GAN总结
本篇文章主要是根据GitHub上的GAN代码库[PyTorch-GAN]进行GAN的复习和回顾,对于之前GAN的各种结构的一种简要的概括。
Code
ACGAN
acgan的全称是auxiliary classifier gan,辅助分类器gan,是一种有监督的生成对抗网络,其主要思想是在生成器和判别器中加入分类器,使得生成器和判别器都能够学习到数据的类别信息,从而提高生成器和判别器的性能。相比于CGAN直接进行分类loss的反向传播,acgan在生成器和判别器中都加入了分类损失,除了GAN loss,还引入了分类器loss.
生成器(Generator):
生成器接受输入的噪声向量 z 和类别标签 y,并生成伪造的图像 x̃。
判别器(Discriminator):
判别器接受真实图像 x 和对应的类别标签 y,以及生成图像 x̃ 和对应的类别标签 y,并输出概率值表示真实图像或生成图像的可能性。
鉴别器损失函数(Discriminator Loss):
鉴别器的目标是最小化真实图像的误分类概率和最大化生成图像的误分类概率。
生成器损失函数(Generator Loss):
生成器的目标是最大化生成图像被判别为真实图像的概率。
分类器损失函数(Auxiliary Classifier Loss):
ACGAN还具有一个分类器 C,它使用生成图像和真实图像的类别标签进行训练。分类器的目标是最小化生成图像和真实图像之间的类别预测误差。
总体损失函数:
其中,λ 是用于平衡生成器和分类器损失的超参数。
ACGAN模型通过引入类别信息,能够生成具有特定类别属性的图像,并且通过分类器提供了更好的控制和可解释性。
Adversarial Autoencoders
AAE 实在VAE上的变种,回想VAE的架构。
VAE分为Encoder和Decoder,Encoder将输入的数据映射到潜在空间(将训练数据的分布映射为一个多维高斯分布 ),Decoder将潜在空间的向量映射到原始数据空间,VAE的目标是最小化重构误差和潜在空间的正则项,从而使得潜在空间的向量能够更好的表示原始数据。
VAE的损失函数主要来自两个方面:
- 重构损失,数据经过Encoder和Decoder的重构误差。
- KL散度,数据经过Encoder映射到潜在空间的向量分布与高斯分布的差异,这个loss强制潜空间的分布符合高斯分布。
AAE就针对第二点提出了一个新的想法,使用GAN来代替KL散度。它通过训练一个额外的判别器来强制潜在空间的向量分布符合高斯分布,判别器会分辨Encoder输出的latent Embedding是否符合特定分布。然后按照GAN的范式来交替更新Encoder、Decoder和判别器。
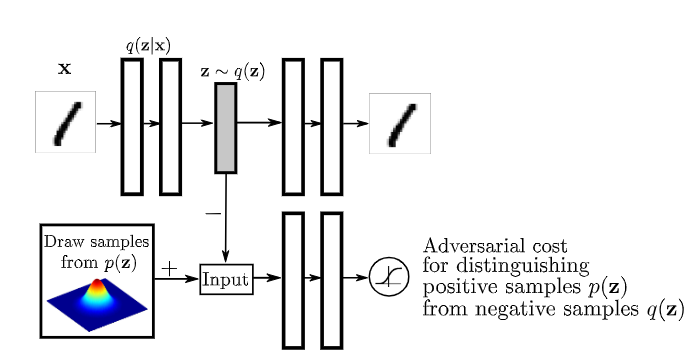
