Classification-CNN
1.base model
1. AlexNet
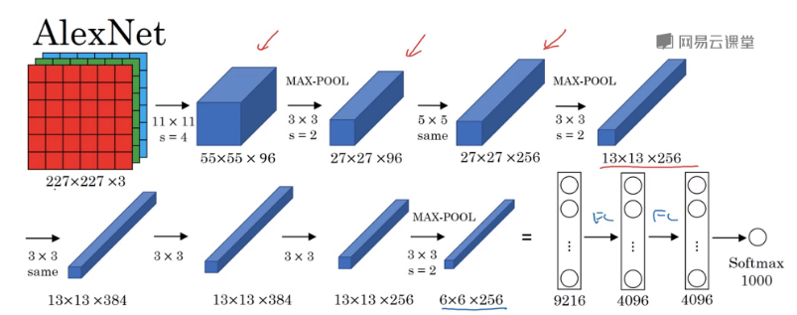
- 卷积核:11,5,3
- 上下两块单独训练
- 所有卷积层都使用ReLU作为非线性映射函数,使模型收敛速度更快
- 在多个GPU上进行模型的训练,不但可以提高模型的训练速度,还能提升数据的使用规模
- 使用LRN对局部的特征进行归一化,结果作为ReLU激活函数的输入能有效降低错误率
- 重叠最大池化(overlapping max pooling),即池化范围z与步长s存在关系\(z>s\)(如\(S_{max}\)中核尺度为\(3\times3/2\)),避免平均池化(average pooling)的平均效应
- 使用随机丢弃技术(dropout)选择性地忽略训练中的单个神经元,避免模型的过拟合
2. VGG
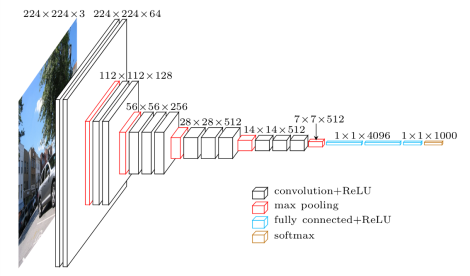
- 整个网络都使用了同样大小的卷积核尺寸3x3和最大池化尺寸2x2。
- 1x1卷积的意义主要在于线性变换,而输入通道数和输出通道数不变,没有发生降维。
- 两个3x3的卷积层串联相当于1个5x5的卷积层,感受野大小为5x5。同样地,3个3x3的卷积层串联的效果则相当于1个7x7的卷积层。这样的连接方式使得网络参数量更小,而且多层的激活函数令网络对特征的学习能力更强。
- VGGNet在训练时有一个小技巧,先训练浅层的的简单网络VGG11,再复用VGG11的权重来初始化VGG13,如此反复训练并初始化VGG19,能够使训练时收敛的速度更快。
- 在训练过程中使用多尺度的变换对原始数据做数据增强,使得模型不易过拟合。
3. inception
googlenet
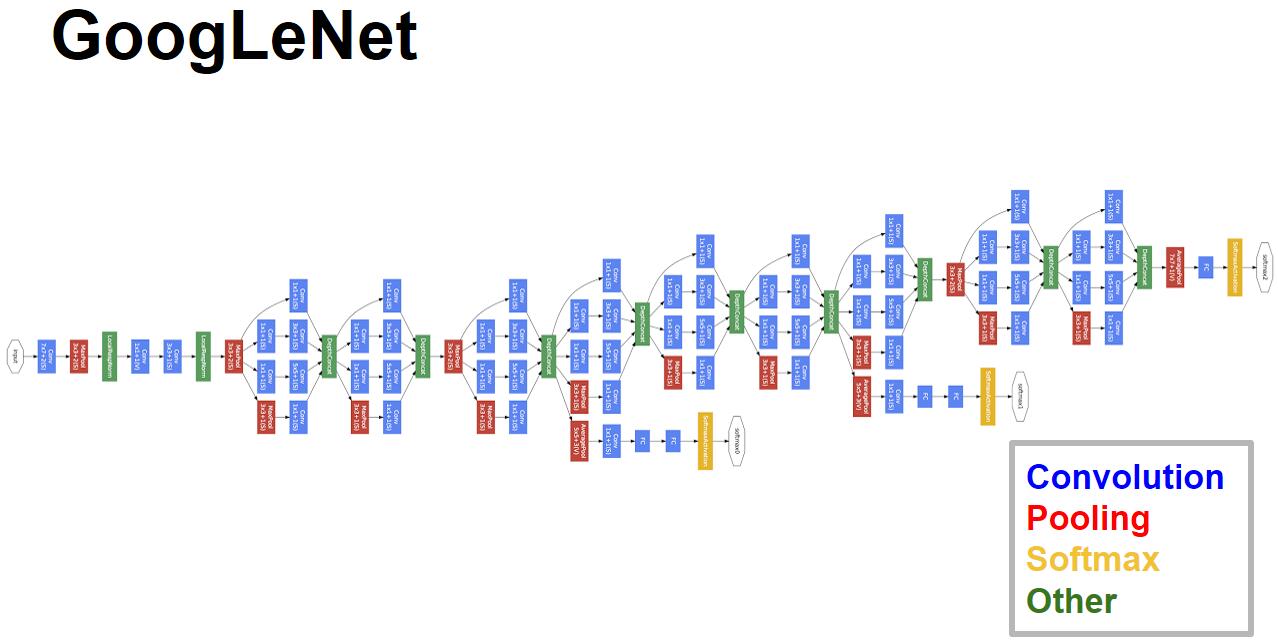
- 采用不同大小的卷积核意味着不同大小的感受野,最后拼接意味着不同尺度特征的融合;
- 之所以卷积核大小采用1、3和5,主要是为了方便对齐。设定卷积步长stride=1之后,只要分别设定pad=0、1、2,那么卷积之后便可以得到相同维度的特征,然后这些特征就可以直接拼接在一起了;
- 网络越到后面,特征越抽象,而且每个特征所涉及的感受野也更大了,因此随着层数的增加,3x3和5x5卷积的比例也要增加。但是,使用5x5的卷积核仍然会带来巨大的计算量。 为此,文章借鉴NIN2,采用1x1卷积核来进行降维。
- 另外增加了两个辅助的softmax分支,作用有两点,一是为了避免梯度消失,用于向前传导梯度。反向传播时如果有一层求导为0,链式求导结果则为0。二是将中间某一层输出用作分类,起到模型融合作用。最后的loss=loss_2 + 0.3 * loss_1 + 0.3 * loss_0。实际测试时,这两个辅助softmax分支会被去掉。
- 使用GAP代替全连接层
- Dense层的问题在于:参数量过大 、降低了训练速度且容易过拟合
- GAP的意义在于:在整个网络上进行正则化,GAP可接受任意大小的输入,但是GAP会拖慢收敛速度
InceptionV3
cvpr2015 Rethinking the Inception Architecture for Computer Vision
网络更深更宽带来的问题:
- 参数太多,若训练数据集有限,容易过拟合;
- 网络越大计算复杂度越大,难以应用;(内存和计算资源)
- 网络越深,梯度越往后穿越容易消失,难以优化模型。
思路:
- 如何减少参数(且保证性能):使用更小的核,比如\(5*5\) 换成 2个\(3*3\);使用Asymmetric方式,比如\(3*3\) 换成 \(1*3\)和\(3*1\)两种
- 如何减少computational cost:Inception结构,将全连接甚至一般的卷积都转化为稀疏连接;
- 如何解决“梯度消失”:BN层
设计原则
- 避免特征表示瓶颈,尤其是在网络的前面。要避免严重压缩导致的瓶颈。特征表示尺寸应该温和的减少,从输入端到输出端。特征表示的维度只是一个粗浅的信息量表示,它丢掉了一些重要的因素如相关性结构。
- 高纬信息更适合在网络的局部处理。在卷积网络中逐步增加非线性激活响应可以解耦合更多的特征,那么网络就会训练的更快。
- 空间聚合可以通过低纬嵌入,不会导致网络表示能力的降低。例如在进行大尺寸的卷积(如3*3)之前,我们可以在空间聚合前先对输入信息进行降维处理,如果这些信号是容易压缩的,那么降维甚至可以加快学习速度。
- 平衡好网络的深度和宽度。通过平衡网络每层滤波器的个数和网络的层数可以是网络达到最佳性能。增加网络的宽度和深度都会提升网络的性能,但是两者并行增加获得的性能提升是最大的。
模型结构
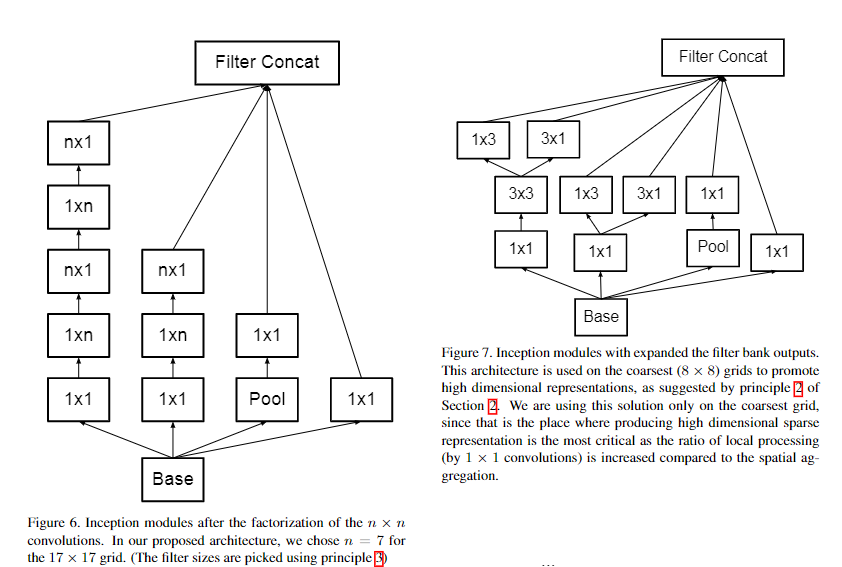
Inception-v2把7x7卷积替换为3个3x3卷积。包含3个Inception部分。第一部分是35x35x288,使用了2个3x3卷积代替了传统的5x5;第二部分减小了feature map,增多了filters,为17x17x768,使用了nx1->1xn结构;第三部分增多了filter,使用了卷积池化并行结构。网络有42层,但是计算量只有GoogLeNet的2.5倍。
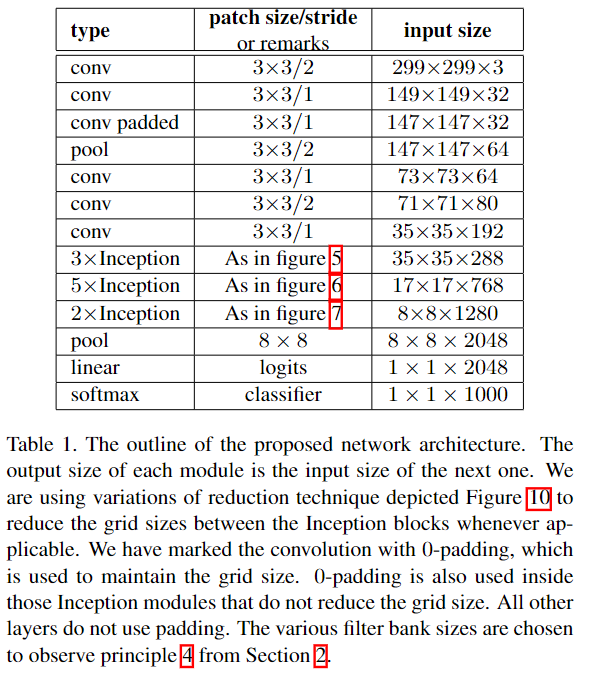
设计功能:最后两层之前模型完成 299x299x3 到 1x1x2048的特征映射,把input映射成2048维的特征向量,完成自动特征提取的工作;
其中,前面的conv和pool完成提取特征,中间Inception结构可以自动学习出滤波器的类型:
- 第一部分是35x35x288,使用了2个3x3卷积代替了传统的5x5;
- 第二部分减小了feature map,增多了filters,为17x17x768,使用了nx1->1xn结构;
- 第三部分增多了filter,使用了卷积池化并行结构。;
最后两层是一个全连接层,起到使用特征向量进行分类的功能。
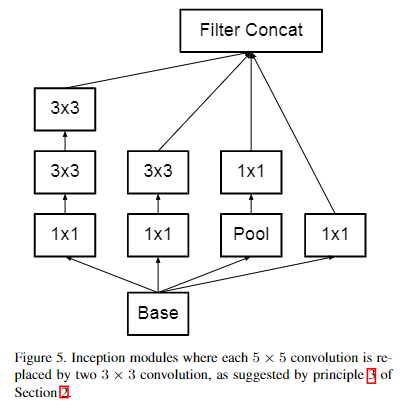
Inception架构的主要思想是找出如何用密集成分来近似最优的局部稀疏结。
- 采用不同大小的卷积核意味着不同大小的感受野,最后拼接意味着不同尺度特征的融合;
- 之所以卷积核大小采用1x1、3x3和5x5,主要是为了方便对齐。设定卷积步长stride=1之后,只要分别设定padding = 0、1、2,采用same卷积可以得到相同维度的特征,然后这些特征直接拼接在一起;
- 文章说很多地方都表明pooling挺有效,所以Inception里面也嵌入了pooling。
- 网络越到后面特征越抽象,且每个特征涉及的感受野也更大,随着层数的增加,3x3和5x5卷积的比例也要增加。
feature map size reduce
一般来说,卷积神经网络使用一些pooling操作来减少grid size of the feature maps。为了避免representation瓶颈,在应用maximum或者average pooling之前需要将activation的维度进行增加,比如输入\(k*d*d\)的feature map,想输出\(2k*\frac{d}{2}*\frac{d}{2}\),我们首先需要去进行一个stride为1的\(2k\)个通道的卷积。然后另外应用一个pooling。
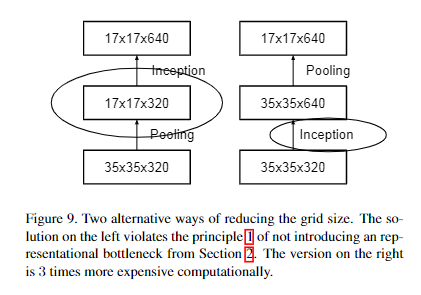
- 左图缺点:带来了一个representation瓶颈
- 右图缺点:计算量增加三倍
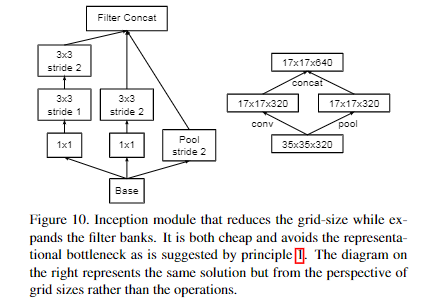
上图是作者新提出的降低feature map的size的方法:用一个并行(conv + pooling两个path的stride都为2)来实现。它很cheap并且避免了representation瓶颈。从grid size而不是op的视角来看,右图represents the same solution。
辅助分类器
Inception v1引进辅助的分类器去提高非常深的网络的收敛。引进辅助分类器的原始动机是加大梯度向更前层的流动(缓解梯度vanishing),从而加速训练过程中的收敛。Lee等人认为辅助分类器有助于更稳定的训练和better收敛。
有趣的是,作者发现辅助分类器并不能加速训练过程的早期收敛:辅助分类器并没有加速网络的早期收敛。在训练末期,有辅助分类器的网络开始超越没有辅助分类器的模型的准确率。
Inception v1使用了两个辅助分类器。去掉低层辅助分类器并不会对网络的最终效果产生负面影响。结合上一段,这意味着Inception v1关于辅助分类器的假设(辅助分类器有助于低层特征的evolving)是错误的。取而代之,我们认为辅助分类器的作用是一个regularizer。作者关于上一句话的解释:如果辅助分类器进行BN或Dropout,网络的主分类器的性能会更好。这也间接说明(weak supporting evidence)了BN作为一个regularizer的推测
