JVM架构概述
0. 术语介绍
Java SE 全称 Java Platform, Standard Edition,提供Java语言的核心API,核心类库和语法定义。本质上是Java语言的一种约定规范。
Java EE Java Platform,Enterprise Edition,Java平台的一个分支,是一套专注于大型,分布式,企业级的应用程序开发和运行的规范。
JVM Java Virtual Machine,是运行Java应用程序的平台。具体点说是正确高效运行相应版本字节码文件的平台,不只是针对于Java语言。
JRE Java Runtime Environment,轻量级的Java运行环境,包含JVM和运行Java程序所需要的类库,但是没有开发工具如编译器和调试器。
JDK Java Development Kit,用于开发Java应用程序的开发工具包。包含了JavaSE和相应的开发工具如编译器,调试器和JVM等集成开发所必须的内容。
1. 什么是JVM?
JVM全称为Java Virtual Machine(Java虚拟机),请注意JVM首先是虚拟机然后才是Java虚拟机。
-
虚拟机是使用软件对现代电子计算机的一种仿真,用户在具体的业务中经常是需要在宿主机器(系统)中仿真出多个虚拟机以适配不同平台的软件。现代虚拟机的实现方式中通常是使用一种叫虚拟机监视器(VMM,Hypervisor)的系统来创建和管理虚拟机。Hypervisor是用于创建和运行虚拟机的软件和硬件集合。
-
其次作为Java虚拟机,可以认为是该虚拟机中可以直接运行相应的Java程序,也可以将其视作Java程序和底层真实机器之间一个软件层。最初JVM是专为Java设计的,后续在此基础上发展出了其他的适配语言如Kotlin,Scale,Groovy ,Clojure,Jython,JRuby等。
JVM设计的初衷是希望能让某些编程语言可以一次编写,到处运行(Write once,run anywhere)。使用JDK中的javac命令将源代码翻译成字节码文件(后缀为.class文件),然后字节码文件在不同平台中具有普遍适用性,直接使用相应的JVM进行运行即可。这样就保证了Java语言的跨平台性。
如何使用JVM,通过特定的启动器(Launcher)创建VM实例然后在其上运行字节码文件。
下面是JVM的三个主要组件:
- ClassLoader,类加载器
