DBMS的结构:
特点:
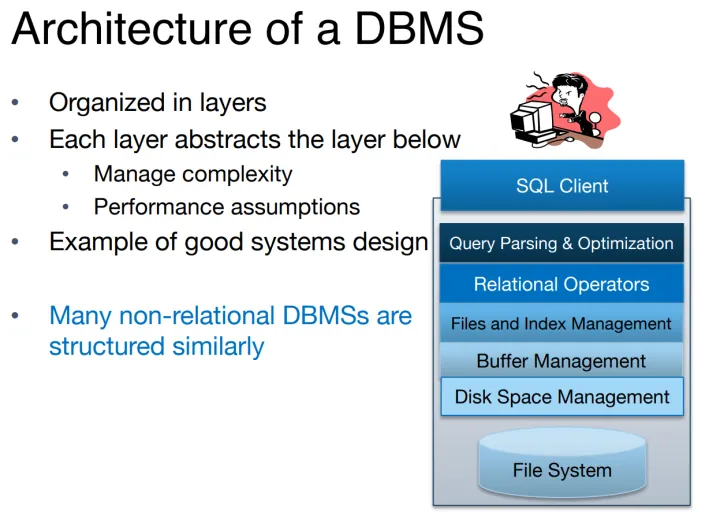
-
分层构造
-
每层都是下层的抽象
==>实验是从下往上进行的
Memory and Disk 内存和磁盘
当数据库处理数据时,该数据必须存在于内存中.因为这样访问该数据的速度相对较快,但是一旦数据变得非常大,就不可能将所有数据都放入内存中.使用磁盘来存储数据相对于内存来说比较廉价,但是当访问数据或写入数据时,磁盘都会产生大量成本.
Files, Pages, Records 文件 页 记录
文件是一种存储在外存上的数据结构, 它由大量性质相同的记录组成.
关系数据库的数据单位是一条记录(行).这些记录被组织成关系(表),并且可以在内存中进行修改,删除,搜索或创建.
磁盘的基本数据单位是页,这是从磁盘到内存的最小传输单位,反之亦然.为了与磁盘兼容的格式表示关系数据库,每个关系都存储在其自己的文件中,并且其记录被组织到文件中的页中.根据关系的模式和访问模式,数据库将确定:
-
(1) 使用的文件类型
-
(2) 页在文件中的组织方式
-
(3) 每一页上的记录是如何组织的
-
(4) 以及每个记录的格式
行 表 页的结构(重点)

表储存为许多逻辑文件,逻辑文件由许多页构成,(文件结构在后面会提到)。每个页可以存放多个records, records就是表的一行。

页是I/O的基本单位,通常页的大小为64kb。
Record
关系模型 ==》表中的每条记录都有一些固定的类型
假设系统目录存储模式
不需要和记录一起存储类型信息(节省空间!)。
目录只是另一个表
目标:
记录在内存和磁盘格式中应该是紧凑的
对字段的快速访问
定长
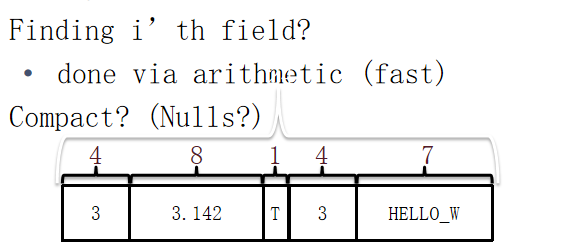
不定长
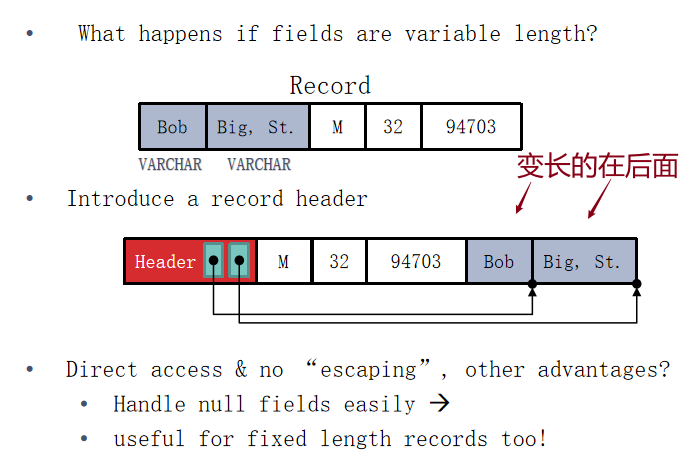
Page

页的内部结构,页眉会保存页的相关信息:记录的records数量;指向free space的指针;位图(用于维护固定长度的records);page的剩余空间..
