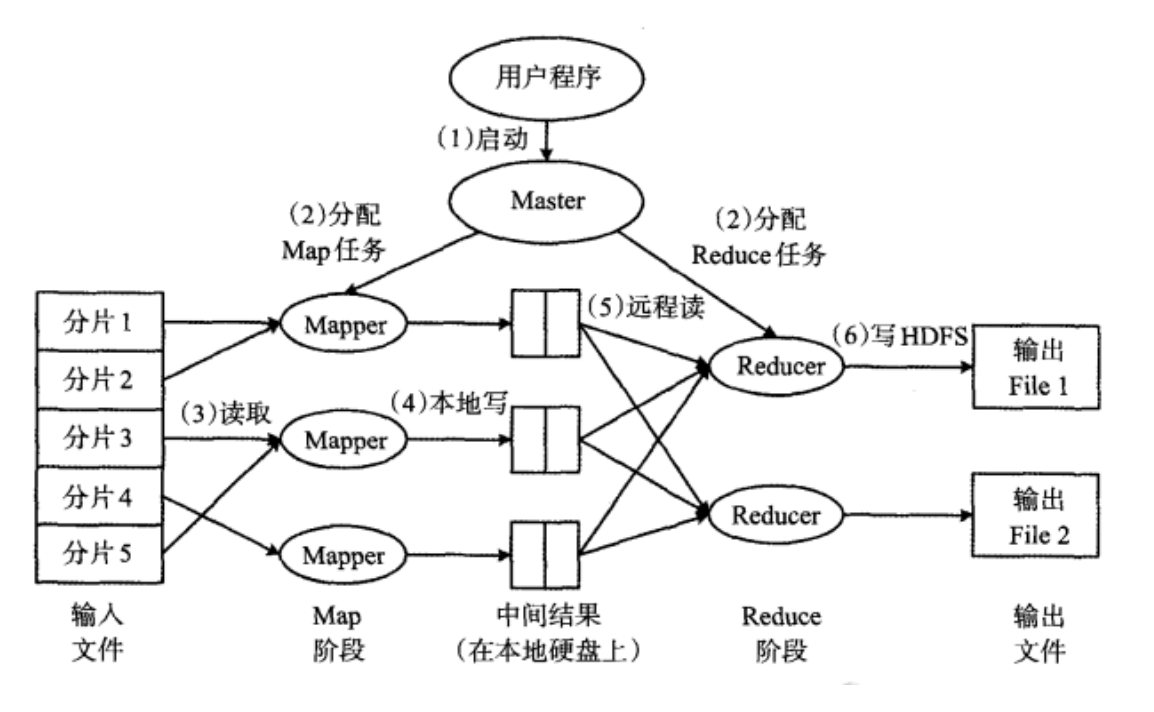
1. MR 性能优化概述
Hadoop MapReduce 源自于 Google 的 MapReduce 论文,是 Google MapReduce 开源版本实现。MapReduce 是一个分布式应用框架。旨在通过将任务划分来并行处理大量数据,解决海量数据计算问题。
1.1 优缺点及应用场景
a. 优点
(1)易于编程
它简单的实现一些接口,就可以完成一个分布式程序,这个程序可以分布到大量的廉价的 PC 机器上运行。也就是说你写一个分布式程序,跟写一个简单的串行程序是一模一样的,用户专注于业务问题即可。就是因为这个特性使的 MapReduce 编程变得非常流行。
(2)良好的扩展性
项目中当你的计算资源得不到满足的时候,你可以通过简单的通过增加机器来扩展它的计算能力。
(3)高容错性
MapReduce 的设计初衷就是使程序能够部署在廉价的 PC 机器上,这就要求它具有很高的容错性。Hadoop 会自动通过 YARN 完成机器级别的故障转移。比如一个机器挂了,它可以把上面的计算任务转移到另一个节点上运行,不至于这个任务运行失败,而且这个过程不需要人工参与,而完全是由 Hadoop 内部完成的。
(4)适合 PB 级以上海量数据的离线处理
理论上只要机器硬件足够多,可以处理无穷大的数据量。Hadoop 设计之初思想就是基于廉价 PC 机器构建大型分布式集群。
b. 缺点
MapReduce 虽然有很多的优势,但是也有它不擅长的。这里的“不擅长”,不代表不能做,而是在有些场景下实现的效果差,并不适合用 MapReduce 来处理,主要表现在以下结果方面:
(1) 处理速度很慢,不适合时效性要求较高的场景
MapReduce 主要处理的数据来自于文件系统,所以无法像 Oracle 或 MySQL 那样在毫米或秒级内返回结果,如果需要大数据量的毫秒级响应,可以考虑结合实时存储系统来实现,利用 HBase、Kudu 等。
(2) 数据存储主要使用静态数据系统,不适合实时数据流
流计算的输入数据是动态的,而 MapReduce 主要的输入来自于 HDFS 等文件系统,数据是静态的,不能动态变化,这是因为 MapReduce 自身的设计特点决定了数据源必须是静态的。如果需要处理流式数据可以用 Storm、Spark Steaming、Flink 等流计算框架。
(3) 只有 Map 和 Reduce 阶段,缺乏 DGA(有向无环图)计算
MapReduce 处理数据过程中,如果需要经过多个步骤来实现,一个 MapReduce 就无法完成,如果通过多个 MapReduce 来实现,那必须将前一个 MapReduce 的结果写入磁盘,导致大量的 IO 的消耗导致 MapReduce 性能较差。
综合以上问题,MapReduce 在解决离线分布式计算的过程中,主要考虑如何提升性能,加快分布式计算过程。
c. 应用场景
擅长场景:
- TopN 问题:从海量查询中统计出现频率最高的前 N 个
- Web日志访问频率统计:统计 url、用户、搜索出现的频率统计
- 数据倒排索引:基于数据构建倒排索引,实现基于复杂条件词的数据检索
不擅长应用:
- 迭代计算:从某个值开始,不断地由上一步的结果计算(或推断)出下一步的结果
- 机器学习:分类、聚类、关联、预测
- 连接计算:join 关联
1.2 优化需求及方向
基于 MapReduce 所存在的性能差的问题,在实际工作中可以通过优化方案来提高 MapReduce 整体性能,进而节约生产成本。
- 从文件角度考虑,通过更改二进制文件、列式存储、压缩来降低磁盘及网络 IO,进而提高程序性能。
- 通过控制 MapReduce 运行过程中的资源属性,合理分配资源,提高资源利用率,提高程序运行效率。
1.3 MR 跑的慢原因
MapReduce 程序效率的瓶颈在于两点:
(1)计算机性能
CPU、内存、磁盘、网络
(2)I/O 操作优化
- 数据倾斜
- Map 运行时间太长,导致 Reduce 等待过久
- 小文件过多
2. 文件类型优化
(1) 针对 HDFS 最初是为访问大文件而开发的,所以会出现对大量小文件的存储效率不高问题,MapReduce 在读取小文件进行处理时,也存在资源浪费导致计算效率不高的问题。采用 Sequence File 和 MapFile 设计一个 HDFS 中合并存储小文件的方案,该方案的主要思想是将小文件序列化存入一个 Sequence File/MapFile 容器,合并成大文件并建立相应的索引文件,有效降低文件数目和提高访问效率。通过和现有的 Hadoop Archives(HAR files)文件归档解决小文件问题的方案对比,实验结果表明,基于 Sequence File 或 MapFile 的存储小文件方案可以更为有效的提高小文件存储性能和减少 HDFS 文件系统的节点内存消耗。
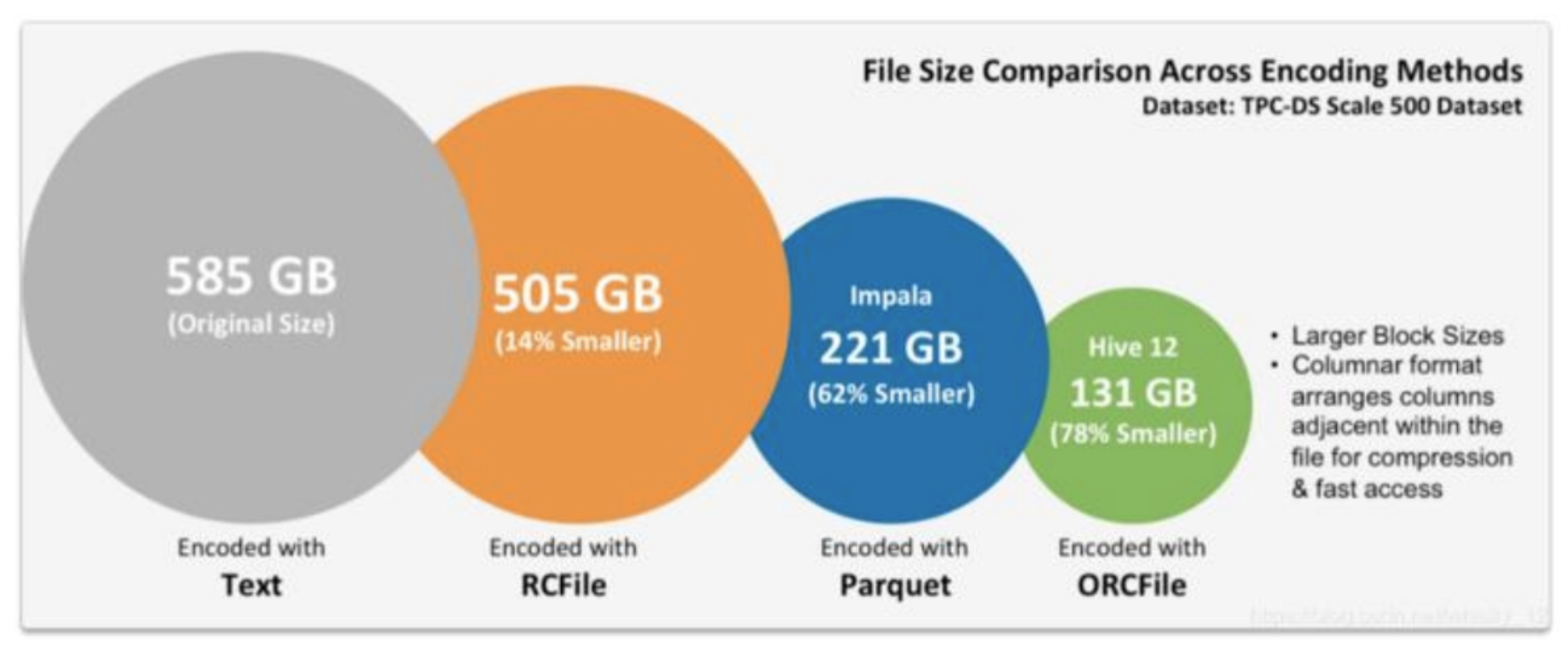
(2) 针对普通按行存储文本文件,MapReduce 在处理实现聚合、过滤等功能时,性能相对较差,针对行式存储的数据处理性能差的问题,可以选择使用列式存储的方案来实现数据聚合处理,降低数据传输及读写的 IO,提高整体 MapReduce 计算处理的性能。
行式存储、列式存储:
- 行式存储(Row-Based):同一行数据存储在一起。
- 行存储的写入是一次性完成,消耗的时间比列存储少,并且能够保证数据的完整性;
- 缺点是数据读取过程中会产生冗余数据,如果只有少量数据,此影响可以忽略,数量大可能会影响到数据的处理效率。
- 行适合插入、不适合查询。
- 列式存储(Column-Based):同一列数据存储在一起。
- 列存储在写入效率、保证数据完整性上都不如行存储,它的优势是在读取过程,不会产生冗余数据,这对数据完整性要求不高的大数据处理领域,比如互联网,犹为重要。
- 列适合查询,不适合插入。
2.1 Sequence File
a. 概述
Sequence File 是 Hadoop 提供的一种二进制文件存储格式。一条数据称之为 record(记录),底层直接以 <key, value> 键值对形式序列化到文件中。
Sequence File 文件也可以作为 MapReduce 作业的输入和输出,Hive 和 Spark 也支持这种格式。
它有如下几个优点:
- 以二进制的 KV 形式存储数据,与底层交互更加友好,性能更快,所以可以在 HDFS 里存储图像或者更加复杂的结构作为 KV 对。
- Sequence File 支持压缩和分片。当你压缩为一个 Sequence File 时,并不是将整个文件压缩成一个单独的单元,而是压缩文件里的 record 或 block of records(块)。因此 Sequence File 是能够支持分片的,即使使用的压缩方式如 Snappy、Lz4、Gzip 不支持分片,也可以利用 Sequence File 来实现分片。
- Sequence File 也可以用于存储多个小文件。由于 Hadoop 本身就是用来处理大型文件的,小文件是不适合的,所以用一个 Sequence File 来存储很多小文件就可以提高处理效率,也能节省 Namenode 内存,因为 Namenode 只需一个 Sequence File 的 metadata,而不是为每个小文件创建单独的 metadata。
- 由于数据是以 Sequence File 形式存储,所以中间输出文件即 map 输出也会用 Sequence File 来存储,可以提高整体的 IO 开销性能。
b. 格式
根据压缩类型,有 3 种不同的 Sequence File 格式:未压缩格式、record 压缩格式、block 压缩格式。
Sequence File 由一个 Header 和一个或多个 Record 组成。以上 3 种格式均使用相同的 Header 结构,如下所示:
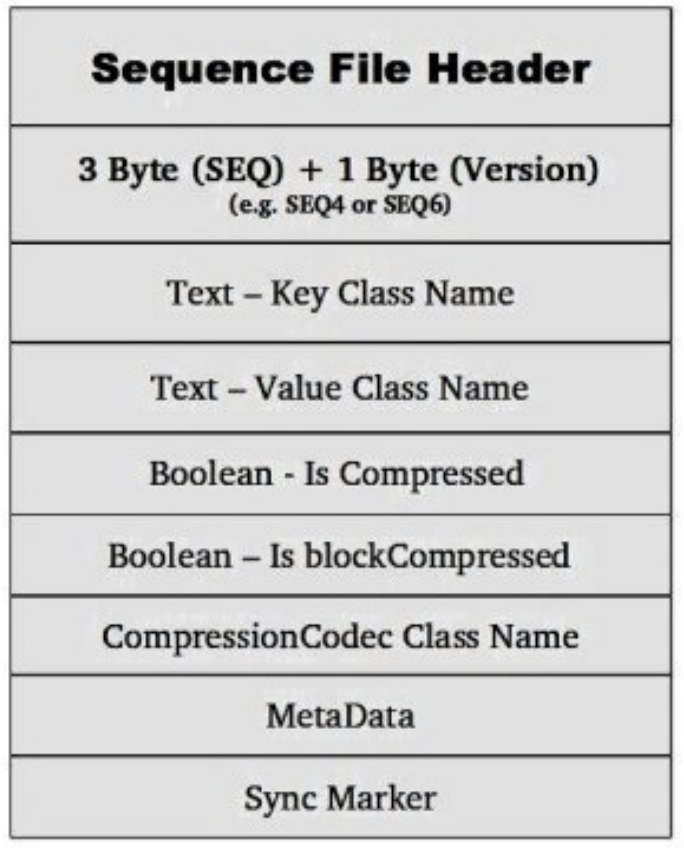
前 3 个字节为 SEQ,表示该文件是序列文件,后跟一个字节表示实际版本号(例如 SEQ4 或 SEQ6)。Header 中其他也包括 Key/Value Class 名字、 压缩细节、Metadata、Sync Marker(同步标记,用于可以读取任意位置的数据)。
(1)未压缩格式
未压缩的 Sequence File 文件由 Header、Record、Sync 三个部分组成。
其中 Record 包含了4个部分:record length(记录长度)、key length(键长)、key、value。
每隔几个 Record(100 字节左右)就有一个 Sync(同步标记)。
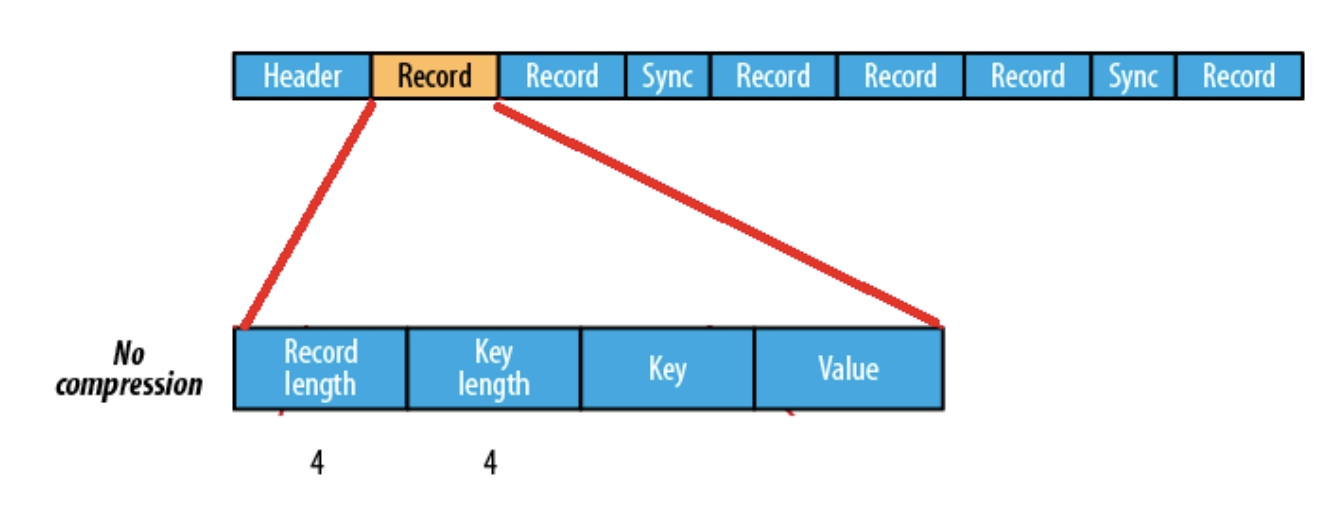
(2)基于 Record 压缩格式
基于 Record 压缩的 Sequence File 文件由 Header、Record、Sync 三个部分组成。
其中 Record 包含了4个部分:record length(记录长度)、key length(键长)、key、compressed value(被压缩的值)。
每隔几个 Record(100字节左右)就有一个同步标记。
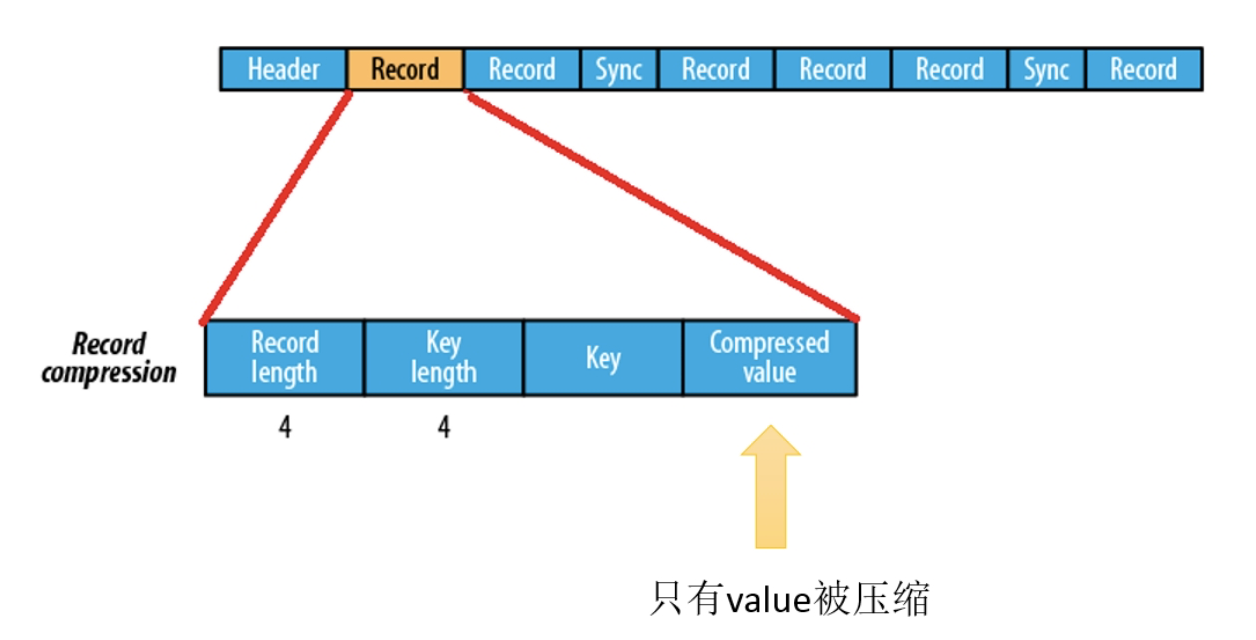
(3)基于 Block 压缩格式
基于 Block 压缩的 Sequence File 文件由 Header、Record、Sync 三个部分组成。
Block 指的是 Record Block,可以理解为多个 Record 记录组成的块。注意,这个 Block 和 HDFS 中分块存储的 Block(128M)是不同的概念。
Block 中包括:record 条数、压缩的 key 长度、压缩的 keys、压缩的 value 长度、压缩的 values。
每隔一个 Block 就有一个同步标记。
Block 压缩比 Record 压缩提供更好的压缩率。使用 Sequence File 时,通常首选「块压缩」。
【小结】
- Sequence File 文件是 Hadoop 用来存储二进制形式的 [Key,Value] 而设计的一种平面文件(Flat File)。
- 可以把 Sequence File 当做是一个容器,把所有的文件打包到 Sequence File 中可以高效的对小文件进行存储和处理。
- Sequence File 文件并不按照其存储的 Key 进行排序存储,Sequence File 的内部类 Writer 提供了 append 功能。
- Sequence File 中的 Key 和 Value 可以是任意类型 Writable 或是自定义 Writable。