- Runtime Memory/Data Area,运行数据区
- Execution Engine,运行引擎
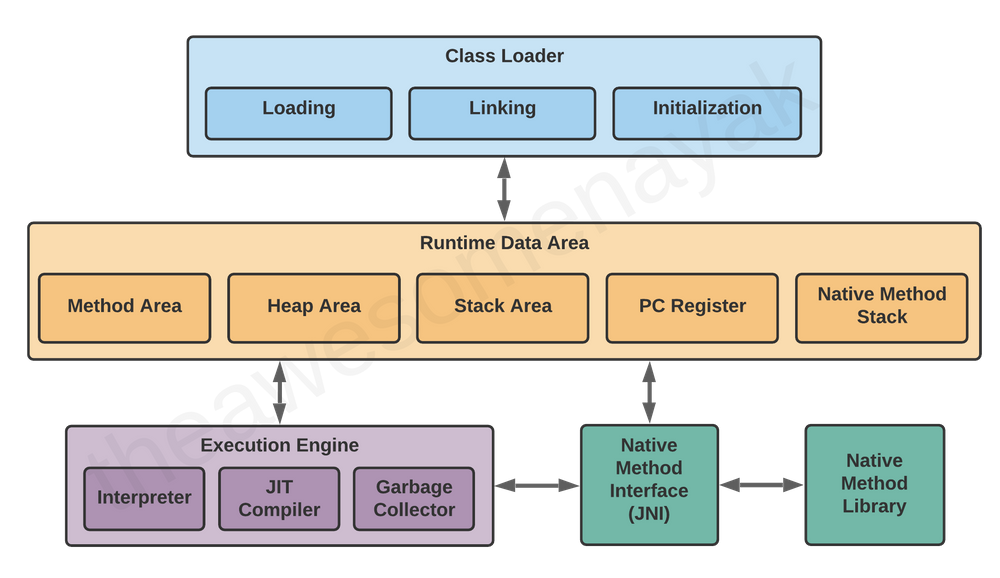
接下来我们详细介绍这三个组件。
2. 类加载器(ClassLoader)
针对某个字节码文件中所代表的类,如果我们在Java应用中需要使用到这个类,那么我们的JVM将首先通过类加载器机制将这个类装载到内存(JVM的运行数据区)中。整个类加载机制有三个主要的阶段:加载(loading)/链接(linking)/初始化(initialization)。
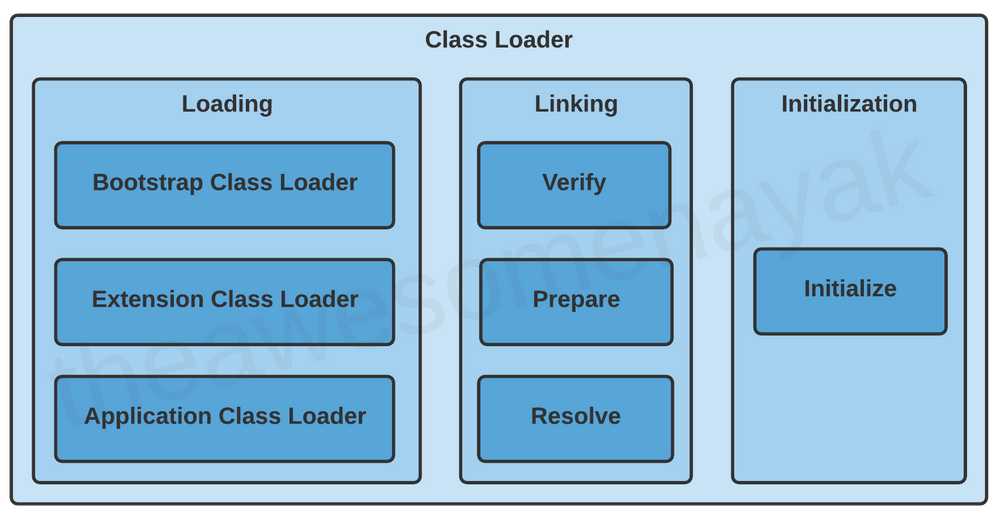
下面我们将详细介绍每个阶段JVM都做了什么。
2.1 Loading
所谓的加载阶段,便是从某个特定名称(一般是全限定类名)的类/接口从硬盘中的字节码文件加载到JVM的运行数据区(Method Area)。整个加载过程主要是通过内置的类加载器来完成,具体就是ClassLoader.laodClass(name,resolve)方法来加载特定名称的类。JVM内置了三个类加载器,他们分别是:
- Bootstrap ClassLoader: 根加载器,加载
java.lang,java.net,java.util,java.io等位于rt.jar和JAVA_HOME/jre/lib的基本的包。 - Extension ClassLoader: Bootstrap的子类,加载位于
JAVA_HOME/jre/lib/ext文件夹的拓展标准库(extensions of standard Java Libraries) - Application ClassLoader: Extension ClassLoader: 加载位于
CLASSPATH中的包,默认的classpath就是应用的当前文件夹,可以通过命令行中的-classpath或者-cp进行特殊指定。
那么JVM中的类加载器是如何加载类的呢?
JVM在加载类的时候,采用委托模式。也就是当一个类加载器无法找到类的时候,便将该工作委托给其子加载器,如果其最终无法找到则抛出NoClassFoundError或者ClassNotFoundException。、
同步JVM在启动的时候,首先加载具有Main函数的类,然后根据其依赖关系后续加载相关的依赖类。
我们什么时候需要自定义的类加载器吗?