Inception V3网络的最后一部分是Auxiliary Logits、全局平均池化、Softmax分类。
- 首先是Auxiliary Logits,作为辅助分类的节点,对分类结果预测有很大帮助。先通过end_points['Mixed_6e']得到Mixed_6e后的特征张量
- 之后接一个【5x5】的平均池化,步长为3,padding为VALID,张量尺寸从第2个模块组的【17x17x768】变为【5x5x768】
- 接着连接一个输出通道为128的【1x1】卷积和输出通道为768的【5x5】卷积,输出尺寸变为【1x1x768】。然后连接输出通道数为num_classes的【1x1】卷积,输出变为【1x1x1000】。最后将辅助分类节点的输出存储到字典表end_points中。
4. resnet
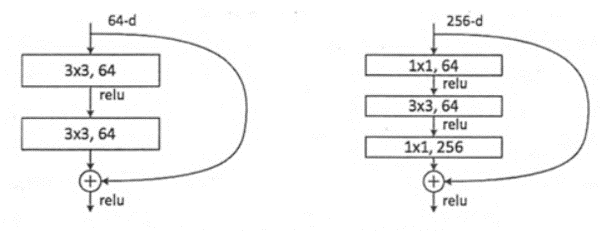
- 残差网络增加了一个identity mapping(恒等映射),把当前输出直接传输给下一层网络(全部是1:1传输,不增加额外的参数),相当于走了一个捷径,跳过了本层运算,这个直接连接命名为“skip connection”,同时在后向传播过程中,也是将下一层网络的梯度直接传递给上一层网络,这样就解决了深层网络的梯度消失问题
- “shortcut”快捷连接添加既不产生额外的参数,也不会增加计算的复杂度。快捷连接简单的执行身份映射,并将它们的输出添加到叠加层的输出。通过反向传播的SGD,整个网络仍然可以被训练成终端到端的形式。
5. resnext
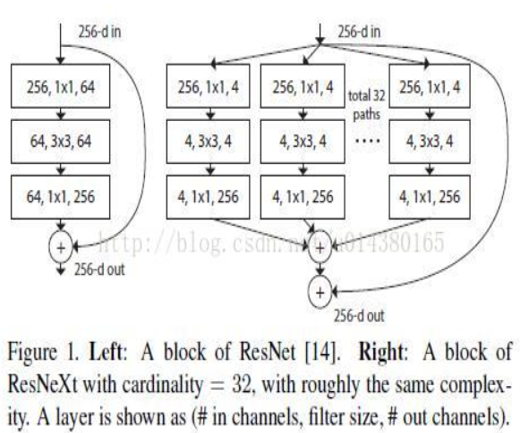
-
增加 cardinality 比增加深度和宽度更有效
-
用一种平行堆叠相同拓扑结构的blocks代替原来 ResNet 的三层卷积的block,在不明显增加参数量级的情况下提升了模型的准确率,同时由于拓扑结构相同,超参数也减少了,便于模型移植
-
网络结构简明,模块化
-
需要手动调节的超参少
-
与 ResNet 相比,相同的参数个数,结果更好:一个101层ResNeXt 网络,和200层的ResNet准确度差不多,但是计算量只有后者的一半
6. densenet
密集模块(Dense Block)包含多个卷积层,其中每一层 H_i 都由批归一化、ReLU 与之后的卷积构成。H_i 的输入不仅包含前一层的输出,还包含之前所有层的输出以及原始输入,即 x_₀, x_₁, …, x_{i-1}。下图中每个 H_i 都输出 4 个特征图。因此,在每一层,特征图的数量都增加 4 倍——增长率。
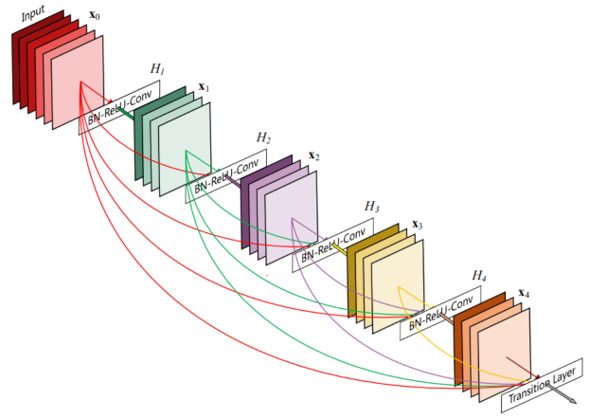
-
包含稠密块(Dense Blocks)和过渡块(transition layers)。 Dense Blocks内部必须特征图大小一致,每层的输入是concat连接,而不是ResNet的element-wise连接,内部的每一个节点代表BN+ReLU+Conv(参考ResNet V2),每个卷积层都是33k的filter,其中k被称为growth rate。Transition layers中包含的Pooling层会改变特征图的大小,transition layer节点由BN-Conv-Pool组成,卷积由1*1构成
-
加强了feature的传递
-
更有效的利用了feature
-
Resnet是做值的叠加,通道数是不变的,DenseNet是做通道的合并。你可以这么理解,add是描述图像的特征下的信息量增多了,但是描述图像的维度本身并没有增加,只是每一维下的信息量在增加,这显然是对最终的图像的分类是有益的。而concatenate是通道数的合并,也就是说描述图像本身的特征增加了,而每一特征下的信息是没有增加。
在代码层面就是ResNet使用的都是add操作,而DenseNet使用的是concatenate
7. xception
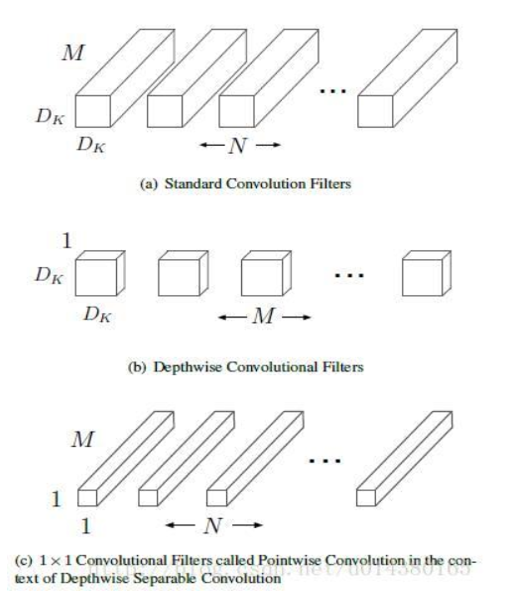
- 主要对inception v3进行改进,采用depthwise separable convolution来替换原来Inception v3中的卷积操作,在基本不增加网络复杂度的前提下提高了模型的效果
- 每个block之间采用的是add,而不是inception系列的concat
8.EfficientNet
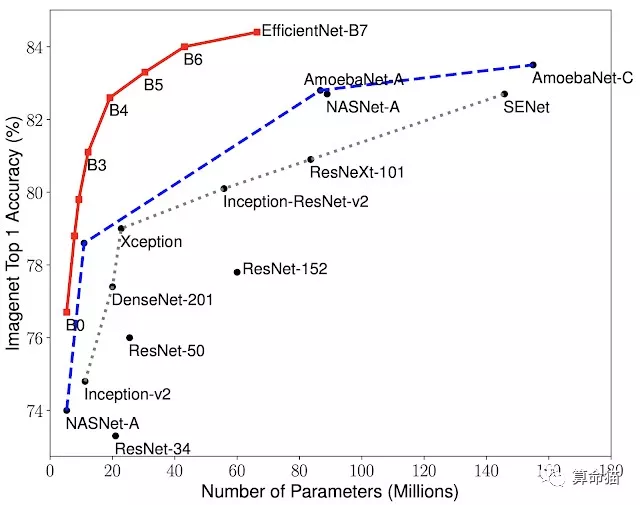
ICML2019的论文对目前分类网络的优化提出更加泛化的思想,认为目前常用的加宽网络、加深网络和增加分辨率这3种常用的提升网络指标的方式之间不应该是相互独立的。因此提出了compound model scaling算法,通过综合优化网络宽度、网络深度和分辨率达到指标提升的目的,能够达到准确率指标和现有分类网络相似的情况下,大大减少模型参数量和计算量。
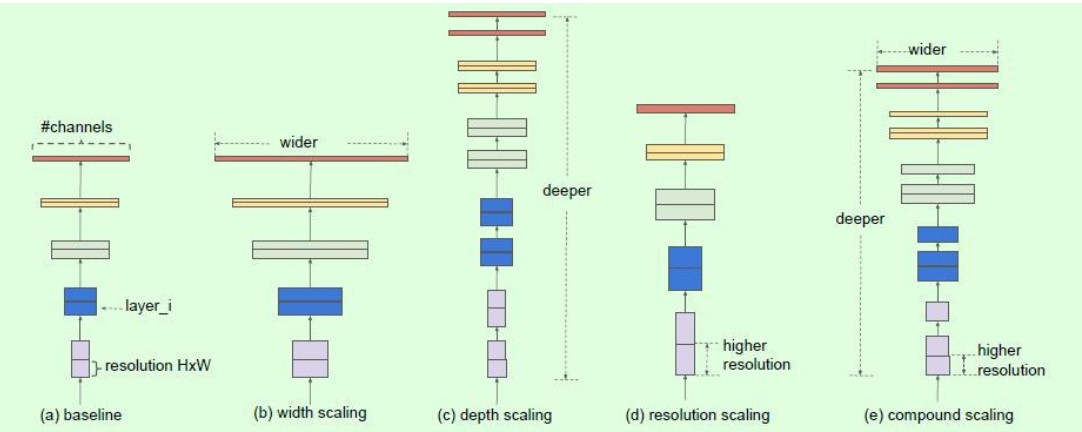
compound model scaling算法:找到最优的3个维度的scaling参数
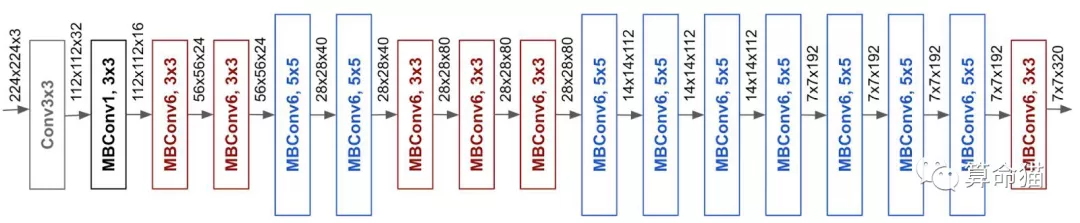
基础的efficientNet-B0
- 深度:更深的网络可以捕获到更丰富和更复杂的特征,再新任务上也可以泛化的更好。网络加深带来网络退化(梯度消失),虽然跨层连接、批量归一化可以缓解该类问题,但是深层网络的精度回报减弱了,即ResNet-1000和ResNet-101具有类似的精度
- 宽度:更宽的网络可以捕捉到更细粒度的特征。但是当网络宽度增大到一定程度时侯,精度很快就会饱和
- 分辨率:分辨率越高,更容易捕捉到细粒度的特征。从开始的224-299-331到GPipe的480
对网络深度、宽度和分辨率任意一个维度的提高都可以提升模型的性能,但是当模型架构到一定程度上,会出现精度回报减弱情况
为了追求更好的精度和效率,平衡网络所有的维度至关重要
APPENDING:加倍深度会使得FLOPS加倍,加倍宽度和分辨率会使得FLOPS加4倍
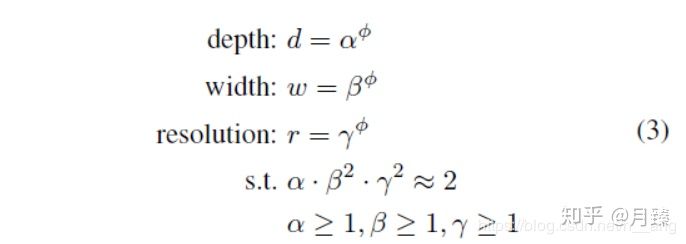
我们采用了和MnasNet相似的设置对我们的EfficientNet模型进行训练:
- RMSProp优化器,decay为0.9,momentum为0.9;
- batch norm momentum为0.99;
- weight decay为1e-5;
- 初始学习率为0.256,并且每2.4个epoches衰减0.97;
- 同时使用了swish activation,固定的增强技术,随机深度(drop connect ratio 为0.2),同时更大的模型需要更强的正则化,所以我们线性地增加dropout比率从EfficientNet-B0的0.2到EfficientNet-B7的0.5;
9.DLA
CVPR2018:https://arxiv.org/abs/1707.06484
https://github.com/ucbdrive/dla
研究如何聚合网络的不同层能更好地融合语义和空间信息以进行识别和定位
摘要
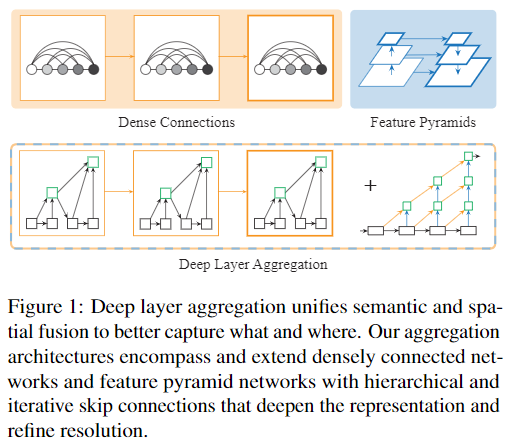
视觉识别任务需要丰富的信息,信息丰富程度从低到高,尺度从小到大。随着卷积神经网络的深度变化,单独的一层并不能够提供足够的信息,只有聚合这些信息,才能够提高获取what与where信息的准确性。现有的很多致力于网络结构设计的工作,包括探索不同的网络结构,设计更深、更大的网络,但是如何更好地融合网络不同层stage、块block之间的信息还没有得到足够的重视。尽管有常见的融合:skip connection技术,但是这种融合方式本身仅限于块内(译者注:"shallow" themselves),而且融合方式仅限于简单的叠加。本文通过采用更好地信息融合方法,来增强基础网络的能力。本文中DLA (Deep Layer Aggregation)结构能够迭代式的将网络结构的特征信息融合起来,从而让网络有更高的精度和更少的参数。同时本文比较了不同结构和不同识别任务,结果显示DLA技术相比起现有的网络分叉与融合策略,能取得更好地识别能力与分辨率
创新
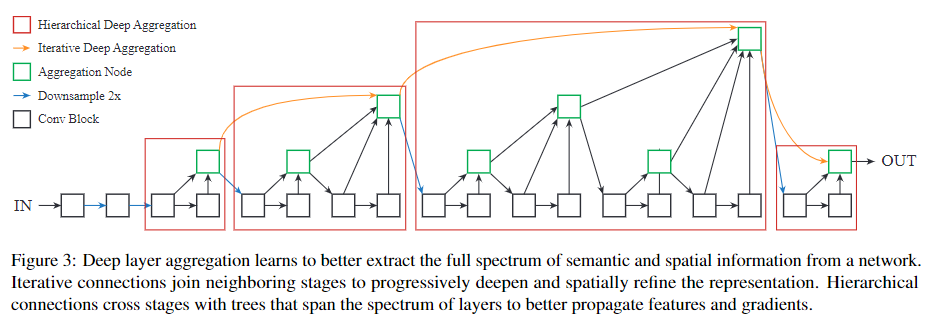
我们提出了深层聚合(DLA)的两种结构:迭代深层聚合(IDA)和层次深层聚合(HDA)
- 这些结构是独立于主干网络来设计的,以便与当前和未来的网络兼容
- IDA专注于融合不同分辨率和不同尺度,HDA则专注于合并来自所有模块和通道的特征
- IDA根据基础网络结构,逐级提炼分辨率和聚合尺度(类似于残差模块)
- HDA整合其自身的树状连接结构,并将各个层级聚合为不同等级的表征(空间尺度的融合,类似于FPN)
问题点