- 存储结构上,Sequence File 主要由一个 Header 后跟多条 Record 组成,Header 主要包含了 Key/Value classname、存储压缩算法、用户自定义元数据等信息,此外,还包含了一些同步标识,用于快速定位到记录的边界。每条 Record 以键值对的方式进行存储,用来表示它的字符数组可以一次解析成:记录的长度、Key 的长度、Key 值和 Value 值,并且 Value 值的结构取决于该记录是否被压缩。
- 在 Record 中,又分为是否压缩格式。当没有被压缩时,key 与 value 使用 Serialization 序列化写入 Sequence File。当选择压缩格式时,Record 的压缩格式与没有压缩其实不尽相同,除了 value 的 bytes 被压缩,key 是不被压缩的。
- 在 Block 中,它使所有的信息进行压缩,压缩的最小大小由配置文件中
io.seqfile.compress.blocksize配置项决定。
c. 示例
(1)读取文本文件,转换为 Sequence File 文件。
public int run(String[] args) throws Exception {
Configuration conf = getConf();
// 实例化作业
Job job = Job.getInstance(conf, "MrWriteToSequenceFile");
// 设置作业的主程序
job.setJarByClass(this.getClass());
// ===> 设置作业的输入为TextInputFormat(普通文本) <===
job.setInputFormatClass(TextInputFormat.class);
// 设置作业的输入路径
FileInputFormat.addInputPath(job, new Path("datas/lianjia/secondhouse.csv"));
// 设置Map端的实现类
job.setMapperClass(WriteSeqFileAppMapper.class);
// 设置Map端输入的Key类型
job.setMapOutputKeyClass(NullWritable.class);
// 设置Map端输入的Value类型
job.setMapOutputValueClass(Text.class);
// ======= 设置作业的输出为SequenceFileOutputFormat =======
job.setOutputFormatClass(SequenceFileOutputFormat.class);
// ======================================================
// 使用SequenceFile的块级别压缩
SequenceFileOutputFormat.setOutputCompressionType(job, SequenceFile.CompressionType.BLOCK);
// 设置Reduce端的实现类
job.setReducerClass(WriteSeqFileAppReducer.class);
// 设置Reduce端输出的Key类型
job.setOutputKeyClass(NullWritable.class);
// 设置Reduce端输出的Value类型
job.setOutputValueClass(Text.class);
// 从参数中获取输出路径
Path outputDir = new Path("datas/output/mr/seq1");
// 如果输出路径已存在则删除
outputDir.getFileSystem(conf).delete(outputDir, true);
// 设置作业的输出路径
FileOutputFormat.setOutputPath(job, outputDir);
// 提交作业并等待执行完成
return job.waitForCompletion(true) ? 0 : 1;
}
public static void main(String[] args) throws Exception {
// 用于管理当前程序的所有配置
Configuration conf = new Configuration();
int status = ToolRunner.run(conf, new MrWriteToSequenceFile(), args);
System.exit(status);
}
(2)读取 Sequence File 文件,转换为普通文本文件。
public int run(String[] args) throws Exception {
// 实例化作业
Job job = Job.getInstance(this.getConf(), "MrReadFromSequenceFile");
// 设置作业的主程序
job.setJarByClass(this.getClass());
// ======= 设置作业的输入为SequenceFileInputFormat ========
job.setInputFormatClass(SequenceFileInputFormat.class);
// ======================================================
// 设置作业的输入路径
SequenceFileInputFormat.addInputPath(job, new Path("datas/output/mr/seq1"));
// 设置Map端的实现类
job.setMapperClass(WriteSeqFileAppMapper.class);
// 设置Map端输入的Key类型
job.setMapOutputKeyClass(NullWritable.class);
// 设置Map端输入的Value类型
job.setMapOutputValueClass(Text.class);
// ===> 设置作业的输出为TextOutputFormat
job.setOutputFormatClass(TextOutputFormat.class);
// 设置Reduce端的实现类
job.setReducerClass(WriteSeqFileAppReducer.class);
// 设置Reduce端输出的Key类型
job.setOutputKeyClass(NullWritable.class);
// 设置Reduce端输出的Value类型
job.setOutputValueClass(Text.class);
// 从参数中获取输出路径
Path outputDir = new Path("datas/output/mr/seq2");
// 如果输出路径已存在则删除
outputDir.getFileSystem(this.getConf()).delete(outputDir, true);
// 设置作业的输出路径
TextOutputFormat.setOutputPath(job, outputDir);
// 提交作业并等待执行完成
return job.waitForCompletion(true) ? 0 : 1;
}
public static void main(String[] args) throws Exception {
// 用于管理当前程序的所有配置
Configuration conf = new Configuration();
int status = ToolRunner.run(conf, new MrReadFromSequenceFile(), args);
System.exit(status);
}
(3)使用 Sequence File 合并小文件
MapReduce 本身不擅长处理小文件的业务场景,原因在于逻辑规划生成切片的时候,不管文件多小本身都是一个切片,一个切片对应一个 maptask 来处理,效率低下。
假设 HDFS 某个目录下有很多个小文件,这些文件虽然磁盘占用空间不大,但是内存空间占据却不少(元数据存储在内存中)。可以编写一个程序将所有的小文件写入到一个 Sequence File 中,即将文件名作为 key,文件内容作为 value 序列化到 Sequence File 大文件中。
private Configuration configuration = new Configuration();
/**
* 把smallFilePaths的小文件遍历读取,然后放入合并的SequenceFile容器中。
*/
public void mergeFile(String[] smallFilePaths, String targetFile) throws Exception {
SequenceFile.Writer.Option bigFile = SequenceFile.Writer.file(new Path(targetFile));
SequenceFile.Writer.Option keyClass = SequenceFile.Writer.keyClass(Text.class);
SequenceFile.Writer.Option valueClass = SequenceFile.Writer.valueClass(BytesWritable.class);
// 构造 Writer
SequenceFile.Writer writer = SequenceFile.createWriter(configuration, bigFile, keyClass, valueClass);
// 遍历读取小文件,逐个写入 SequenceFile
Text key = new Text();
for (String path : smallFilePaths) {
File file = new File(path);
long fileSize = file.length();
byte[] fileContent = new byte[(int) fileSize];
FileInputStream inputStream = new FileInputStream(file);
// 把文件的二进制流加载到 fileContent 字节数组中去
inputStream.read(fileContent, 0, (int) fileSize);
System.out.println("=> mergeFile: " + path + ", md5: " + DigestUtils.md5Hex(fileContent));
key.set(path);
// 把文件路径作为key,文件内容做为value,放入到SequenceFile中
writer.append(key, new BytesWritable(fileContent));
}
writer.hflush();
writer.close();
}
/**
* 读取大文件中的小文件
*/
public void readMergedFile(String bigFilePath) throws Exception {
SequenceFile.Reader.Option file = SequenceFile.Reader.file(new Path(bigFilePath));
SequenceFile.Reader reader = new SequenceFile.Reader(configuration, file);
Text key = new Text();
BytesWritable value = new BytesWritable();
while (reader.next(key, value)) {
byte[] bytes = value.copyBytes();
String md5 = DigestUtils.md5Hex(bytes);
String content = new String(bytes, Charset.forName("GBK"));
System.out.println("=> readFile: " + key + ", md5: " + md5 + ", content: " + content);
}
}
2.2 Map File
a. 概述
可以理解 Map File 是排序后的 Sequence File(即有序二进制文件),通过观察其结构可以看到 Map File 由两部分组成分别是 data 和 index。data 即存储数据的文件,index 作为文件的数据索引,主要记录了每个 Record 的 Key 值,以及该 Record 在文件中的偏移位置。
优点是在 Map File 被访问的时候,索引文件会被加载到内存,通过索引映射关系可以迅速定位到指定 Record 所在文件位置,因此,相对 Sequence File 而言,Map File 的检索效率是最高的。缺点是会消耗一部分内存来存储 index 数据。
b. 格式
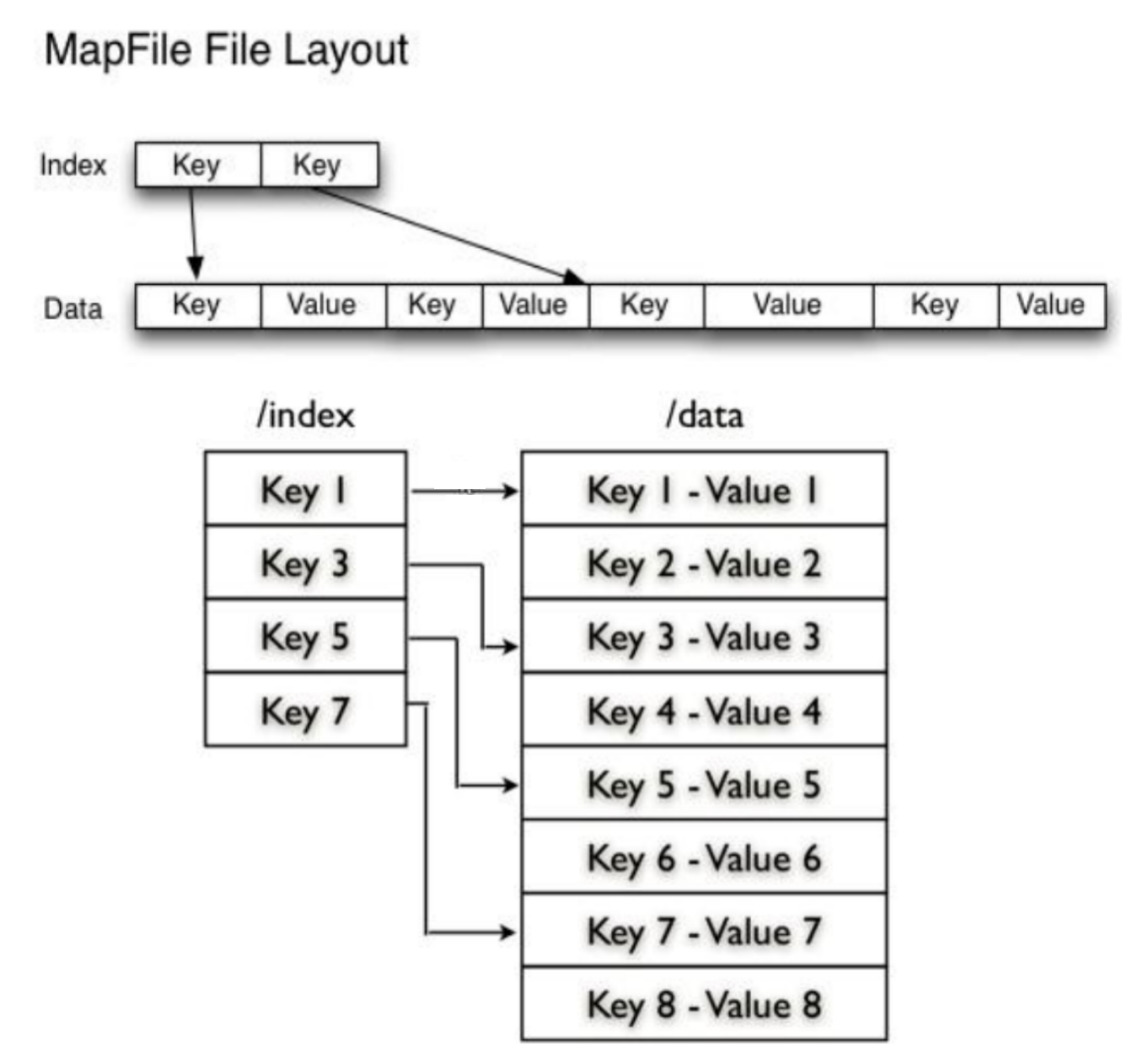
需要注意的是,Map File 并不不会把所有的 Record 都记录到 index 中去,默认情况下每隔 128 条 Record 会存储一个索引映射。当然,记录间隔可认为修改,通过 MapFile.Writer 的 setIndexInterval() 或修改 io.map.index.interval 属性。
并且与 Sequence File 不同的是,Map File 的 KeyClass 一定要实现 WritableComparable 接口,即 Key 值是可比较的,最终实现基于 Key 的有序。
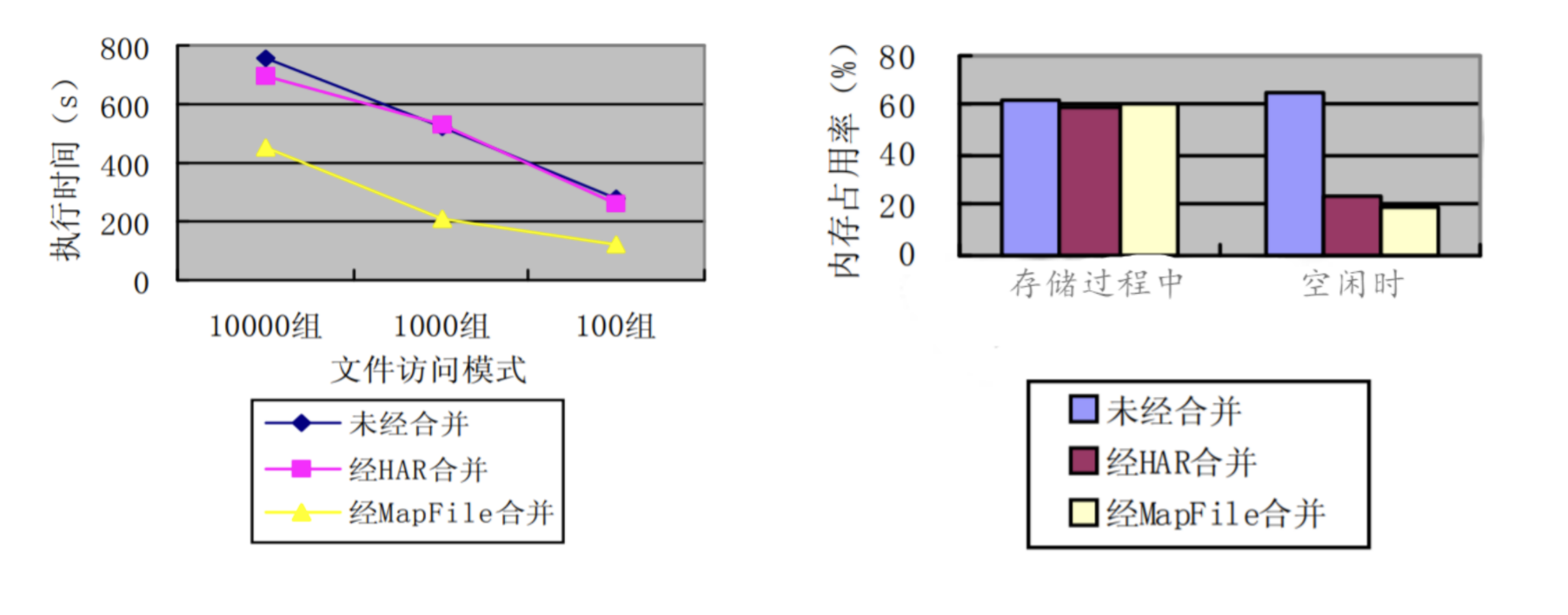
为了验证 Map File 的效果,经过对小文件的对比测试,可以看出本文的改进小文件存储策略在文件上传时的效率与未经改进没什么差别,但是在经过基于 Map File 序列化的将小文件合并成大文件后,在文件读取方面,比未经改进和经 HAR 合并的环境下效率都高,而且在 HDFS 空闲时,合并过后的内存占用率明显下降,这就减轻了 Namenode 名称节点的负担,提高内存使用率。
c. 示例
(1)读取文本文件,转换为 Map File 文件。
public int run(String[] args) throws Exception {
Configuration conf = getConf();
// 实例化作业
Job job = Job.getInstance(conf, "MrWriteToMapFile");
// 设置作业的主程序
job.setJarByClass(this.getClass());
// 设置作业的输入为TextInputFormat(普通文本)
job.setInputFormatClass(TextInputFormat.class);
// 设置作业的输入路径
FileInputFormat.addInputPath(job, new Path(args[0]));
// 设置Map端的实现类
job.setMapperClass(WriteMapFileAppMapper.class);
// 设置Map端输入的Key类型
job.setMapOutputKeyClass(IntWritable.class);
// 设置Map端输入的Value类型
job.setMapOutputValueClass(Text.class);
// ======= 设置作业的输出为MapFileOutputFormat =======
job.setOutputFormatClass(MapFileOutputFormat.class);
// =================================================
// 设置Reduce端的实现类
job.setReducerClass(WriteMapFileAppReducer.class);
// 设置Reduce端输出的Key类型
job.setOutputKeyClass(IntWritable.class);
// 设置Reduce端输出的Value类型
job.setOutputValueClass(Text.class);
// 从参数中获取输出路径
Path outputDir = new Path(args[1]);
// 如果输出路径已存在则删除
outputDir.getFileSystem(conf).delete(outputDir, true);
// 设置作业的输出路径
MapFileOutputFormat.setOutputPath(job, outputDir);
// 提交作业并等待执行完成
return job.waitForCompletion(true) ? 0 : 1;
}
(2)读取 Map File 文件,转换为普通文本文件。
public int run(String[] args) throws Exception {
// 实例化作业
Job job = Job.getInstance(this.getConf(), "MrReadFromMapFile");
// 设置作业的主程序
job.setJarByClass(this.getClass());
// === 设置作业的输入为SequenceFileInputFormat(Hadoop没有直接提供MapFileInput)===
job.setInputFormatClass(SequenceFileInputFormat.class);
// ===========================================================================
// 设置作业的输入路径
SequenceFileInputFormat.addInputPath(job, new Path(args[0]));
// 设置Map端的实现类
job.setMapperClass(ReadMapFileAppMapper.class);
// 设置Map端输入的Key类型
job.setMapOutputKeyClass(NullWritable.class);
// 设置Map端输入的Value类型
job.setMapOutputValueClass(Text.class);
// 设置作业的输出为SequenceFileOutputFormat
job.setOutputFormatClass(TextOutputFormat.class);
// 设置Reduce端的实现类
job.setReducerClass(ReadMapFileAppReducer.class);
// 设置Reduce端输出的Key类型
job.setOutputKeyClass(NullWritable.class);
// 设置Reduce端输出的Value类型
job.setOutputValueClass(Text.class);
// 从参数中获取输出路径
Path outputDir = new Path(args[1]);
// 如果输出路径已存在则删除
outputDir.getFileSystem(this.getConf()).delete(outputDir, true);
// 设置作业的输出路径
TextOutputFormat.setOutputPath(job, outputDir);
// 提交作业并等待执行完成
return job.waitForCompletion(true) ? 0 : 1;
}
2.3 ORC File
a. 列式存储
行存储和列存储,是数据库底层组织数据的方式。
我们平常生活中或者工作中接触了很多数据的存储系统,但是大部分都是行存储系统。比如我们学习的数据库管理系统,我们将数据库中的表想象成一张表格,每条数据记录就是一行数据,每行数据包含若干列。所以我们对大部分数据存储的思维也就是一个复杂一点的表格管理系统。我们在一行一行地写入数据,然后按查询条件查询过滤出我们想要的行记录。大部分传统的 RDBMS(关系型数据库),都是面向行来组织数据的,比如 MySQL、Oracle、PostgreSQL。
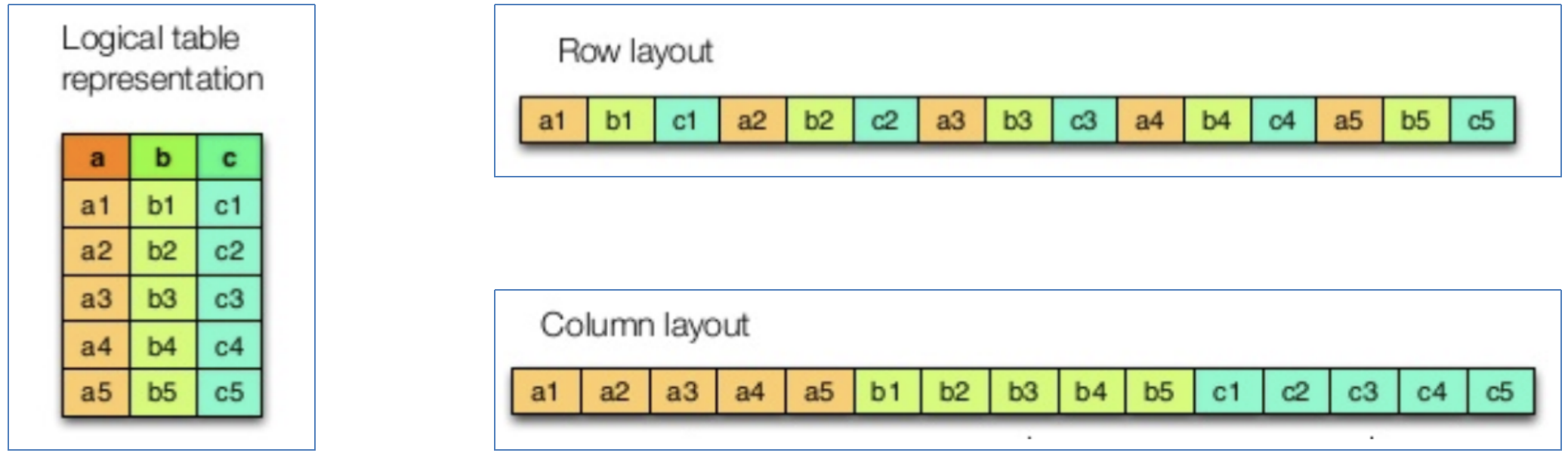
传统 OLTP(Online Transaction Processing) 数据库通常采用「行式存储」。以下图为例,所有的列依次排列构成一行,以行为单位存储,再配合以 B+ 树或 SS-Table 作为索引,就能快速通过主键找到相应的行数据。
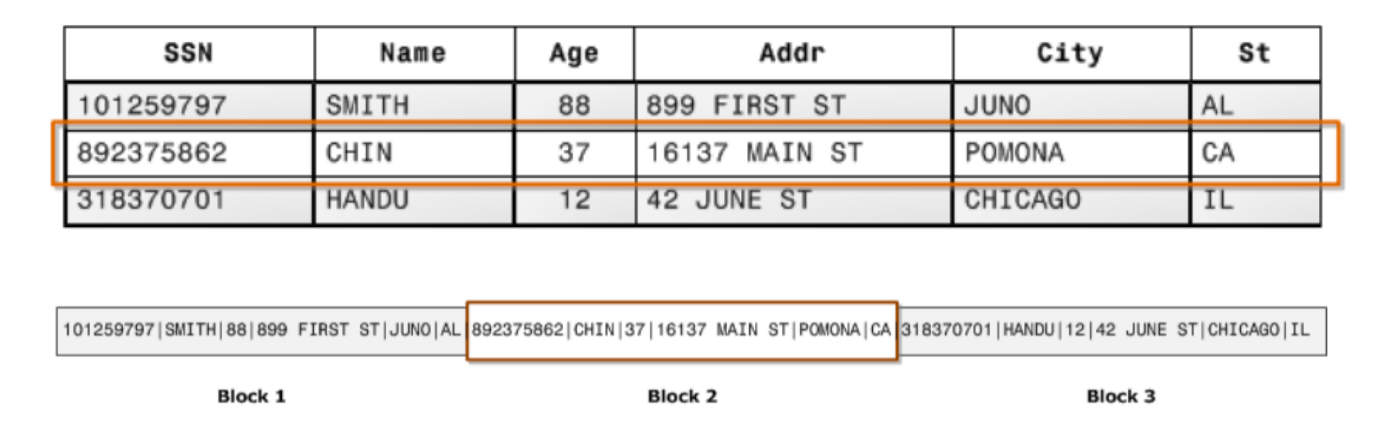
行存储将会以上方式将数据存储在磁盘上。它利于数据一行一行的写入,写入一条数据记录时,只需要将数据追加到已有数据记录后面即可。行模式存储适合 OLTP 系统。因为数据基于行存储,所以数据的写入会更快,对按行查询数据也更简单。
我们常见的数据存储都是行式存储,那为什么我们要学习列式存储呢?
