【摘要】PostgreSQL 是一个功能强大的开源对象关系数据库管理系统,目前应用日益广泛,掌握相关使用技巧和故障处理方法也越来越重要。本文整理了5个故障案例,并介绍了详细的处理方法,希望能够对大家用好PostgreSQL有所帮助。
【作者】泊涯,公司分部测试经理,集团公司技术专家成员之一,目前主要在客户现场做银行系统的性能诊断分析优化和测试管理工作。
PostgreSQL数据库错误:检测到ShareLock死锁处理
PostgreSQL 是一个免费数据库,对于处理分析型+交易型混合型系统来说确实很不错,特别是版本的升级到11.2后性能提升很多,很多运行机制跟Oracle越来越接近,确实很强大,但是开源系统确实存在一些不如意地方,需要长时间项目问题集锦积累才能慢慢的领悟。
而作为从非功能测试转型做技术运维,在运维过程中会从非功能方面(高可用性、高可靠性、可扩展性等)和性能测试优化方面考虑确实可以避免很多生产不必要的故障问题,但是对于开源的技术在版本迭代过程中总会有些不如意的技术故障还是需要我们自己持续性学习、挖掘、积累、提升,才能确保技术能持续满足业务运营发展和市场需求。
如下问题是我们17年上线的系统,经2年的运行,很多业务表达到千万级,导致需要读写分离、分表等来优化,但是问题还是偶尔出现,说明技术还不到位,例如如下:
问题原因:
目前生产环境使用postgres9.5版本,主从配置,但是因为行业业务的特殊性,有些回访表等都是三四百万级别的,而且日常更新频繁度非常高,日常使用频繁比较高的表,一天insert、update都是接近十万,delete三四万以上,导致在对该表的统计信息不准确,而pg默认 autovacuum默认参数导致部分表因本身存量数据大,更新比例小,导致这些日常被用到的大表反而没办法被重新统计分析,最终导致磁盘IO 高,CPU 高问题,而因为在调整过程中调整不当也导致如下,在对表进行批量update 时,而PG就进行 autovacuum_analyze,结果导致出现 ShareLock错误,具体错误如下:
错误内容:
2019-04-14 15:15:47,707 ERROR [thinkgem.jeesite.common.repeat_form_validator.Token] - 2-
2019-04-14 15:15:47,707 ERROR [thinkgem.jeesite.common.repeat_form_validator.Token] - org.apache.shiro.web.servlet.ShiroHttpSession@
461f4ab1
2019-04-14 15:16:15,952 ERROR [thinkgem.jeesite.common.repeat_form_validator.Token] - 2-
2019-04-14 15:16:15,952 ERROR [thinkgem.jeesite.common.repeat_form_validator.Token] - org.apache.shiro.web.servlet.ShiroHttpSession@
285d498f
2019-04-14 15:16:18,138 ERROR [thinkgem.jeesite.common.repeat_form_validator.Token] - 1-61322fb9-7ca7-482b-99ee-913074957a94
2019-04-14 15:16:24,227 ERROR [500.jsp] -
Error updating database. Cause: org.postgresql.util.PSQLException: 错误: 检测到死锁
详细:进程6533等待在事务 36964707上的ShareLock; 由进程10733阻塞.
进程10733等待在事务 36964708上的ShareLock; 由进程6533阻塞.
建议:详细信息请查看服务器日志.
在位置:当更新关系"visit_crd"的元组(11314, 33)时
The error may involve defaultParameterMap
The error occurred while setting parameters
SQL: UPDATE visit_crd SET visit_plan_id = ?, customer_number = ?, call_id = ?, time_start = ?, time_end = ?,
duration = ?, type = ?, route = ?, cpn = ?, cdpn = ?, recording = ?, trunk_number = ?, update_by = ?, updat
e_date = ?, remarks = ?, affiliation = ?, update_ind = ?, execute_ind = ? WHERE id = ?
Cause: org.postgresql.util.PSQLException: 错误: 检测到死锁
详细:进程6533等待在事务 36964707上的ShareLock; 由进程10733阻塞.
进程10733等待在事务 36964708上的ShareLock; 由进程6533阻塞.
建议:详细信息请查看服务器日志.
在位置:当更新关系"visit_crd"的元组(11314, 33)时
; SQL []; 错误: 检测到死锁
详细:进程6533等待在事务 36964707上的ShareLock; 由进程10733阻塞.
进程10733等待在事务 36964708上的ShareLock; 由进程6533阻塞.
建议:详细信息请查看服务器日志.
在位置:当更新关系"visit_crd"的元组(11314, 33)时; nested exception is org.postgresql.util.PSQLException: 错误: 检测到死锁
详细:进程6533等待在事务 36964707上的ShareLock; 由进程10733阻塞.