更多的非线性、更强的处理能力、更大的感受野一般能够提高网络精度,但是难于优化和计算。为了克服这些缺陷,不同的块block或者模组module之间通过协作来平衡和优化这些特点,比如使用bottlenecks进行维度缩减、或者使用residual残差、gated门和concatnative累加模组连接网络不同阶段的特征,以及梯度传播算法,应用这些技术的网络可以达到100+甚至1000+层。
然而,如何连接这些层layer和模组module还需要更多的研究。简单的层级网络,通过连续的堆叠层构造网络,如LeNet到AlexNet再到ResNet。精确到层的精度分析、transferability analysis迁移能力分析和表征可视化分析显示,更深的网络层提取的更多语义和更全局的特征,但是这些迹象并不能表明最后一层就是最终任务需要的表征结果。实际上skip connections已经证明对于分类和回归问题、以及其他一些更为结构化的问题的有效性。因此,如何使用Aggregation聚合,尤其指深度与宽度上的聚合对于网络结构来说是一个非常关键的技术。
思路
本文采用的聚合结构和现有的特征融合结构最为类似。融合主要从空间和语义两个维度上进行。语义融合,或者说在通道和深度方向上的聚合,能够提高推断“是什么”的能力。而空间信息的融合,或者说在分辨率和尺度上的聚合,可以提高推断“在哪儿”的能力。DLA可以看作是这两种融合的组合技术。
-
DenseNets是语义融合网络的最具代表性的网络,设计思路为,采用将不同层级之间的特征通过skip connection级联在一起,来达到更好地传播特征与损失的目的。本文采用的HDA技术采用了类似的思想,重视短路径的应用和复用。并且将skip connection跳跃连接构造了跨越各个层级树状连接结构,从而达到了比一般级联更深的融合效果。稠密连接和深度聚合实现了更高的精度的同时,保证了更有效率的内存利用和参数利用(换句话说就是网络里的参数都是有用的)。
-
FPN网络是空间融合网络中最具有代表性的网络,设计思路为,通过自上而下和横向的连接,来获取更均一化的分辨率和标准化的语义信息。本文所采用的深度聚合技术同样在分辨率尺度下作用,此外通过更强非线性和更激进的函数加深了表征提取。线性并且浅层的FPN连接并不能改善它们语义方面的弱点。金字塔式和深度聚合网络,对于结构化的识别任务,可以更好地解析出“在哪儿”和“是什么”。
思考:语义融合与空间融合的区别:
语义融合:
- 融合的是不同层级间的通道内信息;
- 通道大多在通道数上不同,空间尺度上相同,不需要尺度对齐;
- 主要保留微观信息;
空间融合:特征融合
- 融合的是不同层级间的特征图信息;
- 通道数是相同的,空间尺度上等比缩放,需要尺度对齐。也就是文中所说的均一化和标准化;
- 主要保留宏观信息;
结构
- IDA
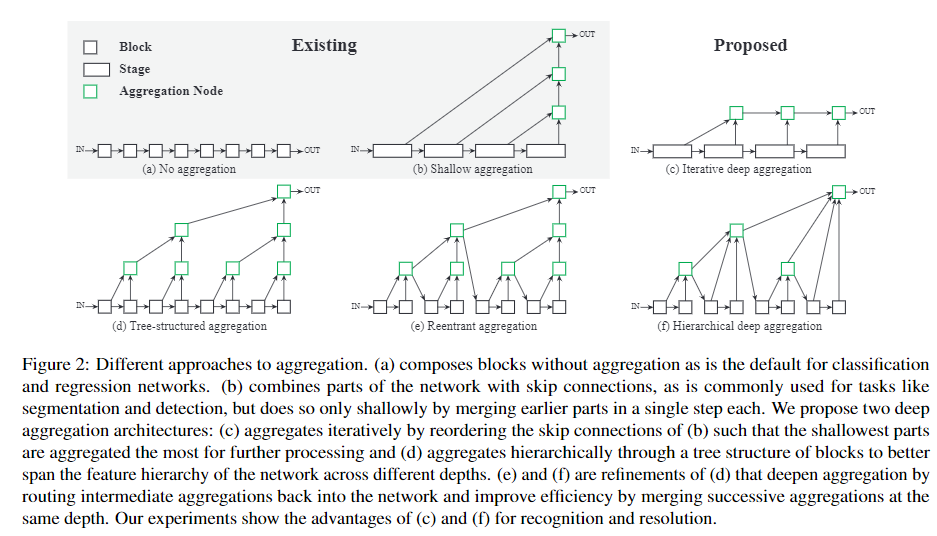
图(2)为不同的融合方法。(a) 标准的不包含聚合方法的网络;(b) 包含了跳跃连接块的网络,主要用于分割和检测任务,但是每一步中只融合了之前的浅层信息;(c) 迭代式的聚合,使浅层的网络可以在后续的网络中获得更多的处理;(d) 通过树状结构块的聚合,可以将特征结构在网络的不同深度上传播;(e)和(f)是(d)的改进,通过将中间聚合路由回网络来加深聚合,并通过合并相同深度的后续聚合来提高效率。 我们的实验显示了(c)和(f)在识别和分辨上的优势
因此,本文提出采用IDA的更为激进的聚合方法。聚合在最浅、最小尺度开始,并不断迭代是的吸收更深、更大尺度。这样的方式可以浅层网络的信息可以通过后续的不同层级的聚合而获得精炼。图2 (c) 展示了IDA的基本结构
-
HDA
分层深度聚合将树中的块和阶段合并,以保留和组合特征通道。 使用HDA可以将更浅的层次和更深的层次进行组合,从而获得跨越更多特征层次结构的更丰富的组合。尽管IDA有效地组合了各个阶段,但对于融合网络的许多块还是不够的,因为它仍然是顺序的。 图2(d)显示了层次聚合的深层分支结构。
在树的中间进行中间聚合时,我们将聚合节点的输出反馈回主干,作为对下一个子树的输入,如图2(e)所示。 这将传播所有先前块的聚合,而不是仅传播先前块的聚合,以更好地保留特征。 为了提高效率,我们合并了相同深度的聚合节点(将父节点和左节点合并),如图2(f)所示
-
Aggregation Nodes 聚合节点 AN
主要功能是组合和压缩节点的输入。这些节点通过训练来选择合适重要的信息来投影到与输入维度一致相同尺度的输出中去。在本文的结构中,所有的IDA节点都是二分节点(只有两个输入),而HDA节点根据树结构的深度不同而有一系列的参数输入。
虽然聚合节点可以基于任何块或层,但为了简单和高效,我们选择使用一个卷积来实现,跟着BN和非线性层。这避免了聚合结构的计算开销。
-
在图像分类网络中,所有节点都使用1×1卷积。
-
在语义分割中,添加了一种进一步的IDA来插值特征,在这种情况下使用3×3卷积
-
10.HRNet
TPAMI2019:Deep High-Resolution Representation Learning for Visual Recognition
总结一下HRNet创新点:
- 将高低分辨率之间的链接由串联改为并联。
- 在整个网络结构中都保持了高分辨率的表征(最上边那个通路),思路在当时来讲,不同分支的信息交互属于很老套的思路(如FPN等),我觉得最大的创新点还是能够从头到尾保持高分辨率,而不同分支的信息交互是为了补充通道数减少带来的信息损耗,这种网络架构设计对于位置敏感的任务会有奇效。
- 在高低分辨率中引入了交互来提高模型性能
总览
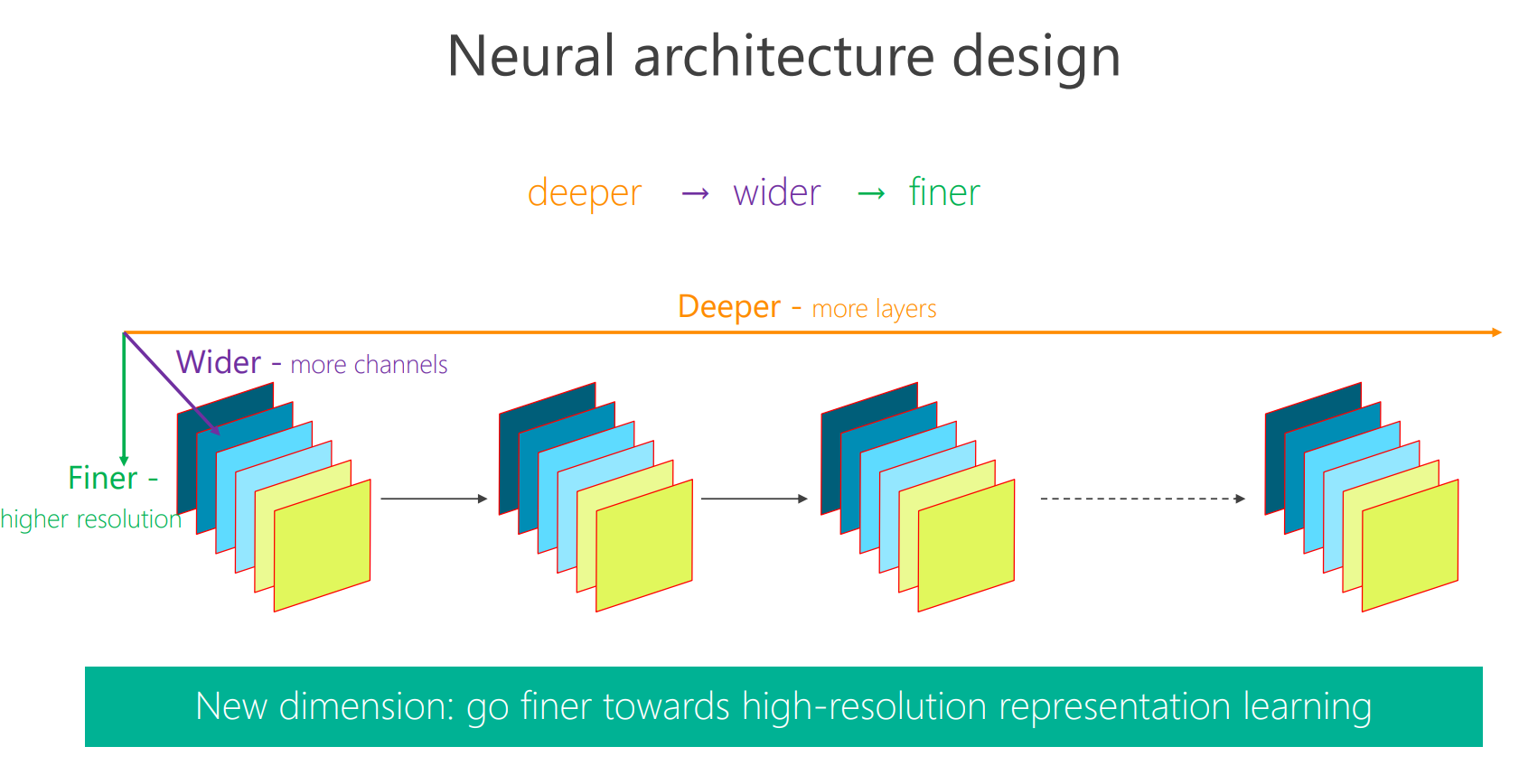
在人体姿态识别这类的任务中,需要生成一个高分辨率的heatmap来进行关键点检测。这就与一般的网络结构比如VGGNet的要求不同,因为VGGNet最终得到的feature map分辨率很低,损失了空间结构。

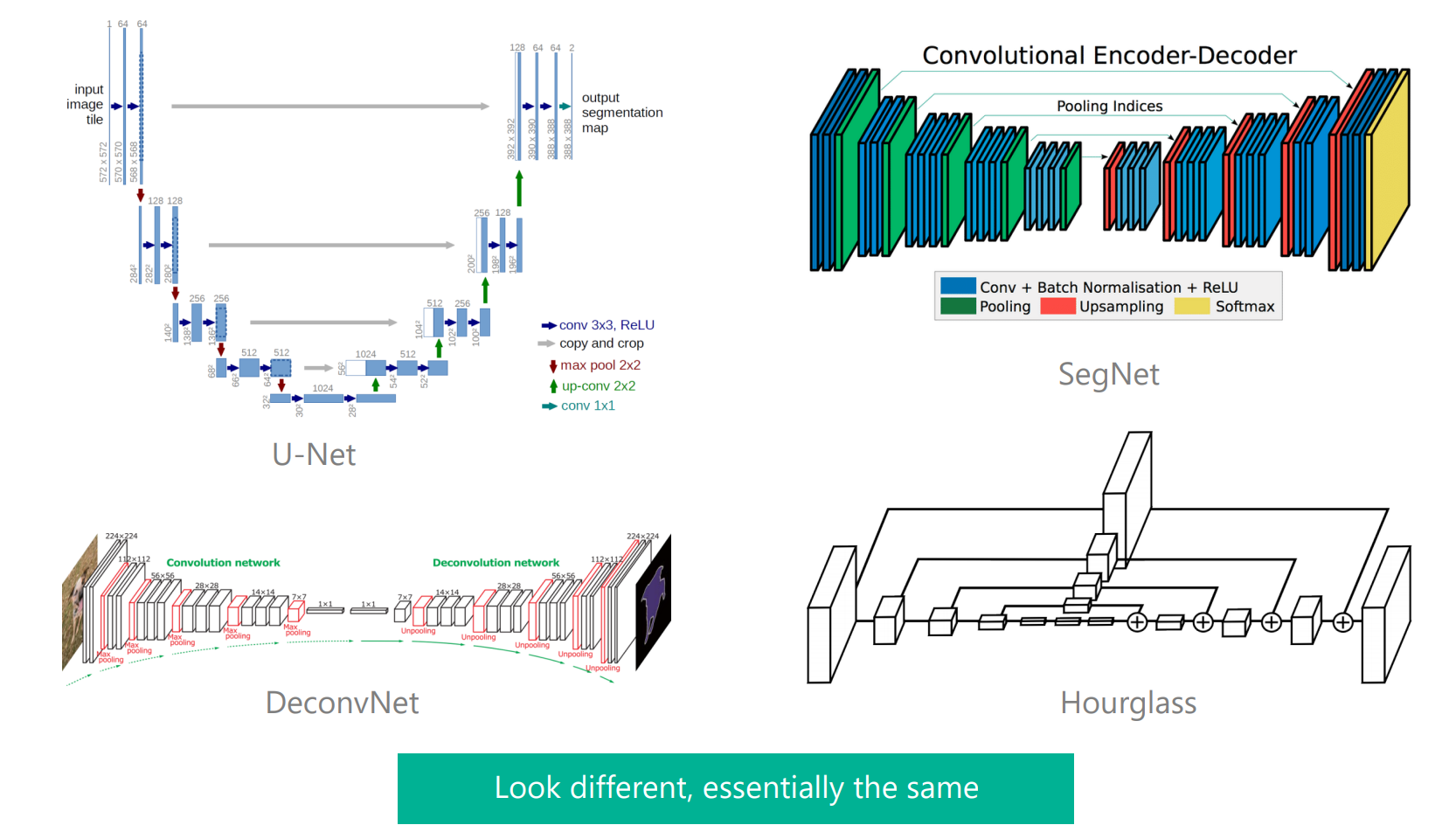
获取高分辨率的方式大部分都是如上图所示,采用的是先降分辨率,然后再升分辨率的方法。U-Net、SegNet、DeconvNet、Hourglass本质上都是这种结构。
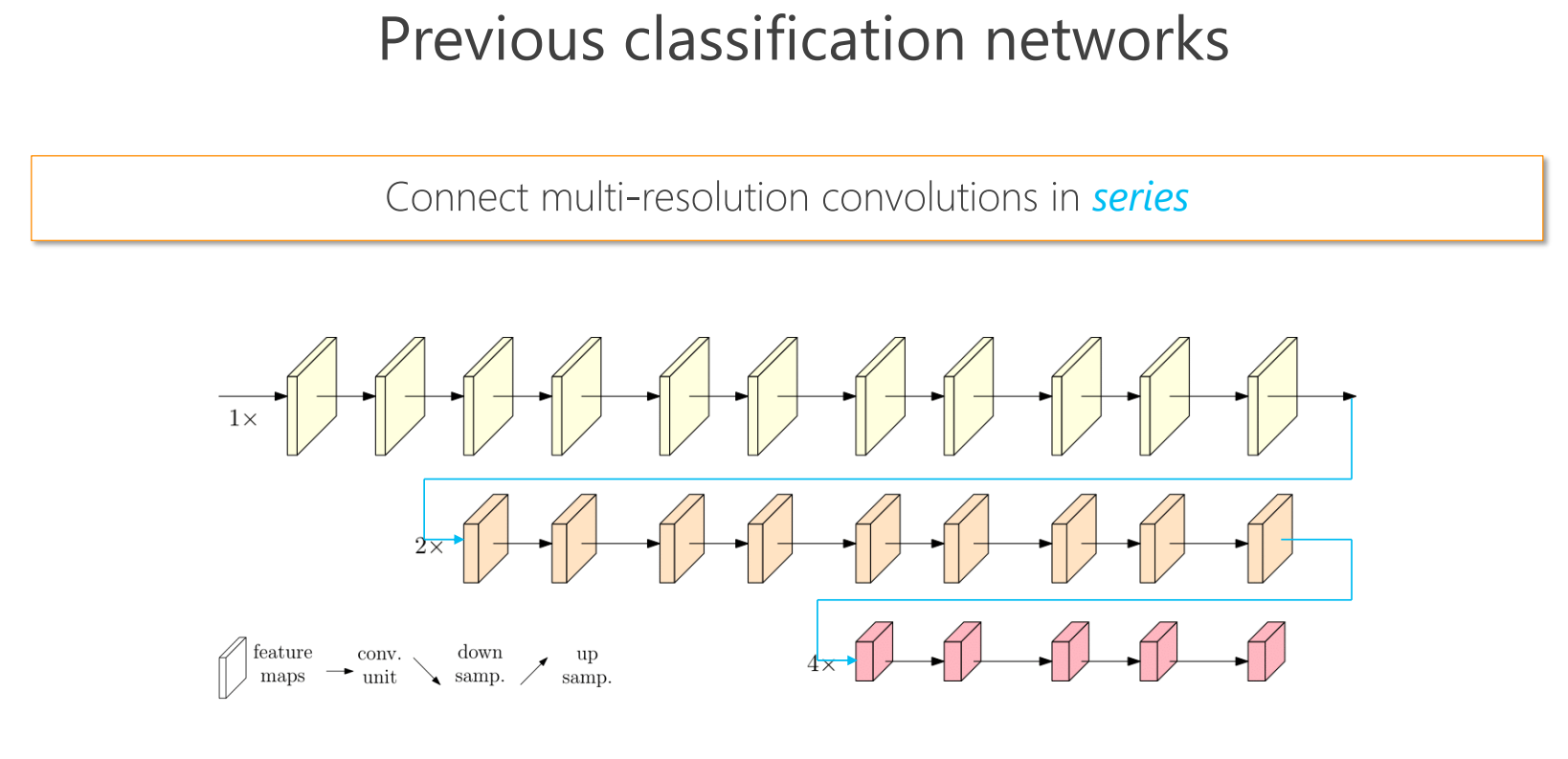
方案
先前的做法
hrnet做法:
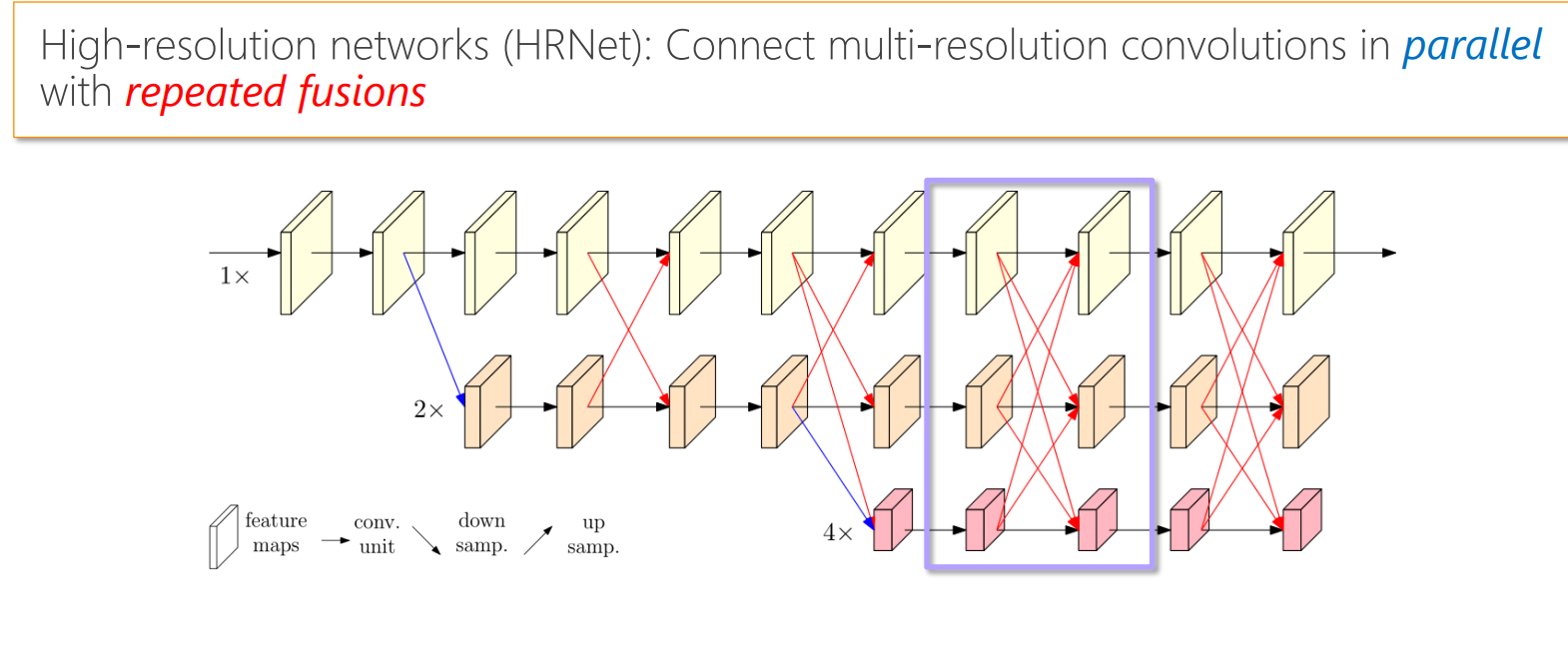
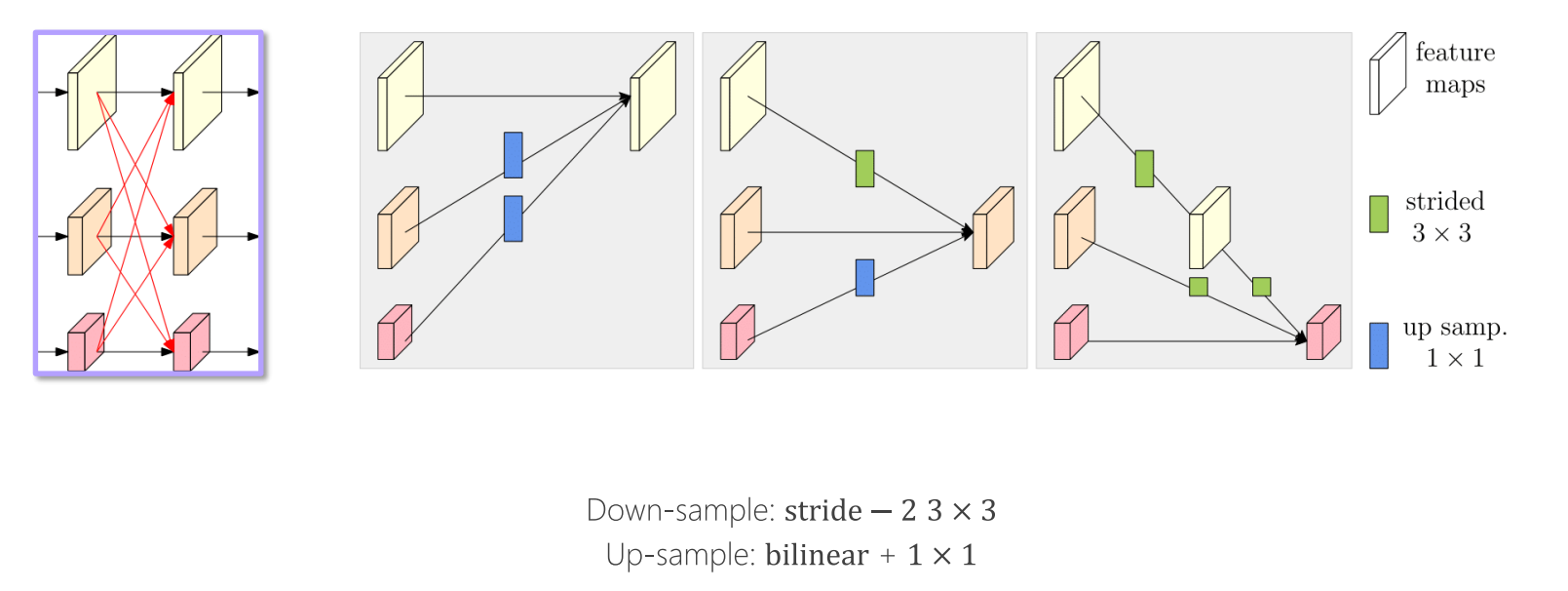
HRNet在并联的基础上,使得不同feature map进行交互,具体交互方式如上图,原则为:
- 同分辨率的层直接复制。
- 需要升分辨率的使用bilinear upsample + 1x1卷积将channel数统一。
- 需要降分辨率的使用strided 3x3 卷积。
- 三个feature map融合的方式是相加。
至于为何要用strided2 3x3卷积,这是因为卷积在降维的时候会出现信息损失,使用strided2 3x3卷积是为了通过学习的方式,降低信息的损耗。所以这里没有用maxpool或者组合池化。

最终输出为四分支,关于如何使用见下文
版本
HRNetV1

HRNetV2

将所有分辨率的特征图(小的特征图进行upsample)进行concate,主要用于语义分割和面部关键点检测
HRNetV2p

在HRNetV2的基础上,使用了一个特征金字塔,主要用于目标检测网络。
细节
backbone
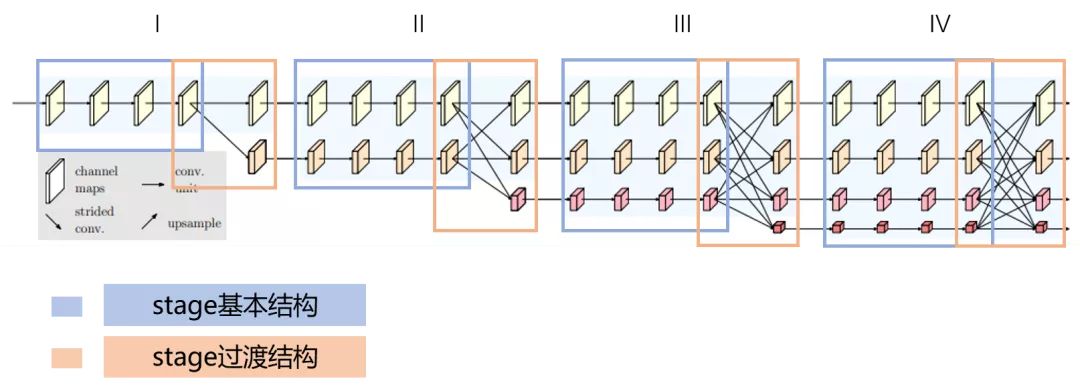
整个backbone部分可以分成4个stage,每个stage分成蓝色框和橙色框两部分。其中蓝色框部分是每个stage的基本结构,由多个branch组成,HRNet中stage1蓝色框使用的是BottleNeck,stage2&3&4蓝色框使用的是BasicBlock。其中橙色框部分是每个stage的过渡结构,HRNet中stage1橙色框是一个TransitionLayer,stage2&3橙色框是一个FuseLayer和一个TransitionLayer的叠加,stage4橙色框是一个FuseLayer。
解释一下为什么这么设计,FuseLayer是用来进行不同分支的信息交互的,TransitionLayer是用来生成一个下采样两倍分支的输入feature map的,stage1橙色框显然没办法做FuseLayer,因为前一个stage只有一个分支,stage4橙色框后面接neck和head了,显然也不再需要TransitionLayer了。
整个backbone的构建流程可以总结为:make_backbone -> make_stages -> make_branches
有关backbone构建相关的看源码,主要讲一下FuseLayer、TransitionLayer和Neck的设计
FuseLayer
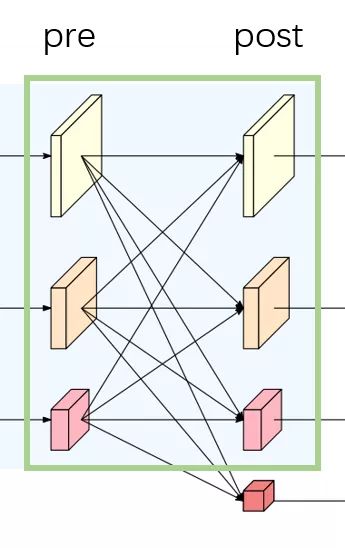
FuseLayer部分以绿色框为例,融合前为pre,融合后为post,静态构建一个二维矩阵,然后将pre和post对应连接的操作一一填入这个二维矩阵中。
以上图为例,图1的pre1和post1的操作为空,pre2和post1的操作为2倍上采,pre3和post1的操作为4倍上采;图2的pre1和post2的操作为3x3卷积下采,pre2和post2的操作为空,pre3和post2的操作为2倍上采;图3的pre1和post3的操作为连续两个3x3卷积下采,pre2和post3的操作为3x3卷积下采,pre3和post3的操作为空。
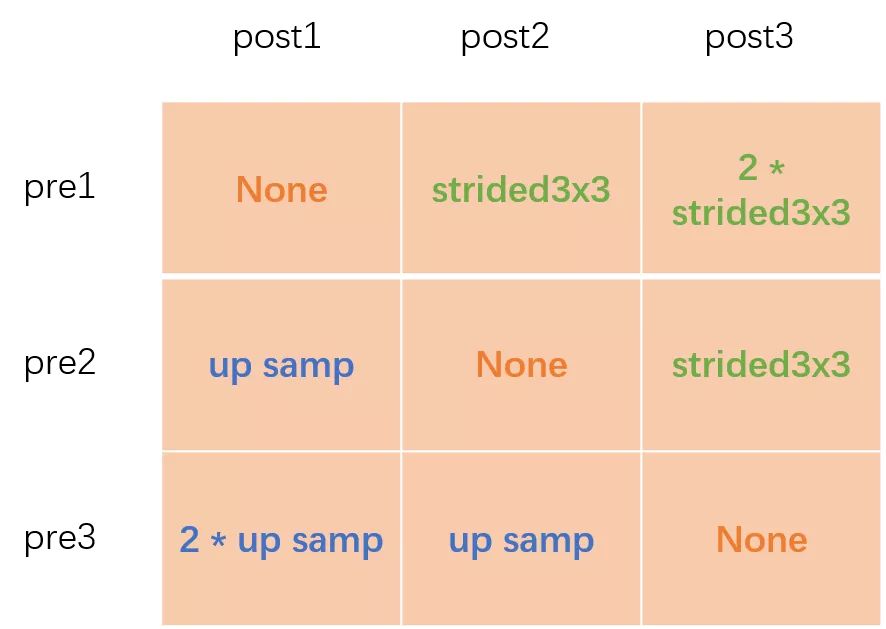
前向计算时用一个二重循环将构建好的二维矩阵一一解开,将对应同一个post的pre转换后进行融合相加。比如post1 = f11(pre1) + f12(pre2) + f13(pre3)
TransitionLayer
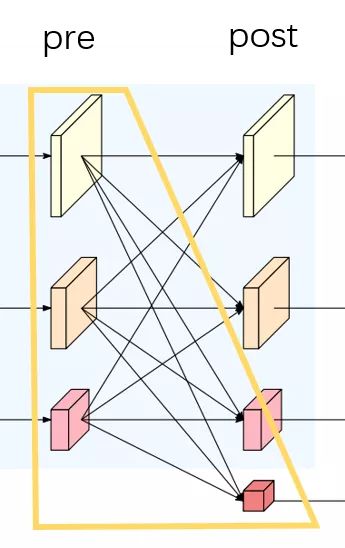
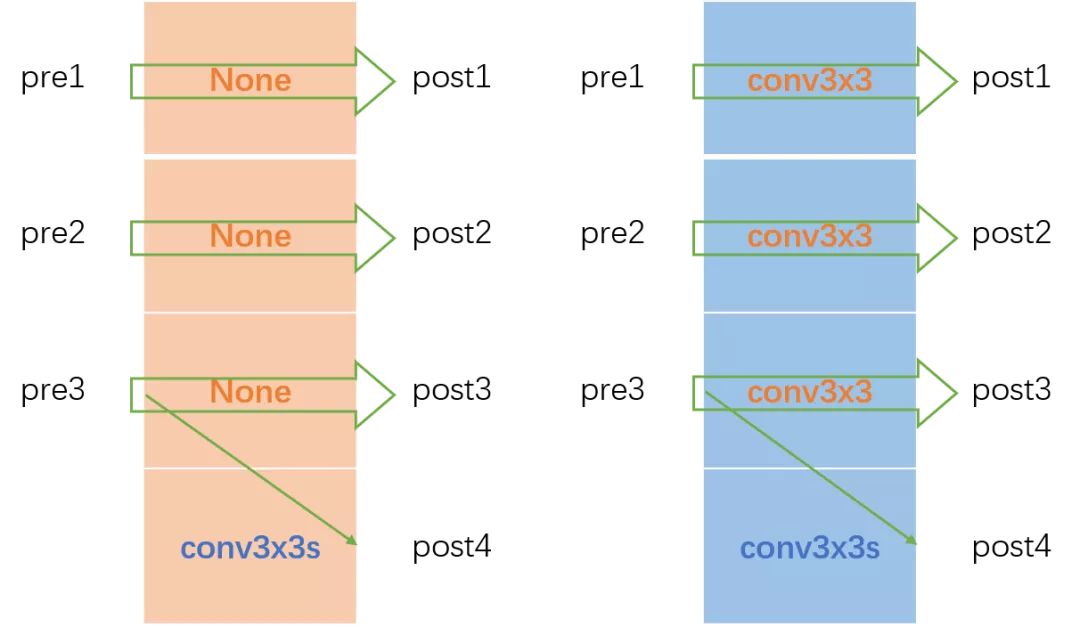
TransitionLayer以黄色框为例,静态构建一个一维矩阵,然后将pre和post对应连接的操作一一填入这个一维矩阵中。当pre1&post1、pre2&post2、pre3&post3的通道数对应相同时,一维矩阵填入None;通道数不相同时,对应位置填入一个转换卷积。post4比较特殊,这一部分代码和图例不太一致,图例是pre1&pre2&pre3都进行下采然后进行融合相加得到post4,而代码中post4通过pre3下采得到。
NECK
我把HRNet所描述的make_head过程理解成make_neck(因为一般意义上将最后的fc层理解成head更为清晰,这个在很多开源code中都是这样子拆解的)。下面着重讲解一下HRNet的neck设计。
HRNet的backbone输出有四个分支,paper中给出了几种方式对输出分支进行操作。
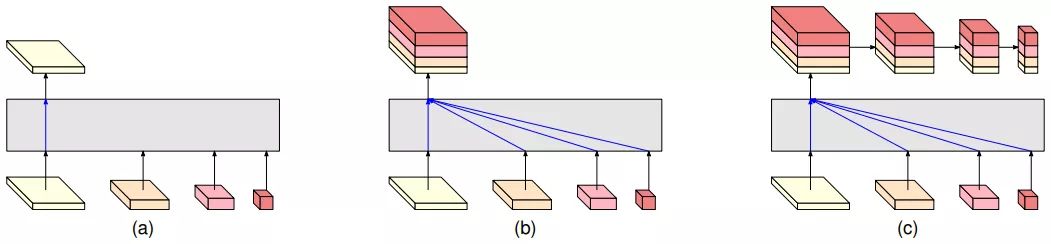
具体使用哪个上文已经阐述。而在分类任务中还有一种设置:
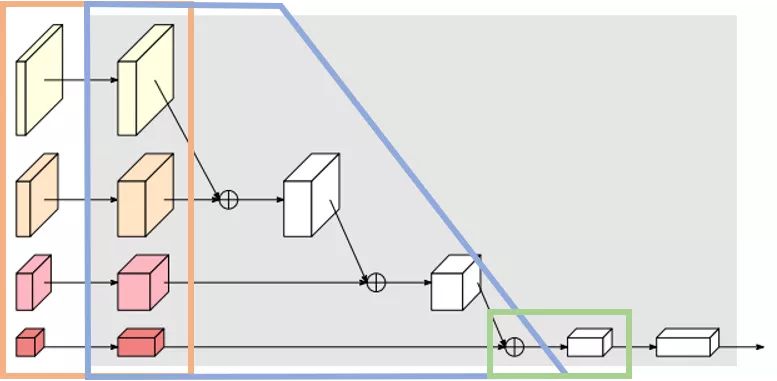
HRNet的neck可以分成三个部分,IncreLayer(橙色框),DownsampLayer(蓝色框)和FinalLayer(绿色框)。对每个backbone的输出分支进行升维操作,然后按照分辨率从大到小依次进行下采样同时从上到下逐级融合相加,最后用一个1x1conv升维。
11. NiN
2013:Network In Network
Network In Network (NIN)是由MinLinMin LinMinLin等人于2014年提出,在CIFAR-10和CIFAR-100分类任务中达到当时的最好水平,其网络结构是由三个多层感知机堆叠而被成。NiN模型论文《Network In Network》发表于ICLR-2014,NIN以一种全新的角度审视了卷积神经网络中的卷积核设计,通过引入子网络结构代替纯卷积中的线性映射部分,这种形式的网络结构激发了更复杂的卷积神经网络的结构设计,GoogLeNet的Inception结构就是来源于这个思想。
使用多层感知机结构来代替卷积的滤波操作,不但有效减少卷积核数过多而导致的参数量暴涨问题,还能通过引入非线性的映射来提高模型对特征的抽象能力。
使用全局平均池化来代替最后一个全连接层,能够有效地减少参数量(没有可训练参数),同时池化用到了整个特征图的信息,对空间信息的转换更加鲁棒,最后得到的输出结果可直接作为对应类别的置信度。
12. SENet
Squeeze-and-Excitation Networks
code
senet的主要贡献在于提出了 Squeeze-and-Excitation(SE)block , 此结构可以很好的地嵌入其它分类或检测模型中
SE block
中心思想:对于每个输出 channel,预测一个常数权重,对每个 channel 加权一下,本质上,SE模块是在 channel 维度上做 attention 或者 gating 操作,这种注意力机制让模型可以更加关注信息量最大的 channel 特征,而抑制那些不重要的 channel 特征。SENet 一个很大的优点就是可以很方便地集成到现有网络中,提升网络性能,并且代价很小。
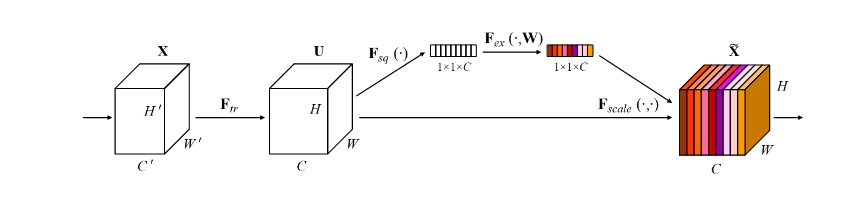
基本结构如上图所示, 对于每一输出通道,先进行 global average pool,每个通道得到 1个标量,C个通道得到C个数,然后经过 FC-ReLU-FC-Sigmoid 得到 C个0~1 之间的标量,作为通道的加权,然后原来的输出通道每个通道用对应的权重进行加权(对应通道的每个元素与权重分别相乘),得到新的加权后的特征,作者称为 feature recalibration。
第一步每个通道 \(H*W\) 个数全局平均池化得到一个标量,称之为 Squeeze,然后两个 FC得到0~1之间的一个权重值,对原始的每个 \(H*W\) 的每个元素乘以对应通道的权重,得到新的 feature map ,称之为 Excitation。任意的原始网络结构,都可以通过这个 Squeeze-Excitation的方式进行 feature recalibration。
SE module一般包含一个AdaptiveAvgPool2d、两个FC全连接层和一个Sigmoid函数。在模块的forward函数中,输入特征x首先被传入AdaptiveAvgPool2d中进行全局平均池化,然后经过两个全连接层和一个Sigmoid函数得到一个权重向量y,最后将原始特征x和权重向量y按元素相乘得到最终的加权特征输出。
参考代码
import torch.nn as nn
class SEModule(nn.Module):
def __init__(self, in_channels, reduction_ratio=16):
super(SEModule, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(output_size=1)
self.fc1 = nn.Linear(in_channels, in_channels // reduction_ratio)
self.relu = nn.ReLU(inplace=True)
self.fc2 = nn.Linear(in_channels // reduction_ratio, in_channels)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
b, c, _, _ = x.size()
y = self.avg_pool(x).view(b, c)
y = self.fc1(y)
y = self.relu(y)
y = self.fc2(y)
y = self.sigmoid(y).view(b, c, 1, 1)
return x * y
13. SKNet
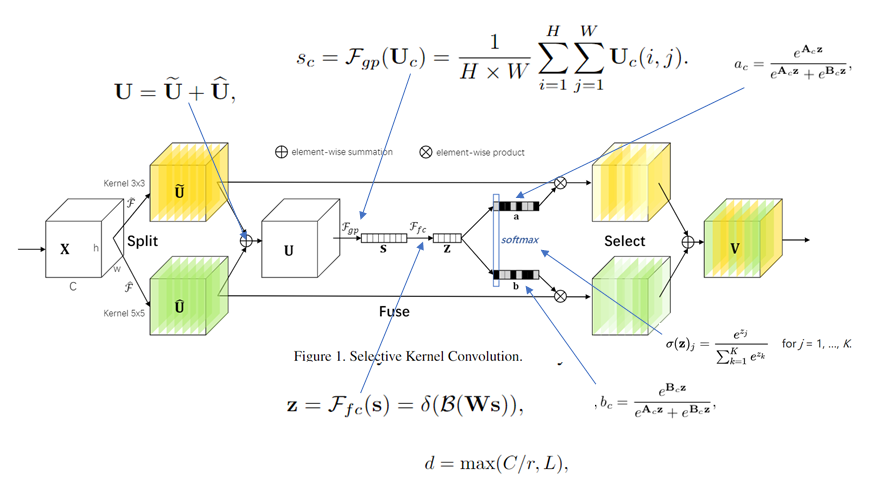
SKNet模块如上图所示,具体地说,其通过三个算子来实现SK卷积:Split, Fuse and Select。Split操作是将原feature map分别通过一个3×3的分组/深度卷积和3×3的空洞卷积(感受野为5×5)生成两个feature map :U1(图中黄色)和U2(图中绿色)。然后将这两个feature map进行相加,生成U。生成的U通过\(F_{gp}\)函数(全局平均池化)生成1×1×C的feature map(图中的s),该feature map通过\(F_{fc}\)函数(全连接层)生成d×1的向量(图中的z),公式如图中所示(δ表示ReLU激活函数,B表示Batch Noramlization,W是一个d×C的维的)。d的取值是由公式\(d = max(\frac{C}{r},L)\)确定,r是一个缩小的比率(与SENet中相似),L表示d的最小值,实验中L的值为32。生成的z通过\(a_c\)和\(b_c\)两个函数,并将生成的函数值与原先的U1和U2相乘。由于\(a_c\)和\(b_c\)的函数值相加等于1, 因此能够实现对分支中的feature map设置权重,因为不同的分支卷积核尺寸不同,因此实现了让网络自己选择合适的卷积核(\(a_c\)和\(b_c\)中的A、B矩阵均是需要在训练之前初始化的,其尺寸均为C×d)
14. ResNeSt
ResNeSt: Split-Attention Networks
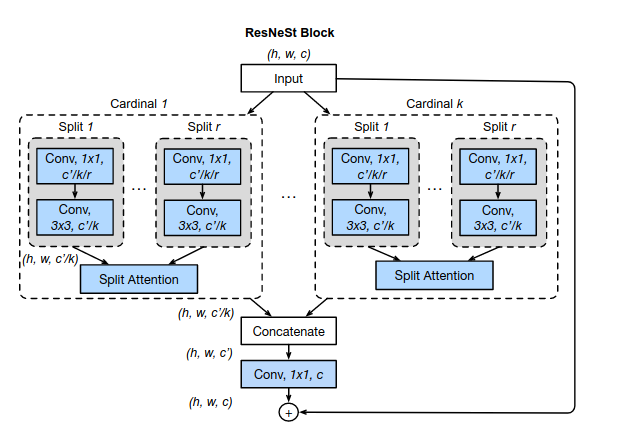
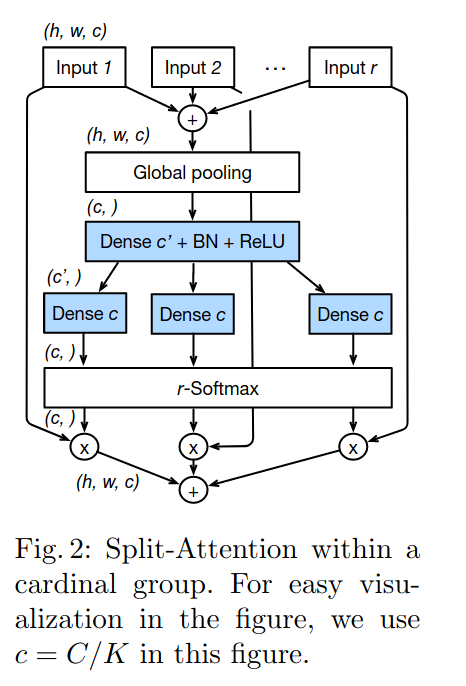
论文主要贡献如名字所示,加入了split-attention模块。主要分为两个点即split(multi-brach)和channel-attention。
- 将SE-Net和SK-Net中用到的对特征使用跨通道attention的方式进一步扩展到对特征图跨group计算attention,并使用普通CNN操作进行模块化,提出一个新的split-attention block。
- 将split-attention block以resnet的方式进行堆叠,得到ResNeSt。该网络可以直接替换检测、分割等任务的backbone并显著提升指标
2.轻量化网络
理论
在设计轻量级网络时,FLOPs和模型参数是主要考虑因素,但是减少模型大小和FLOPs不等同于减少推理时间和降低能耗。比如ShuffleNetv2与MobileNetv2在相同的FLOPs下,前者在GPU上速度更快。所以除了FLOPs和模型大小外,还需要考虑其他因素对能耗和模型推理速度的影响。这里考虑两个重要的因素:内存访问成本(Memory Access Cost,MAC)和GPU计算效率。
可参考shufflenetv2
- G1 相同通道宽度可以最小化内存访问成本MAC。
- G2 过多的组卷积会增加内存访问成本MAC
- G3 网络内部碎片操作会降低并行度
- G4 Element-wise操作不容忽视
内存访问成本
对于CNN网路来说,内存访问比计算对能耗贡献还大,如果网络中间特征比较大,甚至在同等模型大小下内存访问成本会增加,所以要充分考虑CNN层的MAC。在ShuffleNetV2论文中给出计算卷积层MAC的方法:
这里的\(k、h、w、c_i、c_o\)分别为卷积核大小,特征高和框,以及输入和输出的通道数。卷积层的计算量\(B=k^2hwc_ic_o\),如果固定计算量那么有:
根据均值不等式,可以知道当输入和输出的channel数相同时MAC才取下界,此时的设计是最高效的。
GPU计算效率
GPU计算的优势在于并行计算机制,这意味着当要计算的tensor较大时会充分发挥GPU的计算能力。如果将一个较大的卷积层拆分成几个小的卷积层,尽管效果是相同的,但是却是GPU计算低效的。所以如果功效一样,尽量采用较少的层。比如MobileNet中采用深度可分离卷积(depthwise conv+1x1 conv)虽然降低了FLOPs,但是因为额外的1x1卷积而不利于GPU运算效率。相比FLOPs,我们更应该关注的指标是FlOPs per Second,即用总的FLOPs除以总的GPU推理时间,这个指标越高说明GPU利用越高效。
网络内部碎片操作
碎片(Fragmentation)是指多分支上,每条分支上的小卷积或pooling等(如外面的一次大的卷积操作,被拆分到每个分支上分别进行小的卷积操作)。
如在NasNet-A就包含了大量的碎片操作,每条分支都有约13个操作,而ResnetV1上就只有2或3个操作。虽然这些Fragmented sturcture能够增加准确率,但是在高并行情况下降低了效率,增加了许多额外开销(内核启动、同步等等)。
Element-wise
Element-wise操作指的是 ReLU、AddTensor、AddBias等等。虽然这些操作只增加了一点点FLOPs,但是会带来很高的MAC,尤其是Depthwise Convolution深度卷积。
总结
- 平衡相邻层的卷积核数
- 留意组卷积带来的开销
- 减少碎片化的程度
- 减少Element-wise操作
1.MobileNet
mobilenetv1
MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
用于移动和嵌入式视觉应用。 MobileNets是基于一个流线型的架构,它使用深度可分离的卷积来构建轻量级的深层神经网络。引入两个简单的全局超参数,在延迟度和准确度之间有效地进行平衡。这两个超参数允许模型构建者根据问题的约束条件,为其应用选择合适大小的模型。

V1中使用了ReLU6作为激活函数,这个激活函数在 float16/int8 的嵌入式设备中效果很好,能较好的保持网络的鲁棒性。
ReLU6 就是普通的ReLU,但是限制最大输出值为6(对输出值做 clip),这是为了在移动端设备float16的低精度的时候,也能有很好的数值分辨率,如果对ReLU的激活范围不加限制,输出范围为0到正无穷,如果激活值非常大,分布在一个很大的范围内,则低精度的float16无法很好地精确描述如此大范围的数值,带来精度损失。
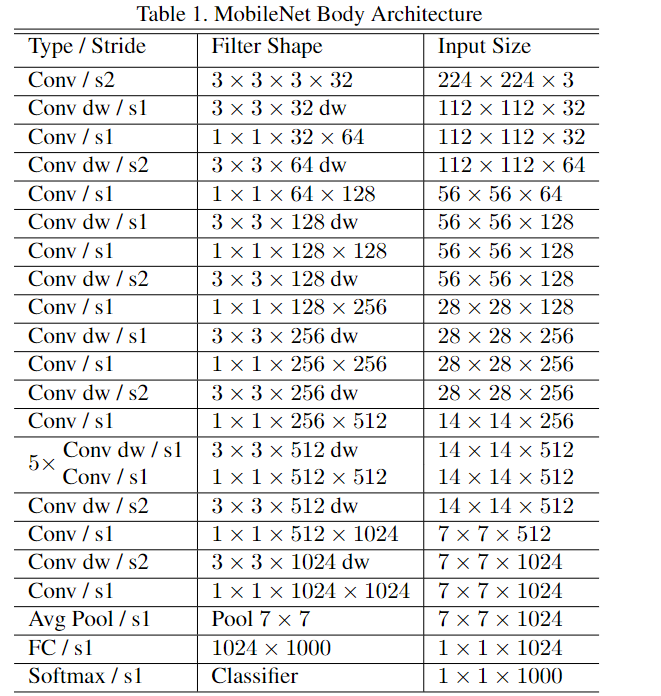
MobileNet的网络结构如下,一共由 28层构成(不包括AvgPool 和 FC 层,且把深度卷积和逐点卷积分开算),其除了第一层采用的是标准卷积核之外,剩下的卷积层都是用Depth Wise Separable Convolution。
mobilenetv2
MobileNet V1 的结构较为简单,另外,主要的问题还是在Depthwise Convolution 之中,Depthwise Convolution 确实降低了计算量,但是Depthwise部分的 Kernel 训练容易废掉,即卷积核大部分为零,作者认为最终再经过 ReLU 出现输出为 0的情况。
V2 传递的思想只有一个,即ReLU 会对 channel 数较低的张量造成较大的信息损耗,简单来说,就是当低维信息映射到高维,经过ReLU后再映射回低维时,若映射到的维度相对较高,则信息变换回去的损失较小;若映射到的维度相对较低,则信息变换回去后损失很大

原文:
此图表明:如果当前激活空间内兴趣流形完整度较高,经过ReLU,可能会让激活空间坍塌,不可避免的会丢失信息,所以我们设计网络的时候,想要减少运算量,就需要尽可能将网络维度设计的低一些但是维度如果低的话,激活变换ReLU函数可能会滤除很多有用信息。然后我们就想到了,反正ReLU另外一部分就是一个线性映射,那么如果我们全用线性分类器,会不会就不会丢失一些维度信息,同时可以设计出维度较低的层呢?。
所以论文针对这个问题使用Linear Bottleneck(即不使用ReLU激活,做了线性变换)的来代替原本的非线性激活变换。到此,优化网络架构的思想也出来了:通过在卷积模块中后插入 linear bottleneck来捕获兴趣流形。实验证明,使用linear bottleneck 可以防止非线性破坏太多信息。
从linear bottleneck 到深度卷积之间的维度比成为 Expansion factor(扩展系数),该系数控制了整个 block 的通道数。
解释:
当原始输入维度数增加到 15 以后再加 ReLU,基本不会丢失太多的信息;但如果只把原始输入维度增加到 2~5维度后再加 ReLU,则会出现较为严重的信息丢失。因此,认为对低维度做ReLU运算,很容易造成信息的丢失。而在高维度进行ReLU运算的话,信息的丢失则会很少。另外一种解释是,高维信息变换回低维度信息时,相当于做了一次特征压缩,会损失一部分信息,而再进行过ReLU后,损失的部分就更大了。作者为了这个问题,就将ReLU替换成线性激活函数。
v1和v2的对比:
-
相同点:都是采用 Depth-wise (DW)卷积搭配 Point-wise(PW)卷积的方式来提取特征。这两个操作合起来也叫 Depth-wise Separable Convolution,之前在 Xception中被广泛使用。这么做的好处是理论上可以成倍的减少卷积层的时间复杂度和空间复杂度,由下式可见,因为卷积核的尺寸K通常远远小于输出通道数 Count,因此标准卷积的计算量复杂度近似为 DW+PW 组合卷积的 \(k^2\)倍。
\[complexity = \frac{DWS conv}{conv}= \frac{1}{K^2} +\frac{1}{C_{out}} \] -
不同点(Linear Bottleneck):V2在DW卷积之前新加了一个PW卷积,这么做的原因是因为DW卷积由于本身的计算特性决定它自己没有改变通道数的能力,上一层给他多少通道,他就只能输出多少通道。所以如果上一层的通道数本身很少的话,DW也只能很委屈的低维空间提取特征,因此效果不是很好,现在V2为了改善这个问题,给每个 DW 之前都配备了一个PW,专门用来升维,定义升维系数为 t=6,这样不管输入通道数Cin 是多是少,经过第一个 PW 升维之后,DW都是在相对的更高维(\(t*Cin\))是多是少,经过第一个 PW升维之后,DW 都是在相对的更高维(t*Cin)进行辛勤工作的。而且V2去掉了第二个PW的激活函数,论文作者称其为 Linear Bottleneck。这么做是因为作者认为激活函数在高维空间能够有效的增加非线性,而在低维空间时则会破坏特征,不如线性的效果好。由于第二个PW的主要功能就是降维,因此按照上面的理论,降维之后就不宜再使用ReLU6了
graph LR v1 --> DW --ReLU6--> PW -- ReLU6--> ...graph LR v2 --> 1x1-PW -- ReLU6--> DW --ReLU6--> PW -- Linear--> ...
v2 和 ResNet对比:
-
残差模块:输入首先经过\(1*1\)的卷积进行压缩,然后使用\(3*3\)的卷积进行特征提取,最后在用\(1*1\)的卷积把通道数变换回去。整个过程是
压缩-卷积-扩张。这样做的目的是减少\(3*3\)模块的计算量,提高残差模块的计算效率。 -
倒残差模块:输入首先经过\(1*1\)的卷积进行通道扩张,然后使用\(3*3\)的depthwise卷积,最后使用\(1*1\)的pointwise卷积将通道数压缩回去。整个过程是
扩张-卷积-压缩。为什么这么做呢?因为depthwise卷积不能改变通道数,因此特征提取受限于输入的通道数,所以将通道数先提升上去。文中的扩展因子为6。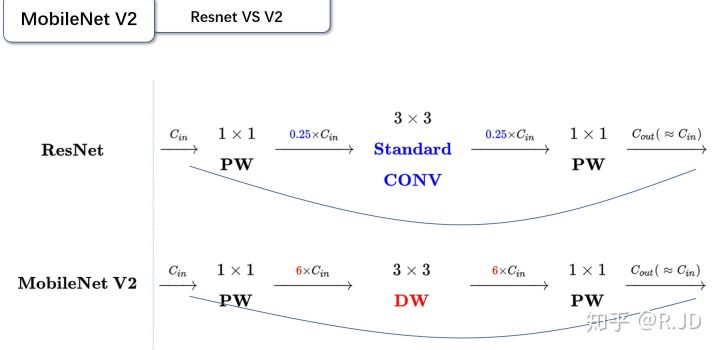
总结:
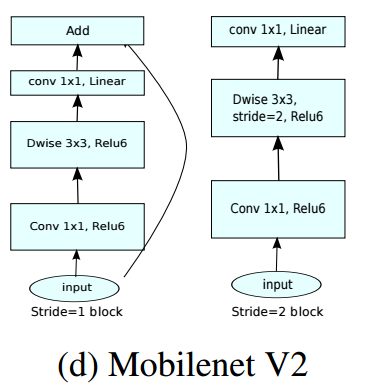
Mobilenet V2 的网络模块如下图所示,当 stride=1时,输入首先经过 $1*1 $卷积进行通道数的扩张,此时激活函数为 ReLU6;然后经过\(3*3\)的depthwise卷积,激活函数是ReLU6;接着经过\(1*1\)的pointwise卷积,将通道数压缩回去,激活函数是linear;最后使用shortcut,将两者进行相加。而当stride=2时,由于input和output的特征图的尺寸不一致,所以就没有shortcut了。
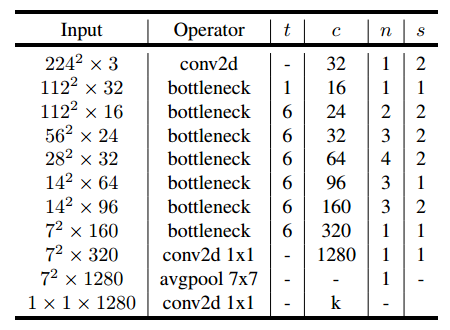
最后,给出V2的网络结构。其中,t 为扩张稀疏,c 为输出通道数,n 为该层重复的次数,s为步长。可以看出 V2 的网络比V1网络深了很多,V2有54层。
mobilenetv3
MobileNet V3发表于2019年,Mobilenet-V3 提供了两个版本,分别为 MobileNet-V3 Large以及 MobileNet-V3 Small,分别适用于对资源要求不同的情况。V3结合了v1的深度可分离卷积、v2的Inverted Residuals和Linear Bottleneck、SE模块,利用NAS(神经结构搜索)来搜索网络的配置和参数。
-
修改尾部结构
在MobileNetV2中,在Avg Pooling之前,存在一个$ 11 $的卷积层,目的是提高特征图的维度,更有利于结构的预测,但是这其实带来了一定的计算量了。所以这里作者做了修改,将其放在 avg Pooling 的后面,首先利于 avg Pooling 将特征图的大小由 \(7*7\) 降到了 \(1*1\),降到 $11 $后,然后再利用 \(1*1\) 提高维度,这样就减少了 \(7*7 =49\) 倍的计算量。并且为了进一步的降低计算量,作者直接去掉了前面纺锤型卷积的$ 33 $以及 \(1*1\) 卷积,进一步减少了计算量,就变成了如下图第二行所示的结构,作者将其中的 \(3*3\) 以及 $11 $去掉后,精度并没有得到损失,这里降低了大约 10ms的延迟,提高了15%的运算速度,且几乎没有任何精度损失。其次,对于v2的输入层,通过\(3*3\)卷积将输入扩张成32维。作者发现使用ReLU或者swish激活函数,能将通道数缩减到16维,且准确率保持不变。这又能节省3ms的延时。
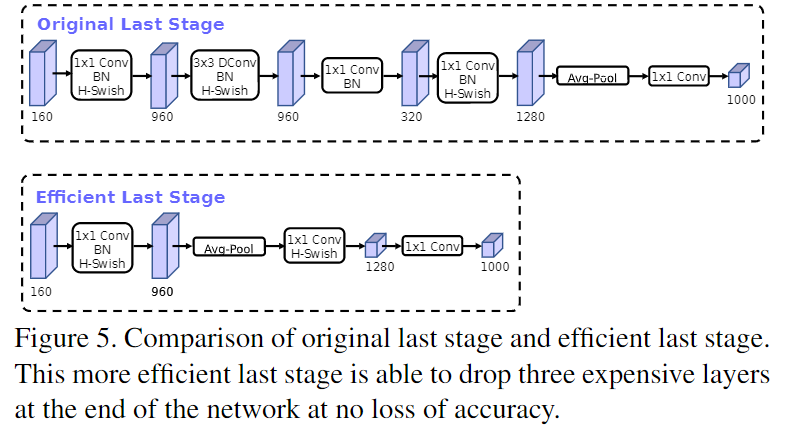
-
H-swish
由于嵌入式设备计算sigmoid是会耗费相当大的计算资源的,特别是在移动端,因此作者提出了h-swish作为激活函数。且随着网络的加深,非线性激活函数的成本也会随之减少。所以只有在较深的层使用h-swish才能获得更大的优势。
\[swish(x) = x \cdot \sigma(x) \]\[h-swish(x) = x \cdot \frac{ReLU6(x+3)}{6} \]观察上图可以发现,其实相差不大(不过swish是谷歌自家的研究成果,h-swish 是在其基础上,为速度进行了优化)。使用ReLU6的好处:
- 可以在任意平台进行计算
- 量化的时候,它消除了潜在的精度损失,使用 h-swish 替换 swish,在量化模式下会提高大约 15%的效率
-
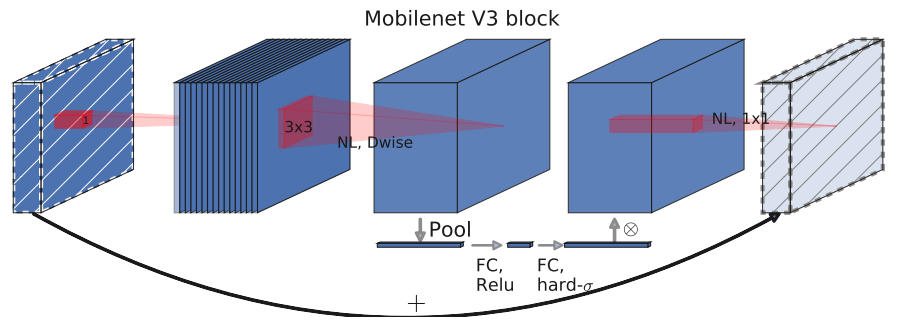
SE
在v2的 bottleneck 结构中引入SE模块,并且放在了 depthwise filter 之后,SE模块是一种轻量级的通道注意力模块,因为SE结构会消耗一定的时间,所以在depthwise之后,经过池化层,然后第一个fc层,通道数缩小4倍,再经过第二个fc层,通道数变换回去(扩大4倍),然后与depthwise进行按位相加,这样作者发现,即提高了精度,同时还没有增加时间消耗。
2.ShuffleNet
shufflenetv1
主要采用channel shuffle、pointwise group convolutions和depthwise separable convolution来修改原来的ResNet单元
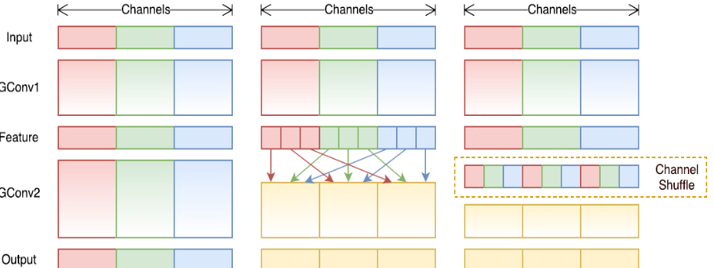
ShuffleNet的核心就是用pointwise group convolution,channel shuffle和depthwise separable convolution代替ResNet block的相应层构成了ShuffleNet uint,达到了减少计算量和提高准确率的目的。channel shuffle解决了多个group convolution叠加出现的边界效应,pointwise group convolution和depthwise separable convolution主要减少了计算量。
对比mobilenet和shufflenet:
-
一看名字 ShuffleNet,就知道 shuffle 是本文的重点,那么 shuffle 是什么?为什么要进行 shuffle?
shuffle 具体来说是 channel shuffle,是将各部分的 feature map 的 channel 进行有序的打乱,构成新的 feature map,以解决 group convolution 带来的「信息流通不畅」问题。(MobileNet 是用 point-wise convolution 解决的这个问题)。
因此可知道 shuffle 不是什么网络都需要用的,是有一个前提,就是采用了 group convolution,才有可能需要 shuffle!!为什么说是有可能呢?因为可以用 point-wise convolution 来解决这个问题。
-
对比一下 MobileNet,采用 shuffle 替换掉 1x1卷积,这样可以减少权值参数,而且是减少大量权值参数,因为在 MobileNet 中,1*1 卷积层有较多的卷积核,并且计算量巨大。
-
在网络拓扑方面,ShuffleNet 采用的是 resnet 的思想,而 mobielnet 采用的是 VGG 的思想,SqueezeNet (主要采用1x1卷积核压缩feature map数量实现轻量化)也是采用 VGG 的堆叠思想
shufflenetv2
ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design
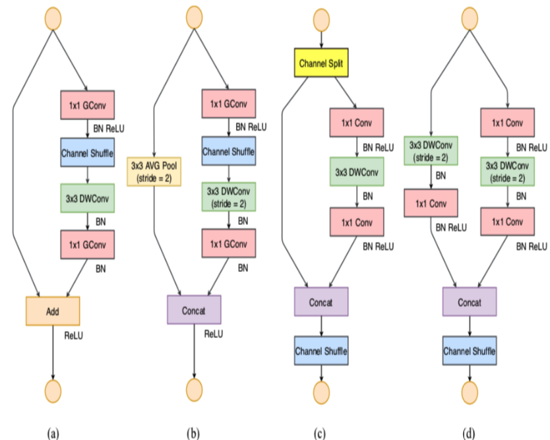
ShuffleNet-V1 严重依赖组卷积,违背了G2,如下图,a,b为V1,c,d为V2。
首先ShuffleNetV1是在给定的计算预算(FLOP)下,为了增加准确率,选择采用了 逐点组卷积 和 类似瓶颈的结构,且还引入了 channel shuffle操作. 如图的(a)、(b)所示。
很明显,逐点组卷积 和 类似瓶颈的结构 增加了MAC(违背G1和G2),采用了太多组卷积违背了G3, Add 操作违背了G4,因此关键问题在于如何保持大量同宽通道的同时,让网络非密集卷积也没太多组卷积。
为了改善v1的缺陷,v2版本引入了一种新的运算:channel split。具体来说,在开始时先将输入特征图在通道维度分成两个分支:通道数分别为\(c^{'}\) 和 \(c-c^{'}\) ,实际实现时\(c^{'}=\frac{c}{2}\) 。左边分支做同等映射,右边的分支包含3个连续的卷积,并且输入和输出通道相同,这符合G1。而且两个1x1卷积不再是组卷积,这符合G2,另外两个分支相当于已经分成两组。两个分支的输出不再是Add元素,而是concat在一起,紧接着是对两个分支concat结果进行channle shuffle,以保证两个分支信息交流。其实concat和channel shuffle可以和下一个模块单元的channel split合成一个元素级运算,这符合原则G4。
对于下采样模块,不再有channel split,而是每个分支都是直接copy一份输入,每个分支都有stride=2的下采样,最后concat在一起后,特征图空间大小减半,但是通道数翻倍。
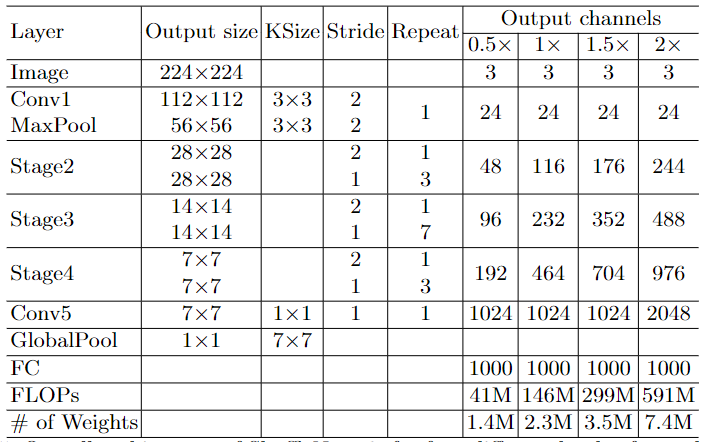
值得注意的一点是,v2在全局pooling之前增加了个conv5卷积,这是与v1的一个区别
3.CSPNet
可以看作是DenseNet的升级版,改进了密集块和过渡层的信息流,优化了梯度反向传播路径,提升了网络的学习能力,同时在处理速度和内存方面提升了不少。在目标检测方面,也做了轻量化设计。yolov5和v4中都使用了此结构
Cross Stage Partial Network(CSPNet)就是从网络结构设计的角度来解决以往工作在推理过程中需要很大计算量的问题。
作者认为推理计算过高的问题是由于网络优化中的梯度信息重复导致的。CSPNet通过将梯度的变化从头到尾地集成到特征图中,在减少了计算量的同时可以保证准确率。CSPNet是一种处理的思想,可以和ResNet、ResNeXt和DenseNet结合。
主要解决的问题:
-
Strengthening learning ability of a CNN
现有的CNN经过轻量化后,其准确性大大降低,所以我们希望加强CNN的学习能力,使其在轻量化的同时保持足够的准确性。所提出的CSPNet可以很容易地应用于ResNet、ResNeXt和DenseNet。将CSPNet应用于上述网络后,计算量从10%减少到20%,并且精度优于对方。
-
Removing computational bottlenecks
过高的计算瓶颈将导致更多的周期来完成推理过程,否则一些算术单元将经常空闲。因此,我们希望在CNN中能够将每一层的计算量平均分配,从而有效的提高每一个计算单元的利用率,减少不必要的能源消耗。注意到所提出的CSPNet使PeleeNet的计算瓶颈减半。此外,在基于MS COCO数据集的目标检测实验中,我们提出的模型在基于yolov3的模型上测试时,可以有效地减少80%的计算瓶颈。
-
Reducing memory costs
动态随机存取存储器(DRAM)的晶圆制造成本非常高,同时也占用大量的空间。如果能有效降低存储成本,将大大降低ASIC的成本。此外,小面积晶圆可以用于各种边缘计算设备。为了减少内存使用,在特征金字塔生成过程中,我们采用了跨通道的pooling 来压缩特征映射。这样,在生成特征金字塔时,CSPNet可以减少PeleeNet 75%的内存使用.
由于CSPNet能够提升CNN的学习能力,因此我们使用更小的模型来达到更好的准确性。我们提出的模型在COCO的AP50可以达到50%,GTX 1080ti 达到109 fps。由于CSPNet可以有效地减少大量的内存流量,我们提出的方法可以在IntelCore i9-9900K上以52 fps的速度COCO AP50实现40%。此外,由于CSPNet可以显著降低计算瓶颈,精确FusionModel (EFM)可以有效降低所需的内存带宽,我们提出的方法可以在Nvidia Jetson TX2上以49 fps的速度COCO AP50实现42%。
结构:
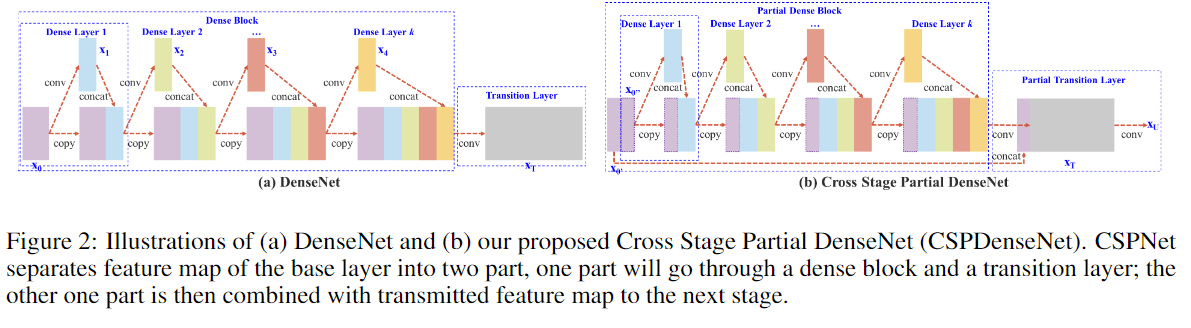
(a)为DenseNet单阶段结构的详细结构。DenseNet的每个阶段包含一个密集块和一个过渡层,每个密集块由k个密集层组成。第i个密集层的输出将与第i个密集层的输入连接,连接后的输出将成为第(i+ 1)个密集层的输入。
CSPDenseNet的一个阶段由局部密集块和局部过渡层组成。在局部密集块中,通过通道\(x_0=[x^{''}_0 ,x^{'}_0 ]\)将某一阶段的基础层特征映射分成两部分。在\(x^{'}_0\)和\(x^{''}_0\)之间,前者直接连接到阶段的末端,后者将进入一个密集块。
另一方面,没有经过密集层的特征图 \(x^{'}_0\)也被单独积分。
对于更新权值的梯度信息,两边不包含属于其他边的重复梯度信息。
总的来说,所提出的CSPDenseNet保留了DenseNet特性重用特性的优点,但同时通过截断梯度流防止了过多的重复梯度信息。该思想通过设计一种分层的特征融合策略来实现,并应用于局部过渡层。
Partial Dense Block
设计局部密集块的目的是为了
-
增加梯度路径:通过分块归并策略,可以使梯度路径的数量增加一倍。由于采用了跨阶段策略,可以减轻使用显式特征图copy进行拼接所带来的弊端;
-
每一层的平衡计算:通常,DenseNet基层的通道数远大于生长速率。由于在局部稠密块中,参与稠密层操作的基础层通道仅占原始数据的一半,可以有效解决近一半的计算瓶颈;
-
减少内存流量:假设DenseNet中一个稠密块的基本特征图大小为w×h×c,增长率为d,共有m个稠密层。则该密集块的CIO为 \((c×m) + (((m^2+m)×d)/2\),而局部密集块的CIO为\(((c×m) + (m^2+m)×d)/2\)。虽然m和d通常比c小得多,但单局部密集的块最多可以节省一半的网络内存流量。
Partial Transition Layer
设计局部过渡层的目的是使梯度组合的差异最大。局部过渡层是一种层次化的特征融合机制,它利用梯度流的聚合策略来防止不同的层学习重复的梯度信息。在这里,我们设计了两个CSPDenseNet变体来展示这种梯度流截断是如何影响网络的学习能力的。
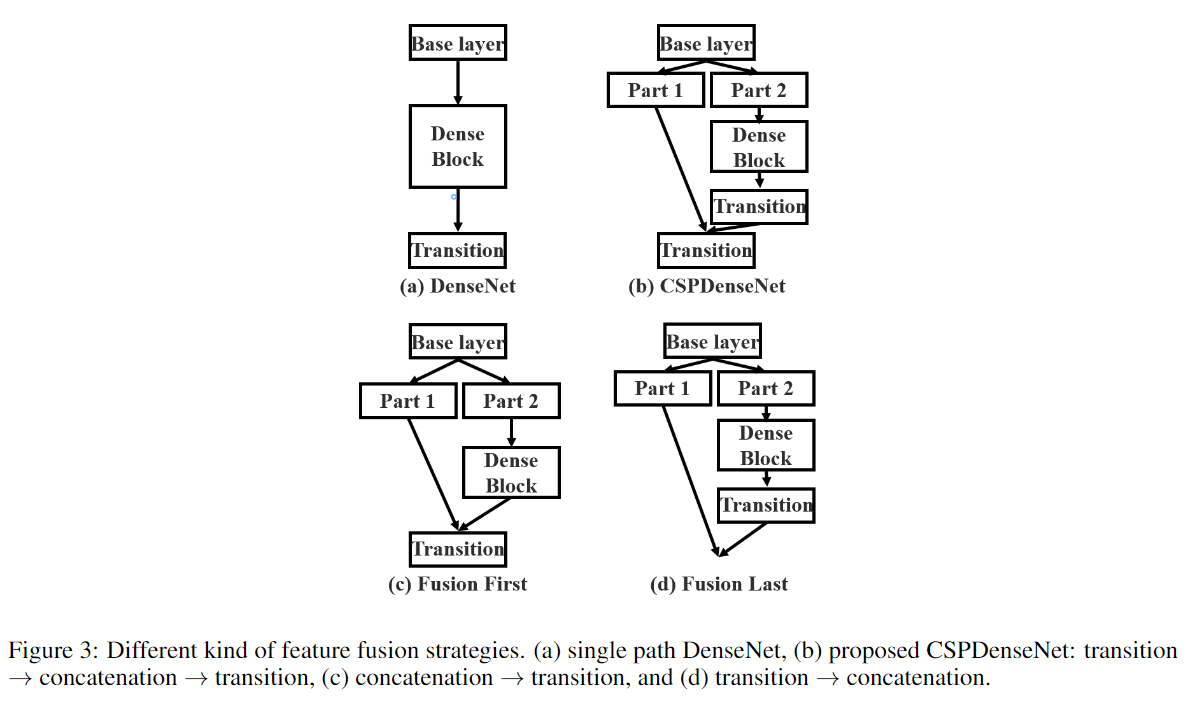
Fustion First的方式是对两个分支的feature map先进行concatenation操作,这样梯度信息可以被重用。
Fusion Last的方式是对Dense Block所在分支先进性transition操作,然后再进行concatenation, 梯度信息将被截断,因此不会重复使用梯度信息 。
- 使用Fusion First有助于降低计算代价,但是准确率有显著下降。
- 使用Fusion Last也是极大降低了计算代价,top-1 accuracy仅仅下降了0.1个百分点。
- 同时使用Fusion First和Fusion Last的CSP所采用的融合方式可以在降低计算代价的同时,提升准确率。
4.GhostNet
该paper的核心内容是Ghost模块(Ghost Module),可以用来替换任何经典CNN网络中的卷积操作,突出优势是轻量高效,实验证明使用了Ghost Module的MobileNetV3的效果,要比原始的MobileNetV3要好
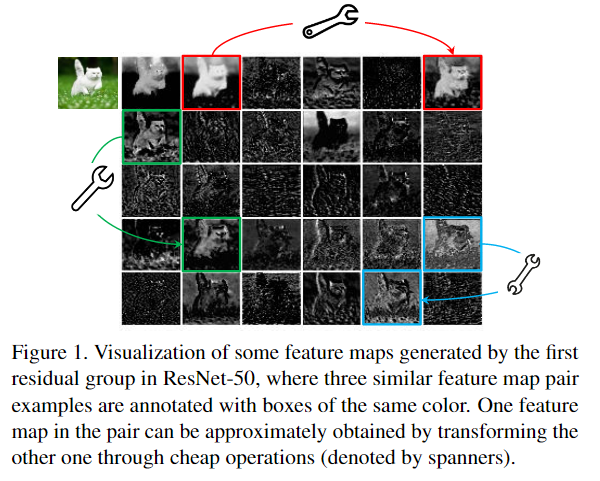
通过对比分析ResNet-50网络第一个残差组(Residual group)输出的特征图可视化结果,发现一些特征图高度相似(如Ghost一般,下图中的三组box内的图像对)。如果按照传统的思考方式,可能认为这些相似的特征图存在冗余,是多余信息,想办法避免产生这些高度相似的特征图。
但本文思路清奇,推测CNN的强大特征提取能力和这些相似的特征图(Ghost对)正相关,不去刻意的避免产生这种Ghost对,而是尝试利用简单的线性操作来获得更多的Ghost对。
ghostconv
-
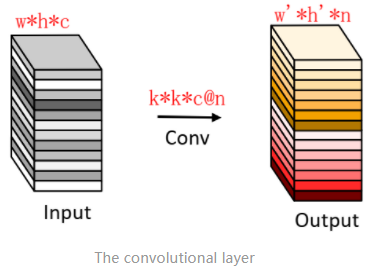
常规卷积
-
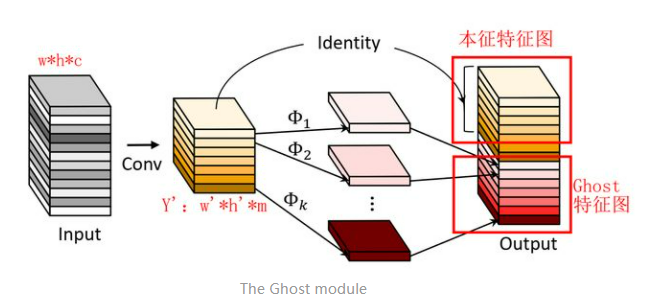
ghostconv:分为常规卷积、Ghost生成和特征图拼接三步
- 使用常规卷积生成本特征图\(Y_{m*w^{'}*h^{'}}\)
\[Y^{'} = X*f^{'} \]-
然后将\(Y^{'}\)的每一个特征图\(y^{'}\)生成ghost特征图\(y_{ij}\)
\[y_{ij}=\Phi_{ij}(y^{'}_i),\forall i=1,...,m,j=1,...,s \] -
最后将第一步得到的本特征图和ghost特征图拼接(identity)得到最终结果OutPut
- 对线性操作\(\Phi_{ij}\)的理解:论文中表示,可以探索仿射变换和小波变换等其他低成本的线性运算来构建Ghost模块。但是,卷积是当前硬件已经很好支持的高效运算,它可以涵盖许多广泛使用的线性运算,例如平滑、模糊等。 此外,线性运算\(\Phi_{ij}\)的滤波器的大小不一致将降低计算单元(例如CPU和GPU)的效率,所以论文中实验中让Ghost模块中的滤波器size取固定值,并利用Depthwise卷积实现 \(\Phi_{ij}\) ,以构建高效的深度神经网络。
所以说,论文中使用的线性操作并不是常见的旋转、平移、仿射变换、小波变换等,而是用的Depthwise卷积。个人猜测可能是传统的线性操作效果没有Depthwise效果好,毕竟CNN可以自动调整filter的权值。那么Ghost Module和深度分离卷积就很类似了,不同之处在于先进行PointwiseConv,后进行DepthwiseConv,另外增加了DepthwiseConv的数量,包括一个恒定映射。
小结:很明显,相比于直接用常规卷积,Ghost Module的计算量大幅度降低。个人认为从另一个角度可以看做是对卷积得到的特征图做了增强/增广,和数据增广似乎有点相似。
Ghost BottleNeck
Ghost BottleNeck整体架构和Residual Block非常相似,也可以直接认为是将Residual Block中的卷积操作用Ghost Module(GM)替换得到。
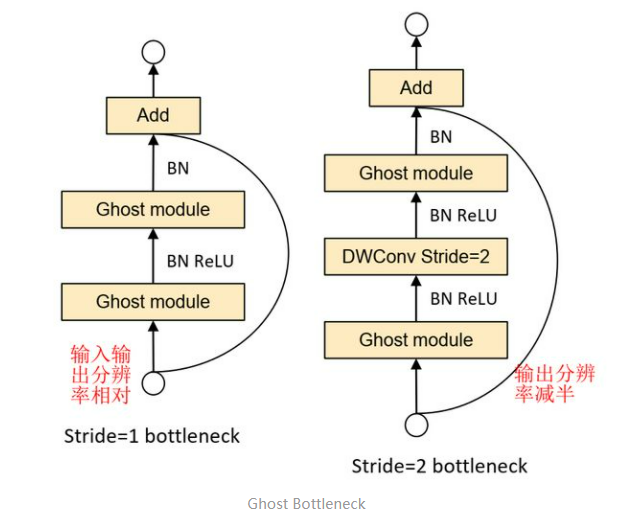
-
第一张图(左,stride=1)主干通路用两个Ghost Module(GM)串联组成,其中第一个GM扩大通道数,第二个GM将通道数降低到与输入通道数一致;跳跃连接通路与ResNet使用方法一样。这样一来,Ghost BottleNeck输入输出维度也一致了,可以和ResBlock一样,很方便地嵌入到其他CNN网络中。
-
第二张图(右,stride=2)和第一张图的不同之处在于,主干通路的两个GM之间加入了一个stride=2的Deepwise卷积,可以将特征图大小降为输入的1/2,同样跳跃连接通路也需要同样的降采样,以保证Add操作可以对齐。这个模块可以用来替换其他CNN中的降采样层(1/2)。
PS:Ghost BottleNeck的Add操作前主干通路不进行ReLU激活(参考了MobileNetV2);
实际应用中,为了进一步提高效率,GhostModule中的所有常规卷积都用pointwise卷积代替。
应用
- stride=2的boottleneck 替换网络中的降采样模块
- Ghost Conv替换 常规卷积
- Ghost BottleNeck替换res block / csp block
5.VoVNet
专注GPU计算、能耗高效的网络结构
An Energy and GPU-Computation Efficient Backbone Network for Real-Time Object Detection
ResNet是目标检测模型最常用的backbone,DenseNet其实比ResNet提取特征能力更强,而且其参数更少,计算量(FLOPs)也更少,用于目标检测虽然效果好,但是速度较慢,这主要是因为DenseNet中密集连接所导致的高内存访问成本和能耗。VoVNet就是为了解决DenseNet这一问题,基于VoVNet的目标检测模型性能超越基于DenseNet的模型,速度也更快,相比ResNet也是性能更好。
OSA模块
对于DenseNet来说,其核心模块就是Dense Block,如下图1a所示,这种密集连接会聚合前面所有的layer,这导致每个layer的输入channel数线性增长。受限于FLOPs和模型参数,每层layer的输出channel数是固定大小,这带来的问题就是输入和输出channel数不一致,如前面所述,此时的MAC不是最优的。另外,由于输入channel数较大,DenseNet采用了1x1卷积层先压缩特征,这个额外层的引入对GPU高效计算不利。所以,虽然DenseNet的FLOPs和模型参数都不大,但是推理却并不高效,当输入较大时往往需要更多的显存和推理时间。
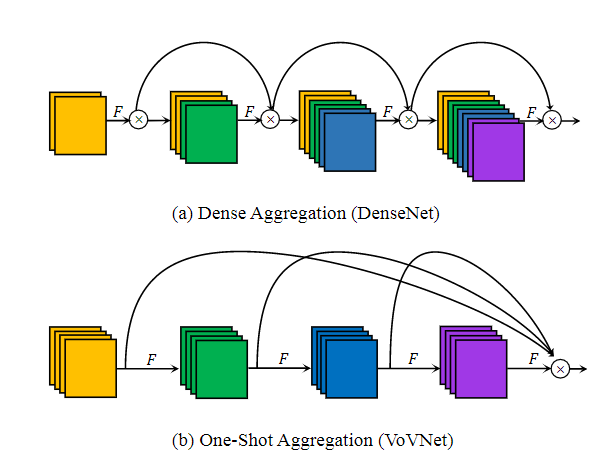
DenseNet的一大问题就是密集连接太重了,而且每个layer都会聚合前面层的特征,其实造成的是特征冗余,而且从模型weights的L1范数会发现中间层对最后的分类层贡献较少,这不难理解,因为后面的特征其实已经学习到了这些中间层的核心信息。这种信息冗余反而是可以优化的方向,据此这里提出了OSA(One-Shot Aggregation)模块,如图1b所示,简单来说,就是只在最后一次性聚合前面所有的layer。这一改动将会解决DenseNet前面所述的问题,因为每个layer的输入channel数是固定的,这里可以让输出channel数和输入一致而取得最小的MAC,而且也不再需要1x1卷积层来压缩特征,所以OSA模块是GPU计算高效的。那么OSA模块效果如何,论文中拿DenseNet-40来做对比,Dense Block层数是12,OSA模块也设计为12层,但是保持和Dense Block类似的参数大小和计算量,此时OSA模块的输出将更大。最终发现在CIFAR-10数据集上acc仅比DenseNet下降了1.2%。但是如果将OSA模块的层数降至5,而提升layer的通道数为43,会发现与DenseNet-40模型效果相当。这说明DenseNet中很多中间特征可能是冗余的。尽管OSA模块性能没有提升,但是MAC低且计算更高效,这对于目标检测非常重要,因为检测模型一般的输入都是较大的。
vovnet v1
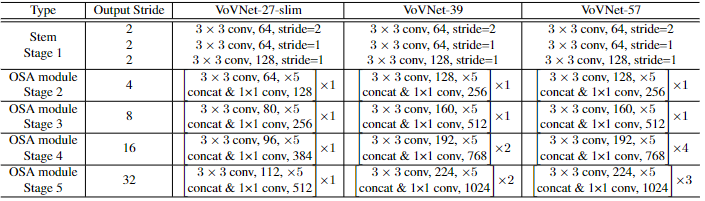
