一、请用requests库的get()函数访问如下一个网站20次,打印返回状态,text()内容,计算text()属性和content属性所返回网页内容的长度。(360搜索主页)
import requests url = 'https://www.so.com/' for i in range(20): response = requests.get(url) print(f"第{i+1}次访问") print(f'Response status: {response.status_code}') print(f'Text content length: {len(response.text)}') print(f'Content length: {len(response.content)}') print(response.text)
运行结果:
二、这是一个简单的html页面,请保持为字符串,完成后面的计算要求。
要求:
- 打印head标签内容和你的学号后两位
- 获取body标签的内容
- 获取id 为first的标签对象
- 获取并打印html页面中的中文字符
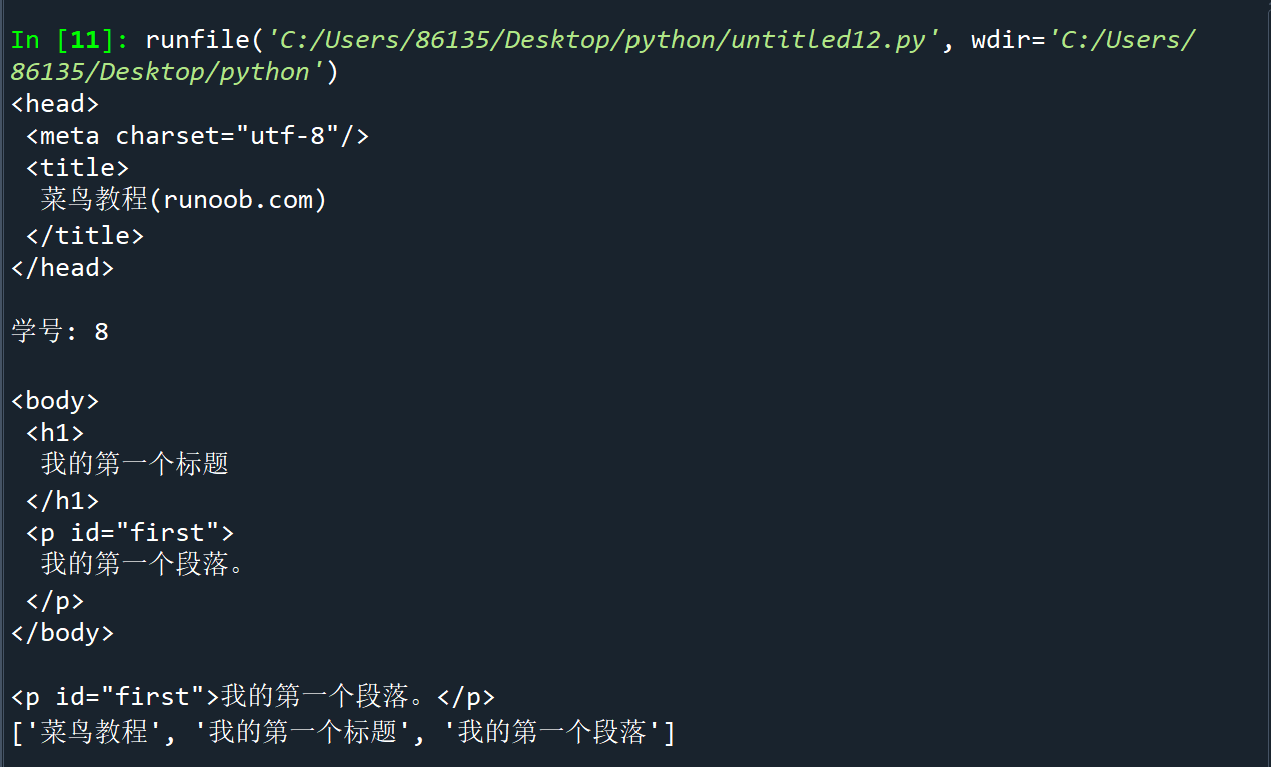
from bs4 import BeautifulSoup import re text = """ <!DOCTYPE html> <html> <head> <meta charset="utf-8"> <title>菜鸟教程(runoob.com)</title> </head> <body> <h1>我的第一个标题</h1> <p id="first">我的第一个段落。</p> </body> <table border="1"> <tr> <td>row 1, cell 1</td> <td>row 1, cell 2</td> </tr> <tr> <td>row 2, cell 1</td> <td>row 2, cell 2</td> </tr> </table> </html> """ # 创建BeautifulSoup对象 soup = BeautifulSoup(text, features="html.parser") # 打印head标签和学号后两位 print(soup.head.prettify()) print("学号: 8\n") # 获取body标签对象 print(soup.body.prettify()) # 获取id为first的对象 first_p = soup.find(id="first") print(first_p) # 获取打印中文字符 pattern = re.compile(u'[\u4e00-\u9fff]+') chinese_chars = pattern.findall(text) print(chinese_chars)
运行结果:
