SQLAlchemy: What's the difference between flush() and commit()?
https://pyquestions.com/sqlalchemy-what-s-the-difference-between-flush-and-commit
A Session object is basically an ongoing transaction of changes to a database (update, insert, delete). These operations aren't persisted to the database until they are committed (if your program aborts for some reason in mid-session transaction, any uncommitted changes within are lost).
The session object registers transaction operations with
session.add(), but doesn't yet communicate them to the database untilsession.flush()is called.
session.flush()communicates a series of operations to the database (insert, update, delete). The database maintains them as pending operations in a transaction. The changes aren't persisted permanently to disk, or visible to other transactions until the database receives a COMMIT for the current transaction (which is whatsession.commit()does).
session.commit()commits (persists) those changes to the database.
flush()is always called as part of a call tocommit()(1).When you use a Session object to query the database, the query will return results both from the database and from the flushed parts of the uncommitted transaction it holds. By default, Session objects
autoflushtheir operations, but this can be disabled.

Types of SQL Commands
https://www.shekhali.com/what-is-sql-server-types-of-sql-commands/
SQL Commands
- SQL commands are instructions that are used to communicate with the database. They are also used to perform specific tasks, functions, and queries on the data.
- SQL commands allow you to do things like create a table, add data to tables, drop the table, modify the table, and set permissions for users.
Types of SQL Commands
Types of SQL Commands
The following is the list of five widely used SQL Commands.
- DDL (Data Definition Language)
- DML (Data Manipulation Language)
- DCL (Data Control Language)
- TCL (Transaction Control Language)
- DQL (Data Query Language)
https://www.educba.com/sql-commit/
A COMMIT command in SQL is an essential command that is used after Data Manipulation Language (DML) operations like INSERT, DELETE and UPDATE transactions. Transactions in SQL are a set of SQL statements.When you perform a DML operation without a COMMIT statement, the changes are visible only to you. You can use a SELECT statement and check the updated records from the modified data. But once you use a COMMIT command after a transaction, the changes in the table or database are visible to other database users.
All the transaction commands like ROLLBACK and COMMIT in SQL obeys the basic principles of ACID properties.
Given below are the basic properties:
- Atomicity: Either the entire transaction will be performed or nothing from that transaction is performed. It means there’s nothing like partial transactions.
- Consistency: It ensures consistency in the database. For example, if you have returned a book to a library, then the details of the book will be updated in all the related tables across databases.
- Isolation: The results of a partially completed transaction are not visible to other users.
- Durability: All the changes made by a COMMIT transaction are permanent in nature.
https://www.geeksforgeeks.org/acid-properties-in-dbms/

https://beginnersbook.com/2015/04/acid-properties-in-dbms/

How SQL Database Engine Work
https://hackernoon.com/how-sql-database-engine-work-483e32o7