因为我们现在学习的数据处理、大数据、数据分析,也就是 OLAP(Online Analytical Processing) 在线分析系统的需求增多了,数据写入的事务和按记录查询数据都不是它的关注点,它关注的是数据过滤,统计聚合,例如统计数据中的行数、平均值、最大值、最小值等。
列式存储(Column-oriented Storage)并不是一项新技术,最早可以追溯到 1983 年的论文 Cantor。然而,受限于早期的硬件条件和使用场景,主流的事务型数据库(OLTP)大多采用行式存储,直到近几年分析型数据库(OLAP)的兴起,列式存储这一概念又变得流行。
对于 OLAP 场景,一个典型的查询需要遍历整个表,进行分组、排序、聚合等操作,这样一来按行存储的优势就不复存在了。分析型 SQL 常常不会用到所有的列,而仅仅对其中某些感兴趣的列做运算,那一行中那些无关的列也不得不参与扫描。而使用了列式存储,可以只扫描我们需要的列,不需要将无关的列进行扫描,减少不必要的 IO 及磁盘检索消耗,提升读的性能。
列式存储就是为这样的需求设计的。
如下图所示,同一列的数据被一个接一个紧挨着存放在一起,表的每列构成一个长数组。
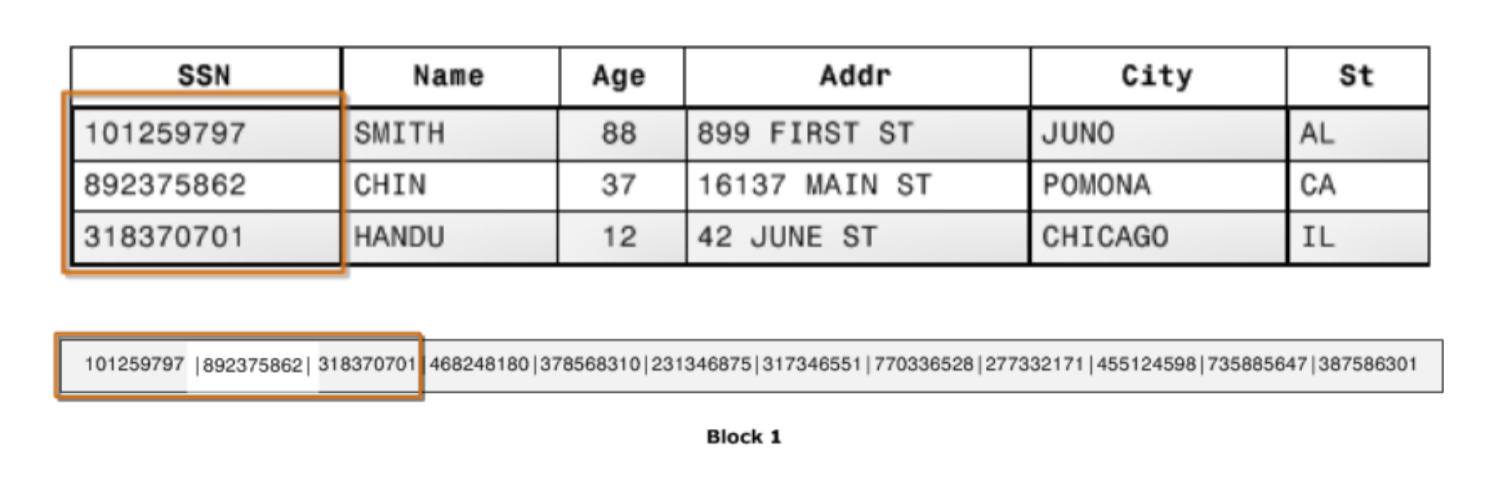
列式存储的优点:
- 【自动索引】因为基于列存储,所以每一列本身就相当于索引。所以在做一些需要索引的操作时,就不需要额外的数据结构来为此列创建合适的索引。
- 【利于数据压缩】相同的列数据类型一致,这样利于数据结构填充的优化和压缩,而且对于数字列这种数据类型可以采取更多有利的算法去压缩存储。
总的来说,列式存储的优势一方面体现在存储上能节约空间、减少 IO,另一方面依靠列式数据结构做了计算上的优化。
下面是行式存储与列式存储对比:
| \ | 行式存储 | 列式存储 |
|---|---|---|
| 特点 | 会扫描不需要的数据列 | 只读取需要的数据列 |
| 场景 | 适合于按记录读写数据的场景,不适合聚合统计的场景。 | 适合于数据过滤、聚合统计的场景,不适合按记录一个一个读写场景。 |
| 应用 | OLTP | OLAP |
| 压缩 | 不利于压缩数据 | 适合压缩数据 |
b. 概述&结构
ORC(OptimizedRC File)文件格式是一种 Hadoop 生态圈中的列式存储格式,源自于 RC(RecordColumnar File),它的产生早在 2013 年初,最初产生自 Apache Hive,用于降低 Hadoop 数据存储空间和加速 Hive 查询速度。
它并不是一个单纯的列式存储格式,仍然是首先根据「行组」分割整个表,在每一个行组内进行按列存储。ORC 文件是自描述的,它的元数据使用 Protocol Buffers 序列化,并且文件中的数据尽可能的压缩以降低存储空间的消耗,目前也被 Spark SQL、Presto 等查询引擎支持。2015 年 ORC 项目被 Apache 项目基金会提升为 Apache 顶级项目。
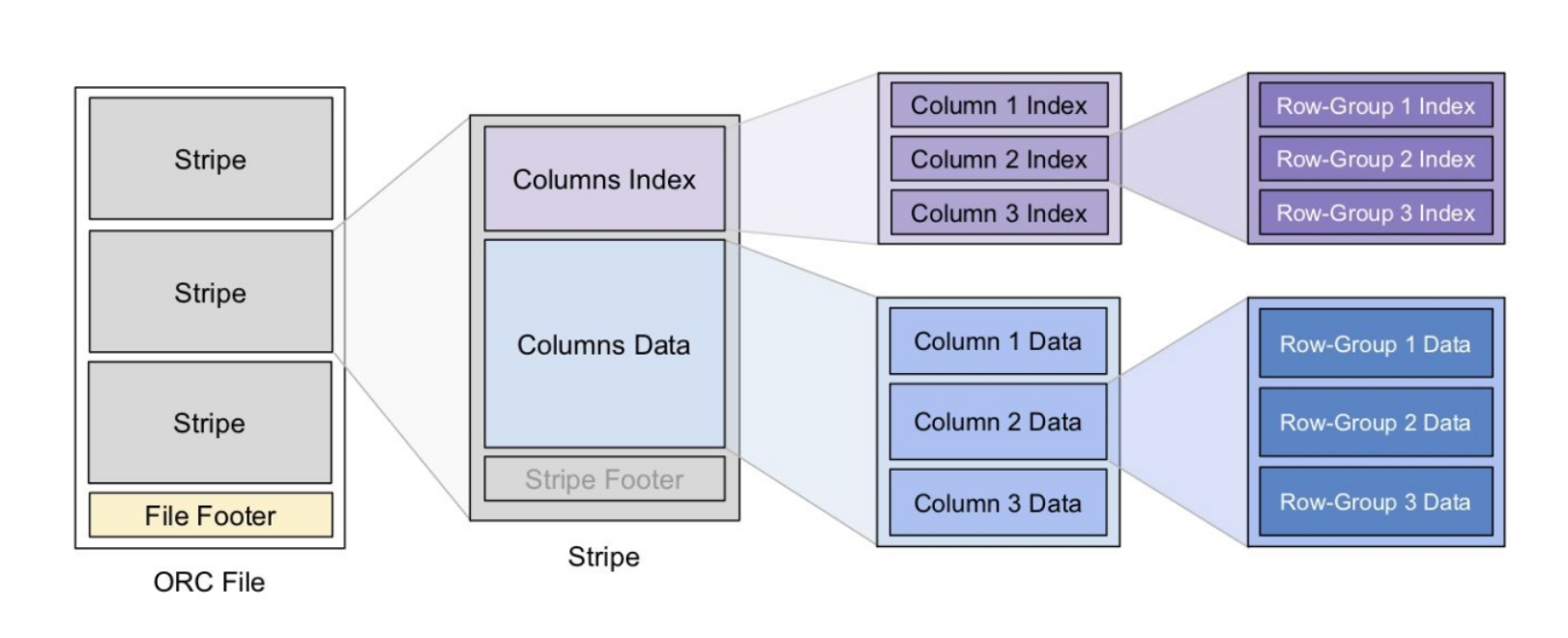
ORC 文件也是以二进制方式存储的,所以是不可以直接读取,ORC 文件也是自解析的,它包含许多的元数据,这些元数据都是同构 ProtoBuffer 进行序列化的。其中涉及到如下的概念:
- 【ORC 文件】保存在文件系统上的普通二进制文件,一个 ORC 文件中可以包含多个 stripe,每一个 stripe 包含多条记录,这些记录按照列进行独立存储。
- 【文件级元数据】包括文件的描述信息 PostScript、文件元信息(包括整个文件的统计信息)、所有 stripe 的信息和文件 schema 信息。
- 【Stripe】一组行形成一个 stripe,每次读取文件是以 Row-Group 为单位的,一般为 HDFS 的块大小,保存了每一列的索引和数据。
- 【Stripe 元数据】保存 stripe 的位置、每一个列的在该 stripe 的统计信息以及所有的 stream 类型和位置。
- 【Row-Group 行组】索引的最小单位,一个 stripe 中包含多个 Row-Group,默认为 10000 个值组成。
- 【stream】一个 stream 表示文件中一段有效的数据,包括索引和数据两类。索引 stream 保存每一个 Row-Group 的位置和统计信息,数据 stream 包括多种类型的数据,具体需要哪几种是由该列类型和编码方式决定。
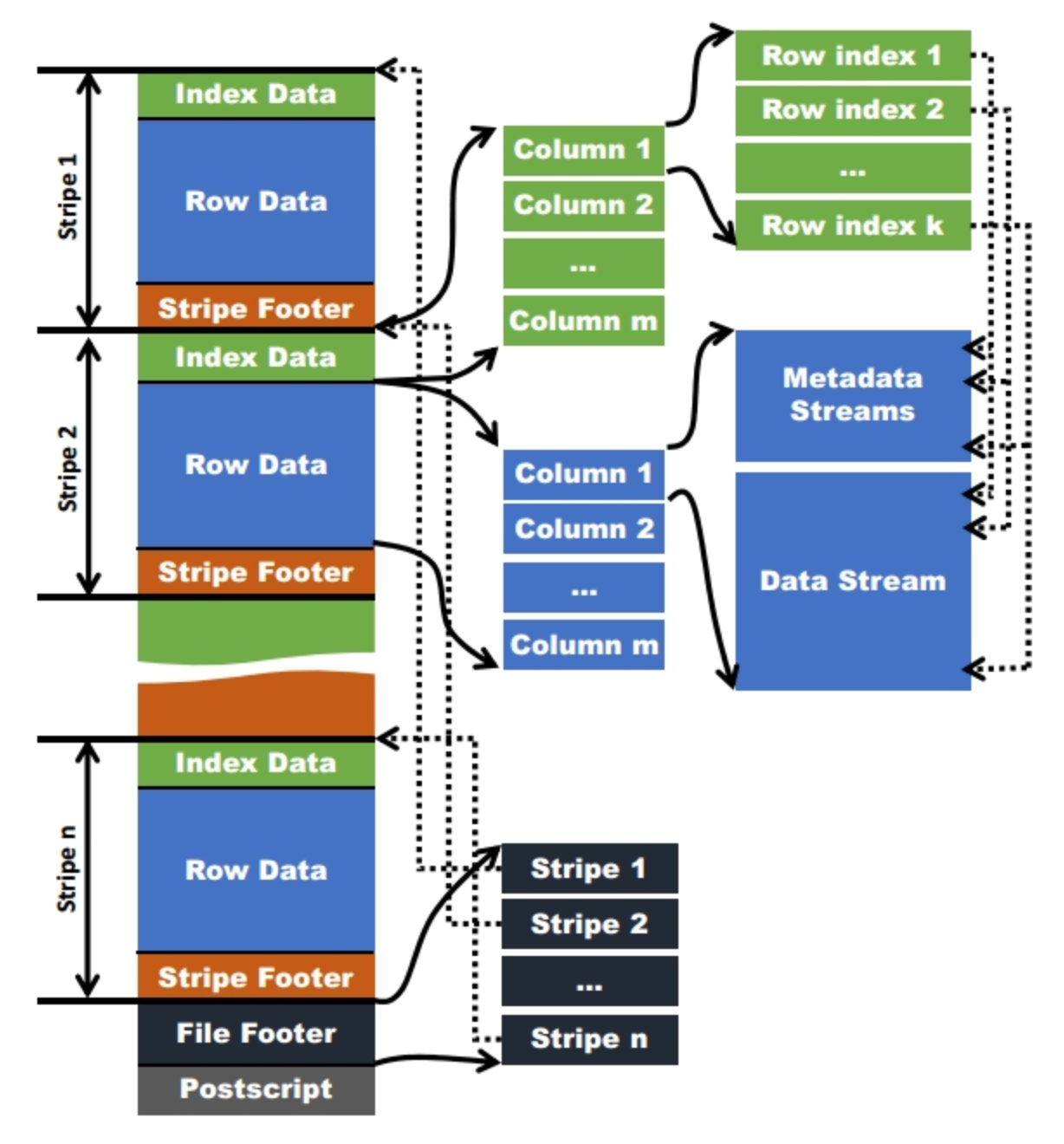
ORC 文件中保存了三个层级的统计信息,分别为 File 级别、Stripe 级别和 Row-Group 级别的,他们都可以用来根据 Search ARGuments(谓词下推条件)判断是否可以跳过某些数据,在统计信息中都包含成员数和是否有 null 值,并且对于不同类型的数据设置一些特定的统计信息。
c. 示例
(1)添加依赖
<!-- ORC文件依赖-->
<dependency>
<groupId>org.apache.orc</groupId>
<artifactId>orc-shims</artifactId>
<version>1.6.3</version>
</dependency>
<dependency>
<groupId>org.apache.orc</groupId>
<artifactId>orc-core</artifactId>
<version>1.6.3</version>
</dependency>
<!-- ORC与MapReduce集成的依赖 -->
<dependency>
<groupId>org.apache.orc</groupId>
<artifactId>orc-mapreduce</artifactId>
<version>1.6.3</version>
</dependency>
(2)用于读取普通文本文件转换为 ORC 文件
public class WriteOrcFileApp extends Configured implements Tool {
/**
* 作业名称
*/
private static final String JOB_NAME = WriteOrcFileApp.class.getSimpleName();
/**
* 构建日志监听
*/
private static final Logger LOG = LoggerFactory.getLogger(WriteOrcFileApp.class);
/**
* 定义数据的字段信息
*/
private static final String SCHEMA = "struct<id:string,type:string,orderID:string,bankCard:string,cardType:string,ctime:string,utime:string,remark:string>";
public int run(String[] args) throws Exception {
// 设置Schema
OrcConf.MAPRED_OUTPUT_SCHEMA.setString(this.getConf(), SCHEMA);
// 实例化作业
Job job = Job.getInstance(this.getConf(), JOB_NAME);
// 设置作业的主程序
job.setJarByClass(WriteOrcFileApp.class);
// 设置作业的Mapper类
job.setMapperClass(WriteOrcFileAppMapper.class);
// 设置作业的输入为TextInputFormat(普通文本)
job.setInputFormatClass(TextInputFormat.class);
// 设置作业的输出为OrcOutputFormat
job.setOutputFormatClass(OrcOutputFormat.class);
// 设置作业使用0个Reduce(直接从map端输出)
job.setNumReduceTasks(0);
// 设置作业的输入路径
FileInputFormat.addInputPath(job, new Path(args[0]));
// 从参数中获取输出路径
Path outputDir = new Path(args[1]);
// 如果输出路径已存在则删除
outputDir.getFileSystem(this.getConf()).delete(outputDir, true);
// 设置作业的输出路径
OrcOutputFormat.setOutputPath(job, outputDir);
