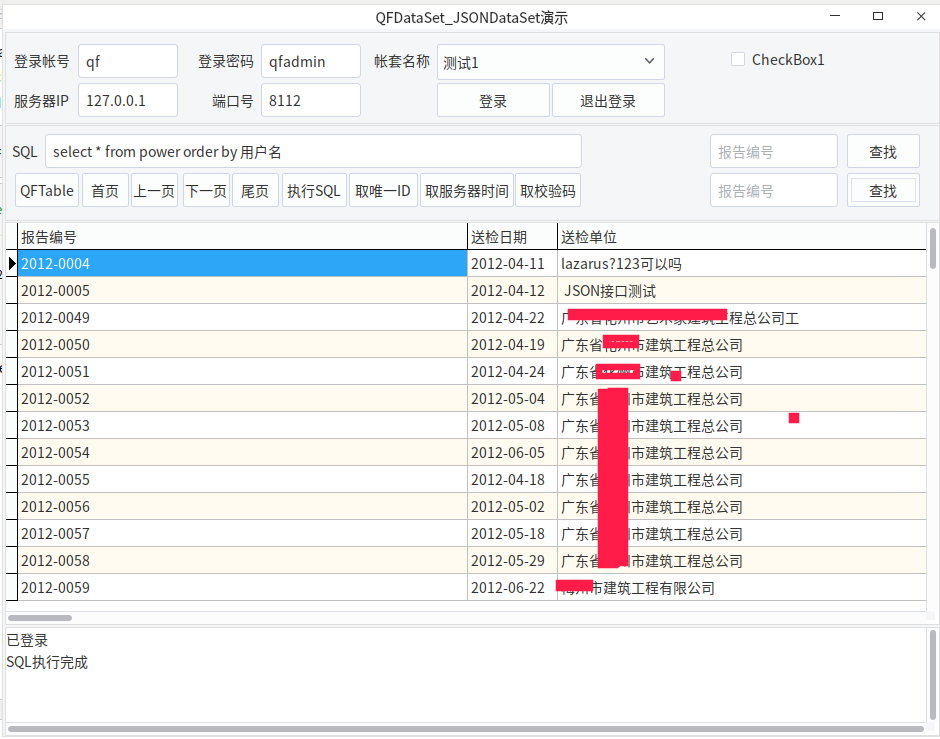
最近在使用fpc(lazarus)BufDataset的Filter使用中文字段名称时无效的问题,经跟踪Bufdataset源码时,发现Filter处理关键字时没正确读取中文引起的,处理起来也很简单:
打开/fpcsrc/packages/fcl-db/src/dbase/dbf_prsore.pas
定位837、870和872行,按以下添加#$80..#$FF,然后重新编译fpcsrc及应用程序就可以。
while (I2 <= Len) and (AnExpr[I2] in ['a'..'z', 'A'..'Z', '_', '0'..'9',#$80..#$FF]) do //第837行添加#$80..#$FF
// However string constants can also appear without delimiters 'a'..'z', 'A'..'Z', '_',#$80..#$FF://第870行添加#$80..#$FF begin while (I2 <= Len) and (AnExpr[I2] in ['a'..'z', 'A'..'Z', '_', '0'..'9',#$80..#$FF]) do //第872行添加#$80..#$FF Inc(I2); end;
修正后Bufdataset Filter已能正确处理含中文的字段: