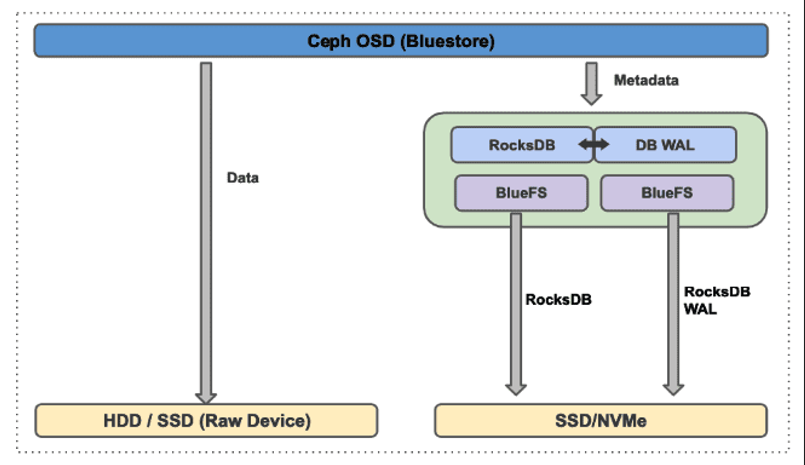
- BlueStore 数据是直接写入裸盘的,不存在双写问题
- BlueStore 数据写入的裸盘中是没有文件系统层的。
- 实现在用户态下使用linux aio直接对裸设备进行I/O操作,去除了本地文件系统的消耗,减少系统复杂度,更有利于Flash介质盘发挥性能优势
- 采用RockDB来存储对象的元数据和DB WAL 。RocksDB是一种嵌入式高性能键/值存储。在闪存存储方面表现出色,RocksDB无法直接写入原始磁盘设备,需要底层文件系统来存储其持久化数据,因此设计了BlueFS。
- BlueFS:简化的文件系统,解决元数据、文件及磁盘的空间分配和管理问题
无论是FileStore 还是BlueStore中为加速元数据的访问都使用键值存储数据库,键值存储数据是依赖文件系统的。FileStore 采用了LevelDB ,BlueStore采用了BlueFS .为了持久化存储事务日志都采用了预写日志的方式(DB WAL)。
因此在生产中FileStore一般是用SSD磁盘作为为日志盘来使用,而数据盘一般是HDD磁盘。 而在BlueStore环境中 一般是采用两块SSD磁盘 ,一块用作RockDB ,一块用作DB WAL。体现在命令上如下
FileStore 环境
#--data 指定数据盘 --journal 指定日志盘,一般为分区。
ceph-volume --cluster ceph lvm create --osd-id 0 /
--filestore --data /dev/sdb--journal /dev/sda1
#--data 指定数据盘 --block.db 指定RocksDB --block.wal 指定WAL
ceph-volume lvm create --bluestore \
--data /dev/{data_device} \
--block.db /dev/{db_device} \
--block.wal /dev/{wal_device}
问题:如何判断一个Ceph集群使用的是FileStore还是BlueStore ?
通过磁盘的type来判断是比较通用的方式
[root@mon01 ~]# cat /var/lib/ceph/osd/ceph-0/type
bluestore
写在最后
生产中存储系统的IO上限就决定了整个系统的磁盘IO的上限。因此为了追求极致的IO,仅仅对元数据的加速访问使用SSD或NVME磁盘是远远不够的。因此下一章节我们将介绍存储的缓存技术。聊下目前比较流行的两种存储的缓存技术。

