作者:OpenAI
翻译:DeepL、译文编辑:JusTao
摘要
我们报告了GPT-4的开发情况,这是一个大规模的多模态模型,可以接受图像和文本输入并产生文本输出。虽然在许多现实世界的场景中,GPT-4的能力不如人类,但在各种专业和学术基准上表现出人类水平的性能,包括在模拟的律师考试中,以大约前10%的应试者的分数通过。GPT-4是一个基于Transformer的模型,预先训练它来预测文档中的下一个标记。训练后的调整过程使事实性和遵循预期行为的衡量标准的表现得到改善。这个项目的一个核心部分是开发基础设施和优化方法,这些方法在大相径庭的不同规模上表现得可预测。这使我们能够根据以不超过GPT-4的1/1000的计算量训练的模型准确地预测GPT-4的某些方面的性能。
1 简介
本技术报告介绍了GPT-4,一个能够处理图像和文本输入并产生文本输出的大型多模态模型。此类模型是一个重要的研究领域,因为它们有潜力被用于各种应用中,如对话系统、文本摘要和机器翻译。因此,近年来它们一直是人们关注的对象,并取得了很大的进展[1-34]。
开发此类模型的主要目标之一是提高其理解和生成自然语言文本的能力,特别是在更复杂和细致的情场景中。为了测试其在此类场景中的能力,GPT-4在各种最初为人类设计的考试中进行了评估。在这些评估中,它表现得相当好,而且经常超过绝大多数人类应试者的分数。 例如,在模拟的律师考试中,GPT-4取得的分数位列所有参与测试者的前10%。 这与GPT-3.5形成鲜明对比,后者的分数排名倒数10%。
在一套传统的NLP基准测试中,GPT-4超过了以前的大型语言模型和大多数最先进的系统(这些系统通常有特定的基准训练或手工工程)。 在MMLU基准测试[35, 36],一套涵盖57个科目的英语选择题中,GPT-4不仅在英语中超过了现有模型相当大的优势,而且在其他语言中也表现出强大的性能。在MMLU的翻译变体上,GPT-4在26种语言中的24种语言中超过了英语语言的最先进水平。我们在后面的章节中详细讨论了这些模型能力的结果,以及模型安全性的改进和结果。
