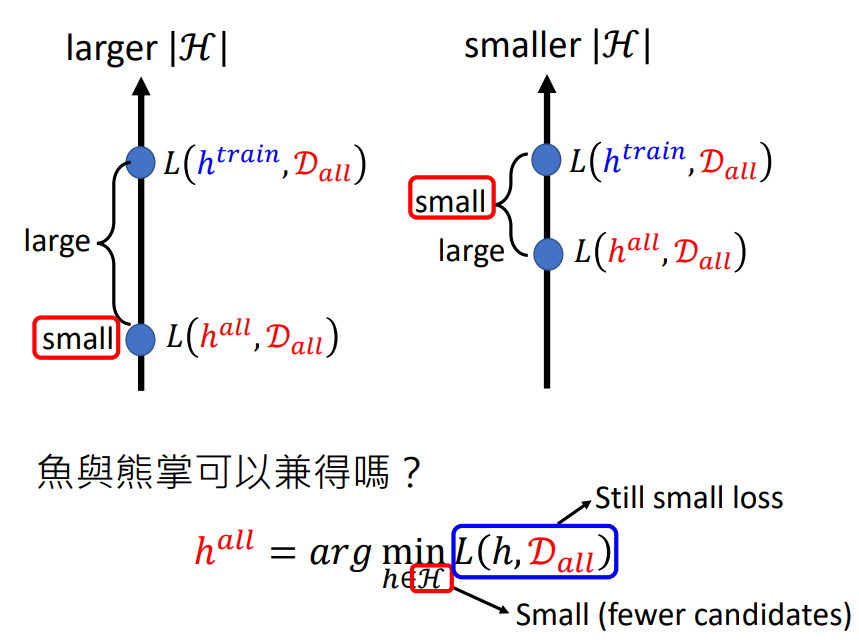
1. 问题回顾
在上节的再谈宝可梦、数码宝贝分类问题上,我们提出了机器学习的分类原理.并提出了一个矛盾点:当可选参数过多,loss会变小,但理想和现实差距会很大;当可选参数比较少,loss会变大,但理想和现实差距会减小.现在我们需要一个Loss小,可选参数也少的模型.
2. Why we need Hidden Layer?
2.1 Piecewise Linear
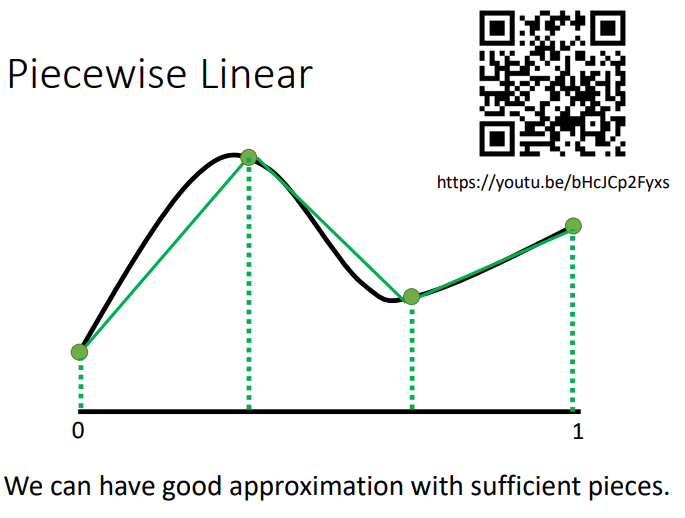
我们可以通过一个Hidden Layer就可以制造出所有可能的Function.如下图所示,现在我们要找一个Function,用Network去产生图中的线.我们将图中的线分成几等分,然后将端点连接起来得到Piecewise Linear.从图中我们可以发现如果绿色的线段足够多,就可以让绿色的线和黑色的线越来越接近.
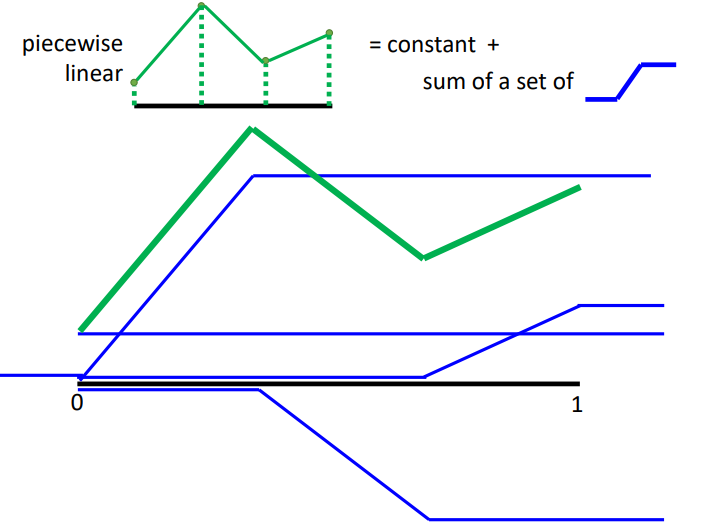
而绿色的线可以看作常数项加上一堆蓝色的Function.
