Go 1.18版本增加了对泛型的支持,泛型也是自 Go 语言开源以来所做的最大改变。
一、为什么要加入泛型?
根据 Go 官方用户调查结果,在“你最想要的 Go 语言特性”这项调查中,泛型霸榜多年。你可以看下这张摘自2020 年 Go 官方用户调查结果的图片:
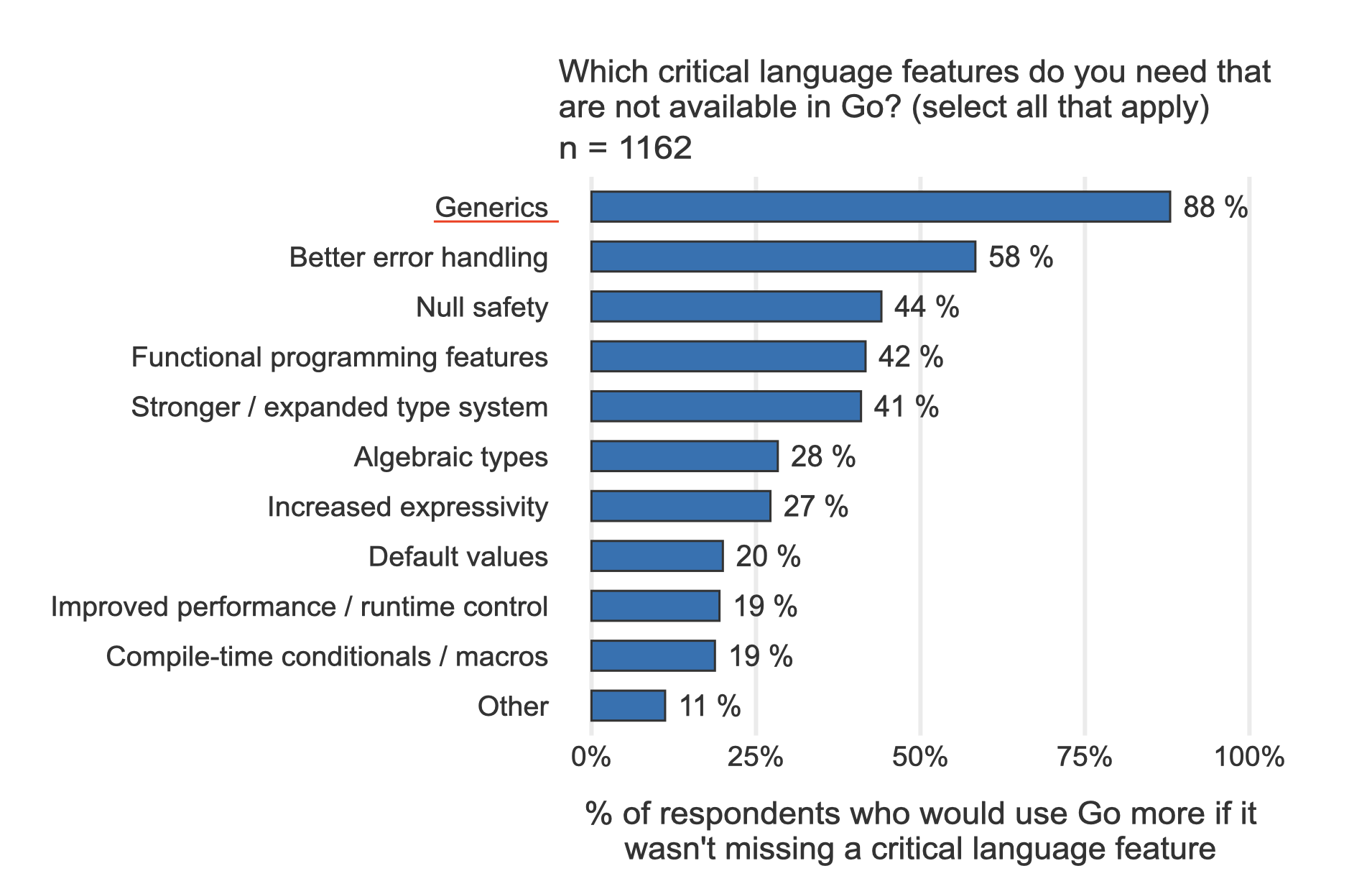
既然 Go 社区对泛型特性的需求如此强烈,那么 Go 核心团队为何要在 Go 开源后的第 13 个年头,才将这个特性加入语言当中呢?这里的故事说来话长。要想了解其中原因,我们需要先来了解一下什么是泛型?