三、爬中国大学排名网站内容,
https://www.shanghairanking.cn/rankings/bcur/201811
要求:(一)爬取大学排名,爬取年费2018
(二)把爬取得数据,存为csv文件
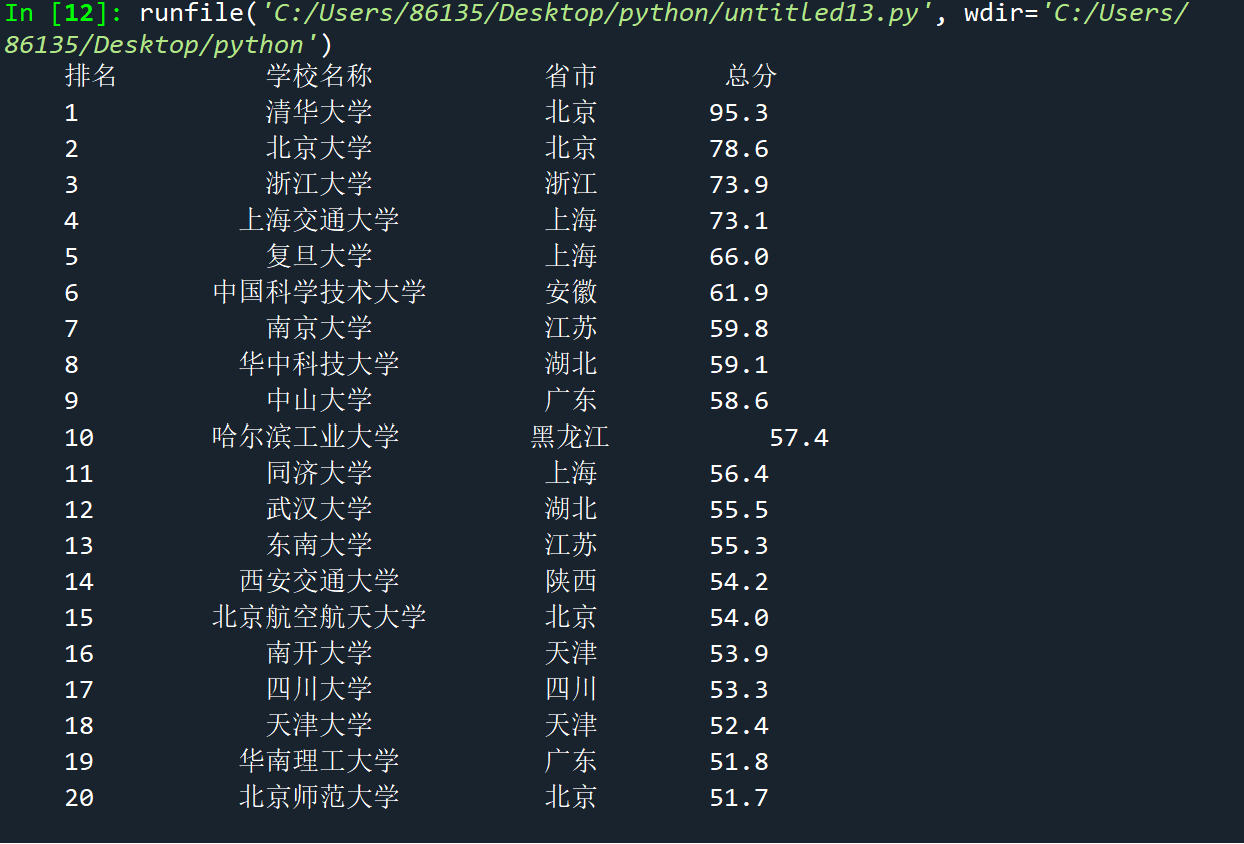
import requests from bs4 import BeautifulSoup import csv all_univ = [] def get_html_text(url): try: r = requests.get(url, timeout=30) r.raise_for_status() r.encoding = 'utf-8' return r.text except: return "" def fill_univ_list(soup): data = soup.find_all('tr') for tr in data: ltd = tr.find_all('td') if len(ltd) < 5: continue single_univ = [ltd[0].string.strip(), ltd[1].find('a', 'name-cn').string.strip(), ltd[2].text.strip(), ltd[4].string.strip()] all_univ.append(single_univ) def print_univ_list(num): file_name = "大学排行.csv" print("{0:^10}\t{1:{4}^10}\t{2:^10}\t{3:^10}".format("排名", "学校名称", "省市", "总分", chr(12288))) with open(file_name, 'w', newline='', encoding='utf-8') as f: writer = csv.writer(f) writer.writerow(["排名", "学校名称", "省市", "总分"]) for i in range(num): u = all_univ[i] writer.writerow(u) print("{0:^10}\t{1:{4}^10}\t{2:^10}\t{3:^10}".format(u[0], u[1], u[2], u[3], chr(12288))) def main(num): url = "https://www.shanghairanking.cn/rankings/bcur/201811" html = get_html_text(url) soup = BeautifulSoup(html, features="html.parser") fill_univ_list(soup) print_univ_list(num) main(20)
运行结果:
csv文件:
