Maven 篇
0. 在离线的nexus3服务器上创建所需的本地依赖仓库。(如果已经创建了依赖仓库文件夹,这个步骤可以忽略)-登录具有创建仓库权限的用户,这里使用默认用户admin示范。
创建新的仓库
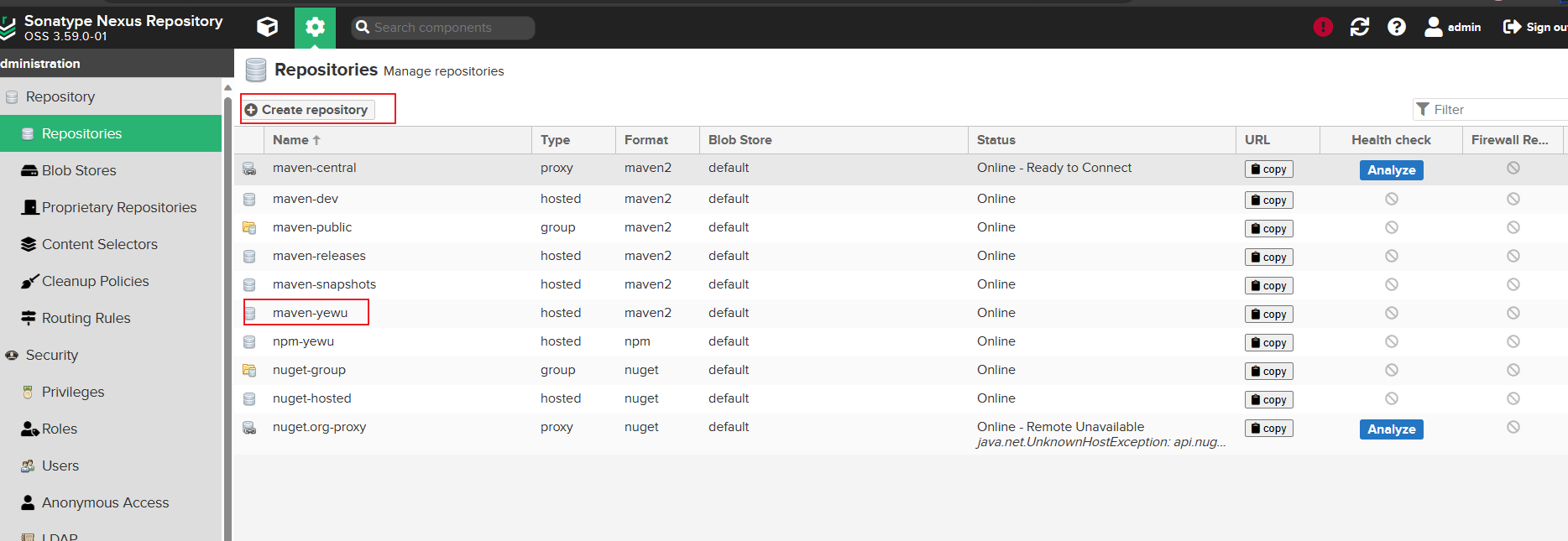
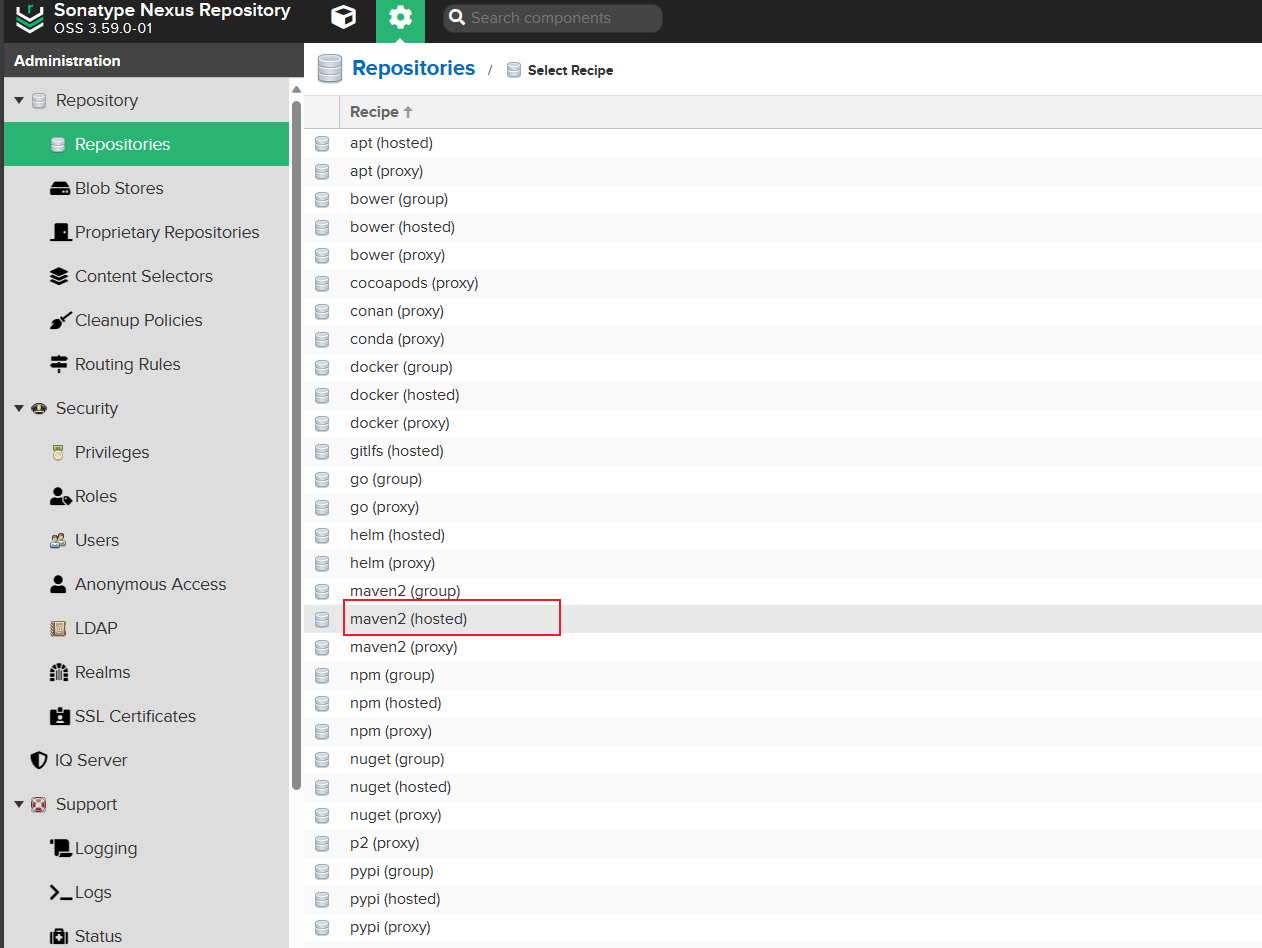