二、什么是泛型
泛型允许程序员在强类型程序设计语言中编写代码时使用一些以后才指定的类型,在实例化时作为参数指明这些类型。ーー换句话说,在编写某些代码或数据结构时先不提供值的类型,而是之后再提供。
泛型是一种独立于所使用的特定类型的编写代码的方法。使用泛型可以编写出适用于一组类型中的任何一种的函数和类型。
三、泛型的来源
维基百科提到:最初泛型编程这个概念来自于缪斯·大卫和斯捷潘诺夫. 亚历山大合著的“泛型编程”一文。那篇文章对泛型编程的诠释是:“泛型编程的中心思想是对具体的、高效的算法进行抽象,以获得通用的算法,然后这些算法可以与不同的数据表示法结合起来,产生各种各样有用的软件”。说白了就是将算法与类型解耦,实现算法更广泛的复用。
四、为什么需要泛型
举个简单的例子。这里是一个简单得不能再简单的加法函数,这个函数接受两个 int32 类型参数作为加数:
func Add(a, b int32) int32 {
return a + b
}
不过上面的函数 Add 仅适用于 int32 类型的加数,如果我们要对 int、int64、 等类型的加数进行加法运算,我们还需要实现 AddInt、AddInt64 等函数。那如果我们用泛型编程的思想来解决这个问题,是怎样呢?
如果我们一遍一遍地编写相同的功能是低效的,从Go1.18开始,我们可以使用泛型将算法与类型解耦,将 Add算法使用any关键字,如下:
func Add[T any](a, b T) T {
return a + b
}
func main() {
Add(1, 2)
}
我们先来运行上面这段代码,会得到如下错误:
invalid operation: operator + not defined on a (variable of type T constrained by any)
这是因为不能对任意类型使用加法运算符。您需要为您的类型参数添加一个约束,限制它们只能是支持加法的类型。所以这里我们可以使用泛型约束,将上面的代码改造如下:
func Add[T number](a, b T) T {
return a + b
}
func main() {
res := Add(3.2, 2.3)
fmt.Println(res)
}
type number interface {
int | float32 | float64 | string | int8 | int16 | int32 | int64 | uint |
uint8 | uint16 | uint32 | uint64
}
修改后,可以对不同类型的参数进行加法操作。代码的解释如下:
func AddT number T定义了一个泛型函数Add,它接受一个类型参数T,一个约束number,和两个参数a和b,都是T类型的。它返回一个T类型的值,表示a和b的和。type number interface定义了一个接口类型number,它包含了所有的数字类型,如int,float32,float64等。它使用了类型集合的语法,用|分隔不同的类型。这个接口类型用于约束Add函数的类型参数,限制它们只能是数字类型。func main()定义了一个主函数,它是程序的入口点。res := Add(3.2, 2.3)调用了Add函数,传入了两个float64类型的参数,分别是3.2和2.3。这时,T类型被推断为float64类型,所以Add函数返回一个float64类型的值,表示两个参数的和。这个值被赋值给一个变量res。fmt.Println(res)调用了fmt包中的Println函数,打印出res的值,也就是5.5。
这样,我们就可以直接使用泛型版 Add 函数去进行各种整型类型的加法运算了,比如下面代码:
func main() {
var m, n int = 5, 6
println(Add(m, n)) // 11
var i, j int64 = 15, 16
println(Add(i, j)) // 31
var c, d string = "ha", "ha"
println(Add(c, d)) // haha
}
通过这个例子我们可以看到,在没有泛型的情况下,我们需要针对不同类型重复实现相同的算法逻辑,比如上面例子提到的 AddInt、AddInt64 等。
这对于简单的、诸如上面这样的加法函数还可忍受,但对于复杂的算法,比如涉及复杂排序、查找、树、图等算法,以及一些容器类型(链表、栈、队列等)的实现时,缺少了泛型的支持还真是麻烦。
在没有泛型之前,Gopher 们通常使用空接口类型 interface{},作为算法操作的对象的数据类型,不过这样做的不足之处也很明显:一是无法进行类型安全检查,二是性能有损失。
既然泛型有这么多优点,为什么 Go 不早点加入泛型呢?其实这个问题在Go FAQ 中早有答案,大概有三点主要理由:
-
这个语法特性不紧迫,不是 Go 早期的设计目标;
在 Go 诞生早期,很多基本语法特性的优先级都要高于泛型。此外,Go 团队更多将语言的设计目标定位在规模化(scalability)、可读性、并发性上,泛型与这些主要目标关联性不强。等 Go 成熟后,Go 团队会在适当时候引入泛型。
-
与简单的设计哲学有悖;
Go 语言最吸睛的地方就是简单,简单也是 Go 设计哲学之首!但泛型这个语法特性会给语言带来复杂性,这种复杂性不仅体现在语法层面上引入了新的语法元素,也体现在类型系统和运行时层面上为支持泛型进行了复杂的实现。
-
尚未找到合适的、价值足以抵消其引入的复杂性的理想设计方案。
从 Go 开源那一天开始,Go 团队就没有间断过对泛型的探索,并一直尝试寻找一个理想的泛型设计方案,但始终未能如愿。直到近几年 Go 团队觉得 Go 已经逐渐成熟,是时候下决心解决 Go 社区主要关注的几个问题了,包括泛型、包依赖以及错误处理等,并安排伊恩·泰勒和罗伯特·格瑞史莫花费更多精力在泛型的设计方案上,这才有了在 Go 1.18 版本中泛型语法特性的落地。如今,Go泛型已经稳定3年了。