如果我们需要自定义类加载器,那么继承java.lang.ClassLoader即可,如、
The network class loader subclass must define the methods {@link
#findClass <tt>findClass</tt>} and <tt>loadClassData</tt> to load a class
from the network. Once it has downloaded the bytes that make up the class,
it should use the method {@link #defineClass <tt>defineClass</tt>} to
create a class instance. A sample implementation is:
class NetworkClassLoader extends ClassLoader {
String host;
int port;
public Class findClass(String name) {
byte[] b = loadClassData(name);
return defineClass(name, b, 0, b.length);
}
private byte[] loadClassData(String name) {
// load the class data from the connection
}
}
2.2 Linking
总的来说,linking阶段涉及到的是将某个类相关的依赖元素和该类组织在一起,具体的是将原来的符号链接转换为直接的内存位置链接。详细的流程设计到以下的三个阶段:
- 验证(Verification):检查类对应的
.class文件的格式,检查的标准是相应版本和JVM内置的一些限制或者规则。比如.class文件是在JDK 11中编译出来的,但是运行在Java8的环境中,此时便会出现验证不通过的情况,抛出VerifyException。 - 准备(Preparation):JVM为类或者接口中的静态变量分配内存,并且使用默认是进行初始化。比如类型为
boolean的静态变量会被初始化为false,对象引用的静态变量会被初始化为null。 - 解析(Resolution):符号引用将被替换为运行常量池中的直接引用(运行时环境中真实的引用)。比如当前类有一个引用其他类或者其他类的常量,那么在这个阶段将他替换为常量池中真实的引用。
2.3 Initialization
这个部分主要是运行类或者接口中初始化方法:<clinit>。首先这个方法是源代码在编译时由编译器自动生成的嵌入在.class文件中,然后在该阶段运行该方法,其次该方法的作用是按顺序收集(运行)类中的静态变量的赋值操作和静态代码块。通过这样便可以将类中的静态变量进行初始化,并且运行类中的静态代码块。可以将
3. 运行数据区(Runtime Data Area)
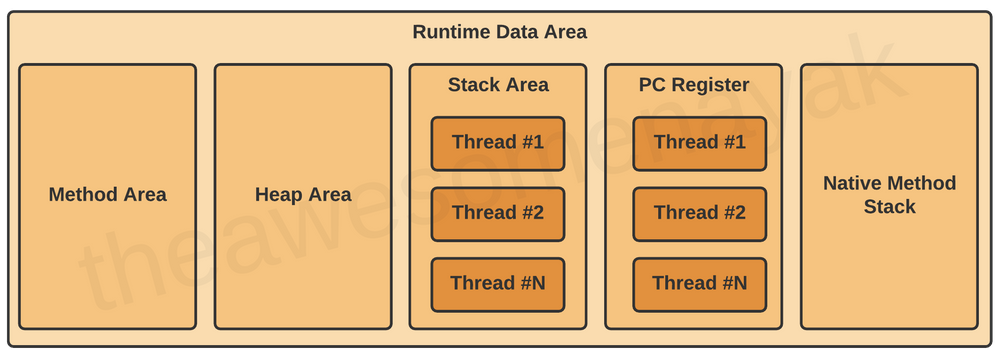
JVM的运行数据区分为5个部分:
- Method Area(方法区):存储类层面的数据,运行时常量池,类的成员变量描述,方法的描述和代码,构造器。
- Heao Area(堆区):所有的对象(和数组)以及相应的实例变量都存储在该区。这是运行时中为实例对象分配内存空间的区域。
- Stack Area(栈区):每当有一个新的线程被创建的时候同步在该区域同步创建一个属于该线程的独立运行时栈区。