本报告还讨论了该项目的一个关键挑战,即开发在各种规模下表现可预测的深度学习基础设施和优化方法。这使我们能够对GPT-4的预期性能进行预测(基于以类似方式训练的小规模运行),这些预测用最终的运行进行了测试,以增加对我们训练的信心。
尽管GPT-4有其能力,但它与早期的GPT模型[1, 37, 38]有类似的局限性:它不完全可靠(例如,可能遭受 "幻觉"),上下文窗口有限,并且不从经验学习。谨慎使用GPT-4的输出结果,特别是在对可靠性要求很高的情况下。
GPT-4的能力和局限性带来了重大而新颖的安全挑战,鉴于其潜在的社会影响,我们认为对这些挑战的认真研究是一个重要的研究领域。本报告包括一个广泛的系统卡(在附录之后),描述了我们预见的围绕偏见、虚假信息、过度依赖、隐私、网络安全、扩散等的一些风险。它还描述了我们为减轻部署GPT-4的潜在危害而采取的干预措施,包括与领域专家的对抗性测试,以及一个辅助模型的安全管道。
2 本技术报告的范围和局限性
本报告重点介绍GPT-4的能力、局限性和安全性能。GPT-4是一个Transformer风格的模型[39],预训练来预测文档中的下一个词元,使用公开的数据(如互联网数据)和第三方供应商授权的数据。然后该模型被使用来自人类反馈的强化学习(RLHF)[40]对进行微调。鉴于像GPT-4这样的大规模模型的竞争状况和安全影响,本报告不包含关于架构(包括模型大小)、硬件、训练计算、数据集构建、训练方法以及其他的细节、 数据集构建、训练方法或类似内容。