// 提交作业并等待执行完成
return job.waitForCompletion(true) ? 0 : 1;
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
int status = ToolRunner.run(conf, new WriteOrcFileApp(), args);
System.exit(status);
}
public static class WriteOrcFileAppMapper extends Mapper<LongWritable, Text, NullWritable, OrcStruct> {
/**
* 获取字段描述信息
*/
private TypeDescription schema = TypeDescription.fromString(SCHEMA);
/**
* 构建输出的Key
*/
private final NullWritable outputKey = NullWritable.get();
/**
* 构建输出的Value为ORCStruct类型
*/
private final OrcStruct outputValue = (OrcStruct) OrcStruct.createValue(schema);
public void map(LongWritable key, Text value, Context output) throws IOException, InterruptedException {
// 将读取到的每一行数据进行分割,得到所有字段
String[] fields = value.toString().split(",", 8);
// 将所有字段赋值给Value中的列
outputValue.setFieldValue(0, new Text(fields[0]));
outputValue.setFieldValue(1, new Text(fields[1]));
outputValue.setFieldValue(2, new Text(fields[2]));
outputValue.setFieldValue(3, new Text(fields[3]));
outputValue.setFieldValue(4, new Text(fields[4]));
outputValue.setFieldValue(5, new Text(fields[5]));
outputValue.setFieldValue(6, new Text(fields[6]));
outputValue.setFieldValue(7, new Text(fields[7]));
// 输出 KV
output.write(outputKey, outputValue);
}
}
}
(3)读取 ORC 文件进行解析还原成普通文本文件
public class ReadOrcFileApp extends Configured implements Tool {
private static final String JOB_NAME = WriteOrcFileApp.class.getSimpleName();
public int run(String[] args) throws Exception {
// 实例化作业
Job job = Job.getInstance(this.getConf(), JOB_NAME);
// 设置作业的主程序
job.setJarByClass(ReadOrcFileApp.class);
// 设置作业的输入为OrcInputFormat
job.setInputFormatClass(OrcInputFormat.class);
// 设置作业的输入路径
OrcInputFormat.addInputPath(job, new Path(args[0]));
// 设置作业的Mapper类
job.setMapperClass(ReadOrcFileAppMapper.class);
// 设置作业使用0个Reduce(直接从map端输出)
job.setNumReduceTasks(0);
// 设置作业的输入为TextOutputFormat
job.setOutputFormatClass(TextOutputFormat.class);
// 从参数中获取输出路径
Path outputDir = new Path(args[1]);
// 如果输出路径已存在则删除
outputDir.getFileSystem(this.getConf()).delete(outputDir, true);
// 设置作业的输出路径
FileOutputFormat.setOutputPath(job, outputDir);
// 提交作业并等待执行完成
return job.waitForCompletion(true) ? 0 : 1;
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
int status = ToolRunner.run(conf, new ReadOrcFileApp(), args);
System.exit(status);
}
public static class ReadOrcFileAppMapper extends Mapper<NullWritable, OrcStruct, NullWritable, Text> {
private NullWritable outputKey;
private Text outputValue;
@Override
protected void setup(Context context) throws IOException, InterruptedException {
outputKey = NullWritable.get();
outputValue = new Text();
}
public void map(NullWritable key, OrcStruct value, Context output) throws IOException, InterruptedException {
// 将ORC中的每条数据转换为Text对象
this.outputValue.set(
value.getFieldValue(0).toString() + "," +
value.getFieldValue(1).toString() + "," +
value.getFieldValue(2).toString() + "," +
value.getFieldValue(3).toString() + "," +
value.getFieldValue(4).toString() + "," +
value.getFieldValue(5).toString() + "," +
value.getFieldValue(6).toString() + "," +
value.getFieldValue(7).toString()
);
// 输出结果
output.write(outputKey, outputValue);
}
}
}
3. 数据压缩优化
3.1 压缩优化设计
a. 压缩概述
运行 MapReduce 程序时,磁盘 I/O 操作、网络数据传输、shuffle 和 merge 要花大量的时间,尤其是数据规模很大和工作负载密集的情况下,鉴于磁盘 I/O 和网络带宽是 Hadoop 的宝贵资源,数据压缩对于节省资源、最小化磁盘 I/O 和网络传输非常有帮助。如果磁盘 I/O 和网络带宽影响了 MapReduce 作业性能,在任意 MapReduce 阶段启用压缩都可以改善端到端处理时间并减少 I/O 和网络流量。
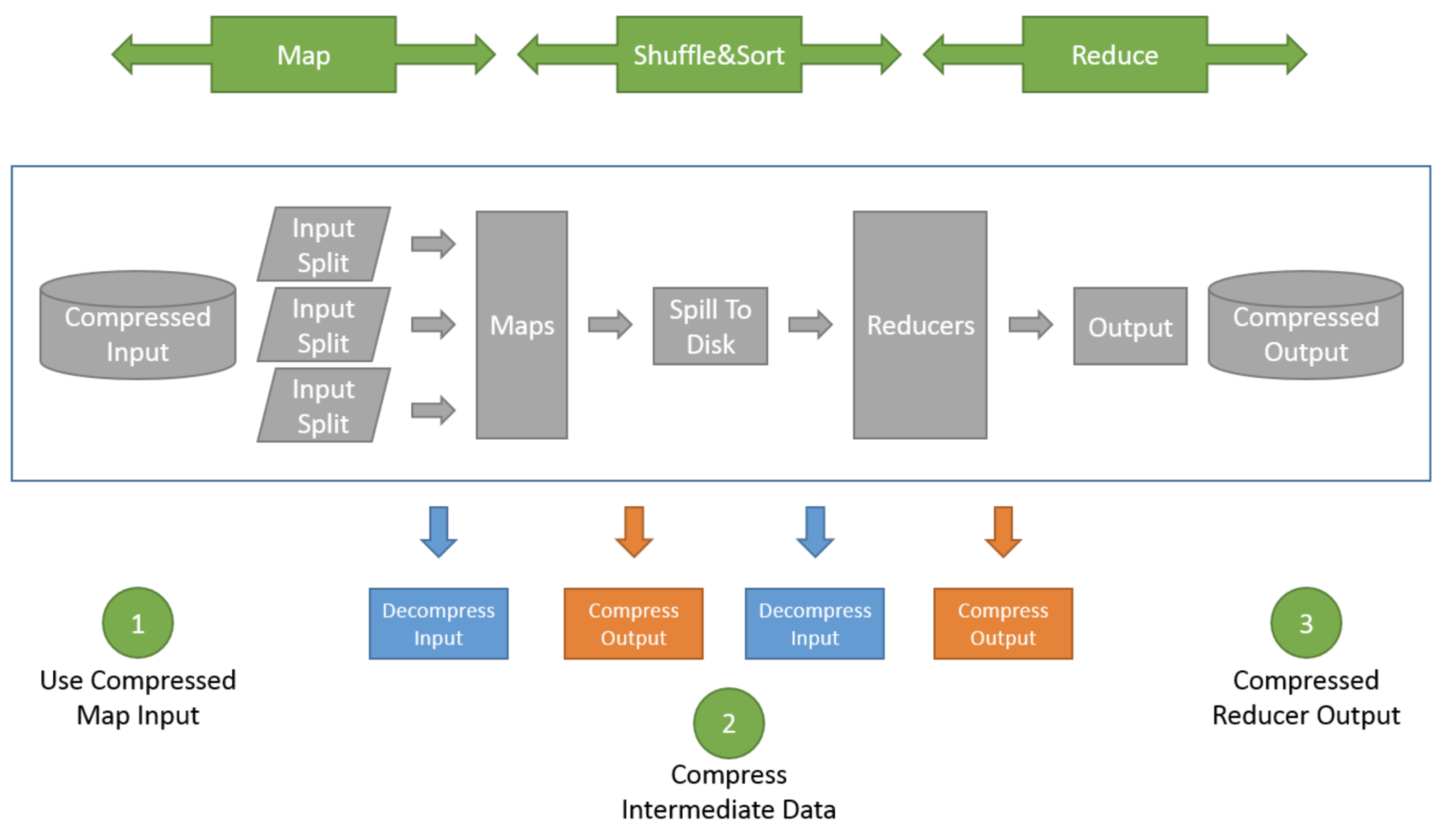
压缩是 MapReduce 的一种优化策略:通过压缩编码对 Mapper 或 Reducer 的输出进行压缩,以减少磁盘 IO,提高 MR 程序运行速度。
压缩优缺点:
- 优点
- 减小文件存储所占空间
- 加快文件传输效率,从而提高系统的处理速度
- 降低 IO 读写的次数
- 缺点
- 使用数据时需要先对文件解压,加重 CPU 负荷,压缩算法越复杂,解压时间越长
b. 支持压缩的位置
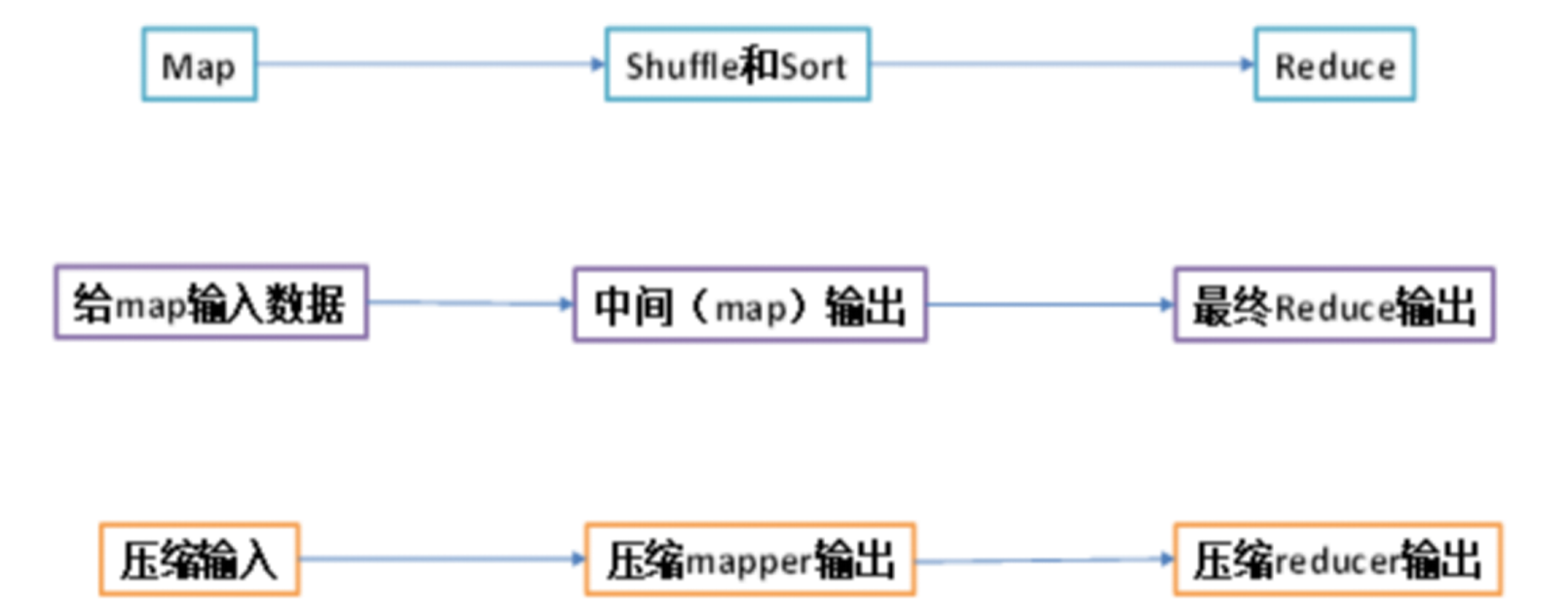
(1)Input 压缩
Hadoop 会自动检查压缩文件的扩展名,使用对应的解码器进行解码无需单独指定!