- PC Register(程序计数器寄存器):JVM中每个线程都对应一个程序计数器来跟踪线程当前执行的指令地址。
- Native Method Stack(本地方法栈):该栈用于支持
native method
3.1 Method Area
首先Method Area是在VM启动的时候(start-up)创建的,因此每个JVM实例只能有一个方法区。其次如果方法区中的内存超限了,JVM将抛出OutOfMemoryError。
其次Method Area中存放哪些数据:
- 类信息:类的版本,字段,方法和接口的信息。
- 静态变量:类中的静态变量信息。
- 即时编译器编译后的代码:JVM即使编译器编译后的本地机器代码,可以视作优化信息。
- 运行时的常量池:
- 字面量:如文本字符串,被final声明的常量。
- 符号引用:类和结构的全限定名称,各个类中字段的名称和描述符,各个类中方法的名称和描述符等。这些都是引用,方便JVM进行查找的,不包括具体的数据。
- 注意:常量池中存储的信息在编译期间就已经确定,在类加载时期被加载到内存中,运行时期被JVM所使用。
3.2 Heap Area
和Method Area一样,Heap Area都是在JVM的start-up阶段创建的,因此一个JVM实例中只有一个Heap Area。多个线程共享这个区域,因此该区域是线程不安全的。
同时一般是在new操作中,会涉及到在Heap Area中申请内存空间。比如类的实例化,数组的实例化。
3.3 Stack Area
如果该线程中使用的局部空间大于了JVM所分配的栈区大小,那么JVM会抛出StackOverflowError。该线程每次调用方法,所对应的栈区中便会创建一个称为栈帧的片段,当方法运行完成之后该帧自动被回收。栈帧被分为了下面的三个部分:
- 局部变量数组(Local Variables):每一帧中都使用一个数组来组织它的局部变量,所有局部变量和他们的值都存在该数组中,同时该数组的长度在编译器便被确定了。
- 操作符栈(Operand Stack):每一帧中都存在一个LIFO的典型栈来组织该过程中的操作符。作为该过程中的一个工作区来执行所有中间操作和中间结果。栈的深度也是在编译期被确定的。
- 帧数据:帧数据分为三个部分
- 动态链接:用于支持方法调用过程中的动态链接,如需要调用其他方法时,存储该方法的引用。因为需要在运行时才能确定,所以称为动态链接。除此之外还有对常量的引用(常量池链接)等。
- 方法返回地址:存储方法返回之后需要跳转的地址。
- 附加信息:存储用于支持异常处理的信息。
3.4 PC Register
每个线程的程序计数器。
3.5 Native Method Stacks
用于支持native method的栈区。其中native method一般是使用其他语言实现的方法如C/C++等。对每一个线程,JVM都会为其分配一片独立的区域。
4. 执行引擎(Execution Engine)
通过上述的类加载机制,我们的类信息及其各种细节都被加载到了相应的数据区域。下一步便是执行这些内容。
但是在运行内存中的代码之前,我们需要将这些字节码的指令转换为相应平台的机器指令。JVM采用以下的Interpreter或者JIT编译器来完成这个转换过程,同时为了保证程序正常的运行,JVM提供了自动的垃圾回收机制。下面是执行引擎的三个部分,接下来我们详细介绍每个部分。
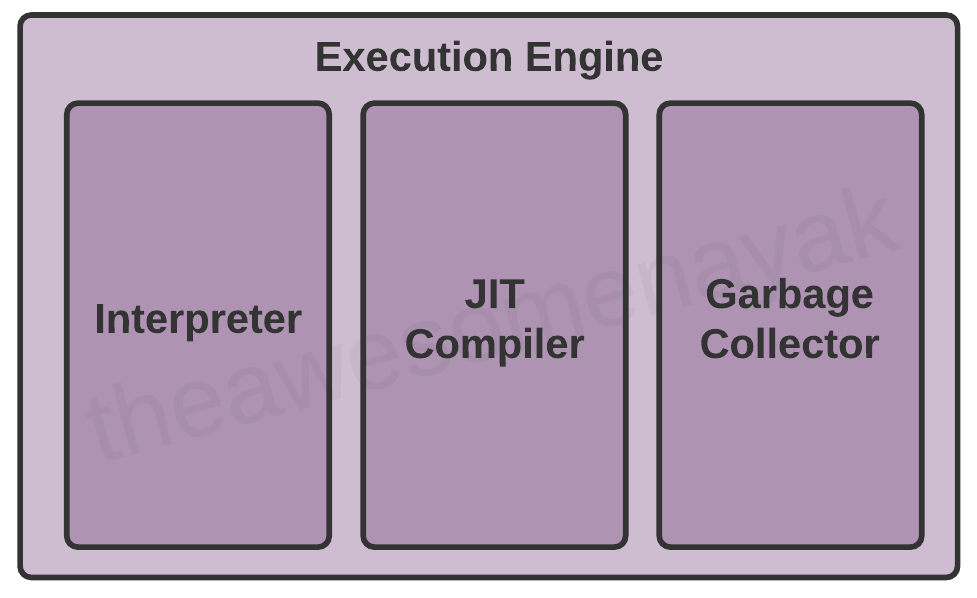