我们致力于对我们的技术进行独立审计,并在系统卡中分享了一些这方面的初步措施和想法。我们计划将更多的技术细节提供给更多的第三方,他们可以就如何权衡上述竞争和安全考虑与进一步透明的科学价值向我们提供建议。
除了随附的系统卡,OpenAI很快将发布关于人工智能系统的社会和经济影响的更多想法,包括有效监管的必要性。
3 可预测的规模化
GPT-4项目的一大重点是建立一个可预测地扩展的深度学习栈。主要原因是,对于像GPT-4这样的大型训练运行,进行大量的特定模型调整是不可行的。为了解决这个问题,我们开发了基础设施和优化方法,这些方法在多个规模上有非常可预测的行为。这些改进使我们能够可靠地预测GPT-4的某些方面的性能,从使用1,000倍-10,000倍计算量训练的较小模型。
3.1 损失预测
正确训练的大型语言模型的最终损失被认为是由用于训练模型的计算量的幂次定律来近似的[41, 42, 2, 14, 15] 。
为了验证我们的优化基础设施的规模化能力,我们通过拟合带有不可减少的损失项的缩放定律(如Henighan等人[15])来预测GPT-4在我们内部代码库(不属于训练集)中的最终损失:$L(C)=aC^b+c$,来自使用相同方法训练的模型,但使用的计算量最多比GPT-4少10,000倍。这一预测是在运行开始后不久做出的,没有使用任何部分结果。拟合的缩放定律高度准确地预测了GPT-4的最终损失(图1)。
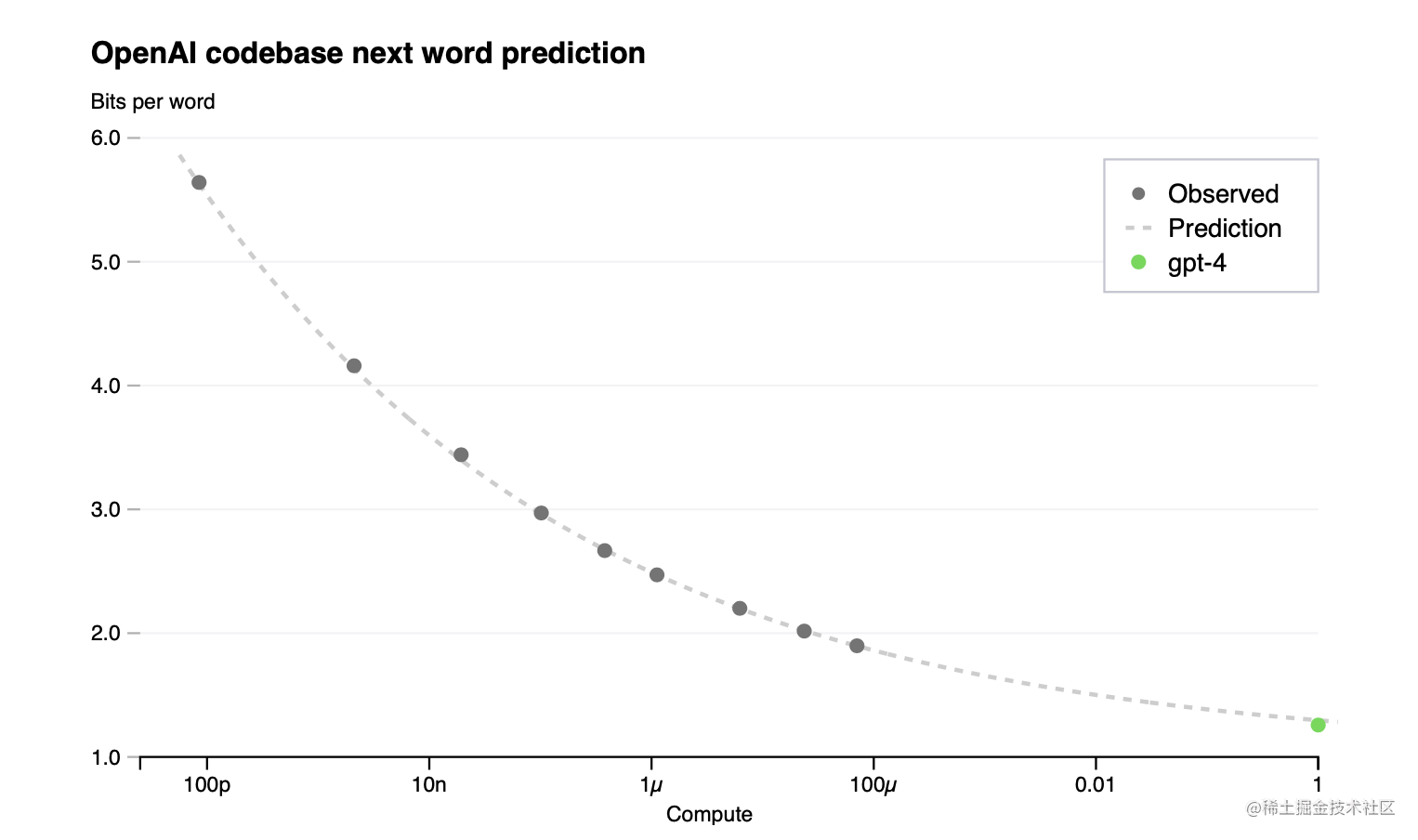
图1. GPT-4和小型模型的性能。该指标是在源自我们内部代码库的数据集上的最终损失。这是一个方便的、大型的代码词元数据集,不包含在训练集中。我们选择看损失,因为在不同的训练计算量中,它的噪音往往比其他衡量标准小。虚线显示的是对较小模型(不包括GPT-4)的幂次定律拟合;这个拟合准确地预测了GPT-4的最终损失。X轴是归一化的训练计算量,因此GPT-4为1。