(2)Map 输出压缩
配置 Map 输出的结果进行压缩,需要指定以下属性来开启压缩机配置压缩算法类型。
| 配置名 | 配置值 |
|---|---|
| mapreduce.map.output.compress | true |
| mapreduce.map.output.compress.codec | org.apache.hadoop.io.compress.DefaultCodec |
(3)Reduce 输出压缩
配置 Reduce 输出的结果进行压缩,需要指定以下属性来开启压缩机配置压缩算法类型。
| 配置名 | 配置值 |
|---|---|
| mapreduce.output.fileoutputformat.compress | true |
| mapreduce.output.fileoutputformat.compress.codec | org.apache.hadoop.io.compress.DefaultCodec |
| mapreduce.output.fileoutputformat.compress.type | RECORD |
c. 压缩算法
检查 Hadoop 支持的压缩算法:hadoop checknative
Hadoop 支持的压缩算法:
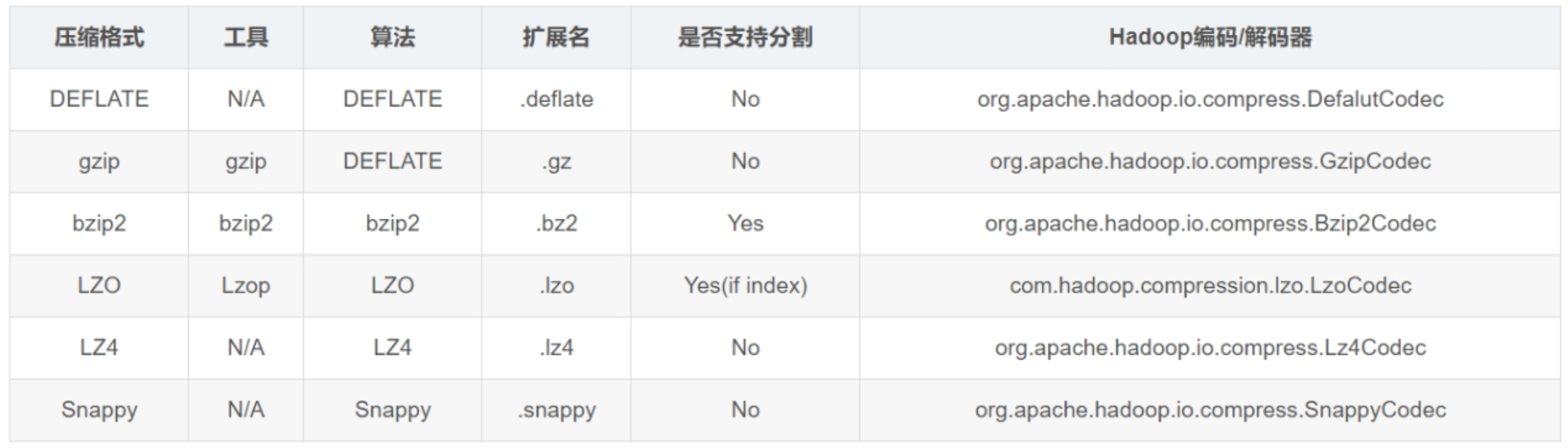
各压缩算法压缩性能对比:
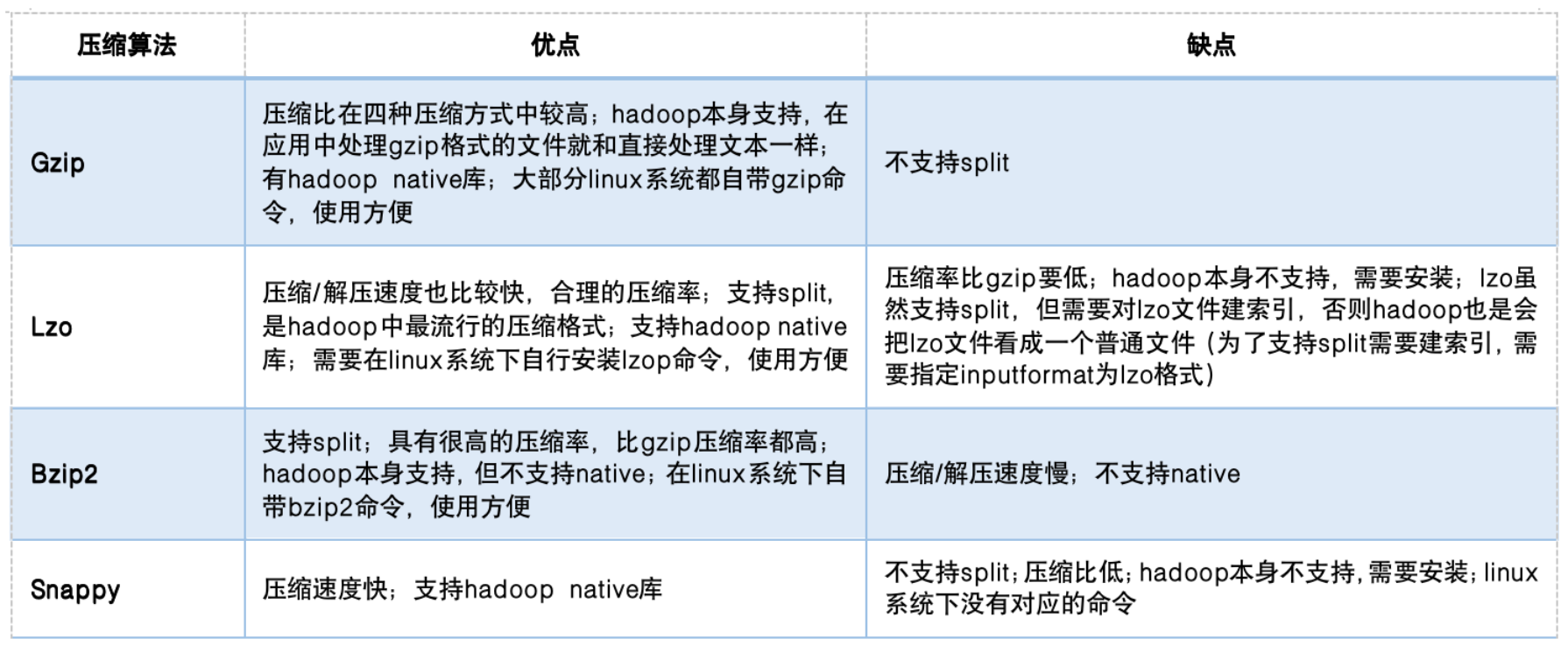
同样大小的数据对应压缩比:
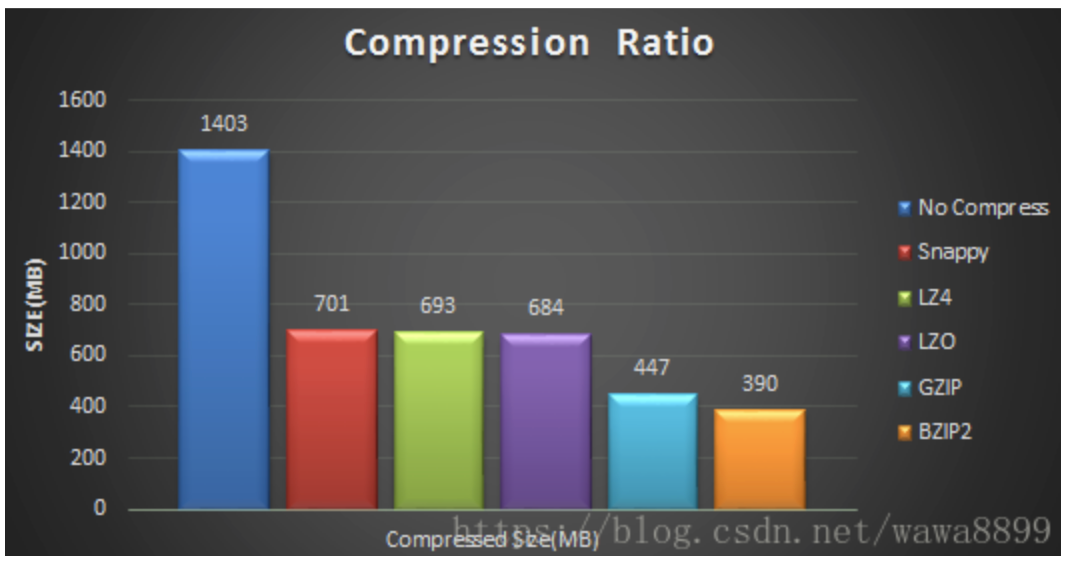
压缩时间和解压时间:
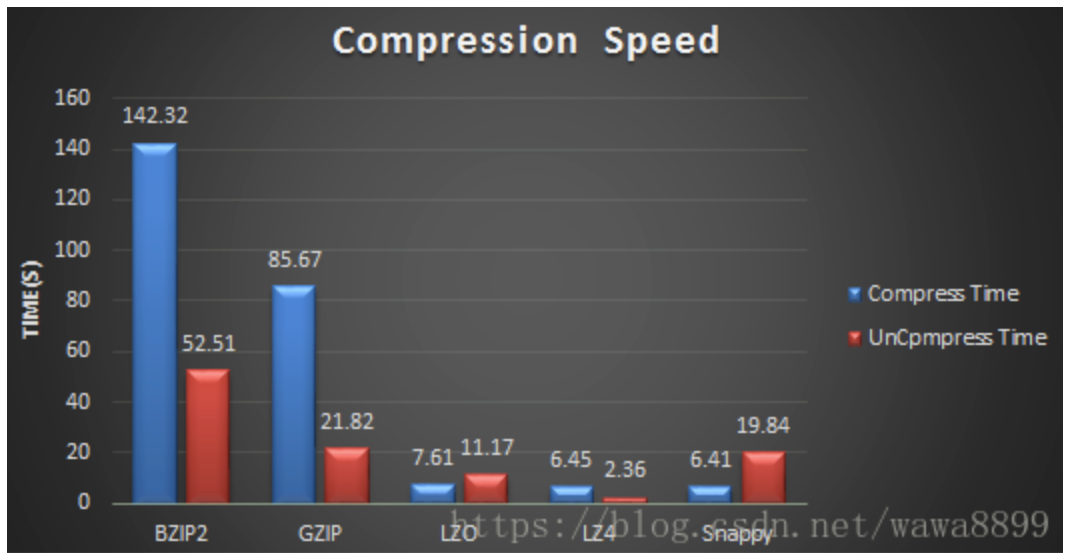
3.2 Gzip 压缩
生成 Gzip 压缩文件
public static void main(String[] args) throws Exception {
// 用于管理当前程序的所有配置
Configuration conf = new Configuration();
// 配置输出结果压缩为Gzip格式
conf.set("mapreduce.output.fileoutputformat.compress", "true");
conf.set("mapreduce.output.fileoutputformat.compress.codec", "org.apache.hadoop.io.compress.GzipCodec");
// 调用run方法,提交运行Job
int status = ToolRunner.run(conf, new MRWriteGzip(), args);
System.exit(status);
}
3.3 Snappy 压缩
Hadoop 支持 Snappy 类型的压缩算法,并且也是最常用的一种压缩算法,但是 Hadoop 官方已编译的安装包中并没有提供 Snappy 的支持,所以如果想使用 Snappy 压缩,必须下载 Hadoop 源码,自己进行编译,在编译时添加 Snappy 的支持。
生成 Snappy 压缩文件:Map 输出不压缩 / Map 输出压缩
public static void main(String[] args) throws Exception {
// 用于管理当前程序的所有配置
Configuration conf = new Configuration();
// 配置 Map 输出结果压缩为Snappy格式
conf.set("mapreduce.map.output.compress", "true");
conf.set("mapreduce.map.output.compress.codec", "org.apache.hadoop.io.compress.SnappyCodec");
// 配置 Reduce 输出结果压缩为Snappy格式
conf.set("mapreduce.output.fileoutputformat.compress", "true");
conf.set("mapreduce.output.fileoutputformat.compress.codec", "org.apache.hadoop.io.compress.SnappyCodec");
// 调用run方法,提交运行Job
int status = ToolRunner.run(conf, new MRMapOutputSnappy(), args);
System.exit(status);
}
3.4 Lzo 压缩
a. 配置 Lzo 支持
Hadoop 本身不支持 Lzo 类型的压缩,需要额外单独安装,并在编译时添加 Lzo 的压缩算法支持,编译过程请参考:http://t.csdn.cn/N5gxb
编译完成后,请实现以下配置,让当前的 Hadoop 支持 Lzo 压缩:
(1)添加 Lzo 支持 jar 包
$ cp hadoop-lzo-0.4.21-SNAPSHOT.jar /export/server/hadoop-3.1.4/share/hadoop/common/
(2)同步到所有节点
$ cd /export/server/hadoop-3.1.4/share/hadoop/common/
$ scp hadoop-lzo-0.4.21-SNAPSHOT.jar node2:$PWD
$ scp hadoop-lzo-0.4.21-SNAPSHOT.jar node3:$PWD
(3)修改 core-site.xml
<property>
<name>io.compression.codecs</name>
<value>org.apache.hadoop.io.compress.GzipCodec,org.apache.hadoop.io.compress.DefaultCodec,org.apache.hadoop.io.compress.BZip2Codec,org.apache.hadoop.io.compress.SnappyCodec,com.hadoop.compression.lzo.LzoCodec,com.hadoop.compression.lzo.LzopCodec</value>
</property>
<property>
<name>io.compression.codec.lzo.class</name>
<value>com.hadoop.compression.lzo.LzoCodec</value>
</property>
(4)同步 core-site.xml 到其他所有节点
$ cd /export/server/hadoop-3.1.4/etc/hadoop
$ scp core-site.xml node2:$PWD
$ scp core-site.xml node3:$PWD
(5)重新启动Hadoop集群
b. 生成 Lzo 压缩文件
- 编码器:org.apache.hadoop.io.compress.LzoCodec
- 结尾为 .lzo_deflate
- 不能构建索引,不兼容 lzop
- 编码器:com.hadoop.compression.lzo.LzopCodec
- 结尾为 .lzo
- 可以构建索引,兼容 lzo
读取普通文本文件,生成 Lzo 压缩结果文件:
public static void main(String[] args) throws Exception {
// 用于管理当前程序的所有配置
Configuration conf = new Configuration();
// 配置输出结果压缩为Lzo格式
conf.set("mapreduce.output.fileoutputformat.compress", "true");
conf.set("mapreduce.output.fileoutputformat.compress.codec", "com.hadoop.compression.lzo.LzopCodec");
// 调用run方法,提交运行Job
int status = ToolRunner.run(conf, new MRWriteLzo(), args);
System.exit(status);
}
观察控制台打印:
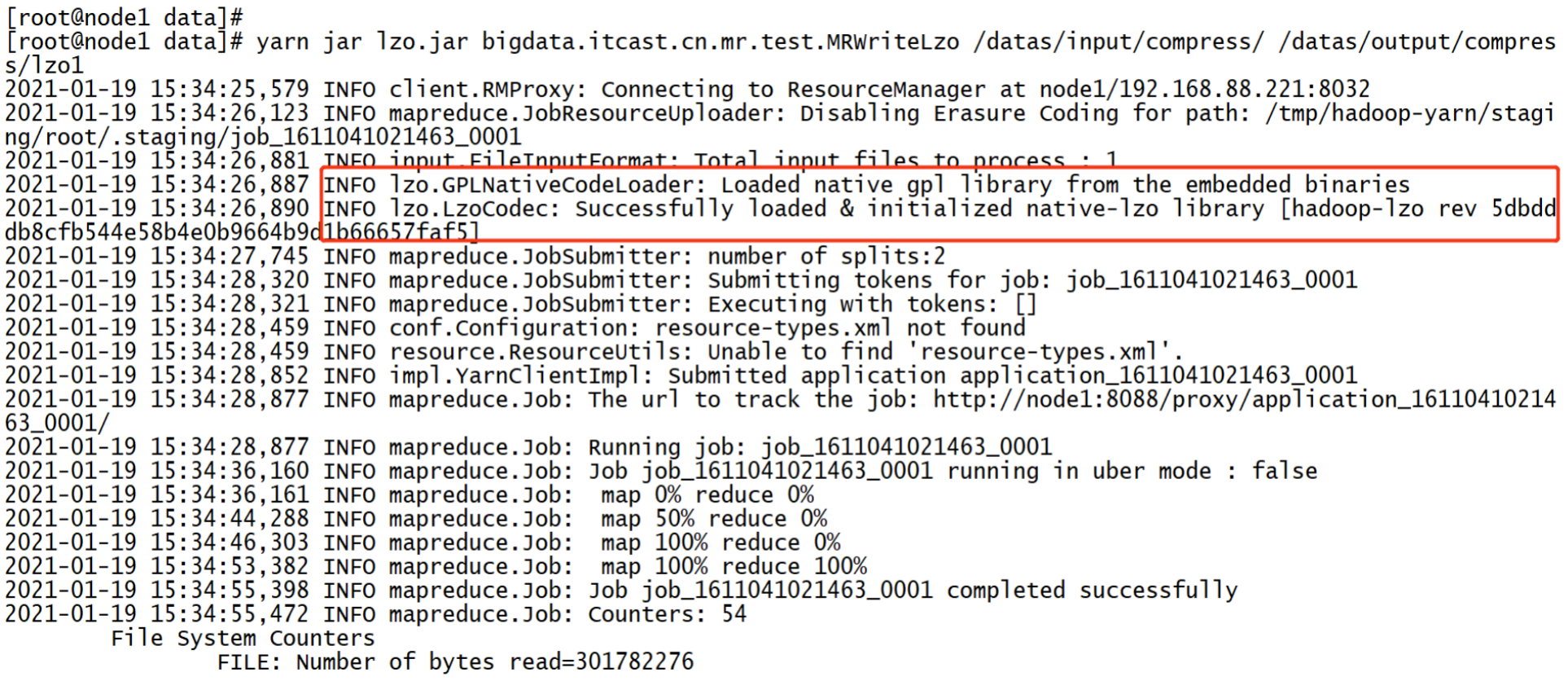
c. 生成 Lzo 索引
(1)调整切片大小为 30M,生成多个 MapTask 读取 Lzo 文件。
$ yarn jar test-mapreduce-1.0.jar cn.itcast.hadoop.mapreduce.compress.lzo.MRReadLzo \
-D mapreduce.input.fileinputformat.split.maxsize=31457280 \
/data/compress/lzo /data/compress/lzo1
(2)分片未生效,依旧只启动一个 MapTask 进行处理。
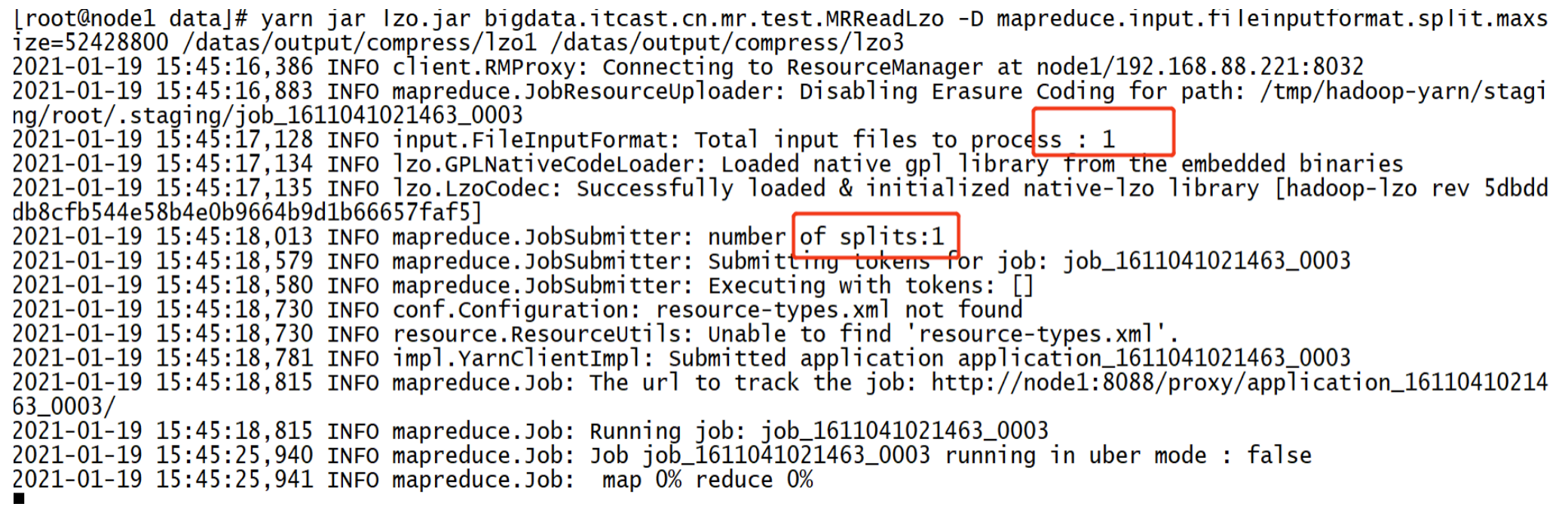
- 原因:默认使用 TextInputFormat 读取 Lzo 文件,只会启动一个 MapTask 来读取,不论大小。
- 解决:基于 Lzo 文件索引,使用 LzoTextInputFormat 进行读取,可以根据分片规则进行分片,启动多个 MapTask。
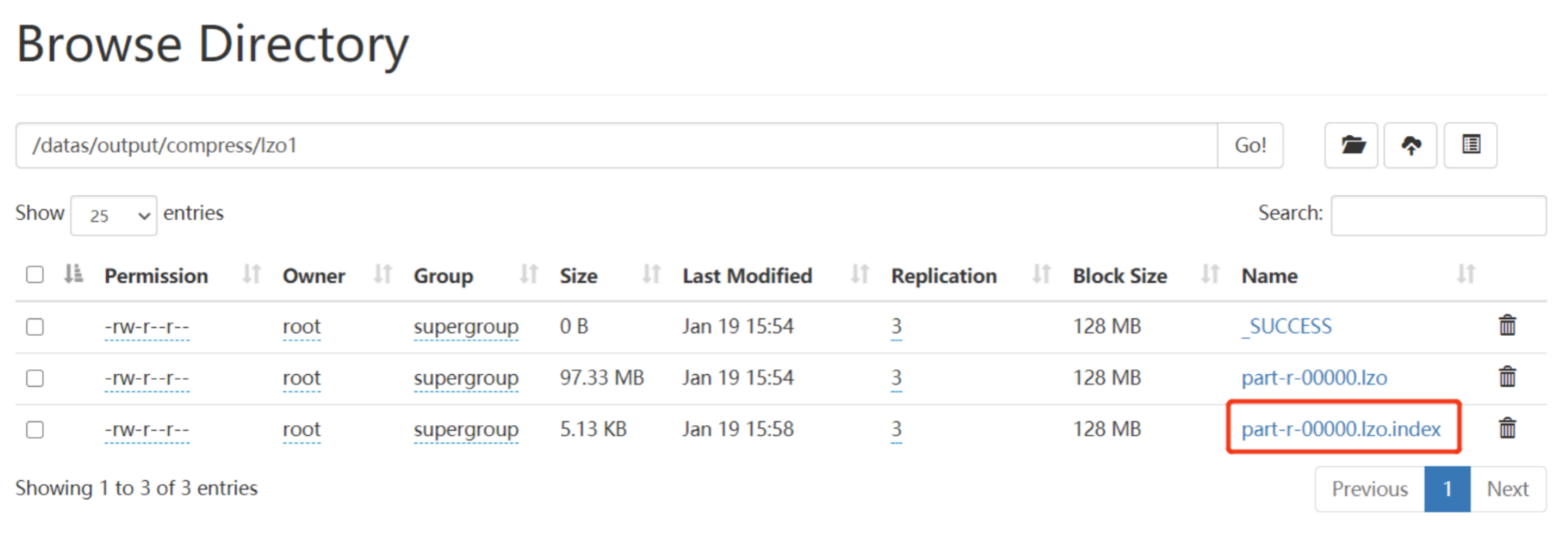
(3)生成索引
$ yarn jar /export/server/hadoop-3.1.4/share/hadoop/common/hadoop-lzo-0.4.21-SNAPSHOT.jar com.hadoop.compression.lzo.DistributedLzoIndexer /data/compress/lzo/part-r-00000.lzo
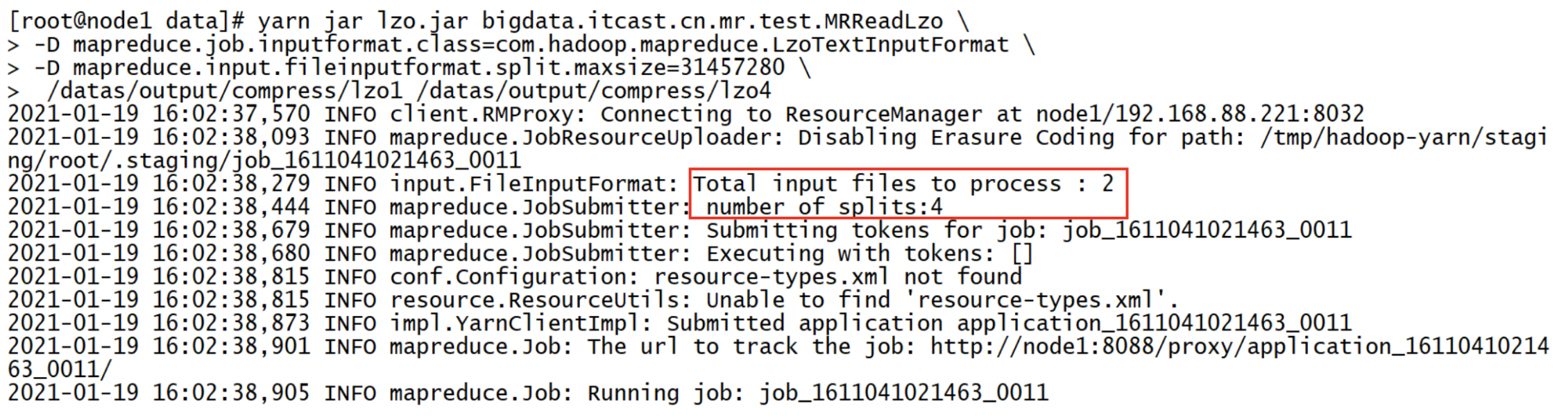
(4)设置分片大小为 30 M,重新运行
$ yarn jar test-mapreduce-1.0.jar cn.itcast.hadoop.mapreduce.compress.lzo.MRReadLzo \
-D mapreduce.job.inputformat.class=com.hadoop.mapreduce.LzoTextInputFormat \
-D mapreduce.input.fileinputformat.split.maxsize=31457280 \
/data/compress/lzo /data/compress/lzo2
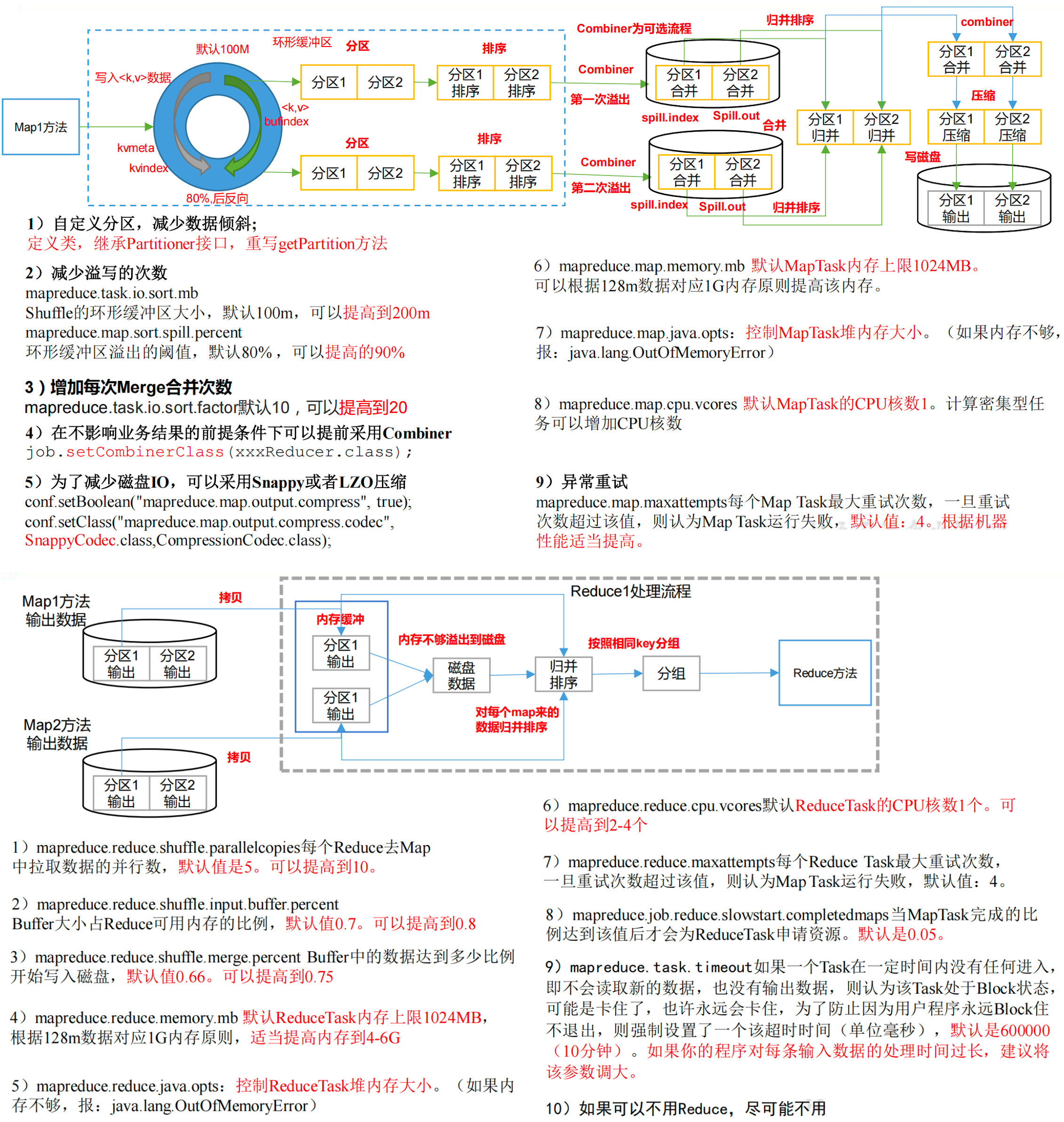
4. MR 属性优化
MapReduce 的核心优化在于修改数据文件类型、合并小文件、使用压缩等方式,通过降低 IO 开销来提升 MapReduce 过程中 Task 的执行效率。除此之外,MapReduce 中也可以通过调节一些参数来从整体上提升 MapReduce 的性能。
4.1 基准测试
可以通过基准测试来测试 MapReduce 集群对应的性能,观察实施了优化以后的 MapReduce 的性能是否得到提升等。
MapReduce 中自带了基准测试的工具 jar 包,只要运行即可看到自带的测试工具类。
(1)基准测试-MR Bench
-
功能:用于指定生成文件,MapTask、ReduceTask 的个数,并且可以指定执行的次数。
-
例如:生成每个文件 10000 行,20 个 Mapper,5 个 Reducer,执行 2 次。
$ yarn jar hadoop-mapreduce-client-jobclient-3.1.4-tests.jar mrbench -numRuns 2 -inputLines 10000 -maps 20 -reduces 5
(2)基准测试-Load Gen
-
功能:指定对某个数据进行加载,处理,测试性能耗时,可以调整 Map 和 Reduce 个数。
-
例如:对 150M 的数据进行测试,10 个 Map,1 个 Reduce。
$ yarn jar hadoop-mapreduce-client-jobclient-3.1.4-tests.jar loadgen -m 10 -r 1 -indir /data/compress/src_data -outdir /data/compress/load
4.2 Uber 模式
我们在实际使用 MapReduce 过程会发现一种特殊情况,当运行于 Hadoop 集群上的一些 MR 作业本身的数据量并不是很大,如果此时的任务分片很多,那么为每个 map 任务或者 reduce 任务频繁创建 Container,势必会增加 Hadoop 集群的资源消耗,并且因为创建分配 Container 本身的开销,还会增加这些任务的运行时延。面临这个问题,如果能将这些小任务都放入少量的 Container 中执行,将会解决这些问题。MapReduce 中就提供了这样的解决方案 —— Uber 模式。
Uber 运行模式对小作业进行优化,不会给每个任务分别申请分配 Container 资源,这些小任务将统一在一个 Container 中按照先执行 map 任务后执行 reduce 任务的顺序串行执行。
开启(默认为 false):mapreduce.job.ubertask.enable=true
条件:
- map 任务的数量不大于 mapreduce.job.ubertask.maxmaps 参数(默认值是 9)
- reduce任务的数量不大于 mapreduce.job.ubertask.maxreduces 参数(默认值是 1)
- 输入文件大小不大于 mapreduce.job.ubertask.maxbytes 参数(默认为 1 个块的大小 128M)
- map 任务和 reduce 任务需要的资源量不能大于 MRAppMaster 可用的资源总量
4.3 JVM 重用