五、Go 泛型设计的简史
Go 核心团队对泛型的探索,是从 2009 年 12 月 3 日 Russ Cox 在其博客站点上发表的一篇文章开始的。在这篇叫“泛型窘境”的文章中,Russ Cox 提出了 Go 泛型实现的三个可遵循的方法,以及每种方法的不足,也就是三个 slow(拖慢):
- 拖慢程序员:不实现泛型,不会引入复杂性,但就像前面例子中那样,需要程序员花费精力重复实现
AddInt、AddInt64等; - 拖慢编译器:就像 C++ 的泛型实现方案那样,通过增加编译器负担为每个类型实例生成一份单独的泛型函数的实现,这种方案产生了大量的代码,其中大部分是多余的,有时候还需要一个好的链接器来消除重复的拷贝;
- 拖慢执行性能:就像 Java 的泛型实现方案那样,通过隐式的装箱和拆箱操作消除类型差异,虽然节省了空间,但代码执行效率低。
在当时,三个 slow 之间需要取舍,就如同数据一致性的 CAP 原则一样,无法将三个 slow 同时消除。
之后,伊恩·泰勒主要负责跟进 Go 泛型方案的设计。从 2010 到 2016 年,伊恩·泰勒先后提出了几版泛型设计方案,它们是:
- 2010 年 6 月份,伊恩·泰勒提出的Type Functions设计方案;
- 2011 年 3 月份,伊恩·泰勒提出的Generalized Types设计方案;
- 2013 年 10 月份,伊恩·泰勒提出的Generalized Types 设计方案更新版;
- 2013 年 12 月份,伊恩·泰勒提出的Type Parameters设计方案;
- 2016 年 9 月份,布莱恩·C·米尔斯提出的Compile-time Functions and First Class Types设计方案。
虽然这些方案因为存在各种不足,最终都没有被接受,但这些探索为后续 Go 泛型的最终落地奠定了基础。
2017 年 7 月,Russ Cox 在 GopherCon 2017 大会上发表演讲“Toward Go 2”,正式吹响 Go 向下一个阶段演化的号角,包括重点解决泛型、包依赖以及错误处理等 Go 社区最广泛关注的问题。
后来,在 2018 年 8 月,也就是 GopherCon 2018 大会结束后不久,Go 核心团队发布了 Go2 draft proposal,这里面涵盖了由伊恩·泰勒和罗伯特·格瑞史莫操刀主写的 Go 泛型的第一版 draft proposal。
这版设计草案引入了 contract 关键字来定义泛型类型参数(type parameter)的约束、类型参数放在普通函数参数列表前面的小括号中,并用 type 关键字声明。下面是这个草案的语法示例:
// 第一版泛型技术草案中的典型泛型语法
contract stringer(x T) {
var s string = x.String()
}
func Stringify(type T stringer)(s []T) (ret []string) {
}
接着,在 2019 年 7 月,伊恩·泰勒在 GopherCon 2019 大会上发表演讲“Why Generics?”,并更新了泛型的技术草案,简化了 contract 的语法设计,下面是简化后的 contract 语法,你可以对比上面代码示例中的 contract 语法看看:
contract stringer(T) {
T String() string
}
后来,在 2020 年 6 月,一篇叫《Featherweight Go》论文发表在 arxiv.org 上,这篇论文出自著名计算机科学家、函数语言专家、Haskell 语言的设计者之一、Java 泛型的设计者菲利普·瓦德勒(Philip Wadler)之手。
Rob Pike 邀请他帮助 Go 核心团队解决 Go 语言的泛型扩展问题,这篇论文就是菲利普·瓦德对这次邀请的回应
这篇论文为 Go 语言的一个最小语法子集设计了泛型语法 Featherweight Generic Go(FGG),并成功地给出了 FGG 到 Featherweight Go(FG)的可行性实现的形式化证明。这篇论文的形式化证明给 Go 团队带来了很大信心,也让 Go 团队在一些泛型语法问题上达成更广泛的一致。
2020 年 6 月末,伊恩·泰勒和罗伯特·格瑞史莫在 Go 官方博客发表了文章《The Next Step for Generics》,介绍了 Go 泛型工作的最新进展。Go 团队放弃了之前的技术草案,并重新编写了一个新草案。
在这份新技术方案中,Go 团队放弃了引入 contract 关键字作为泛型类型参数的约束,而采用扩展后的 interface 来替代 contract。这样上面的 Stringify 函数就可以写成如下形式:
type Stringer interface {
String() string
}
func Stringify(type T Stringer)(s []T) (ret []string) {
... ...
}
同时,Go 团队还推出了可以在线试验 Go 泛型语法的 playground,这样 Gopher 们可以直观体验新语法,并给出自己的意见反馈。
然后,在 2020 年 11 月的 GopherCon 2020 大会,罗伯特·格瑞史莫与全世界的 Gopher 同步了 Go 泛型的最新进展和 roadmap,在最新的技术草案版本中,包裹类型参数的小括号被方括号取代,类型参数前面的 type 关键字也不再需要了:
func Stringify[T Stringer](s []T) (ret []string) {
... ...
