进行HIVE环境配置
1.上传相关的包

2.对上传的包进行下载和创建软连接
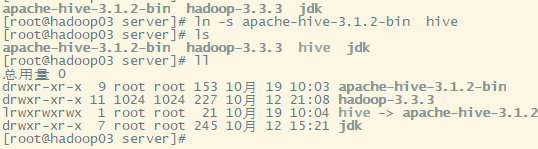
3.配置相关的文件
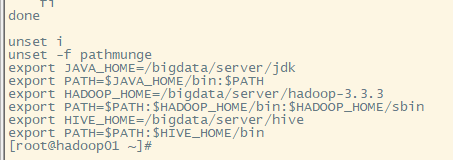
4.分别发送给其他机子
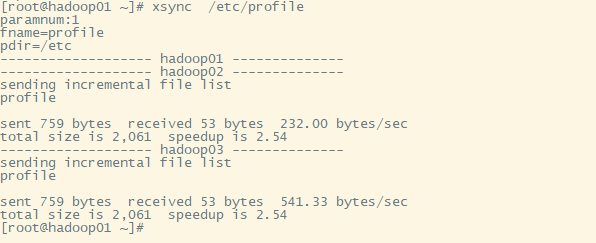
假设你需要在所有机器执行同一个指令,则你就需要相关设置
5.在hive的onf文件中创建hive-site.xml进行相关设置
```xml
<configuration>
<-- 元数据存储的数据库配置 -->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://biz01:3306/hive?useSSL=false</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
</property>
<-- 数据文件存储的目录配置 -->
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
<-- 去掉metastore的校验 -->
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
<-- 设置thrift的访问端口 hiveserver2 -->
<property>
<name>hive.server2.thrift.port</name>
<value>10000</value>
</property>
<-- 设置hiveserver2绑定的主机 -->
<property>
<name>hive.server2.thrift.bind.host</name>
<value>hadoop03</value>
</property>
<-- 禁用权限认证 -->
<property>
<name>hive.metastore.event.db.notification.api.auth</name>
<value>false</value>
</property>
<-- hive客户端配置, 显示表头信息 -->
<property>
<name>hive.cli.print.header</name>
<value>true</value>
</property>
<-- hive客户端配置, 显示当前数据库 -->
<property>
<name>hive.cli.print.current.db</name>
<value>true</value>
</property>
</configuration>
```
### 初始化元数据信息
```shell
schematool -initSchema -dbType mysql -verbose
```
设置好之后,进行创建数据库和创建表之类的操作
Spark环境配置
1.上传相关包

2.进行解压
vim conf/spark-env.sh
# spark-on 配置
export HADOOP_CONF_DIR=/bigdata/server/hadoop/etc/hadoop
export YARN_CONF_DIR=/bigdata/server/hadoop/etc/hadoop
# spark的classpath依赖配置
export SPARK_DIST_CLASSPATH=$(/bigdata/server/hadoop/bin/hadoop classpath)
spark.master=yarn
spark.eventLog.enabled=true
spark.eventLog.dir=hdfs://hadoop01:8020/spark/log
spark.executor.memory=1g
spark.driver.memory=1g