JVM 正常指代一个 Java 进程,Hadoop 默认使用派生的 JVM 来执行 MR,如果一个 MapReduce 程序中有 100 个 Map 和 10 个 Reduce,Hadoop 默认会为每个 Task 启动一个 JVM 来运行,那么就会启动 100 个 JVM 来运行 MapTask,在 JVM 启动时内存开销大,尤其是 Job 大数据量情况,如果单个 Task 数据量比较小,也会导致 JVM 资源,这就导致了资源紧张及浪费的情况。
为了解决上述问题,MapReduce 中提供了 JVM 重用机制来解决,JVM 重用可以使得 JVM 实例在同一个 Job 中重新使用 N 次,当一个 Task 运行结束以后,JVM 不会进行释放,而是继续供下一个 Task 运行,直到运行了 N 个 Task 以后,就会释放,N 的值可以在 Hadoop 的 mapred-site.xml 文件中进行配置,通常在 10~20 之间。
- Hadoop3 之前在 mapred-site.xml 中添加参数:mapreduce.job.jvm.numtasks=10
- Hadoop3 中已不再支持该选项
4.4 重试机制
当 MapReduce 运行过程中,如果出现 MapTask 或 ReduceTask 由于网络、资源等外部因素导致 Task 失败,AppMaster 会检测到 Task 的任务失败,会立即重新分配资源,重新运行该失败的 Task,默认情况下会重试 4 次,如果重试 4 次以后依旧没有运行成功,那么整个 Job 会终止,程序运行失败。
我们可以根据实际的情况来调节重试的次数,在 mapred-site.xml 中修改:
- MapTask 失败后的重试次数:mapreduce.map.maxattempts=4
- ReduceTask 失败后的重试次数:mapreduce.reduce.maxattempts = 4
4.5 推测执行
MapReduce 模型将 Job 作业分解成 Task 任务,然后并行的运行 Task 任务,使整个 Job 作业整体执行时间少于各个任务顺序执行时间。这会导致作业执行时间多,但运行缓慢的任务很敏感,因为运行一个缓慢的 Task 任务会使整个 Job 作业所用的时间远远长于其他 Task 任务的时间。
当一个 Job 有成百上千个 Task 时,可能会出现拖后腿的 Task 任务。Task 任务执行缓慢可能有多种原因,包括硬件老化或软件配置错误,但检测问题具体原因很难,因为任务总能成功执行完,尽管比预计时间长。Hadoop 不会尝试诊断或修复执行慢的任务。
推测执行时指在一个 Task 任务运行比预期慢时,程序会尽量检测并启动另一个相同的任务作为备份,这就是推测执行(Speculative Execution),但是如果同时启动两个相同的任务他们会相互竞争,导致推测执行无法正常工作,这对集群资源是一种浪费。
只有在一个 Job 作业的所有 Task 任务都启动之后才会启动推测任务,并只针对已经运行一段时间(至少 1 分钟)且比作业中其他任务平均进度慢的任务。一个任务成功完成后任何正在运行的重复任务都将中止。如果原任务在推测任务之前完成则推测任务就会被中止,同样,如果推测任务先完成则原任务就会被中止。
推测任务只是一种优化措施,它并不能使 Job 作业运行的更加可靠。如果有一些软件缺陷造成的任务挂起或运行速度慢,依靠推测执行是不能成功解决的。默认情况下推测执行是启用的,可根据集群或每个作业,单独为 map 任务或 reduce 任务启用或禁用该功能。
在 mapred-site.xml 中修改默认属性:
- MapTask 的推测执行机制(默认开启):mapreduce.map.speculative = false
- ReduceTask 的推测执行机制(默认开启):mapreduce.reduce.speculative = false
4.6 其他属性优化
a. 小文件合并优化
针对于小文件处理场景,默认每个小文件都会构建一个切片,启动一个 maptask 处理。可以使用 CombineTextInputFormat 代替 TextInputFormat,将多个小文件合并为一个分片。
CombineTextInputFormat 切片机制过包括「虚拟存储过程」和「切片过程」二部分。
CombineTextInputFormat 的设置使用:
// 设置输入类
job.setInputFormatClass(CombineTextInputFormat.class);
// 设置最大切片 4M
CombineTextInputFormat.setMaxInputSplitSize(job, 4194304);
【例】假设 setMaxInputSplitSize 值为 4M,有如下 4 个文件:
a.txt 1.7M
b.txt 5.1M
c.txt 3.4M
d.txt 6.8M
(1)虚拟存储过程
将输入目录下所有文件大小,依次和设置的 setMaxInputSplitSize 值比较,如果不大于设置的最大值,逻辑上划分一个块。如果输入文件大于设置的最大值且大于两倍,那么以最大值切割一块,当剩余数据大小超过设置的最大值且不大于最大值 2 倍,此时将文件均分成 2 个虚拟存储块(防止出现太小切片)。
1.7M < 4M 划分一块
5.1M > 4M 但是小于 2x4M,划分二块:块1=2.55M,块2=2.55M
3.4M < 4M 划分一块
6.8M > 4M 但是小于 2x4M,划分二块:块1=3.4M,块2=3.4M
最终存储的文件:
1.7M
2.55M 2.55M
3.4M
3.4M 3.4M
(2)切片过程
判断虚拟存储的文件大小是否大于 setMaxIputSplitSize 值,大于等于则单独形成一个切片。如果不大于则跟下一个虚拟存储文件进行合并,共同形成一个切片。
最终会形成 3 个切片:(1.7+2.55) M、(2.55+3.4) M、(3.4+3.4) M
b. 减少 Shuffle 的 Spill&Merge
减少 Spill,默认每个缓冲区大小为 100M,每次达到 80% 开始 Spill,如果调大这两个值,可以减少数据 Spill 的次数,从而减少磁盘 IO。
修改 mapred-site.xml:
- mapreduce.task.io.sort.mb = 200
- mapreduce.map.sort.spill.percent = 0.9
减少 Merge,默认每次生成 10 个小文件开始进行合并,如果增大文件个数,可以减少 Merge 的次数,从而减少磁盘 IO。
修改 mapred-site.xml:
- mapreduce.task.io.sort.factor = 15
c. 开启 Reduce 端缓存
默认情况下 Reduce 端会将数据从 Buffer 缓存写入磁盘,然后再从磁盘读取数据进行处理,Buffer 中不会存储数据,如果内存允许的情况下,我们可以直接将 Buffer 的数据缓存在内存中,读取时直接从内存中获取数据。
修改 mapred-site.xml,指定 20% 内存空间用来存储 Buffer 的数据(默认为 0):
mapreduce.reduce.input.buffer.percent = 0.2