}
与此同时,go2goplay.golang.org 也支持了方括号语法,Gopher 们可以在线体验。
接下来的 2021 年 1 月,Go 团队正式提出将泛型加入 Go 的 proposal,2021 年 2 月,这个提案被正式接受。
然后是 2021 年 4 月,伊恩·泰勒在 GitHub 上发布 issue,提议去除原 Go 泛型方案中置于 interface 定义中的 type list 中的 type 关键字,并引入 type set 的概念,下面是相关示例代码:
// 之前使用type list的方案
type SignedInteger interface {
type int, int8, int16, int32, int64
}
// type set理念下的新语法
type SignedInteger interface {
~int | ~int8 | ~int16 | ~int32 | ~int64
}
那什么是 type set(类型集合)呢?伊恩·泰勒给出了这个概念的定义:
- 每个类型都有一个
type set; - 非接口类型的类型的
type set中仅包含其自身。比如非接口类型T,它的type set中唯一的元素就是它自身:{T}; - 对于一个普通的、没有
type list的普通接口类型来说,它的type set是一个无限集合。所有实现了这个接口类型所有方法的类型,都是该集合的一个元素,另外,由于该接口类型本身也声明了其所有方法,因此接口类型自身也是其Type set的一员; - 空接口类型
interface{}的type set中囊括了所有可能的类型。
这样一来,我们可以试试用 type set 概念,重新表述一下一个类型 T 实现一个接口类型 I。也就是当类型 T 是接口类型 I 的 type set 的一员时,T 便实现了接口 I;对于使用嵌入接口类型组合而成的接口类型,其 type set 就是其所有的嵌入的接口类型的 type set 的交集。
这样一来,我们可以试试用 type set 概念,重新表述一下一个类型 T 实现一个接口类型 I。也就是当类型 T 是接口类型 I 的 type set 的一员时,T 便实现了接口 I;对于使用嵌入接口类型组合而成的接口类型,其 type set 就是其所有的嵌入的接口类型的 type set 的交集。
而对于一个带有自身 Method 的嵌入其他接口类型的接口类型,比如下面代码中的 MyInterface3:
type MyInterface3 interface {
E1
E2
MyMethod03()
}
它的 type set 可以看成 E1、E2 和 E3(type E3 interface { MyMethod03()})的 type set 的交集。
最后,在 2021 年 12 月 14 日,Go 1.18 beta1 版本发布,这个版本包含了对 Go 泛型的正式支持。
经过 12 年的努力与不断地自我否定,Go 团队终于将泛型引入到 Go 中,并且经过缜密设计的语法并没有违背 Go1 的兼容性。如今,Go 泛型已经稳定了三年了,那么接下来,我们就正式看看 Go 泛型的基本语法。
六、泛型语法
泛型为Go语言添加了三个新的重要特性:
- 函数和类型的类型参数。
- 将接口类型定义为类型集,包括没有方法的类型。
- 类型推断,它允许在调用函数时在许多情况下省略类型参数。
Go 泛型的核心是类型参数(type parameter),下面我们就从类型参数开始,了解一下 Go 泛型的基本语法。
6.1 类型参数(type parameter)
类型参数是在函数声明、方法声明的 receiver 部分或类型定义的类型参数列表中,声明的(非限定)类型名称。类型参数在声明中充当了一个未知类型的占位符(placeholder),在泛型函数或泛型类型实例化时,类型参数会被一个类型实参替换。
为了更好地理解类型参数究竟如何声明,它又起到了什么作用,我们以函数为例,对普通函数的参数与泛型函数的类型参数作一下对比:
func Foo(x, y aType, z anotherType)
这里,x, y, z 是形参(parameter)的名字,也就是变量,而 aType,anotherType 是形参的类型,也就是类型。
6.2 类型实参(type argument)
我们知道函数定义时可以指定形参,函数调用时需要传入实参。

现在,Go语言中的函数和类型支持添加类型参数。类型参数列表看起来像普通的参数列表,只不过它使用方括号([])而不是圆括号(())。

6.3 类型参数(type parameter)列表
接下来,我们再来看一下泛型函数的类型参数(type parameter)列表:
func GenericFoo[P aConstraint, Q anotherConstraint](x,y P, z Q)
这里,P、Q 是类型形参的名字,也就是类型。aConstraint,anotherConstraint 代表类型参数的约束(constraint),我们可以理解为对类型参数可选值的一种限定。
从 GenericFoo 函数的声明中,我们可以看到,泛型函数的声明相比于普通函数多出了一个组成部分:类型参数列表。
类型参数列表位于函数名与函数参数列表之间,通过一个方括号括起。类型参数列表不支持变长类型参数。而且,类型参数列表中声明的类型参数,可以作为函数普通参数列表中的形参类型。
但在泛型函数声明时,我们并不知道 P、Q 两个类型参数具体代表的究竟是什么类型,因此函数参数列表中的 P、Q 更像是未知类型的占位符。
