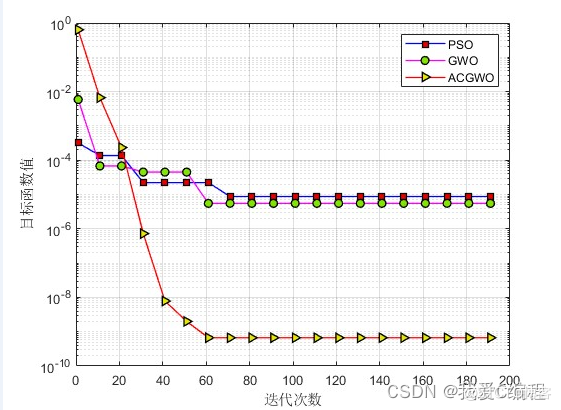
1.算法仿真效果
matlab2022a仿真结果如下:
2.算法涉及理论知识概要
灰狼优化算法(GWO),灵感来自于灰狼.GWO算法模拟了自然界灰狼的领导层级和狩猎机制.四种类型的灰狼,如 α,β,δ,w 被用来模拟领导阶层。此外,还实现了狩猎的三个主要步骤:寻找猎物、包围猎物和攻击猎物。
为了在设计GWO算法时对灰狼的社会等级进行数学建模,我们将最适解作为α .因此,第二和第三个最佳解决方案分别被命名为 β 和 δ .剩下的候选解被假定为 w .在GWO算法中,狩猎过程由 ,α,β 和 δ 引导. w 狼跟随这三只狼。
在狩猎过程中,将灰狼围捕猎物的行为定义如下:
D=|C⋅Xp(t)−X(t)| (1)
X(t+1)=Xp(t)−A⋅D (2)
式(1)表示个体与猎物间的距离,式(2)是灰狼的位置更新公式.其中, t 是目前的迭代代数, A 和 C 是系数向量, Xp 和 X 分别是猎物的位置向量和灰狼的位置向量. A 和 C 的公式如下:
A=2a⋅r1−a (3)
C=2⋅r2 (4)
其中, a 是收敛因子,随着迭代次数从2线性减小到0, r1 和 r2 的模取[0,1]之间的随机数.
2.2 狩猎
灰狼能够识别猎物的位置并包围它们.当灰狼识别出猎物的位置后, β 和 δ 在 α 的带领下指导狼群包围猎物.灰狼个体跟踪猎物位置的数学模型描述如下:
Dα=|C1⋅Xα−X|
Dβ=|C2⋅Xβ−X| (5)
Dδ=|C3⋅Xδ−X|
其中, Dα , Dβ和 Dδ 分别表示 α,β 和 δ 与其他个体间的距离; Xα,Xβ 和 Xδ 分别代表 α,β 和 δ 当前位置; C1,C2,C3 是随机向量, X 是当前灰狼的位置。
X1=Xα−A1⋅(Dα)
X2=Xβ−A2⋅(Dβ) (6)
X3=Xδ−A3⋅(Dδ)
X(t+1)=X1+X2+X33 (7)
式(6)分别定义了狼群中 w 个体朝向 α,β 和 δ 前进的步长和方向,式(7)定义了ω的最终位置。
2.3 攻击猎物
当猎物停止移动时,灰狼通过攻击来完成狩猎过程.为了模拟逼近猎物, a 的值被逐渐减小,因此 A 的波动范围也随之减小.换句话说,在迭代过程中,当 a 的值从2线性下降到0时,其对应的 A 的值也在区间 [−a,a] 内变化.如图3所 示,当 A 的值位于区间内时,灰狼的下一位置可以位于其当前位置和猎物位置之间的任意位置.当 |A|<1 时,狼群向猎物发起攻击(陷入局部最优).当 |A|>1 时,灰狼与猎物分离,希望找到更合适的猎物(全局最优).
GWO算法还有另一个组件 C 来帮助发现新的解决方案.由式(4)可知, C 是[0,2]之 间 的随机值. C 表示狼所在的位置对猎物影响的随机权重, C>1 表示影响权重大,反之,表示影响权重小.这有助于GWO算法更随机地表现并支持探索,同时可在优化过程中避免陷入局部最优.另外,与 A 不同, C 是非线性减小的.这样,从最初的迭代到最终的迭代中,它都提供了决策空间中的全局搜索.在算法陷入了局部最优并且不易跳出时, C 的随机性在避免局部最优方面发挥了非常重要的作用,尤其是在最后需要获得全局最优解的迭代中.
3.MATLAB核心程序
%a=2-2*((i)/Max_iter); % 对每一次迭代,计算相应的a值,a decreases linearly fron 2 to 0
a=2-2*((1/(exp(1)-1))*(exp(i/Max_iter)-1));
% 包围猎物,位置更新
for i=1:size(Positions,1)
for j=1:size(Positions,2)
r1=rand(); % r1 is a random number in [0,1]
r2=rand(); % r2 is a random number in [0,1]
A1=2*a*r1-a; % 计算系数A,Equation (3.3)
C1=2*r2; % 计算系数C,Equation (3.4)
% Alpha狼位置更新
D_alpha=abs(C1*Alpha_pos(j)-Positions(i,j)); % Equation (3.5)-part 1
X1=Alpha_pos(j)-A1*D_alpha; % Equation (3.6)-part 1
r1=rand();
r2=rand();
A2=2*a*r1-a; % Equation (3.3)
C2=2*r2; % Equation (3.4)
% Beta狼位置更新
D_beta=abs(C2*Beta_pos(j)-Positions(i,j)); % Equation (3.5)-part 2
X2=Beta_pos(j)-A2*D_beta; % Equation (3.6)-part 2
r1=rand();
r2=rand();
A3=2*a*r1-a; % 计算系数A,Equation (3.3)
C3=2*r2; %计算系数C, Equation (3.4)
% Delta狼位置更新
D_delta=abs(C3*Delta_pos(j)-Positions(i,j)); % Equation (3.5)-part 3
X3=Delta_pos(j)-A3*D_delta; % Equation (3.5)-part 3
% 位置更新
Positions(i,j)=(X1+X2+X3)/3;% Equation (3.7)
end
for t=1:20 %次数
%1生成
cxl=rand(SearchAgents_no,dim);
end
for j=1:dim
cxl(j)=4*cxl(j)*(1-cxl(j)); %logic混沌方程
end
end
l=l+1;
Convergence_curve(l)=Alpha_score;
end