1. 摘要
近些年super resolution(SR)取得了很大进步,图像的SR真实世界数据集也有很多,相比来说视频要落后很多。本文构建了第一个真实世界的RAW视频SR数据集。数据集中包含450对RAW视频,LR图像有对应的2x/3x/4x的HR图像。本文提出一个两分支网络,分别处理packed RGGB序列和Bayer RAW序列,两个分支互相补充,最后通过对齐,交互,融合和重建模块获取对应的HR sRGB序列。实验结果在真实世界数据集和合成数据集上都取得了sota的结果。
code: https://github.com/zmzhang1998/Real-RawVSR
paper: https://www.ecva.net/papers/eccv_2022/papers_ECCV/papers/136660597.pdf
本文贡献:1)构建了一个VSR数据集,包含raw和sRGB的LR-HR数据对,上采样率涵盖2x,3x和4x,数据集包含450个视频,每个视频150帧;2)提出一个新的针对raw图的VSR网络架构,输入为bayer raw图和对应的packed sub-frames,并且提出采用联合对齐、交互和融合模块来利用两个分支的信息;3)提出一个简单有效的颜色校正算法用于在训练中匹配LR-HR之间的颜色差异,并且通过实验验证在raw和sRGB域都有效果。
2. 数据集介绍
SR数据集一般包括合成数据集和真实世界数据集,合成数据集如DIV2K和REDS,但合成数据集一般不能正确表示LR相对于HR的衰减(degradation),真实世界数据集包括RealSR、City100等,他们通过不同焦距的相机获得对应的LR-HR图像对,但以上数据集都是在sRGB域的。
目前有很多工作开始迁移到RAW图像进行,比如超分、HDR和deblur等,因为RAW图包含更大的动态范围(10/12/14bit),并且RAW由于没有经过ISP的处理,尤其是tone mapping操作,线性数据更加有利于模型处理[ref]。因此针对SR问题,也有一些RAW数据集被提出,如ImagePairs。
对于视频SR的数据集,RealVSR是通过iPhone11ProMax手机和DoubleTake APP获取不同焦距下的图像分别组成LR-HR对,但是由于手机的焦距限制,这个数据集只有2x的上采样。另外还有BurstSR(ETH的DBSR)、RawVD等数据集。
本文提出的Real-RawSR数据集介绍:真实世界SR数据集采集一般分为两种,静态场景可以通过一台机器的短长焦分别获取LR和HR图像,动态图像可以通过分光镜和两个图像采集设备获取。本文采用第二种方法,具体设备参数和采集方法可参考原论文。
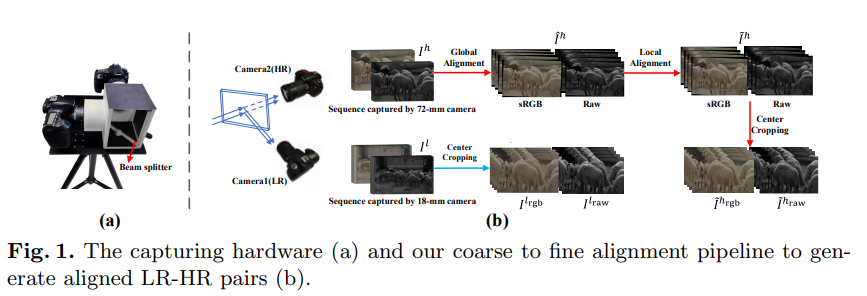
由于FOV差异和lens distortion,采集到的LR-HR图像对需要进一步对齐。本文采用coarse-to-fine的对齐方法,对于RGB图像,首先上采样LR_rgb到和HR_rgb相同分辨率,然后使用SIFT关键点+RANSAC进行匹配,最后计算两者之间的单一性矩阵,将HR_rgb先初步对齐到LR_rgb;然后使用DeepFlow,一种传统光流进行进一步对齐,然后crop掉边缘部分,保证内容没有空洞;需要注意的是数据集是对HR图像进行变换,最后获得的是RGB的ground-truth;对于RAW图,其distortion流程和RGB严格对齐,保持一致,但由于直接对RAW图进行变换会破坏掉Bayer RAW格式,首先将RAW的4个通道进行split,组成RGGB sub-frames,然后对其进行变换,当然,由于sub-frame分辨率降低了一倍,因此采用单一性矩阵和光流时都需要缩放0.5。