records分为固定长度(FLR)和不固定长度(VLR),前者每个字段都是固定字节的类型,相同模式(schema)的FLR有相等的字节大小, VLR可以保存固定和可变的字段。
只储存FLR的page:
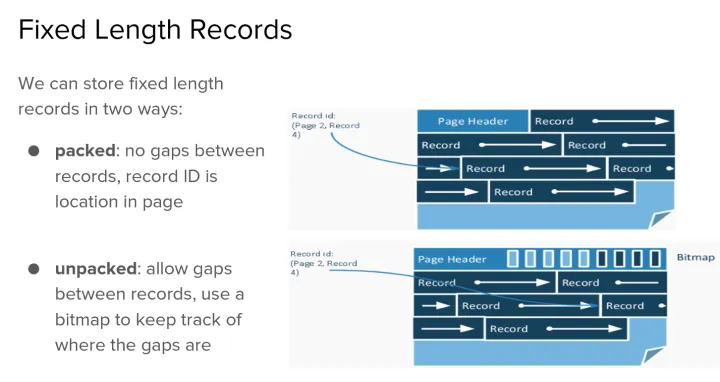
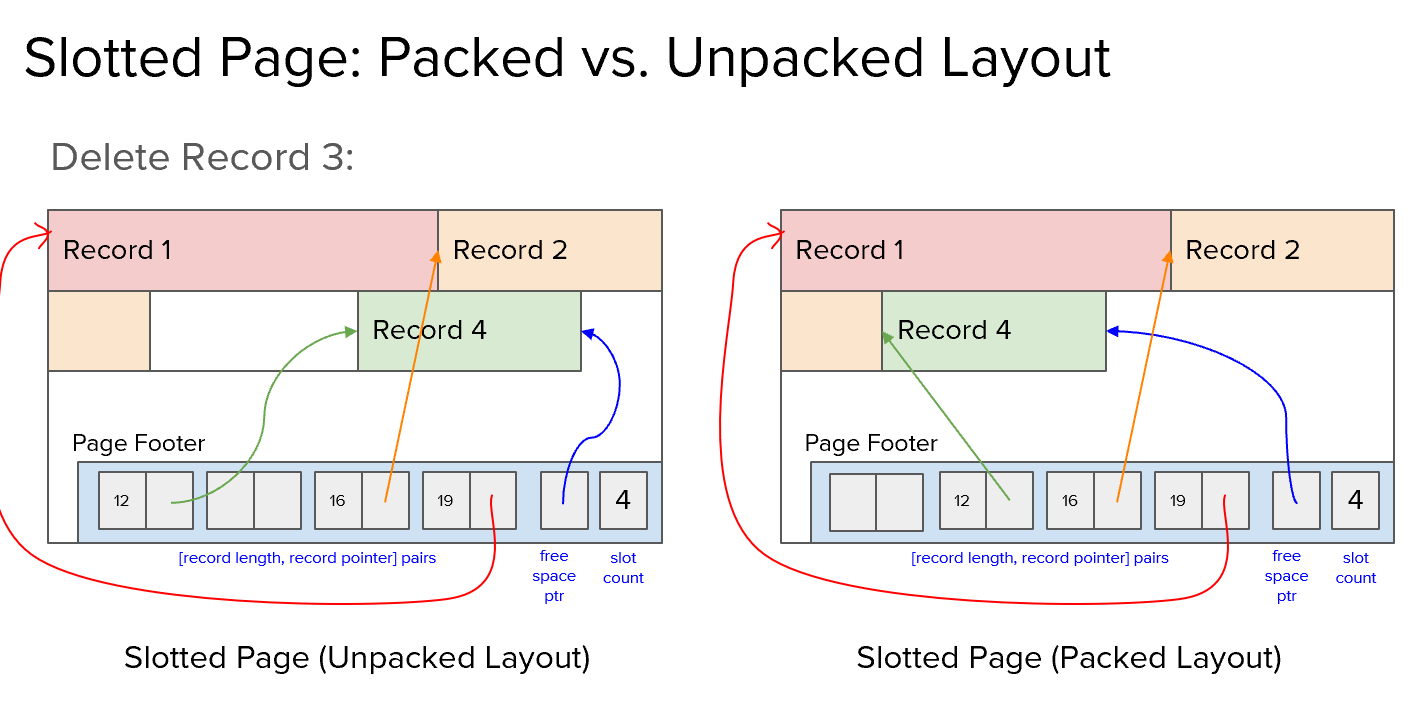
packed方式:删除后需要调整使得每个record之间没有空袭,每次插入都在末尾。 unpacked 运用bitmap维护删除和插入。
存储VLR的page:
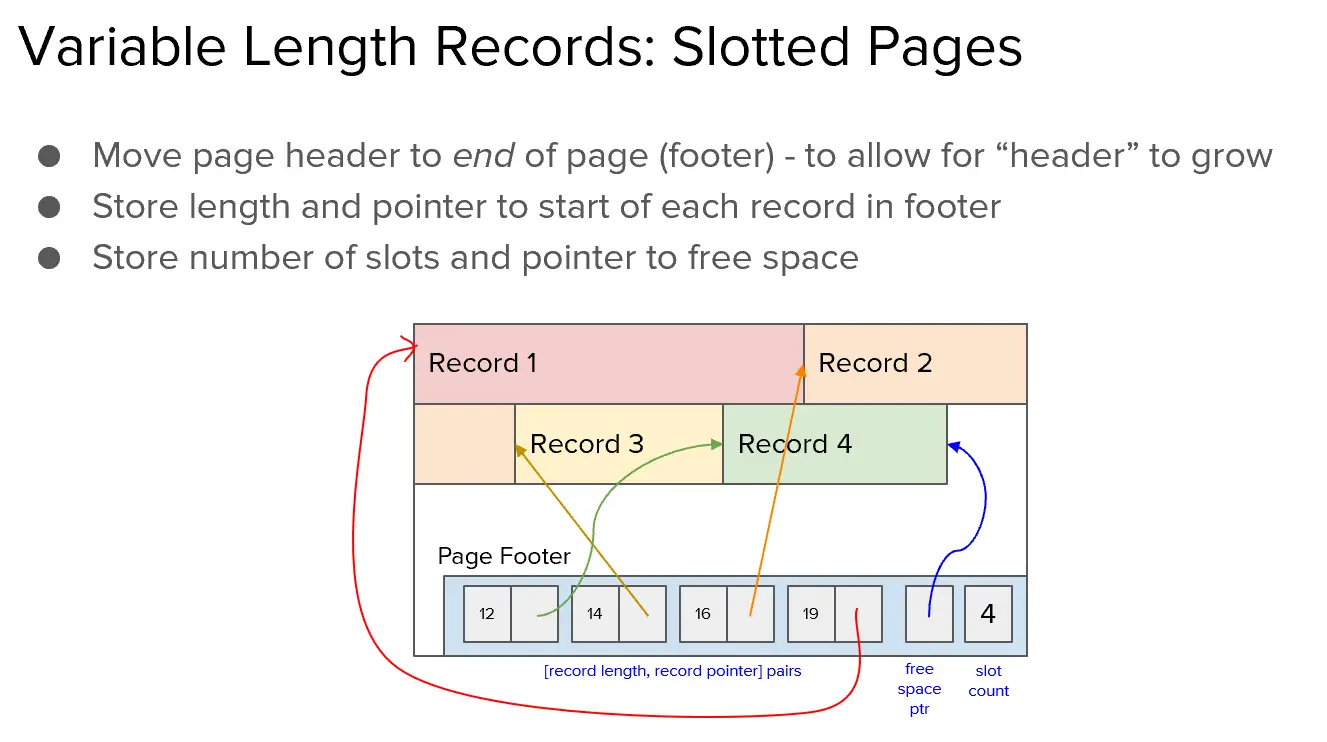
页眉并非在开头,而是在最后面,像链表一样往前增长,存储指针。
【记录长度,记录指针】
槽页的两种布局。
可以看出VLR 的 unpacked方式中,删除操作可能会造成磁盘碎片,造成空间的浪费。(Fragmentation)
Choosing File Types 选择文件类型
文件有两种主要类型:堆文件和排序文件.对于每个关系,数据库都会根据该关系的访问模式的I/O成本来选择要使用的文件类型.1个I/O等效于从磁盘读取1页或写入磁盘1页,并且根据其访问模式中的插入,删除和扫描操作对每种文件类型进行I/O计算.选择产生较少I/O成本的文件类型.