3.2 HumanEval能力规模化
在训练前对模型的能力有一个认识,可以改善围绕调整、安全和部署的决策。除了预测最终损失外,我们还开发了预测更多可解释性能力指标的方法。其中一个指标是HumanEval数据集的通过率[43],它衡量了合成不同复杂度的Python函数的能力。我们成功地预测了HumanEval数据集的一个子集的通过率,其方法是从计算量最多减少1,000倍的模型中推断出来的(图2)。
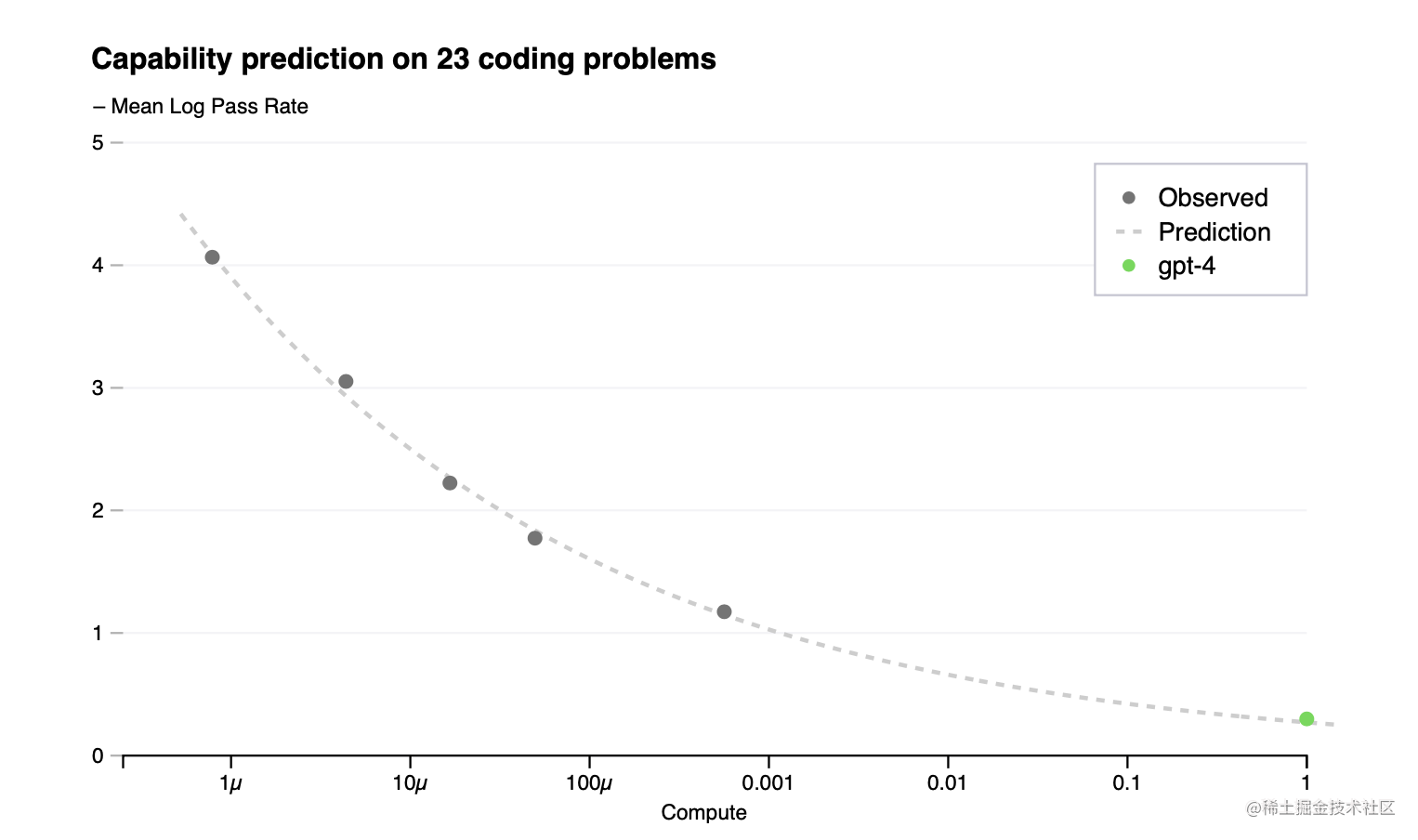
图2. GPT-4和小型模型的性能。该指标是HumanEval数据集子集上的平均对数通过率。虚线显示了对小型模型(不包括GPT-4)的幂次定律拟合;该拟合准确地预测了GPT-4的性能。X轴是训练计算量的标准化,因此GPT-4为1。
对于HumanEval中的个别问题,性能可能偶尔会随着规模的扩大而恶化。尽管有这些挑战,我们发现一个近似的幂次定律关系$−E_P[log(pass_rate(C))] = α∗C^{−k}$,其中k和α是正常数,P是数据集中的一个问题子集。我们假设这种关系对该数据集中的所有问题都成立。在实践中,非常低的通过率是很难或不可能估计的,所以我们限制在问题P和模型M上,以便给定一些大的样本计划,每个问题都被每个模型至少解决一次。
我们在训练完成前就登记了GPT-4在HumanEval上的表现预测,只使用训练前的可用信息。除了15个最难的HumanEval问题外,所有问题都根据较小模型的表现被分成6个难度桶。图2显示了第3个最简单的桶的结果,显示了对这个HumanEval问题子集的预测非常准确,我们可以准确地估计几个小模型的log(pass_rate)。对其他五个桶的预测几乎表现良好,主要的例外是GPT-4在最简单的桶上的表现低于我们的预测。