VoVNet由OSA模块构成,主要有三种不同的配置,如下表所示。VoVNet首先是一个由3个3x3卷积层构成的stem block,然后4个阶段的OSA模块,每个stage的最后会采用一个stride为2的3x3 max pooling层进行降采样,模型最终的output stride是32。与其他网络类似,每次降采样后都会提升特征的channel数。VoVNet-27-slim是一个轻量级模型,而VoVNet-39/57在stage4和stage5包含更多的OSA模块,所以模型更大。
vovnet v2
VoVNet只是继承了DenseNet的优点,但是可以走的更远,这就是CenerMask这篇论文所提出的改进版本VoVNetV2。简单来说,VoVNetV2引入了ResNet的残差连接和SENet的SE模块:
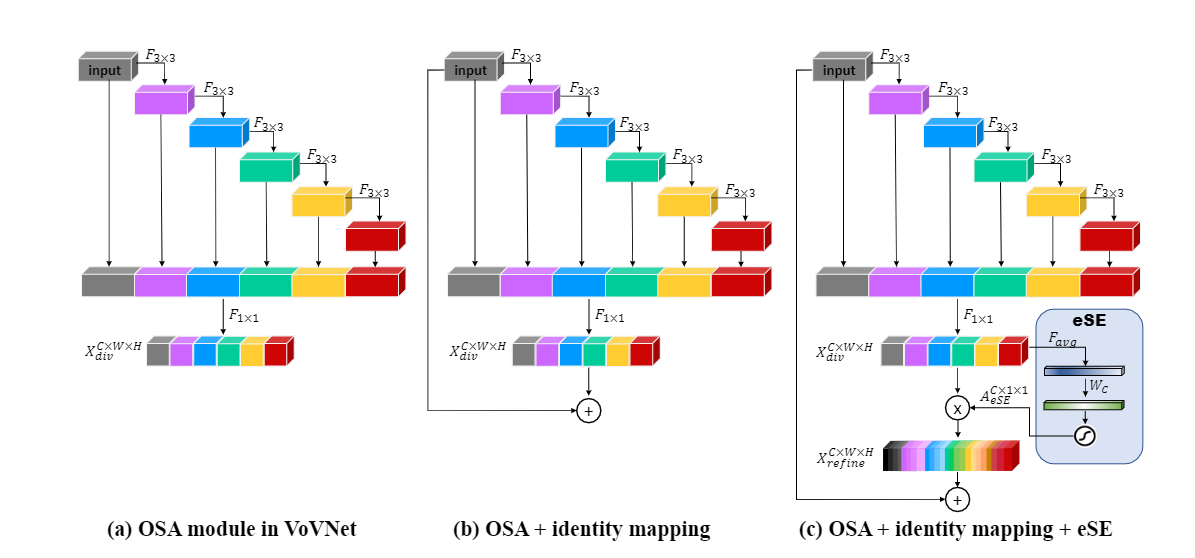
从图2b可以看到,改进的OSA模块直接将输入加到输出上,增加短路连接,使得VoVNet可以训练更深的网络,论文中是VoVNet-99。从图2c可以看到,改进的另外一个点是在最后的特征层上加上了sSE模块来进一步增强特征,原始的SE模块包含两个FC层,其中中间的FC层主要是为降维,这在一定程度上会造成信息丢失。而sSE模块是去掉了这个中间FC层。VoVNetV2相比VoVNet增加了少许的计算量,但是模型性能有提升。
6.PP-LCNet
针对Intel CPU做了优化
本文提出一种基于MKLDNN加速的轻量CPU模型PP-LCNet,它在多个任务上改善了轻量型模型的性能。本文列举了一些可以提升模型精度且保持延迟几乎不变的技术,基于这些改进,所提PP-LCNet可以凭借同等推理速度大幅超过其他已有网络。
结构
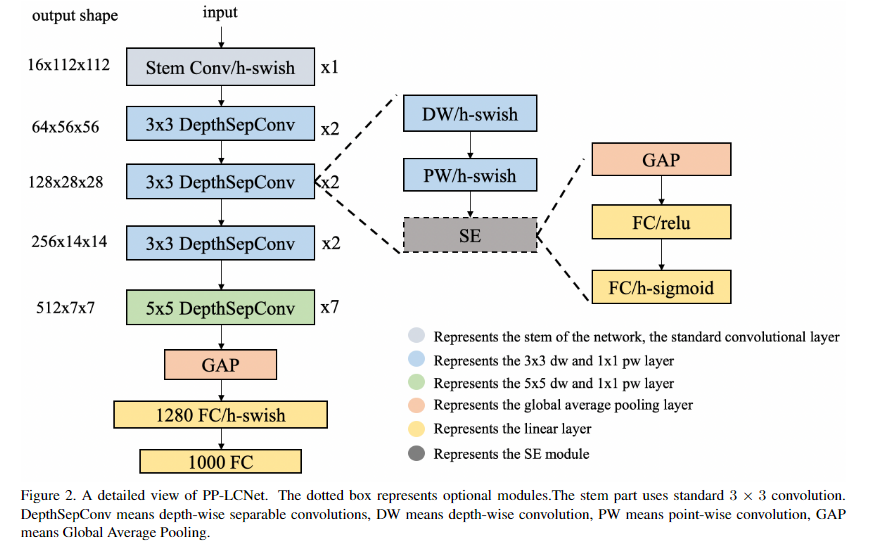
在这里,我们总结了一些可以提升模型性能且几乎不会造成推理延迟的方法。我们以MobileNetV1中的DepthSepConv作为基础模块,即没有跳过连接,也就没有concat或者add操作(这些操作不仅会降低模型的推理速度,而且在小模型上不会提升,模型精度);此外,由于这些操作已被Intel CPU的加速库MKLDNN进行深度优化,推理速度优于其他轻量型模块。我们通过堆叠模块构建了一个类似MobileNetV1的BaseNet,然后组合BaseNet与某些现有技术构建了一种更强力网络PP-LCNet,见下图(注:带SE模块的图示好像有点问题,跟code对不上。code中的实现方式为DW-SE-PW)。
激活函数
众所周知,激活函数的质量决定了模型的性能。激活函数从早期的Sigmoid转换到了ReLU后,模型的性能得到了显著提升。近年来,深度学习领域也提出各种更优秀的激活函数,而Swish系列则是其中的佼佼者,尤以H-Swish为最优。
本文同样采用H-Swish替换BaseNet中的ReLU,性能大幅提升,而推理速度几乎不变。
SE
自提出以来,SE就被广泛应用到不用网络架构中,比如MobileNetV3。然而,在Intel CPU端,SE模块会提升模型的推理耗时,故我们不能对整个网络使用它。
事实上,我们做了大量的实验并发现:当把SE置于模型的尾部时,它具有更好作用 。因此,我们仅将SE模块添加到接近网络尾部的模块 ,这种处理方式具有更好的精度-速度平衡。注:SE模块采用了与MobileNetV3相似的机制:SE中的两个激活函数分别为SE和H-Sigmoid。
Larger convolution kernels
卷积核的尺寸通常会影响模型最终的性能,MixNet的作者分析了不同尺寸卷积对于网络性能的影响并提出了已中混合不同尺寸的卷积核,然而这种操作会降低模型的推理速度。我们尝试仅使用一个尺寸的卷积,并在低延迟&高精度情形下使用大尺度卷积核。
我们实验发现:类似SE模块的位置,在网络的尾部采用\(5×5\)卷积核可以取得全部替换相近的效果。因此,我们仅在网络的尾部采用 \(5×5\)卷积 。
Larger dimensional 1x1conv layer after GAP
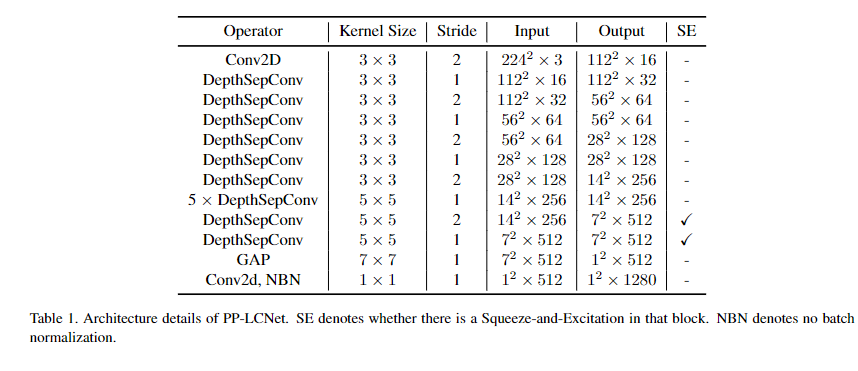
在本文所提PP-LCNet中,GAP后的输出维度比较小,直接添加分类层会有相对低的性能。为提升模型的强拟合能能力,我们在GAP后添加了一个1280维的\(1*1\)卷积,它仅需很小的推理延迟即可取得更强的性能。
经验参数
1.se的使用
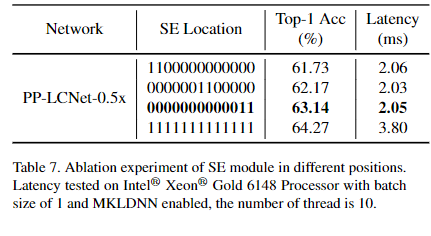
可以看到:SE在模型的尾部时具有更重要的影响。为更好平衡推理-精度,PP-LCNet仅在尾部两个模块添加SE模块。
2.卷积核尺寸

不同位置大尺寸卷积对于性能的影响,可以看到:在模型的尾部使用5×5卷积更具竞争力。因此,我们选用了表中第三行的配置
3.对比试验
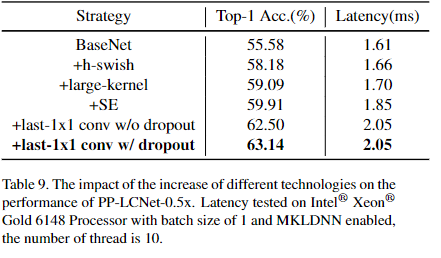
- H-Swish与大卷积核可以提升模型性能且几乎不会造成推理耗时提升;
- 添加少量的SE更进一步提升模型性能;
- GAP后采用更大FC层可以极大提升模型性能;
- dropout技术可以进一步提升了模型的精度。
3.重参数化
1.RepVGG
RepVGG,用结构重参数化(structural re-parameterization)实现VGG式单路极简架构,一路3x3卷到底,在速度和性能上达到SOTA水平,在ImageNet上超过80%正确率。
下面用一句话介绍RepVGG模型的基本架构:将20多层3x3卷积堆起来,分成5个stage,每个stage的第一层是stride=2的降采样,每个卷积层用ReLU作为激活函数。
再用一句话介绍RepVGG模型的详细结构:RepVGG-A的5个stage分别有[1, 2, 4, 14, 1]层,RepVGG-B的5个stage分别有[1, 4, 6, 16, 1]层,宽度是[64, 128, 256, 512]的若干倍。这里的倍数是随意指定的诸如1.5,2.5这样的“工整”的数字,没有经过细调。
VGG式结构的优势:
- 3x3卷积非常快。在GPU上,3x3卷积的计算密度(理论运算量除以所用时间)可达1x1和5x5卷积的四倍。
- 单路架构非常快,因为并行度高。同样的计算量,“大而整”的运算效率远超“小而碎”的运算。
- 单路架构省内存。例如,ResNet的shortcut虽然不占计算量,却增加了一倍的显存占用。
- 单路架构灵活性更好,容易改变各层的宽度(如剪枝)。
- RepVGG主体部分只有一种算子:3x3卷积接ReLU。在设计专用芯片时,给定芯片尺寸或造价,我们可以集成海量的3x3卷积-ReLU计算单元来达到很高的效率。别忘了,单路架构省内存的特性也可以帮我们少做存储单元。
结构重参数化:
近年来,VGG式模型鲜有关注的原因是其性能较差,ResNet性能好的一种解释是ResNet的分支结构(shortcut)产生了一个大量子模型的隐式ensemble(因为每遇到一次分支,总的路径就变成两倍),单路架构显然不具备这种特点。
既然多分支架构是对训练有益的,而我们想要部署的模型是单路架构,我们提出解耦训练时和推理时架构。我们通常使用模型的方式是:
- 训练一个模型
- 部署这个模型
但在这里,我们提出一个新的做法:
-
训练一个多分支模型
-
将多分支模型等价转换为单路模型
-
部署单路模型
这样就可以同时利用多分支模型训练时的优势(性能高)和单路模型推理时的好处(速度快、省内存)。这里的关键显然在于这种多分支模型的构造形式和转换的方式。
我们的实现方式是在训练时,为每一个3x3卷积层添加平行的1x1卷积分支和恒等映射分支,构成一个RepVGG Block。这种设计是借鉴ResNet的做法,区别在于ResNet是每隔两层或三层加一分支,而我们是每层都加。
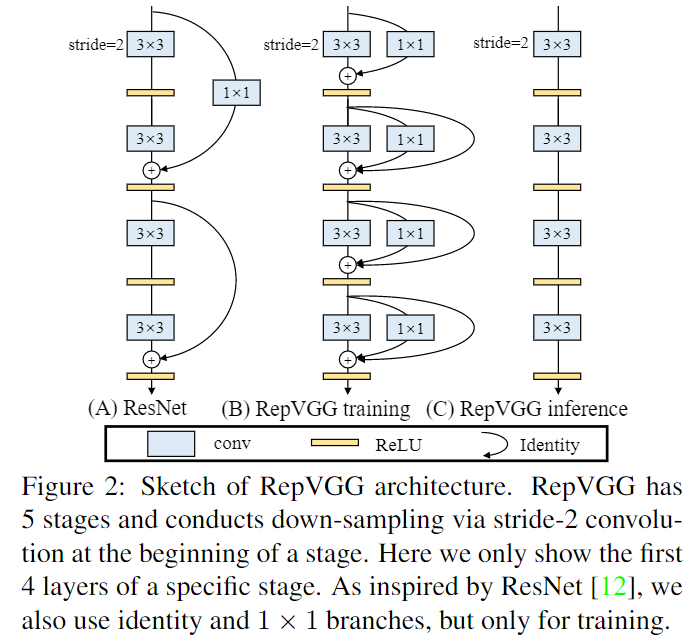
训练完成后,我们对模型做等价转换,得到部署模型。这一转换也非常简单,因为1x1卷积是一个特殊(卷积核中有很多0)的3x3卷积,而恒等映射是一个特殊(以单位矩阵为卷积核)的1x1卷积!根据卷积的线性(具体来说是可加性),每个RepVGG Block的三个分支可以合并为一个3x3卷积。
假设输入和输出通道都是2,故3x3卷积的参数是4个3x3矩阵,1x1卷积的参数是一个2x2矩阵。注意三个分支都有BN(batch normalization)层,其参数包括累积得到的均值及标准差和学得的缩放因子及bias。这并不会妨碍转换的可行性,因为推理时的卷积层和其后的BN层可以等价转换为一个带bias的卷积层(也就是通常所谓的“吸BN”)。
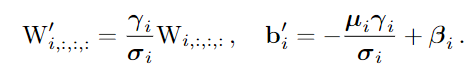
对三分支分别“吸BN”之后(注意恒等映射可以看成一个“卷积层”,其参数是一个2x2单位矩阵!),将得到的1x1卷积核用0给pad成3x3。最后,三分支得到的卷积核和bias分别相加即可。这样,每个RepVGG Block转换前后的输出完全相同,因而训练好的模型可以等价转换为只有3x3卷积的单路模型。
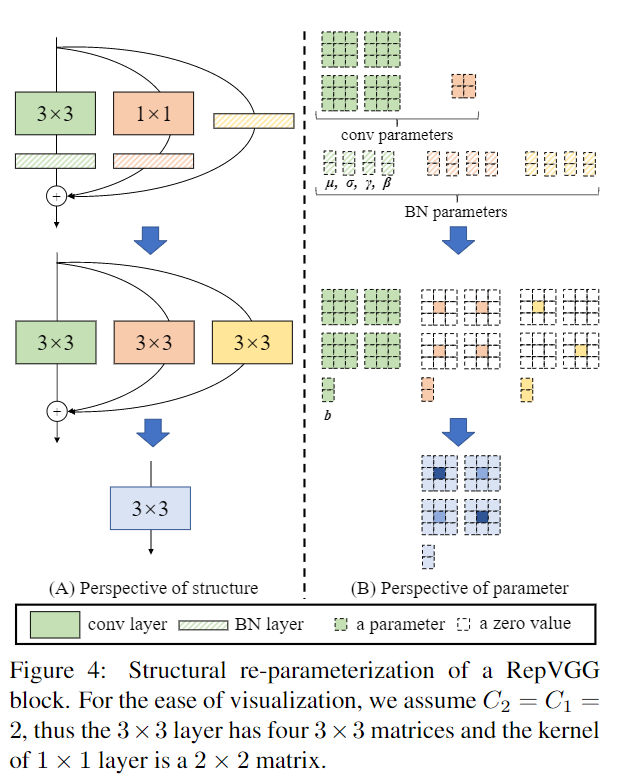
从这一转换过程中,我们看到了“结构重参数化”的实质:训练时的结构对应一组参数,推理时我们想要的结构对应另一组参数;只要能把前者的参数等价转换为后者,就可以将前者的结构等价转换为后者。
2. RepOpt
Re-parameterizing Your Optimizers rather than Architectures
该文基于repvgg进行改进,主要创新如下
- RepVGG加入了结构先验(如1x1,identity分支),并使用常规优化器训练。而RepOptVGG则是将这种先验知识加入到优化器实现中
- 尽管RepVGG在推理阶段可以把各分支融合,成为一个直筒模型。但是其训练过程中有着多条分支,需要更多显存和训练时间。而RepOptVGG可是从训练过程中就是一个VGG结构
- RepOpt并非结构重参数化,作者通过定制优化器,实现了结构重参数化和梯度重参数化的等价变换,这种变换是通用的,可以拓展到更多模型
3. MobileOne
MobileOne: An Improved One millisecond Mobile Backbone
MobileOne是苹果针对CNN结构推出的适用于移动端的超轻量级骨干网络。
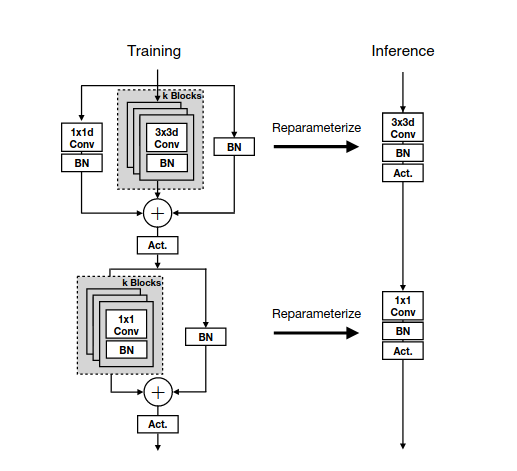
重参数化
基于repvgg的内容, 我们知道重参数化有以下方法:
- 一个conv和一个bn可以合并为一个conv;
- 对于多个超参数(如核大小、步长、padding等)相同的conv,如果它们的输出是直接相加的, 那么这些conv可以合并成一个新的conv
如上图所示左侧部分构成了训练时mobileone的基础block, 由两部分组成, 上面基于深度卷积, 下面基于点卷积。对于深度卷积而言, 我们可以首先把3x3卷积和bn合并成一个3x3卷积, 于是就有了k个卷积核, 根据上面所说的重参数化方法二又可以将这k个卷积核合并, 此外类似于repvgg的重参数化方法合并1x1卷积分支和恒等映射分支得到了右侧部分推理时的结构。点卷积的重参数化方法类似, 不再赘述。