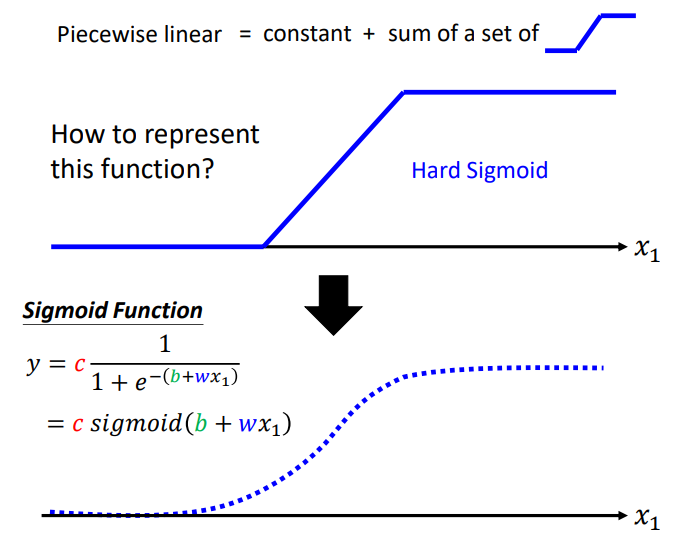
Piecewise Linear可以逼近任何\(function\),所以任何function可以由Neural Network表示.那么Neural Network怎么表示Piecewise Linear呢?我们可以使用Sigmoid Function近似地表示蓝色阶梯形的线(Hard Sigmoid).
如下图所示,每一个neuron都可以制造出蓝色阶梯形的线,然后把它们加起来,再加上常数项,就可以产生Piecewise Linear.
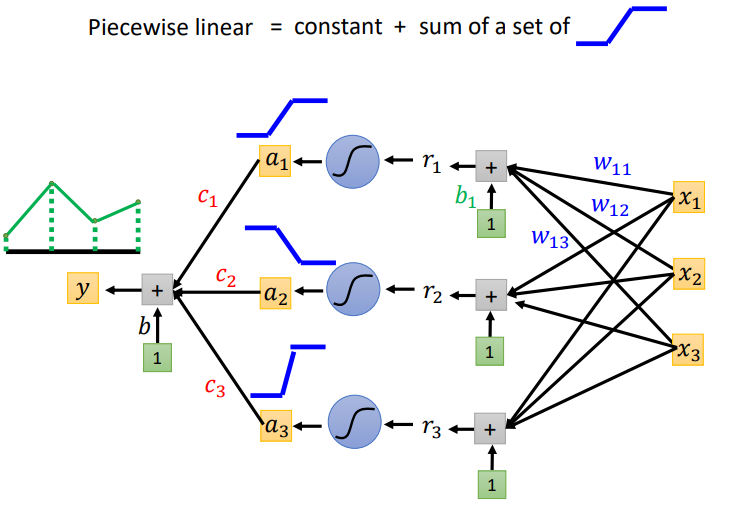
所以我们只要有足够多的neuron,我们就可以产生其它任何的Function.
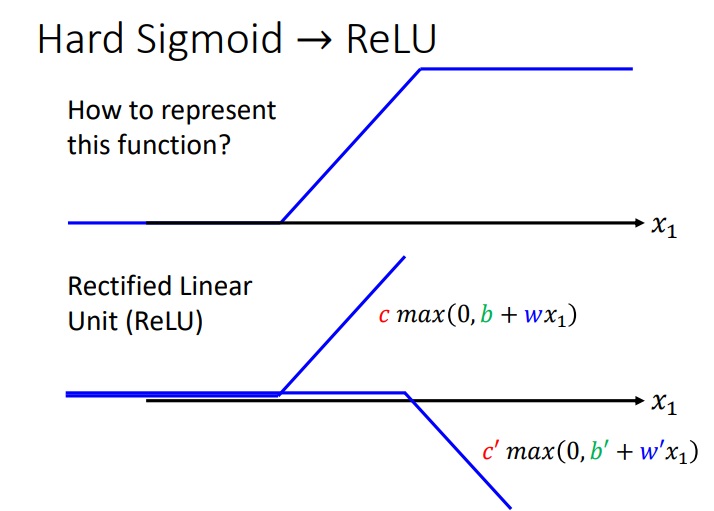
2.2 Hard Sigmoid → ReLU
Hard Sigmoid Function可以由两个ReLU Function所组成,ReLU Function如下图所示.
