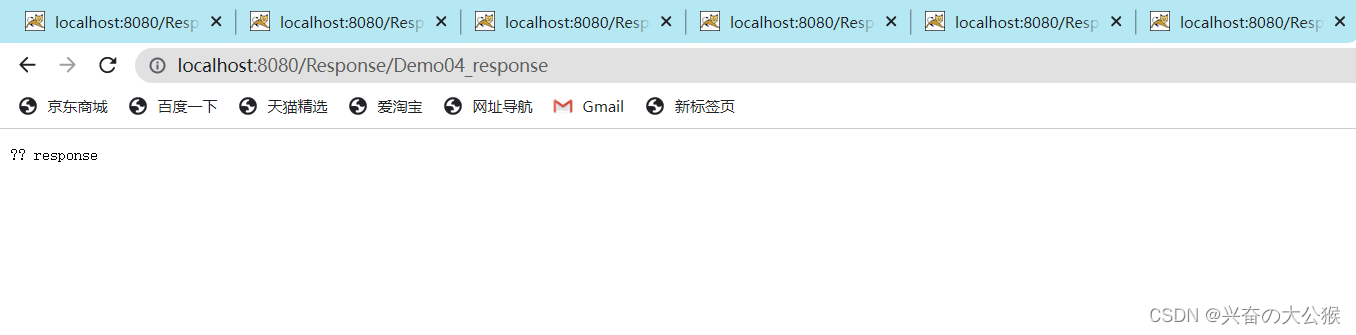
出现乱码代码
@Override protected void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException { //1.获取字符输出流 PrintWriter pw = response.getWriter(); pw.write("你好 response"); }
问题分析
出现问题这样的问题的原因是浏览器默认的为我们系统使用的字符集,一般默认为GBK,而PrintWriter对象是我们从response获取而来的,而服务器默认的字符集为utf-8,所以就会出现乱码情况,如果是自己创建的PrintWriter对象的话,就不会出现这种情况.所以只需要让浏览器知道服务器使用的是什么编码,并且对浏览器的请求头content-type进行修改就可以解决编码不一致的问题了
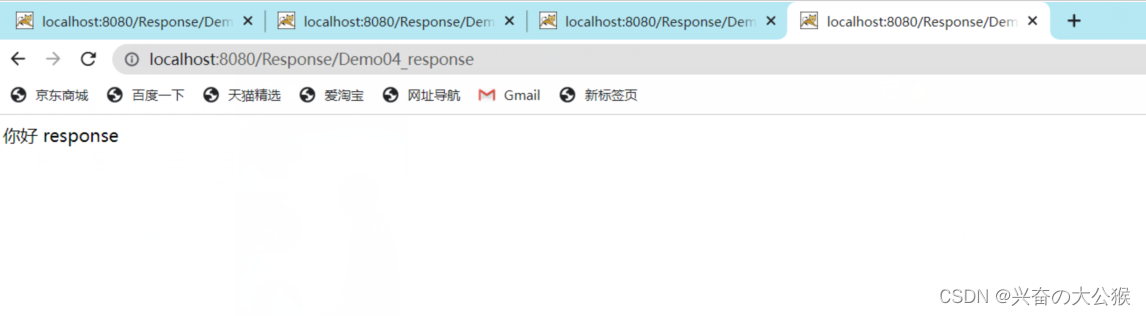
修改后的代码
@Override protected void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException { //在获取流对象之前告诉浏览器使用什么字符集 response.setCharacterEncoding("utf-8"); //告诉浏览器,服务器发送的消息体的数据的编码 response.setHeader("content-type","text/html;charset=utf-8"); //1.获取字符输出流 PrintWriter pw = response.getWriter(); pw.write("你好 response"); }
补充:
除了以上的方法,还有更简单的方法,就是直接设置 response.setContentType(“text/html;charset=utf-8”);
其效果也是一样的
//简单的设置编码的方法 response.setContentType("text/html;charset=utf-8");
https://blog.csdn.net/qq_46274901/article/details/123167231#:~:text=%E5%87%BA%E7%8E%B0%E9%97%AE%E9%A2%98%E8%BF%99%E6%A0%B7%E7%9A%84%E9%97%AE,%E7%A0%81%E4%B8%8D%E4%B8%80%E8%87%B4%E7%9A%84%E9%97%AE%E9%A2%98%E4%BA%86