进程10733等待在事务 36964708上的ShareLock; 由进程6533阻塞.
建议:详细信息请查看服务器日志.
在位置:当更新关系"visit_crd"的元组(11314, 33)时
org.springframework.dao.DeadlockLoserDataAccessException:
问题分析:
PG 默认 autovacuum
1、autovacuum_vacuum_threshold:默认50
2、autovacuum_vacuum_scale_factor默认值为20%。
3、autovacuum_analyze_threshold:默认50。
4、autovacuum_analyze_scale_factor默认10%
第一次优化:
autovacuum_vacuum_scale_factor = 0.001
autovacuum_analyze_scale_factor = 0.001
结果导致如上错误信息:
第二次优化:
autovacuum_vacuum_scale_factor = 0.03
autovacuum_analyze_scale_factor = 0.03
问题得到解决
Postgres11.2版本客户端打开column "p.prolang"问题处理
postgres升级到到11版本后,客户端打开会提示
ERROR:column p.proisagg does not exist
LINE 1:...database d on d.datname=current_database() where p.proisagg..
HINT: Perhaps you meant to reference the column "p.prolang"
无法打开函数功能,如下图:

是数据库服务版本高,客户端版本低引起的,通过下载最新pgadmin4-4.6 问题解决。

Postgres数据库大批量单表导入数据引发性能故障
因公司经营管理策略原因,我们地区部门还是以开发外包和产品服务为主,对测试外包服务销售工作要求占比不高,而测试部门本来有四五个性能测试人员,加上老员工都比较积极做事在测试团队建设管理上不用花费太多精力。估计因为我对数据库、tomcat、linux性能这块了解比较深以前相关的测试环境都是我搭建部署,一直都很稳定,所以公司让我帮忙兼职做公司产品技术运维支持工作,因此我大部分时间都是在做软件产品基础设施搭建研究MYSQL\\PG\\TOMCAT\\Centos等优化配置和数据安全备份方法,作为初学者很多未知领域需要探索学习研究。
这段时间的运维感触是,做为一名技术运维人员需要一个拥有“耐心、静心、探索心、敬业心”,不然心情一爽rm -rf ,后果不敢设想,或者部署配置时日志格式、清理机制、数据存放路径、备份方式没弄好也会导致系统不稳定等问题。
当然有时客户自己也有专职运维人员,但是往往有些技术运维人员,对数据安全等敏感性没那么高,会误操作导致双方一下子手忙脚乱,例如系统缓慢就restart tomcat 或者kill pid 来应急,但是最终的效果是数据不一致或者丢失等现象。例如下面这个问题就是因为客户一下子插入700W笔数据,但是事先没跟我方项目人员沟通导致系统无法正常运行问题。
下午临近下班时,客户突然打电话给我方项目经理说,系统运行很慢,PG数据库服务器卡死,输入top 都要等五六分钟才能响应,但是CPU使用率不高,如下图:
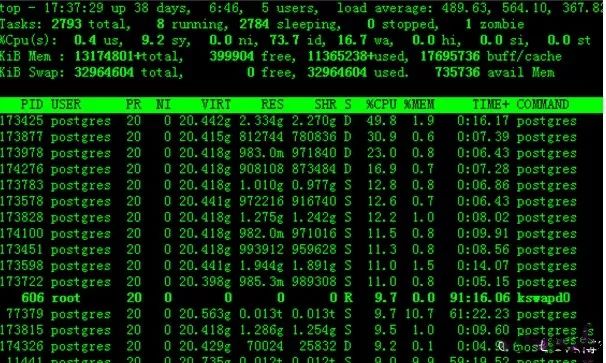
这是看到的数据库服务器CPU使用率确实不高,通过free命令
看到内存将耗尽

通过top看到系统调用KSWAPd0,并运行占用时间比较长,于是我让项目经理打电话问客户说在操作什么,是不是在倒数据?
一开始客户说没做任何操作,但是持续监控一段时间查看了内存使用free一直很低,而且kswapd0进程一直被调度使用,
kswapd0进程的作用:它是虚拟内存管理中,负责换页的,操作系统每过一定时间就会唤醒kswapd ,看看内存是否紧张,如果不紧张,则睡眠,在 kswapd 中,有2 个阀值,pages_hige 和 pages_low,当空闲内存页的数量低于 pages_low 的时候,kswapd进程就会扫描内存并且每次释放出32 个free pages,直到 free page 的数量到达pages_high,由于内存实在不够用了, 于是就死掉了.