选择hosted格式的maven2仓库
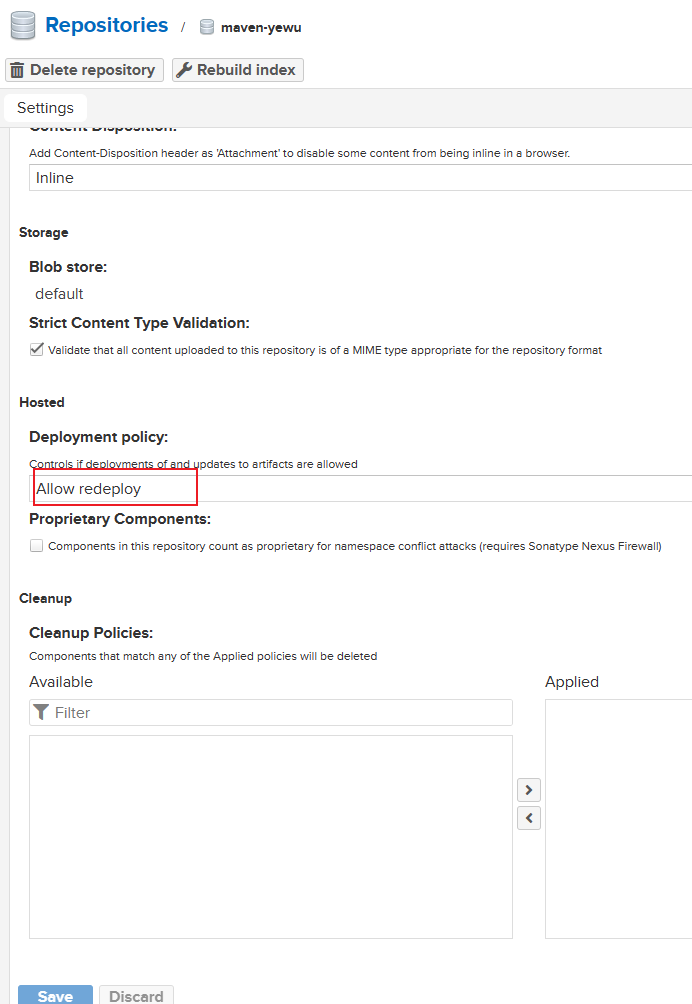
选择允许依赖的要求,其他默认
1. 准备所需的依赖文件-主体的思想就是将项目所需的依赖jar包先下载好,然后使用脚本提交到离线的nexus仓库
1. 方式一:先将项目在自己本地构建一遍,构建成功后将使用的本地仓库打包,复制到nexus服务器上,或者能访问到nexus的主机.