那么 P、Q 的类型什么时候才能确定呢?这就要等到泛型函数具化(instantiation)时才能确定。另外,按惯例,类型参数(type parameter)的名字都是首字母大写的,通常都是用单个大写字母命名。
在类型参数列表中修饰类型参数的就是约束(constraint)。
6.4 类型约束(type constraint)
约束(constraint)规定了一个类型实参(type argument)必须满足的条件要求。如果某个类型满足了某个约束规定的所有条件要求,那么它就是这个约束修饰的类型形参的一个合法的类型实参。
在 Go 泛型中,我们使用 interface 类型来定义约束。为此,Go 接口类型的定义也进行了扩展,我们既可以声明接口的方法集合,也可以声明可用作类型实参的类型列表。下面是一个约束定义与使用的示例:
package main
type C1 interface {
~int | ~int32
M1()
}
type T struct{}
func (T) M1() {
}
type T1 int
func (T1) M1() {
}
func foo[P C1](t P) {
}
func main() {
var t1 T1
foo(t1)
var t T
foo(t) // 编译器报错:T does not satisfy C1 (T missing in ~int | ~int32)
}
在这段代码中,C1 是我们定义的约束,它声明了一个方法 M1,以及两个可用作类型实参的类型 (~int | ~int32)。我们看到,类型列表中的多个类型实参类型用“|”分隔。
这段代码中,我们还定义了两个自定义类型 T 和 T1,两个类型都实现了 M1 方法,但 T 类型的底层类型为 struct{},而 T1 类型的底层类型为 int,这样就导致了虽然 T 类型满足了约束 C1 的方法集合,但类型 T 因为底层类型并不是 int 或 int32 而不满足约束 C1,这也就会导致 foo(t) 调用在编译阶段报错。
这里还要建议:做约束的接口类型与做传统接口的接口类型最好要分开定义,除非约束类型真的既需要方法集合,也需要类型列表。
知道了类型参数声明的形式,也知道了约束如何定义后,我们再来看看如何使用带有类型参数的泛型函数。
6.5 类型具化(instantiation)
声明了泛型函数后,接下来就要调用泛型函数来实现具体的业务逻辑。现在我们就通过一个泛型版本 Sort 函数的调用例子,看看调用泛型函数的过程都发生了什么:
func Sort[Elem interface{ Less(y Elem) bool }](list []Elem) {
}
type book struct{}
func (x book) Less(y book) bool {
return true
}
func main() {
var bookshelf []book
Sort[book](bookshelf) // 泛型函数调用
}
根据 Go 泛型的实现原理,上面的泛型函数调用 Sort[book](bookshelf) 会分成两个阶段:
6.5.1 第一个阶段就是具化(instantiation)
形象点说,具化(instantiation)就好比一家生产“排序机器”的工厂根据要排序的对象的类型,将这样的机器生产出来的过程。我们继续举前面的例子来分析一下,整个具化过程如下:
-
工厂接单:
Sort[book],发现要排序的对象类型为book; -
模具检查与匹配:检查
book类型是否满足模具的约束要求(也就是是否实现了约束定义中的Less方法)。如果满足,就将其作为类型实参替换Sort函数中的类型形参,结果为Sort[book];如果不满足,编译器就会报错; -
生产机器:将泛型函数
Sort具化为一个新函数,这里我们把它起名为booksort,其函数原型为func([]book)。本质上booksort := Sort[book]。
6.5.2 第二阶段是调用(invocation)
一旦“排序机器”被生产出来,那么它就可以对目标对象进行排序了,这和普通的函数调用没有区别。这里就相当于调用 booksort(bookshelf),整个过程只需要检查传入的函数实参(bookshelf)的类型与 booksort 函数原型中的形参类型([]book)是否匹配就可以了。
我们用伪代码来表述上面两个过程:
Sort[book](bookshelf)
<=>
具化:booksort := Sort[book]
调用:booksort(bookshelf)
不过,每次调用 Sort 都要传入类型实参 book,这和普通函数调用相比还是繁琐了不少。那么能否像普通函数那样只传入普通参数实参,不用传入类型参数实参呢?答案是可以的。
Go 编译器会根据传入的实参变量,进行实参类型参数的自动推导(Argument type inference),也就是说上面的例子,我们只需要像这样进行 Sort 的调用就可以了:
Sort(bookshelf)
有了对类型参数的实参类型的自动推导,大多数泛型函数的调用方式与常规函数调用一致,不会给 Gopher 带去额外的代码编写负担。
6.6 类型集
Go1.18开始接口类型的定义也发生了改变,由过去的接口类型定义方法集(method set)变成了接口类型定义类型集(type set)。也就是说,接口类型现在可以用作值的类型,也可以用作类型约束。
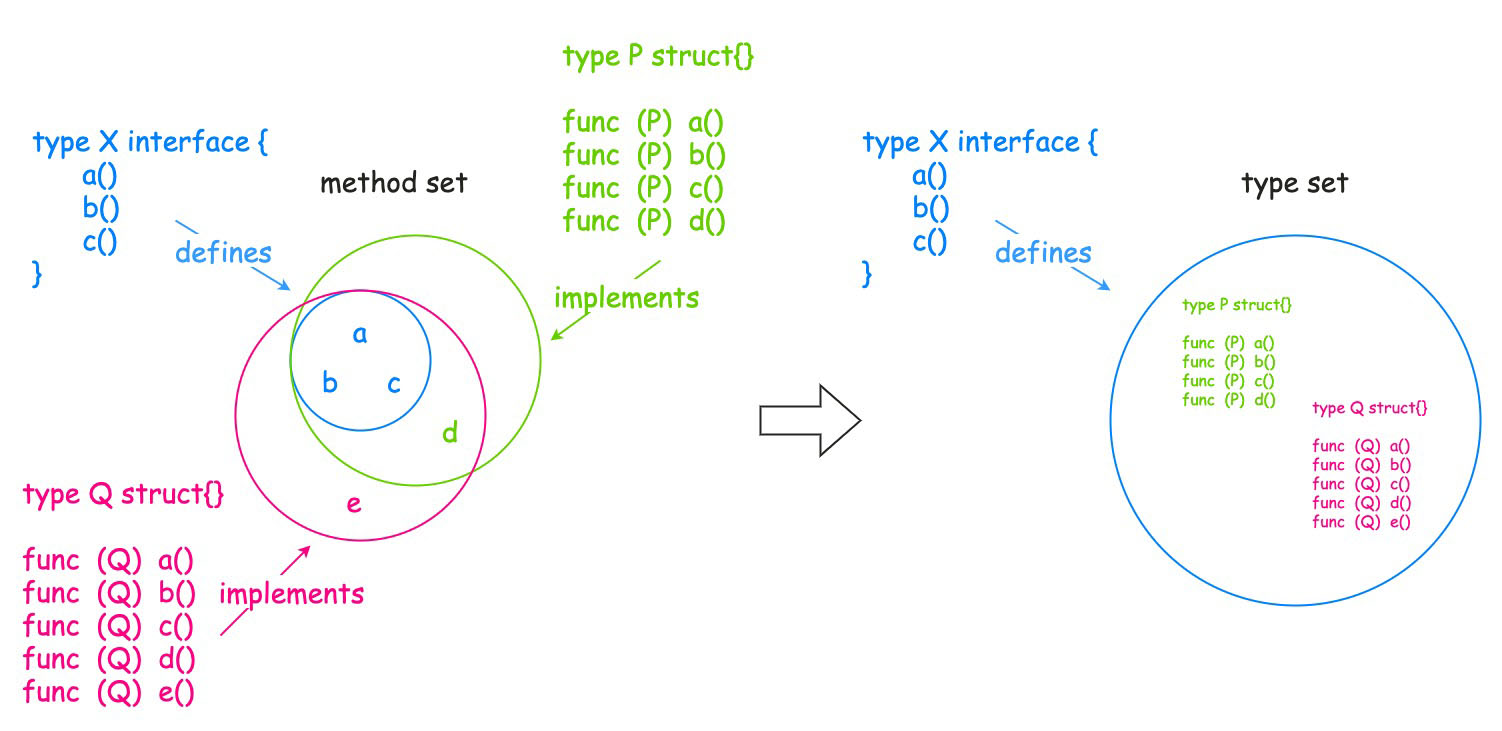