Heap file organization
https://www.javatpoint.com/dbms-heap-file-organization
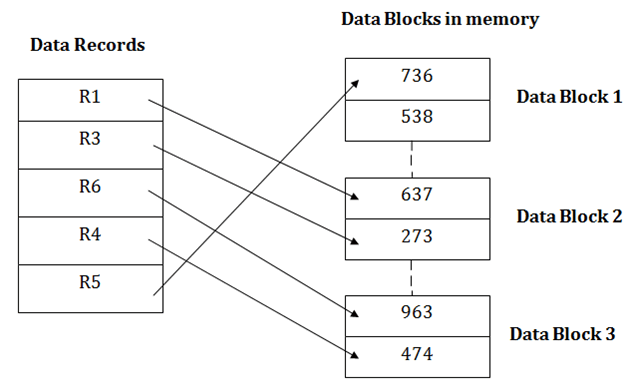
- It is the simplest and most basic type of organization. It works with data blocks. In heap file organization, the records are inserted at the file's end. When the records are inserted, it doesn't require the sorting and ordering of records.
- When the data block is full, the new record is stored in some other block. This new data block need not to be the very next data block, but it can select any data block in the memory to store new records. The heap file is also known as an unordered file.
- In the file, every record has a unique id, and every page in a file is of the same size. It is the DBMS responsibility to store and manage the new records.
Minibase
https://github.com/srmocher/Minibase
https://github.com/srmocher/Minibase/blob/master/proj2/HeapFile/include/hfpage.h
#ifndef _HFPAGE_H #define _HFPAGE_H #include "minirel.h" #include "page.h" const int INVALID_SLOT = -1; const int EMPTY_SLOT = -1; // Class definition for a minibase data page. // The design assumes that records are kept compacted when // deletions are performed. Notice, however, that the slot // array cannot be compacted. Notice, this class does not keep // the records aligned, relying instead on upper levels to take // care of non-aligned attributes. class HFPage { protected: struct slot_t { short offset; short length; // equals EMPTY_SLOT if slot is not in use }; static const int DPFIXED = sizeof(slot_t) + 4 * sizeof(short) + 3 * sizeof(PageId); // Warning: // These items must all pack tight, (no padding) for // the current implementation to work properly. // Be careful when modifying this class. short slotCnt; // number of slots in use short usedPtr; // offset of first used byte in data[] short freeSpace; // number of bytes free in data[] short type; // an arbitrary value used by subclasses as needed PageId prevPage; // backward pointer to data page PageId nextPage; // forward pointer to data page PageId curPage; // page number of this page slot_t slot[1]; // first element of slot array. char data[MAX_SPACE - DPFIXED]; public: void init(PageId pageNo); // initialize a new page void dumpPage(); // dump contents of a page PageId getNextPage(); // returns value of nextPage PageId getPrevPage(); // returns value of prevPage void setNextPage(PageId pageNo); // sets value of nextPage to pageNo void setPrevPage(PageId pageNo); // sets value of prevPage to pageNo PageId page_no() { return curPage;} // returns the page number // inserts a new record pointed to by recPtr with length recLen onto // the page, returns RID of record Status insertRecord(char *recPtr, int recLen, RID& rid); // delete the record with the specified rid Status deleteRecord(const RID& rid); // returns RID of first record on page // returns DONE if page contains no records. Otherwise, returns OK Status firstRecord(RID& firstRid); // returns RID of next record on the page // returns DONE if no more records exist on the page Status nextRecord (RID curRid, RID& nextRid); // copies out record with RID rid into recPtr Status getRecord(RID rid, char *recPtr, int& recLen); // returns a pointer to the record with RID rid Status returnRecord(RID rid, char*& recPtr, int& recLen); // returns the amount of available space on the page int available_space(void); // Returns true if the HFPage is has no records in it, false otherwise. bool empty(void); }; #endif // _HFPAGE_H
https://github.com/srmocher/Minibase/blob/master/proj2/HeapFile/include/heapfile.h
#ifndef _HEAPFILE_H #define _HEAPFILE_H #include "minirel.h" #include "page.h" #include "hfpage.h" #include "scan.h" #include "buf.h" #include "db.h" #include "new_error.h" // This heapfile implementation is directory-based. We maintain a // directory of info about the data pages (which are of type HFPage // when loaded into memory). The directory itself is also composed // of HFPages, with each record being of type DataPageInfo // as defined below. // // The first directory page is a header page for the entire database // (it is the one to which our filename is mapped by the DB). // All directory pages are in a doubly-linked list of pages, each // directory entry points to a single data page, which contains // the actual records. // // The heapfile data pages are implemented as slotted pages, with // the slots at the front and the records in the back, both growing // into the free space in the middle of the page. // See the file 'hfpage.h' for specifics on the page implementation. // // We can store roughly pagesize/sizeof(DataPageInfo) records per // directory page; for any given HeapFile insertion, it is likely // that at least one of those referenced data pages will have // enough free space to satisfy the request. // Error codes for HEAPFILE. enum heapErrCodes { BAD_RID, BAD_REC_PTR, HFILE_EOF, INVALID_UPDATE, NO_SPACE, NO_RECORDS, END_OF_PAGE, INVALID_SLOTNO, ALREADY_DELETED, }; // DataPageInfo: the type of records stored on a directory page: struct DataPageInfo { int availspace; // total available space of a page: HFPage returns int for avail space, so we use int here int recct; // number of records in the page: for efficient implementation of getRecCnt() PageId pageId; // page id: id of this particular data page (a HFPage) }; class HeapFile { public: // Initialize. A null name produces a temporary heapfile which will be // deleted by the destructor. // If the name already denotes a file, the // file is opened; otherwise, a new empty file is created. HeapFile( const char *name, Status& returnStatus ); ~HeapFile(); // return number of records in file int getRecCnt(); // insert record into file Status insertRecord(char *recPtr, int recLen, RID& outRid); // delete record from file Status deleteRecord(const RID& rid); // updates the specified record in the heapfile. Status updateRecord(const RID& rid, char *recPtr, int reclen); // read record from file, returning pointer and length Status getRecord(const RID& rid, char *recPtr, int& recLen); // initiate a sequential scan class Scan *openScan(Status& status); // delete the file from the database Status deleteFile(); private: friend class Scan; PageId firstDirPageId; // page number of header page int file_deleted; // flag for whether file is deleted (initialized to be false in constructor) char *fileName; // heapfile name // get new data pages through buffer manager // (dpinfop stores the information of allocated new data pages) Status newDataPage(DataPageInfo *dpinfop); // return a data page (rpDataPageId, rpdatapage) containing a given record (rid) // as well as a directory page (rpDirPageId, rpdirpage) containing the data page and RID of the data page (rpDataPageRid) Status findDataPage(const RID& rid, PageId &rpDirPageId, HFPage *&rpdirpage, PageId &rpDataPageId,HFPage *&rpdatapage, RID &rpDataPageRid); // put data page information (dpinfop) into a dir page(s) Status allocateDirSpace(struct DataPageInfo * dpinfop,/* data page information*/ PageId &allocDirPageId,/*Directory page having the first data page record*/ RID &allocDataPageRid /*RID of the first data page record*/); }; #endif // _HEAPFILE_H
- SQLAlchemy difference between commit flushsqlalchemy difference between commit innodb_flush_log_at_trx_commit difference and leetcode between 39 concatenated difference between differences toxicology studies between javascript difference promise between difference constexpr between const time difference the between difference between session entity difference procedures functions between