2. 创建脚本
创建脚本
# 创建脚本
vim mavenimport.sh
写入脚本命令
#!/bin/bash
# copy and run this script to the root of the repository directory containing files
# this script attempts to exclude uploading itself explicitly so the script name is important
# Get command line params
while getopts ":r:u:p:" opt; do
case $opt in
r) REPO_URL="$OPTARG"
;;
u) USERNAME="$OPTARG"
;;
p) PASSWORD="$OPTARG"
;;
esac
done
find . -type f -not -path './mavenimport\.sh*' -not -path '*/\.*' -not -path '*/\^archetype\-catalog\.xml*' -not -path '*/\^maven\-metadata\-local*\.xml' -not -path '*/\^maven\-metadata\-deployment*\.xml' | sed "s|^\./||" | xargs -I '{}' curl -u "$USERNAME:$PASSWORD" -X PUT -v -T {} ${REPO_URL}/{} ;
3. 执行脚本
将上传到服务器的文件解压,进入文件夹内部
执行如下命令,记得替换[]中的内容
mavenImport.sh -u [nexus3账户] -p [nexus3密码] -r http://[IP]:[端口]/repository/[仓库名称]/
npm 篇
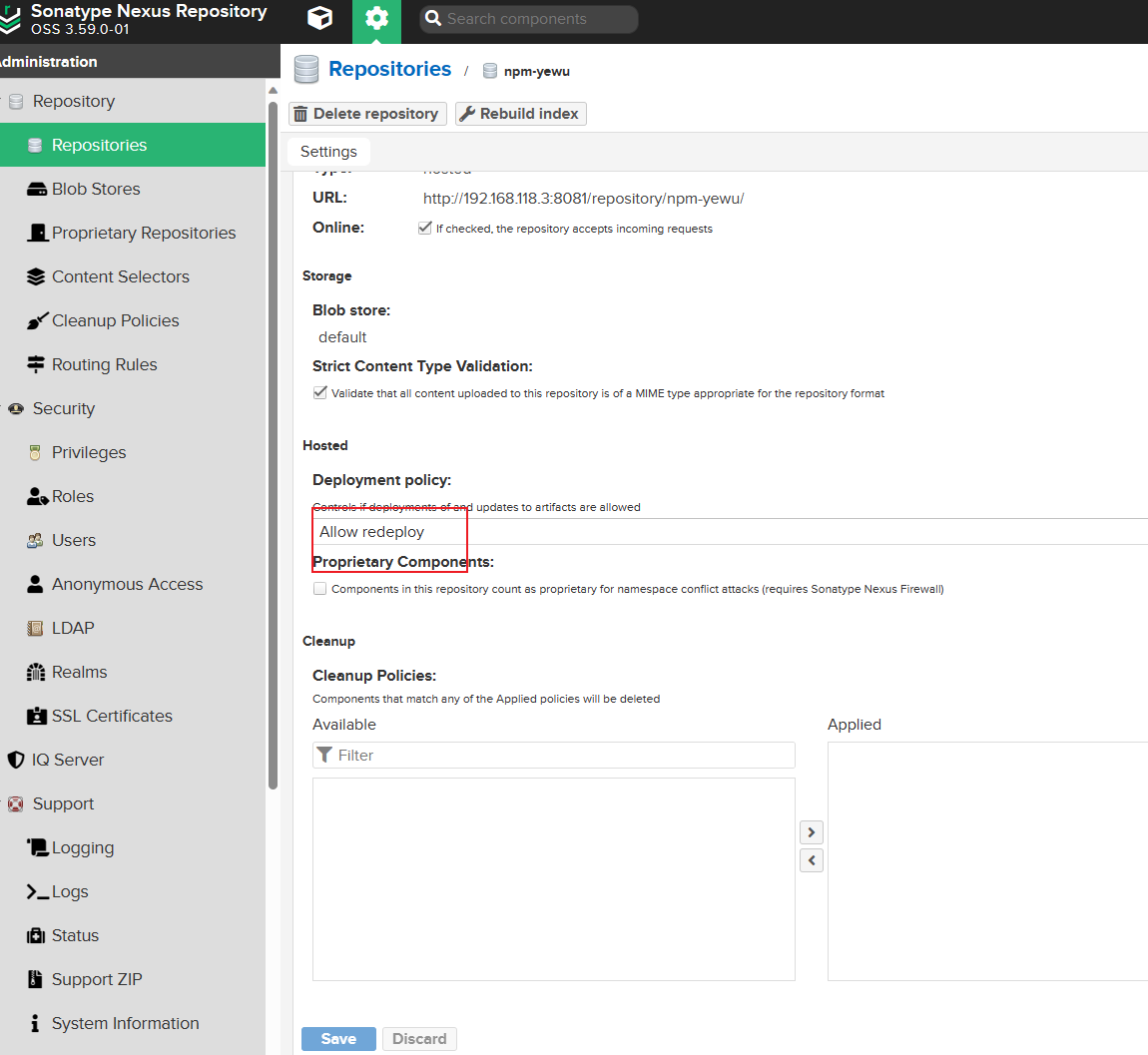
0. 创建npm仓库,步骤同上,展示创建配置,悬着npm类型的仓库
配置展示
1. 现在本地打包构建,获取到package-lock.json,或者 yarn-lock.json
2. 根据获取到的文件,执行下列Python脚本,进行下载对应的npm包。
npm 执行如下脚本
import os
import re
import aiohttp
import asyncio
from urllib.parse import urlparse
from concurrent.futures import ThreadPoolExecutor
# 创建存储文件夹
download_folder = "sourcenpm"
os.makedirs(download_folder, exist_ok=True)
# 读取文件内容
with open("pack.json", "r") as file:
content = file.read()
# 使用正则表达式匹配resolved字段的值
pattern = r'"resolved":\s+"(https:\/\/[^"]+\.tgz)"'
matches = re.findall(pattern, content)
# 异步下载函数
async def download_file(session, url):
async with session.get(url) as response:
if response.status == 200:
parsed_url = urlparse(url)
filename = os.path.basename(parsed_url.path)
full_filename = os.path.join(download_folder, filename)
content = await response.read()
with open(full_filename, "wb") as output_file:
output_file.write(content)
print(f"文件 {filename} 下载成功")
else:
print(f"无法下载文件 {url}")
async def download_with_semaphore(semaphore, session, url):
async with semaphore:
await download_file(session, url)
async def main():
