Day 01
发布时间 2023-05-31 20:48:27作者: 翻斗花园小美Q
- hyperparameters 超参数
- Gradient Descent 梯度下降算法
- 先选一个初始的参数,W 、b,计算θ0对你的loss function的Gradient,也就是计算每一个network里面的参数,w1、w2、b1、b2......等等。对你的L(θ0)的偏微分,计算出这个东西之后,这个gradient其实是一个vector(向量),计算出这个vector之后,就可以去更新参数吧,然后
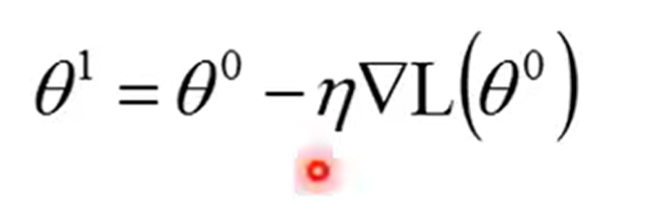 这样计算,持续这个过程,计算θ1、θ2. ..
这样计算,持续这个过程,计算θ1、θ2. ..
- 当我们用Gradient Descent方法的时候,跟我们在做Logistic Regression、还有Linear Regression等等,是没有太大的差别的,最大的差别是,在neural network里面,我们有非常非常多的参数,用Backpropagation来做(它也是Gradient Descent,不过它比较有效率去计算vector。)
- Backpropagation之Chain Rule (链式法则) 偏导数
- Sigmoid函数:常见的S型函数
- Optimization 最优化
- Overfitting 过拟合
- Perceptron 感知机
- Backpropagation 反向传播
- Logistic Regression 逻辑回归
- Mean Square error 均方误差
- Discrimination 区分度
- Generation Learning 生成学习