如上图为数据集中的几个示例,总共包含450个视频段(2x,3x,4x每个尺度150个视频段),每个视频150 frames,包含sRGB和Raw的LR-HR图像对(sRGB是经过black level correction,LSC,WB,CCM和gamma后获得的),2x的分辨率分别为1440x640和720x320。需要注意的是图像虽然对齐,但图像对之间还存在color and illumination differences。类型包括室内、室外和运动场景,运动分为相机运动和场景运动。
3. 相关工作介绍
对于视频/多帧超分任务,一般都是对齐+融合的链路。有些方法聚焦在对齐模块,采用光流方法和deformable convolution,如DBSR/TDAN/EDVR。近期,BasicVSR和其加强版IconVSR/BasicVSR++通过结合前向和后向传播信息和基于光流的对齐取得了很好的效果。
对于真实世界的SR数据集,他们的LR-HR数据对一般具有误对齐、color dismatching和intensity variance等问题。对于处理以上问题,DBSR通过在最后一层预测时采用训练好的光流网络进一步对齐prediction和gt,并且采用一个颜色对齐矩阵来处理color dismatching;zoom2learn提出一个contextual bilateral loss来处理空间误对齐;RealVSR提出一个基于拉普拉斯金字塔的损失来处理误对齐和颜色不匹配;考虑到真实的衰减会在时序上进一步放大,RealBasicVSR提出一个pre-cleaning模块来减少时序传播时的噪声和artifacts。
对于RAW图超分,zoom2learn使用一个ResNet将RAW直接映射到sRGB;DBSR合成多帧RAW,合成为高分辨率的demosaic后的RGB;和本文方法相关的是TRWSR和RawVSR,他们都采用two-branch来分别构建HR-Raw和RGB,分别处理细节和颜色,或者两者互相辅助。
4. 方法
VSR任务是通过融合2N+1张LR图像获得1张HR图像,之前针对raw图的SR基本都是将一张RGGB raw图分解成4张单色通道的输入,这破坏了raw图的像素顺序(有些任务是raw2rgb的超分,这样划分只是扩大了上采样倍率,和单图SR一致,我觉得论文这儿的说法存疑)。因此本文采用了two-braches的结构,一条分支输入为bayer raw,另一条为单色通道的sub-frames,然后两条通道联合对齐融合等。
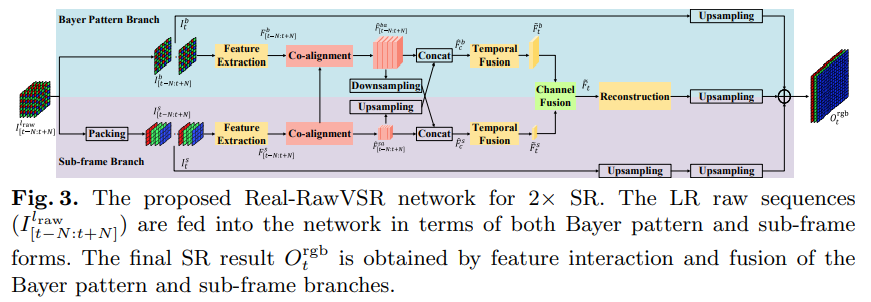
如上两个分支输入2N+1帧的bayer raw和sub-frames,分别通过各自的extractor提取特征;然后采用EDVR中的PCD对齐方法对齐2N帧到1帧参考帧,其中PCD对齐由金字塔和可形变卷积deformable convolution实现;接下来进入交互模块,通过传递两条分支的特征进行信息融合;时序融合用于融合2N+1帧的特征;然后是通道融合模块来整合两个分支的信息;最后是图像重建模块。
4.1 特征对齐模块
PCD对齐和可形变卷积先欠着,后续补充EDVR论文时详细介绍;
4.2 其他模块
- 交互模块:由于两条分支的信息是互补的,本文设计了一个交互模块来传递两条分支的信息,具体来说bayer raw分支通过(3x3 conv, stride=2)来下采样特征图,sub-frames分支通过pixel shuffle上采样特征图,分别传递到另一条链路进行concatenate;
- 时序融合:对齐模块将2N帧的特征对齐到ref帧,但每一帧特征对参考帧的贡献是不同的,本文在时间维度采用了一个non-local temporal attention模块来整合远程依赖信息,然后使用temporal spatial attention (TSA)模块来将特征融合到一起;
- 通道融合:用于融合两条分支的特征图,本文采用了selective kernel convolution (SKF);首先sub-frames分支进行pixel shuffle上采样,然后和bayer raw分支相加,再进行SKF模块;
- 重建模块:重建模块由10个ResBlock组成,然后结合pixelshuffle和conv映射到3通道输出,然后采用两个long skip connection分别连接两个分支,从而生成最后的输出;以上是2x超分的所有结构,对于4x,本文类似于EBSR,采用了两阶段的基于long skip connection的上采样;
- 潜在问题:以上结构通过两个分支进行,对于bayer raw分支,采用卷积进行特征提取,相当于融合RGGB四个位置的信息,而每个通道的像素值是差距很大的,相当于从不同通道之间交互,这种特征提取是否有效?在交互模块和通道融合模块,两个分支进行concatenate或pixel-wise add,但bayer raw像素分布和sub-frames在像素上RGB通道是不对齐的,这种融合是否存在问题?当然这只是推测,需要实验和进一步分析。
4.2 颜色校正和损失函数
由于LR-HR图像来自不同设备,之间存在着颜色和亮度的不同,不能直接计算prediction和gt之间的损失,因此本文在计算损失之前采用了颜色校正先对齐两者之间的颜色差异。DBSR是通过计算一个3x3的颜色校正矩阵来同时校正RGB三个通道,本文采用了一个channel-based的方法分别校正3个通道。
![]()
如上alpha是每个通道对应的scale参数,通过最小化输入图像LR_rgb和下采样后的HR_rgb之间的least square loss得到。
![]()
另外本文采用的损失为Charbonnier loss,它类似于L1,相比于L2,它对异常值不敏感,适用于超分任务。
5. 实验
数据处理:对于每一个放大倍率,130个视频用于训练和验证,20个用于测试,每个视频从150帧中采样50帧。raw数据预处理包括减去黑电平和white level normalization。多帧融合数目为5(2N+1, N=2),通道数为64,kernel size=3。
定量分析:

定性分析:

- Real-RawVSR University Dataset Tianjin RawVSRreal-rawvsr university dataset tianjin real-rawvsr tianjin rawvsr university university xinyang agriculture forestry programming university contest jimei university the stanford famous concurrency assignment2 algorithms university university technology zhejiang science