# 创建异步HTTP会话
async with aiohttp.ClientSession() as session:
semaphore = asyncio.Semaphore(8) # 限制并发数为8
tasks = []
for url in matches:
tasks.append(download_with_semaphore(semaphore, session, url))
await asyncio.gather(*tasks)
print("下载完成")
# 运行异步下载
if __name__ == "__main__":
asyncio.run(main())
yarn 执行如下脚本
import os
import re
import aiohttp
import asyncio
from urllib.parse import urlparse
from concurrent.futures import ThreadPoolExecutor
# 创建存储文件夹
download_folder = "sourcenpm"
os.makedirs(download_folder, exist_ok=True)
# 读取文件内容
with open("yarn.lock", "r") as file:
content = file.read()
# 使用正则表达式匹配resolved属性中的tgz下载链接
pattern = r'resolved\s+"(https:\/\/[^"]+\.tgz)'
matches = re.findall(pattern, content)
# 异步下载函数
async def download_file(session, url):
async with session.get(url) as response:
if response.status == 200:
parsed_url = urlparse(url)
filename = os.path.basename(parsed_url.path)
full_filename = os.path.join(download_folder, filename)
content = await response.read()
with open(full_filename, "wb") as output_file:
output_file.write(content)
print(f"文件 {filename} 下载成功")
else:
print(f"无法下载文件 {url}")
async def download_with_semaphore(semaphore, session, url):
async with semaphore:
await download_file(session, url)
async def main():
# 创建异步HTTP会话
async with aiohttp.ClientSession() as session:
semaphore = asyncio.Semaphore(8) # 限制并发数为8
tasks = []
for url in matches:
tasks.append(download_with_semaphore(semaphore, session, url))
await asyncio.gather(*tasks)
print("下载完成")
# 运行异步下载
if __name__ == "__main__":
asyncio.run(main())
3. 上传下载好的文件,执行如下脚本
创建脚本
vim npmimport.sh
写入脚本内容
find . -type f -name '*.tgz' | sed "s|^\./||" | xargs -I '{}' \
curl -u "$USERNAME:$PASSWORD" -X 'POST' -v \
${REPO_URL} \
-H 'accept: application/json' \
-H 'Content-Type: multipart/form-data' \
-F 'npm.asset=@{};type=application/x-compressed' ;
将上传文件解压,将脚本放入需要上传的根目录中,执行如下命令执行上传
./npmimport.sh -u [nexus3账号] -p [nexus3密码] -r http://[ip]:[端口]/service/rest/v1/components?repository=[仓库名称]