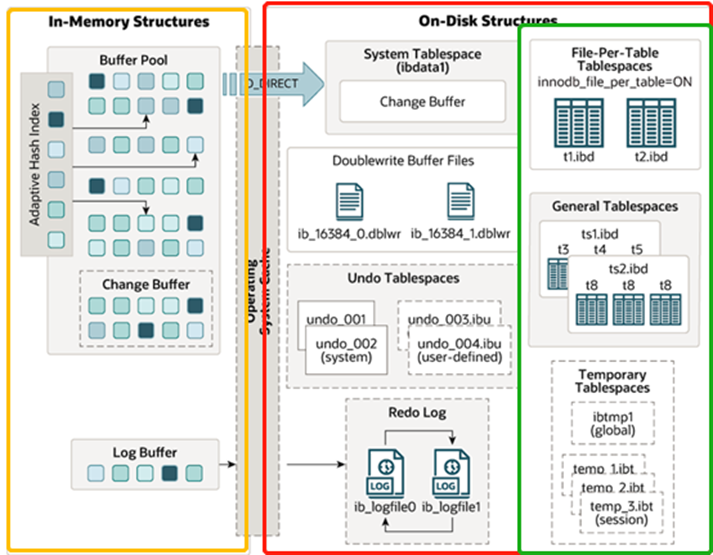
上图innodb存储引擎的架构引用官方手册,从上图来看关于架构的相关功能看起来很复杂,实际上也确实很复杂。为了方便理解我用黄红绿三个框稍微给归纳一下,分成三个部分。
简单的概括一下,当然没有很全面。
黄框是关于内存方面的功能;
红框是将数据从内存落实到硬盘的相关功能;
绿框是硬盘表空间的相关功能;
缓冲池(bufferpool):
缓冲池主要是通过内存提升数据库运行效率,解决硬盘运行速度较慢的缺点。在内存中分配一块区域给缓冲池,然后将数据库查询到的数据放在划分的内存中。如果下次再读取相同的数据,首先会去内存中找,找到了直接从内存中取走。找不到再去硬盘中读取。
以上是读取的操作,对于修改的操作则会先修改内存上的数据再通过checkpoint刷新回硬盘,这样做主要是减少磁盘的io,提高性能。
而缓冲区的大小将会直接影响Mysql数据库的性能,通过”SHOW VARIABLES LIKE 'innodb_buffer_pool_size’\G;命令可以查看缓冲池大小。
缓冲池的管理:

缓冲池通过LRU算法来管理放入内存中的数据,因为内存就算设置的再大也不可能存放所有的数据,既然只能存放一部分那肯定就是要存放最有“价值“的那一部分,而这个价值指的就是”访问频率“。lru会根据访问频率将数据按页的规格从头到尾的存放,访问频率较低的放在尾部,高的放在头部。如果加入缓冲池的数据超过了设置的大小就会从尾部开始将数据释放出缓冲池,并且进行了一定的优化,引入了”midpoint“算法。为什么要引入这个算法,可以想象一下,加入有一个缓冲池1G大小。里面已经存放了1G的数据,前300M是访问频繁的数据,后面700M是频率较低的数据。此时数据库产生了新的300M数据放在缓冲池中,刚才尾部的700M被”挤“出去300M剩400M。而刚才头部的300M被”挤“到中间的位置。这是产生的数据没有超过缓冲池大小的情况如果产生的数据超过了1G呢。比如查询一个比较少用到的表,这个操作可以一个月做不了几次,但是会产生大量的数据比如正好1G。上文说过每个操作产生的数据都会放入内存中,那这个1G不常用的数据是不是正好将300M常用的数据顶出去了。所以引用了”midpoint“算法,产生的新的数据不会存放在头部位置,而是大概3/8的位置,midpoint之前的页是new list,之后的页是old list。如果是 old list 的数据被访问到了,这个页信息就会变成 new list,变成 young page,就会将数据页信息移动到头部。加入了一个参数” innodb_old_blocks_time“表示新加入在midpoint点的数据必须保持多少秒,才能加入到new页。