上述是用于重构的AAE,用于VAE的一些技术也可以用于AAE,例如添加分类信息、使用半监督学习、无监督学习等,下面给出半监督学习和无监督学习的架构,看图应该就可以理解了。
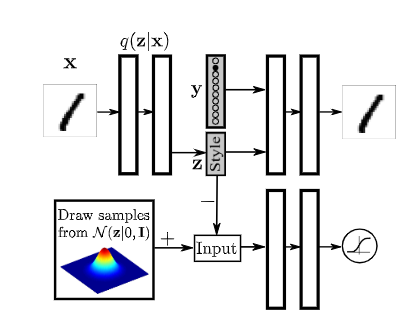
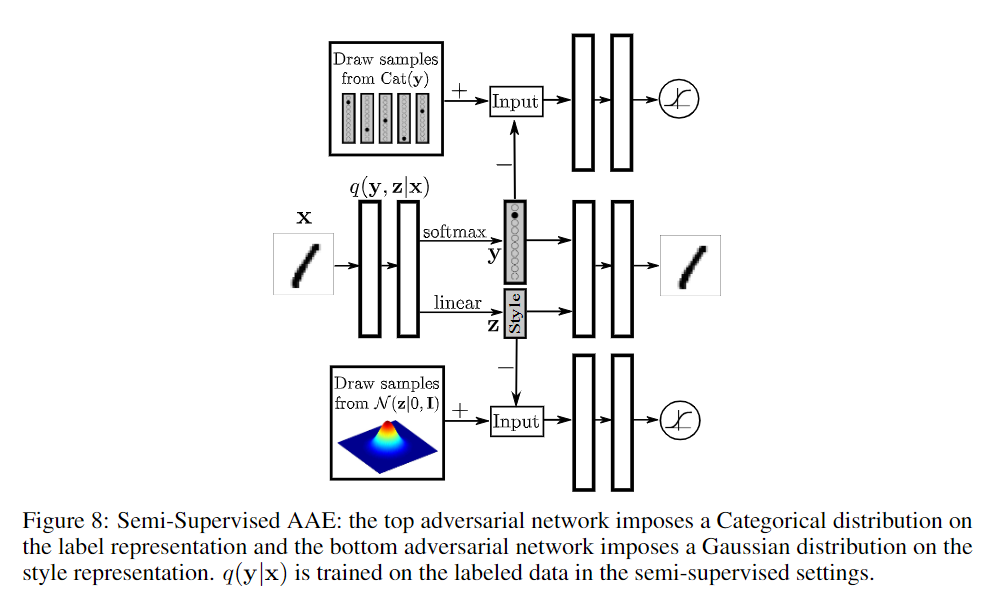
WGAN
WGAN(Wasserstein Generative Adversarial Networks)是一种生成对抗网络模型,其具有以下创新点:
-
使用Wasserstein距离代替传统的JS散度:WGAN引入了Wasserstein距离作为衡量真实分布与生成分布之间差异的指标。相比于传统的JS散度,Wasserstein距离具有更好的数值稳定性和连续性,能够提供更可靠的梯度信号,从而使训练过程更加稳定。
-
判别器的权重剪裁:为了满足Wasserstein距离的要求,WGAN通过对判别器的权重进行剪裁,将权重限制在一个预定义的范围内。这种权重剪裁机制有助于避免梯度消失或爆炸问题,并促使判别器学习到更加平滑且良好的输出。
-
去除了传统GAN中的sigmoid函数和log损失函数:WGAN不使用sigmoid函数作为判别器的最后一层激活函数,也不使用二元交叉熵损失函数。取而代之的是,判别器只需线性输出,同时使用Wasserstein距离作为损失函数。这种改变避免了训练过程中的梯度消失问题,提高了训练的稳定性。
-
基于梯度惩罚的正则化方法:为了满足Wasserstein距离的Lipschitz连续性要求,WGAN引入了梯度惩罚的正则化方法。该方法通过对判别器在真实图像和生成图像之间的采样点上计算的梯度进行惩罚,来推动判别器的参数满足Lipschitz条件。
这些创新点使得WGAN能够更好地解决传统GAN中存在的训练不稳定、模式崩溃等问题,并提供了一种理论上更可靠的损失函数及训练策略。WGAN的引入对生成对抗网络的发展具有重要意义。
他还有具有一些变种,例如WGAN-GP,WGAN-DIV,WGAN-LP等,这些变种都是在WGAN的基础上进行改进,例如WGAN-GP是在WGAN的基础上引入了梯度惩罚,WGAN-DIV是在WGAN的基础上引入了KL散度,WGAN-LP是在WGAN的基础上引入了Lp范数。
WGAN:对于每一个中间参数的梯度都进行剪裁,使得梯度的范数不超过一个固定的常数c,这样就可以保证判别器满足Lipschitz连续性。
WGAN-GP:在WGAN上修改了梯度惩罚的方式,相比于直接计算loss相对于图片的loss,这篇论文将生成的FakeImg和真实Img按照一定的比例混合,然后计算梯度惩罚。
WGAN-DIV:相比于裁剪梯度,这篇论文换成了梯度正则化,求loss相对于图片的梯度,并将它的L2范数添加进loss。