4.1 Interpreter(解释器,翻译器)
解释器是逐行的去阅读和执行字节码。这意味着使用解释器运行字节码指令不仅非常缓慢而且对于重复执行的代码片段需要反复进行解释。
4.2 JIT Complier(即使编译器)
JIT主要是解决了解释器需要反复解释相同代码(热点代码hotspots)的问题。
大体的做法是:执行引擎首先使用解释器运行代码,当引擎发现热点代码之后就使用JIT编译器,然后JIT将这些字节码直接编译成本地的机器码,这些机器码将在后续反复的运行中被调用,而不需要重新翻译一遍。
JIT编译器的组成部分
- 中间代码生成器(Intermediate Code Generator):生成中间代码。
- 代码优化器(Code Optimizer):优化中间代码,以获得更佳的性能。
- 目标代码生成器(Target Code Generator):将中间代码转换为本地机器码。
- Profiler:寻找热点代码。
实际使用中注意:
JIT编译器相比于解释器在翻译代码方面需要花费更多的时间,因此如果程序只需要运行一次,那么使用解释器速度会更快。但是如果对于类似服务需要常驻后台的程序,JIT显然优势更加明显。
4.3 Garbage Collector(垃圾回收器,GC)
GC可以收集和删除哪些未被引用的对象,它是一个自动回收闲置空间的过程。GC使得Java的内存管理更加高效,因为它可以使得那些闲置的对象被回收然后给新的对象腾出空间,这中间涉及到两个过程:
- Mark(标记):GC将识别内存中那些没有被引用的对象。
- Sweep(移除):GC将回收那些在第一个阶段中被标记的内存。
GC是可以自动在一定的时间间隔中自动执行内存回收任务的过程,不需要手动去管理,当然也可以调用System.gc()去手动触发不过这个调用不一定真正出发GC。JVM中内置了三种不同的GC:
- Serial GC(串行GC):这是GC最简单的实现方式,针对那些单线程的简单应用。GC也使用一个单线程来处理回收,当该线程运行的时候,GC将触发一个
stop the world的事件使得整个应用暂停。JVM中指定穿行GC的参数是:-XX:+UseSerialGC。 - Parallel GC(并行GC):这是GC的默认实现方式,也称为Throughput Collector,该GC使用多个线程来进行GC处理,但是当进行 回收的时候,应用依然会暂停。JVM 中指定并行GC的参数是:
-XX:+UseParallelGC。 - Grabage First(G1)GC:专门为那些大堆区的多线程的应用设计的GC。它是将堆区划分为几个相同大小的区域,然后使用多个线程去不断扫描这些区域。G1GC每次都是选择那些垃圾最多的区域进行垃圾回收的操作。JVM指定G1GC的参数是:
-XX:+UseG1GC。
5. Java Native Interface(JNI)
有时候在我们的应用中需要使用一些非Java的代码,这个时候我们可以使用JNI来实现,具体需要使用JNI的场景可以是:
- 需要和底层的硬件交互。
- 需要克服Java的内存管理和性能约束(瓶颈)。
- 一些特定平台的代码。
在Java代码中我们可以使用native关键词来表明该方法是使用非Java代码实现的,再次之前我们需要在调用System.loadLibrary()将共享的原生库加载到JVM中。这些原生库可以使用C/C++/汇编编写,格式一般是.dll或者.so,这些格式的库可以被JNI加载到JVM的内存中。