把接口类型当做类型集相较于方法集有一个优势: 我们可以显式地向集合添加类型,从而以新的方式控制类型集。
Go语言扩展了接口类型的语法,让我们能够向接口中添加类型。例如
type V interface {
int | string | bool
}
上面的代码就定义了一个包含 int、 string 和 bool 类型的类型集。

从 Go 1.18 开始,一个接口不仅可以嵌入其他接口,还可以嵌入任何类型、类型的联合或共享相同底层类型的无限类型集合。
当用作类型约束时,由接口定义的类型集精确地指定允许作为相应类型参数的类型。
-
|符号T1 | T2表示类型约束为T1和T2这两个类型的并集,例如下面的Integer类型表示由Signed和Unsigned组成。type Integer interface { Signed | Unsigned } -
~符号~T表示所以底层类型是T的类型,例如~string表示所有底层类型是string的类型集合。type MyString string // MyString的底层类型是string注意:
~符号后面只能是基本类型。
接口作为类型集是一种强大的新机制,是使类型约束能够生效的关键。目前,使用新语法表的接口只能用作类型约束。
6.7 类型推断
从某些方面来说,类型推断是语言中最复杂的变化,但它很重要,因为它能让人们在编写调用泛型函数的代码时更自然。
6.7.1 函数参数类型推断
对于类型参数,需要传递类型参数,这可能导致代码冗长。回到我们通用的 min函数:
func min[T int | float64](a, b T) T {
if a <= b {
return a
}
return b
}
类型形参T用于指定a和b的类型。我们可以使用显式类型实参调用它:
var a, b, m float64
m = min[float64](a, b) // 显式指定类型实参
在许多情况下,编译器可以从普通参数推断 T 的类型实参。这使得代码更短,同时保持清晰。
var a, b, m float64
m = min(a, b) // 无需指定类型实参
这种从实参的类型推断出函数的类型实参的推断称为函数实参类型推断。函数实参类型推断只适用于函数参数中使用的类型参数,而不适用于仅在函数结果中或仅在函数体中使用的类型参数。例如,它不适用于像 MakeT [ T any ]() T 这样的函数,因为它只使用 T 表示结果。
6.7.2 约束类型推断
Go 语言支持另一种类型推断,即约束类型推断。接下来我们从下面这个缩放整数的例子开始:
// Scale 返回切片中每个元素都乘c的副本切片
func Scale[E constraints.Integer](s []E, c E) []E {
r := make([]E, len(s))
for i, v := range s {
r[i] = v * c
}
return r
}
这是一个泛型函数适用于任何整数类型的切片。
现在假设我们有一个多维坐标的 Point 类型,其中每个 Point 只是一个给出点坐标的整数列表。这种类型通常会实现一些业务方法,这里假设它有一个String方法。
type Point []int32
func (p Point) String() string {
b, _ := json.Marshal(p)
return string(b)
}
由于一个Point其实就是一个整数切片,我们可以使用前面编写的Scale函数:
func ScaleAndPrint(p Point) {
r := Scale(p, 2)
fmt.Println(r.String()) // 编译失败
}
不幸的是,这代码会编译失败,输出r.String undefined (type []int32 has no field or method String的错误。
问题是Scale函数返回类型为[]E的值,其中E是参数切片的元素类型。当我们使用Point类型的值调用Scale(其基础类型为[]int32)时,我们返回的是[]int32类型的值,而不是Point类型。这源于泛型代码的编写方式,但这不是我们想要的。
为了解决这个问题,我们必须更改 Scale 函数,以便为切片类型使用类型参数。
func Scale[S ~[]E, E constraints.Integer](s S, c E) S {
r := make(S, len(s))
for i, v := range s {
r[i] = v * c
}
return r
}
我们引入了一个新的类型参数S,它是切片参数的类型。我们对它进行了约束,使得基础类型是S而不是[]E,函数返回的结果类型现在是S。由于E被约束为整数,因此效果与之前相同:第一个参数必须是某个整数类型的切片。对函数体的唯一更改是,现在我们在调用make时传递S,而不是[]E。
现在这个Scale函数,不仅支持传入普通整数切片参数,也支持传入Point类型参数。
这里需要思考的是,为什么不传递显式类型参数就可以写入 Scale 调用?也就是说,为什么我们可以写 Scale(p, 2),没有类型参数,而不是必须写 Scale[Point, int32](p, 2) ?