如下图所示,假设Network里面的neuron都是ReLU.只要有足够多的ReLU,把它们组合起来,就可以变成Piecewise Linear,这个Piecewise Linear可以逼近任何的Function.
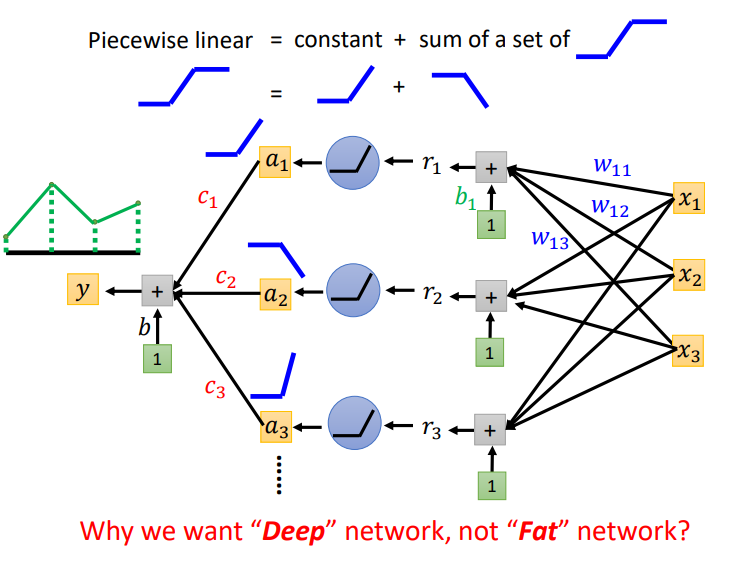
那么我们会说只要有一个足够宽的 Hidden Layer就可以模拟任何function,那么为什么需要deep呢?
3. Deeper is Better?
如下图所示,这里是对语音辨识性能的研究.我们可以发现Network越深,错误率越低.当我们把Network越叠越深时,H就会越来越大,理想的Loss会越来越低,就算有足够多的资料量,理想与现实也不会差太多.

深度学习不仅需要大模型,也需要大量的训练资料.如果没有大量的训练资料,就会出现overfitting.
4. Fat + Short v.s. Thin + Tall
如下图所示,我们可以让模型横向发展,也就是把模型变胖,这样也可以制造很大的模型.现在我们让Shallow Network和Deep Network有一样的参数,看谁的表现更好?
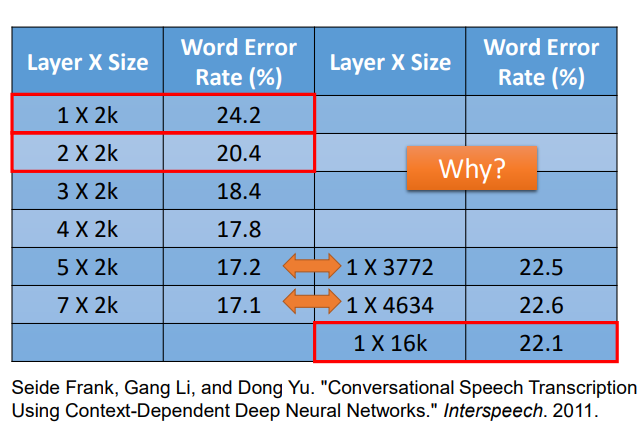
如上图所示,当参数量相同时(同一行参数量近似),Deep Network比Shallow Network的表现更好,错误率更低.
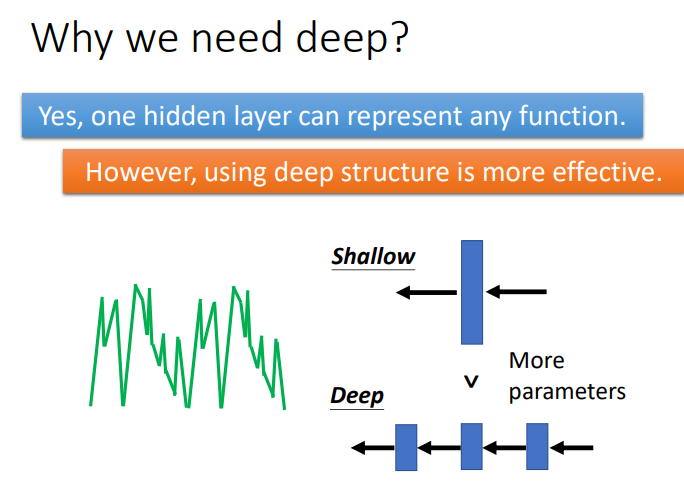
5. Why we need deep?
看了上面实验,我们可能会提出一个疑问,为什么将Network变高会比Network变胖更有效呢?
当表示某一个Function时,使用Deep的架构更加有效率,因为Deep使用的参数比Shallow使用的参数少.
6. Analogy – Logic Circuits