这说明一点客户在做大量数据插入操作,导致内存不足,引发系统卡顿,但是客户那边说没做任何操作,我们也怀疑是不是被安全攻击等,作为初级运维人员思维确实比较混乱,没有那么多经验,当时应急方式先重启数据库后,内存立马释放正常,但是没过几分钟又重现问题,这时我们双方打电话沟通了下,原来客户是有在对一张已有百万级数据量的表做迁移插入操作,插入数据也是百万级,知道原因后,也知道对应的表后,查看了该表发现客户在做操作时没有对该表的索引等先删除在插入操作导致系统就慢慢的死掉了。----这也是项目运维管理规范问题导致的。
PG数据库快速INSERT大量数据
临时删除index
有时候我们在备份和导入大量数据时,这个时候可以先把index删除掉。导入在建index。
Postgres异常断电导致启动失败解决方法
问题起因:
前段时间客户生产服务器,突然不小心弄断电了,虽然运维人员重启服务后,看似能正常访问,但是出现主从无法正常同步数据问题,而重新启动服务后,报could not connet to server。。。。postgresql/.s.PGSQL.5432,后台日志出现,accepting TCP/IP connections on port 5432等一串错误信息。突发性断电导致异常终止,这是数据库的postmaster.pid 文件仍健在,但是其实不起作用,在后台数据库日志也可以看到如下错误信息,lock file "postmaster.pid" already exists,这时建议先cp 备份另存下,以防改错,然后在直接mv postmaster.pid 迁移到其他地方 ,然后重启数据库服务,即可解决问题。而启动的时候出现启动失败,具体情况请看下下面的文章:《postgres启动失败问题分析与处理 》
原理分析:
当我们启动PostgresSQL时,会在PostgreSQL中的数据文件夹生成postmaster.pid 文件,该文件主要是记录启动时对应的进程号等相关信息,如果该文件已经存在,在启动时,会导致进程号无法对应,最终启动失败,原理如下:
1、26385: 代表Postgres主进程的PID
2、/home/postgresql_data: 代表数据目录
3、5432: 代表数据库监听端口,在postgresql.conf中对应port = 5432
4、5432001 229376:代表的是共享内存的地址(shared memory segments中的key和shmid)。

Postgres启动失败问题分析与处理
很多企业使用开源的操作系统例如centos,也是用开源的数据库例如mysql或者postgres,在安装使用过程中经常出现一些不可预知的错误,导致安装失败或者启动失败等。
例如需要安装gcc 或者最新lib等,也有因为安全控件问题阻挡软件正常安装使用,或者有时平常运行好好的,突然重新启动竟然报错,让人捉摸不清问题原因。
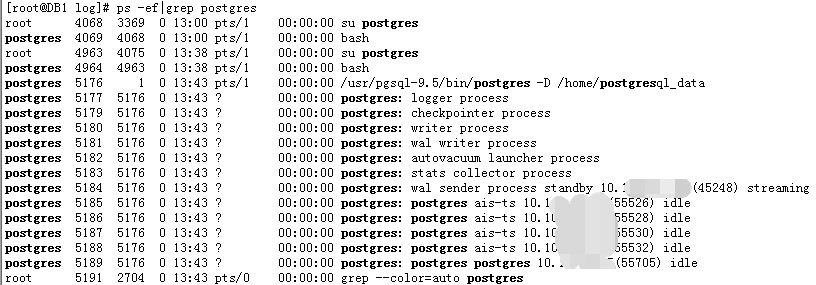
这两天客户一个系统使用postgres数据库,做了主从,但是因为断电问题导致主从数据同步出现问题,该项目经理让我帮忙分析处理,出于个人懒,
就找了17年帮他们项目组搭建的postgre现有设置好的主从测试开发环境,该环境持续运行一年半,一直没出现问题,我想模拟下,客户生产
故障,一个原因是模拟直接kill 主库进程,一个模拟强制断电关机看是否能正常启动,并自动主从数据同步,结果世事难料,在模拟直接kill掉进程后,竟然启动不了,具体错误如下:
看了半天错误信息,看到了ERROR: Unable to open policy etc/selinux/targeted/policy/policy.30.
[root@DB1 postgresql_data]# journalctl -xe
9月 27 12:43:59 DB1 dbus[784]: [system] Activating service name='org.fedoraproject.Setroubleshootd' (using servicehelper)
9月 27 12:43:59 DB1 dbus-daemon[784]: dbus[784]: [system] Activating service name='org.fedoraproject.Setroubleshootd' (using servicehelper)
9月 27 12:43:59 DB1 dbus-daemon[784]: ERROR: policydb version 30 does not match my version range 15-29
9月 27 12:43:59 DB1 dbus-daemon[784]: ERROR: Unable to open policy /etc/selinux/targeted/policy/policy.30.
