利用图像特征提升准确度
我们之前仅仅是逐个像素的计算, 而忽视和图像在HSV空间的像素集中度和图像纹理特征. 根据别人的博客,准确率进一步从54%提升到58%. 下面进行解析.
HOG/颜色直方图代码解读
本次的作业没有要求我们自己实现, 但是我们还是应该读懂代码. 在前面, 我们一直希望我们的网络能够抓住主要矛盾, 识别出目标而不要基于背景太多权重. 为此, 我们引入了HOG. 首页就能搜到的文章一文讲解方向梯度直方图(hog) - 知乎 (zhihu.com) 讲解的相当好, 其实HOG反应就是图像的亮度梯度的方向, 而HOG利用离散化的角度来反应这个方向.其中的大概步骤再次总结如下:
- 通过x和y方向的sobel算子来计算梯度
- 二者结合计算总梯度大小和方向
- 将图像划分成一定尺寸的cell,根据cell内角度的范围归类到HOG表
- 对由数个cell组成的block通过滑动窗口方法归一化(这里没做)
下面是对原始代码的注释:
if im.ndim == 3:
image = rgb2gray(im) # 转换为灰度图,不考虑色度信息
else:
image = np.at_least_2d(im)
sx, sy = image.shape # 图像尺寸
orientations = 9 # 梯度的角度分类为9, 即按照0~20度/20~40度...
cx, cy = (8, 8) # cell的大小为8*8
gx = np.zeros(image.shape)
gy = np.zeros(image.shape)
gx[:, :-1] = np.diff(image, n=1, axis=1) # 生成x向的梯度
gy[:-1, :] = np.diff(image, n=1, axis=0) # y向梯度
grad_mag = np.sqrt(gx ** 2 + gy ** 2) # 总梯度大小
grad_ori = np.arctan2(gy, (gx + 1e-15)) * (180 / np.pi) + 90 # 总梯度方向. 这里+1e-15目的是防止gx=0下arctan求不出来
n_cellsx = int(np.floor(sx / cx)) # x向cell个数
n_cellsy = int(np.floor(sy / cy)) # y向cell个数
orientation_histogram = np.zeros((n_cellsx, n_cellsy, orientations)) # 构造cell为单位的HOG表
for i in range(orientations):
temp_ori = np.where(grad_ori < 180 / orientations * (i + 1), # 解算出梯度小于某个格子上限处的点,成立原样返回,否则返回0
grad_ori, 0)
temp_ori = np.where(grad_ori >= 180 / orientations * i,
temp_ori, 0)
cond2 = temp_ori > 0 # 不允许梯度=0
temp_mag = np.where(cond2, grad_mag, 0) # 获取它们的幅度
orientation_histogram[:,:,i] = uniform_filter(temp_mag, size=(cx, cy))[round(cx/2)::cx, round(cy/2)::cy].T # 均匀化
return orientation_histogram.ravel() # 数组展平,和flatten区别在于hist改变,这个值也会同步变化而颜色直方图仅仅是对色相进行直方图统计. 这个代码相对简单, 就不解读了. 关键是这里hue也是正则化为0-255,和opencv有所不同, 此外imhist = imhist * np.diff(bin_edges) 这句考虑了格子长度的影响.
下面我们需要将两个特征合并成单个行向量. 因为HOG表的长度为(32/8)^2*9 = 144, 而颜色直方图的长度为10, 结果就是154长度, 对SVM还需要加上最后一项用于去除偏置项. 这里的extract_features函数通过传入lambda函数, 一行一行叠加,生成最终矩阵规模为49000*154, 从lambda原始形式直到其是按HOG 0~143, 颜色直方图144~153摆放的, 因为分类器应可以针对不同数据基于不同权重,所以摆放顺序不重要. 此外这里并没有对HOG做后处理, 因为理想情况下神经网络就应该由神经网络决策喂进去的信息对于结果贡献程度, 我们只需要显式放进去信息就行. 但也正因此, 超参数的选取只会更重要.
调参
下面要做的本质上就是利用不同的超参数来进行探究. 这里的代码和前面类似, 也不多写了. 参考其他博客选取, 结果如下:

需要注意的是,我实验了数次,曾得到了一次lr=1.2e-7,reg=5e4(注意不是5e-4)下准确率为43.0%的例子, lr影响不算很大,这个答案不是唯一的, 但是reg影响会非常大. 下面是我自己的另一个实验,按照lr=1.2e-7计算,考察reg的不同结果:

这里不难看出, 这里过拟合带来的后果是很严重的, 所以上升reg初期会使得准确度大幅上升, 但是后面就不明显了,可能是我这里reg取得不是很大,增大reg后的欠拟合不明显. 下面附上reg=0,1e-4,2e-4的loss变化: (※不同图片间的误差不能互相比较!!)
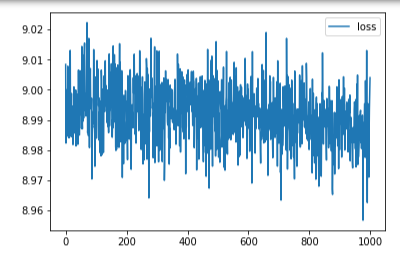
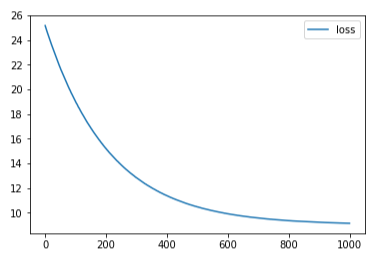
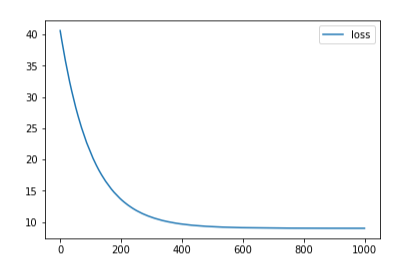
下面是另一个博主实验神经网络获得的结果(其隐含层数很大, 不致造成瓶颈):

我们看出, 学习率的影响同样不算很大(除非太大导致不能收敛!), reg太大出现了欠拟合,准确率急剧下降, 但是Reg很小影响反而又不大(上面的图说明不了, 我自己reg=0下其他参数最优准确率为56.8%). 只能说, 这东西着实是玄学, 超参数对于不同场景, 不同模型都必须依靠实践才能获得, 不同场景下的结论是不能通用的! 最终reg=1e-3,lr=0.5,和前面不是一个数量级.
问题

回答: 我们回顾一下正确分类的图片: (左正确右错误)

首先, 部分错误在色调分布上和正确的明显类似, 典型的包含frog和plane的部分图片, 当然其中有些是色调和颜色梯度分布都很类似的, 例如:

仅仅亮度梯度类似的,色调明显不同的:

不过有一些是结果明显但依然分类错的:

上面的图片青蛙特征明显, 但是和马的梯度接近, 所以马的打分也会比较高.