新 Scale 函数有两个类型参数——S 和 E。在不传递任何类型参数的 Scale(p, 2) 调用中,如上所述,函数参数类型推断让编译器推断 S 的类型参数是 Point。但是这个函数也有一个类型参数 E,它是乘法因子 c 的类型。相应的函数参数是2,因为2是一个非类型化的常量,函数参数类型推断不能推断出 E 的正确类型(最好的情况是它可以推断出2的默认类型是 int,而这是错误的,因为Point 的基础类型是[]int32)。相反,编译器推断 E 的类型参数是切片的元素类型的过程称为约束类型推断。
约束类型推断从类型参数约束推导类型参数。当一个类型参数具有根据另一个类型参数定义的约束时使用。当其中一个类型参数的类型参数已知时,约束用于推断另一个类型参数的类型参数。
通常的情况是,当一个约束对某种类型使用 ~type 形式时,该类型是使用其他类型参数编写的。我们在 Scale 的例子中看到了这一点。S 是 ~[]E,后面跟着一个用另一个类型参数写的类型[]E。如果我们知道了 S 的类型实参,我们就可以推断出E的类型实参。S 是一个切片类型,而 E是该切片的元素类型。
6.8 泛型类型
6.8.1 泛型类型
除了函数可以携带类型参数变身为“泛型函数”外,类型也可以拥有类型参数而化身为“泛型类型”,比如下面代码就定义了一个向量泛型类型:
type Vector[T any] []T
这是一个带有类型参数的类型定义,类型参数位于类型名的后面,同样用方括号括起。在类型定义体中可以引用类型参数列表中的参数名(比如 T)。类型参数同样拥有自己的约束,如上面代码中的 any。
6.8.2 预声明标识符(Predeclared identifiers):any
从 Go 1.18 开始,any是interface{}的别名,也是一个预定义标识符,使用any` 作为类型参数的约束,代表没有任何约束。
// any is an alias for interface{} and is equivalent to interface{} in all ways.
// any 是一个 interface{}的 别名,并且在任何情况下和interface{}相同。
// src/builtin/builtin.go
type any = interface{}
泛型类型,我们也要遵循先具化,再使用的顺序,比如下面例子:
type Vector[T any] []T
func (v Vector[T]) Dump() {
fmt.Printf("%#v\n", v)
}
func main() {
var iv = Vector[int]{1,2,3,4}
var sv Vector[string]
sv = []string{"a","b", "c", "d"}
iv.Dump()
sv.Dump()
}
这段代码中,我们在使用 Vector[T] 之前都显式用类型实参对泛型类型进行了具化,从而得到具化后的类型 Vector[int] 和 Vector[string]。Vector[int] 的底层类型为 []int,Vector[string] 的底层类型为 []string。然后我们再对具化后的类型进行操作。
以上就是 Go 泛型语法特性的一些主要语法概念,我们可以看到,泛型的加入确实进一步提高了程序员的开发效率,大幅提升了算法的重用性。
6.8.3 constrains 包
constraints 包提供了一些常用类型,地址:https://pkg.go.dev/golang.org/x/exp/constraints
6.8.4 any的最佳实践
(一). 在map的情况下,map更适合做key
我们先来看一个下面两个时间,大家比较一下,哪一个比较好。
func TestAny(t *testing.T) {
m1 := make(map[any]string, 0)
m1["1"] = "1"
m1[2] = "2"
var v1 string = m1["1"]
var v2 string = m1[2]
t.Log(v1, v2)
m2 := make(map[string]any, 0)
m2["1"] = "1"
m2["2"] = 2
var v3 string = m2["1"].(string)
var v4 int = m2["2"].(int)
t.Log(v3, v4)
}
结论是 m1这种方式好。为什么,因为用做key的话,这样我们无论做为保存,还是读取,都无需多做什么操作。
m2这种方式,我们需要拿到数据后,进行类型的转换。这一步还的和之前保存的一样,就很复杂。
(二). 函数的参数和返回值,any更适合做参数
在官方的json解析包里面。无论是编码还是解码,any都只是作为参数。
func Marshal(v any) ([]byte, error)
func Unmarshal(data []byte, v any) error
如果是返回值的话,我们调用这个函数,还得进行返回值的类型转换,这对于调用方,无疑是巨大负担。
但作为参数,对于调用方,是巨大的便利,他可以传入各种类型。
那么,Go 泛型方案对 Go 程序的运行时性能又带来了哪些影响呢?我们接下来就来通过例子验证一下。
七、Go 泛型的性能
我们创建一个性能基准测试的例子,参加这次测试的三位选手分别来自:
- Go 标准库
sort包(非泛型版)的Ints函数; - Go 团队维护
golang.org/x/exp/slices中的泛型版Sort函数; - 对
golang.org/x/exp/slices中的泛型版Sort函数进行改造得到的、仅针对[]int进行排序的Sort函数。
下面是使用 Go1.21.4 版本在 macOS 上运行该测试的结果,相关可以到这里下载相关源码。
$go test -bench .