9月 27 12:43:59 DB1 python[9716]: detected unhandled Python exception in '/usr/sbin/setroubleshootd'
9月 27 12:43:59 DB1 abrt-server[9721]: Not saving repeating crash in '/usr/sbin/setroubleshootd'
9月 27 12:43:59 DB1 dbus-daemon[784]: Traceback (most recent call last):
9月 27 12:43:59 DB1 dbus-daemon[784]: File "/usr/sbin/setroubleshootd", line 30, in <module>
9月 27 12:43:59 DB1 dbus-daemon[784]: from setroubleshoot.util import log_debug
9月 27 12:43:59 DB1 dbus-daemon[784]: File "/usr/lib64/python2.7/site-packages/setroubleshoot/util.py", line 291, in <module>
9月 27 12:43:59 DB1 dbus-daemon[784]: from sepolicy import get_all_file_types
9月 27 12:43:59 DB1 dbus-daemon[784]: File "/usr/lib64/python2.7/site-packages/sepolicy/init.py", line 798, in <module>
9月 27 12:43:59 DB1 dbus-daemon[784]: raise e
9月 27 12:43:59 DB1 dbus-daemon[784]: ValueError: Failed to read //etc/selinux/targeted/policy/policy.30 policy file
9月 27 12:43:59 DB1 dbus[784]: [system] Activated service 'org.fedoraproject.Setroubleshootd' failed: Launch helper exited with unknown return code 1
9月 27 12:43:59 DB1 dbus-daemon[784]: dbus[784]: [system] Activated service 'org.fedoraproject.Setroubleshootd' failed: Launch helper exited with unknown return code 1
9月 27 12:43:59 DB1 dbus-daemon[784]: dbus[784]: [system] Activating service name='org.fedoraproject.Setroubleshootd' (using servicehelper)
9月 27 12:43:59 DB1 dbus[784]: [system] Activating service name='org.fedoraproject.Setroubleshootd' (using servicehelper)
9月 27 12:43:59 DB1 fprintd[9127]: ** Message: No devices in use, exit
9月 27 12:43:59 DB1 dbus-daemon[784]: ERROR: policydb version 30 does not match my version range 15-29
9月 27 12:43:59 DB1 dbus-daemon[784]: ERROR: Unable to open policy //etc/selinux/targeted/policy/policy.30.
修改selinux 比较麻烦,时间有限,我选择流氓做法,直接设置SELINUX=disabled,然后在重新启动postgres,竟然报数据文件目录权限问题,如下:
9月 27 12:37:26 DB1 systemd[1]: Starting PostgreSQL 9.5 database server...
9月 27 12:37:26 DB1 pg_ctl[3560]: < 2018-09-27 12:37:26.211 CST >FATAL: data directory "/home/postgresql_data" has group or world access
9月 27 12:37:26 DB1 pg_ctl[3560]: < 2018-09-27 12:37:26.211 CST >DETAIL: Permissions should be u=rwx (0700).
9月 27 12:37:27 DB1 pg_ctl[3560]: pg_ctl: 无法启动服务器进程
9月 27 12:37:27 DB1 pg_ctl[3560]: 检查日志输出.
9月 27 12:37:27 DB1 systemd[1]: postgresql-9.5.service: control process exited, code=exited status=1
9月 27 12:37:27 DB1 systemd[1]: Failed to start PostgreSQL 9.5 database server.
9月 27 12:37:27 DB1 systemd[1]: Unit postgresql-9.5.service entered failed state.
9月 27 12:37:27 DB1 systemd[1]: postgresql-9.5.service failed.
根据错误信息提示,信息给得很详细,postgresql的数据文件权限被改了,现在不是0700(只有用户权限)。
重新 chmod 700 -R 赋权后重启,问题解决,启动成功,该数据库运行接近两年,一直相安无事,这次竟然报该错误信息。
如有任何问题,可到社区原文下评论交流
原文地址:
-
PostgreSQL数据库错误:检测到ShareLock死锁处理
http://www.talkwithtrend.com/Article/244327
-
postgres11.2版本客户端打开column "p.prolang"问题处理
http://www.talkwithtrend.com/Article/244473
-
postgres数据库大批量单表导入数据引发性能故障
http://www.talkwithtrend.com/Article/244493
-
postgres异常断电导致启动失败解决方法
http://www.talkwithtrend.com/Article/244507
-
postgres启动失败问题分析与处理
http://www.talkwithtrend.com/Article/244511
欢迎关注社区 “PostgreSQL”技术主题,将会不断更新优质资料、文章。地址:
http://www.talkwithtrend.com/Topic/112101