堆文件插入速度快 O(1),但查找速度慢 O(N);
排序文件插入速度慢,查找可以二分实现 O(logn);
堆文件有两种实现方法: 链表和页目录。
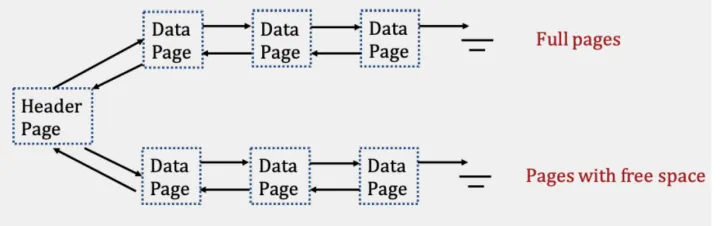
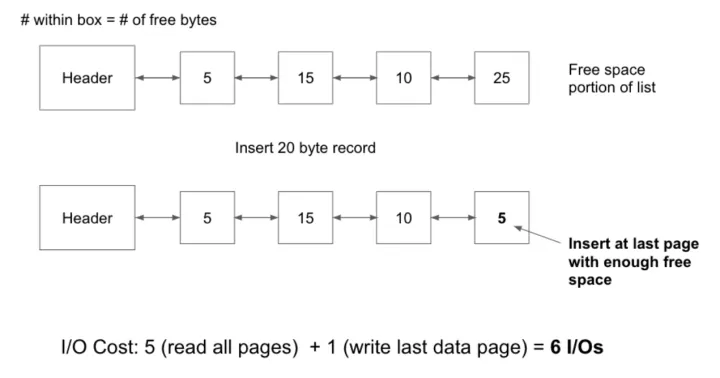
链表实现堆文件。header page相当于链表表头,不存数据。
插入recode时遍历free page, 找到合适的page就写入。
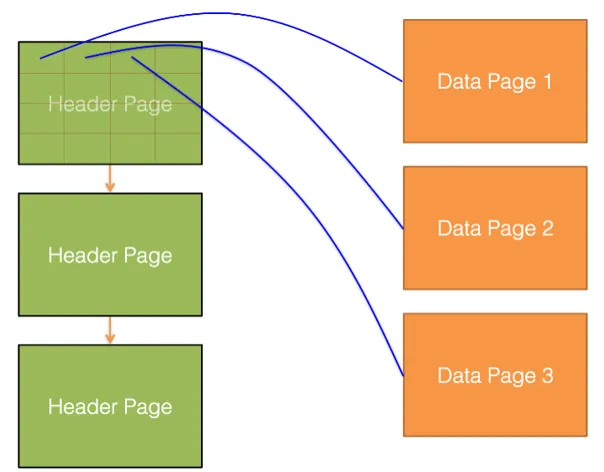
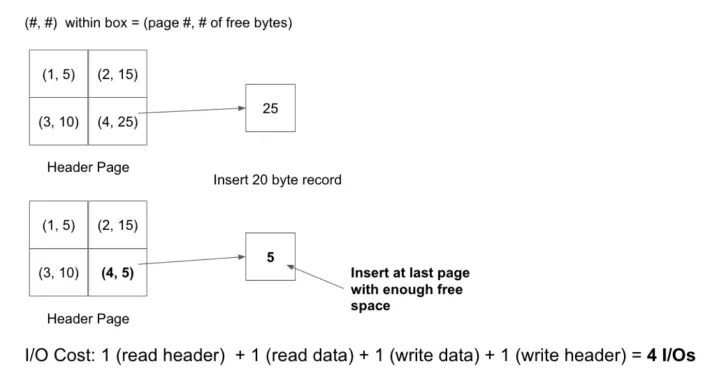
页目录实现堆文件。每个Header Page有多个entry.
●Each entry in a header page contains:
-
Pointer to a data page
-
The amount of free space for the data page
堆文件插入record:
Sorted Files 排序文件
排序文件是一种文件类型,其中页按顺序排序,并且每个页中的记录均按键排序.
这些文件是使用 页目录 实现的,并根据记录的排序方式对数据页执行排序.搜索排序的文件需要logN个I/O,其中N=页数,因为可以使用二分搜索来查找包含记录的页.同时,通常情况下,插入需要logN+N个I/O,因为需要二分搜索来找到要写入的页,并且该插入的记录可能会导致所有以后的记录都回退一个.平均而言,将需要推回N/2页,这涉及到每个页的读取和写入IO,这将导致N I/O项.