goos: darwin
goarch: arm64
pkg: demo
BenchmarkSortInts-12 132 8845318 ns/op 24 B/op 1 allocs/op
BenchmarkSlicesSort-12 229 5192995 ns/op 0 B/op 0 allocs/op
BenchmarkIntSort-12 242 4932431 ns/op 0 B/op 0 allocs/op
PASS
ok demo 6.826s
我们看到,泛型版和仅支持[]int的 Sort 函数的性能是一致的,性能都要比目前标准库的 Ints 函数高出近一倍,并且在排序过程中没有额外的内存分配。由此我们可以得出结论:至少在这个例子中,泛型在运行时并未给算法带来额外的负担。
现在看来,Go 泛型没有拖慢程序员的开发效率,也没有拖慢运行效率。
八、Go 泛型的使用建议
在本文最开始提到,Go 当初没有及时引入泛型的一个原因就是与 Go 语言“简单”的设计哲学有悖,现在加入了泛型,随之而来的就是增加了语言的复杂性。
为了尽量降低复杂性,Go 团队做了很多工作,包括前面提到的在语法中加入类型实参的自动推导等语法糖,尽量减少给开发人员编码时带去额外负担,也尽可能保持 Go 代码良好的可读性。
此外,Go 核心团队最担心的就是“泛型被滥用”,所以 Go 核心团队在各种演讲场合都在努力地告诉大家 Go 泛型的适用场景以及应该如何使用。这里我也梳理一下来自 Go 团队的这些建议,可以参考一下。
8.1 什么情况适合使用泛型
首先,类型参数的一种有用的情况,就是当编写的函数的操作元素的类型为 slice、map、channel 等特定类型的时候。如果一个函数接受这些类型的形参,并且函数代码没有对参数的元素类型作出任何假设,那么使用类型参数可能会非常有用。在这种场合下,泛型方案可以替代反射方案,获得更高的性能。
另一个适合使用类型参数的情况是编写通用数据结构。所谓的通用数据结构,指的是像切片或 map 这样,但 Go 语言又没有提供原生支持的类型。比如一个链表或一个二叉树。
今天,需要这类数据结构的程序会使用特定的元素类型实现它们,或者是使用接口类型(interface{})来实现。不过,如果我们使用类型参数替换特定元素类型,可以实现一个更通用的数据结构,这个通用的数据结构可以被其他程序复用。而且,用类型参数替换接口类型通常也会让数据存储的更为高效。
另外,在一些场合,使用类型参数替代接口类型,意味着代码可以避免进行类型断言(type assertion),并且在编译阶段还可以进行全面的类型静态检查。
8.2 什么情况不宜使用泛型
首先,如果你要对某一类型的值进行的全部操作,仅仅是在那个值上调用一个方法,请使用 interface 类型,而不是类型参数。比如,io.Reader 易读且高效,没有必要像下面代码中这样使用一个类型参数像调用 Read 方法那样去从一个值中读取数据:
func ReadAll[reader io.Reader](r reader) ([]byte, error) // 错误的作法
func ReadAll(r io.Reader) ([]byte, error) // 正确的作法
使用类型参数的原因是它们让你的代码更清晰,如果它们会让你的代码变得更复杂,就不要使用。
第二,当不同的类型使用一个共同的方法时,如果一个方法的实现对于所有类型都相同,就使用类型参数;相反,如果每种类型的实现各不相同,请使用不同的方法,不要使用类型参数。
最后,如果你发现自己多次编写完全相同的代码(样板代码),各个版本之间唯一的差别是代码使用不同的类型,那就请你考虑是否可以使用类型参数。反之,在你注意到自己要多次编写完全相同的代码之前,应该避免使用类型参数。