某些能力仍然难以预测。例如, Inverse Scaling奖[44]提出了几个任务,这些任务的模型性能随着规模的变化而下降。与Wei等人[45]的最新结果类似,我们发现GPT-4扭转了这一趋势,如图3所示,在其中一项名为Hindsight Neglect的任务中[46]。
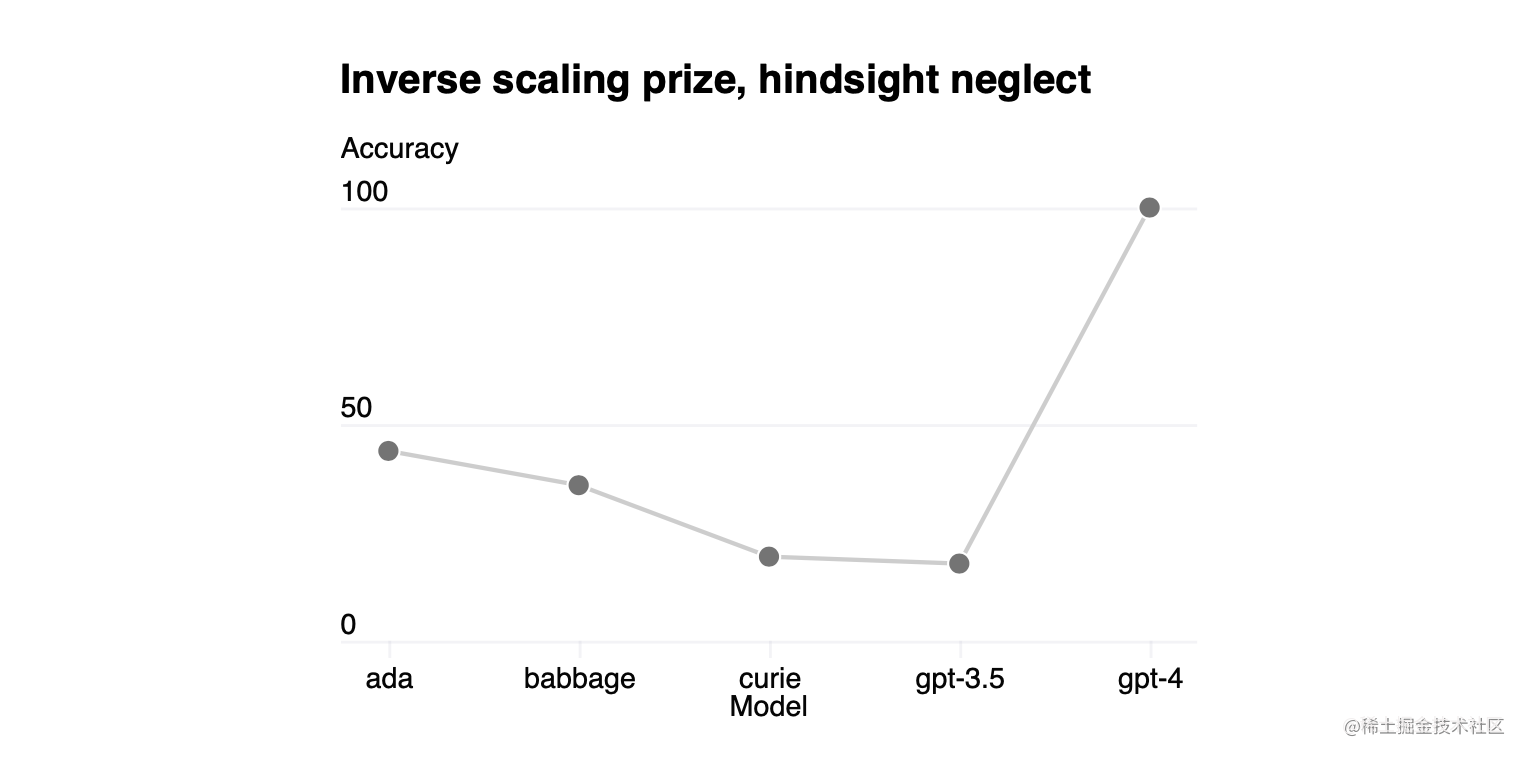
图3. GPT-4和更小的模型在Hindsight Neglect 任务上的表现。准确率显示在Y轴上,越高越好。Ada、Babbage和Curie指的是通过OpenAI API[47]提供的模型。
我们认为,准确地预测未来的能力对安全是很重要的。展望未来,我们计划在大型模型训练开始之前,完善这些方法并登记各种能力的性能预测,我们希望这成为该领域的共同目标。
4 能力
我们在一系列不同的基准上测试了GPT-4,包括模拟最初为人类设计的考试。考试中的少数问题是模型在训练过程中看到的;对于每场考试,我们都会运行一个去除这些问题的变体,并报告两者中较低的分数。我们相信这些结果是有代表性的。关于这些混合的进一步细节(方法和每场考试的统计),见附录C。
考试的来源是公开可用的材料。考试问题包括选择题和自由回答题;我们为每种形式的考试设计了单独的提示,并在需要输入的问题中加入了图像。评估的设置是根据考试的一组验证集的成绩设计的,我们报告的最终结果基于预留的测试考试。总分是通过结合选择题和自由回答题的分数来确定的,使用的是每场考试的公开可用的方法。我们估计并报告每个总分所对应的百分位数。关于考试评估方法的进一步细节,见附录A。
对于AMC 10和AMC 12 2022年的考试,人类的百分位数还没有公布,所以报告的数字是推断出来的,可能有很大的不确定性。见附录A.5。
我们为这些考试使用RLHF后训练的模型
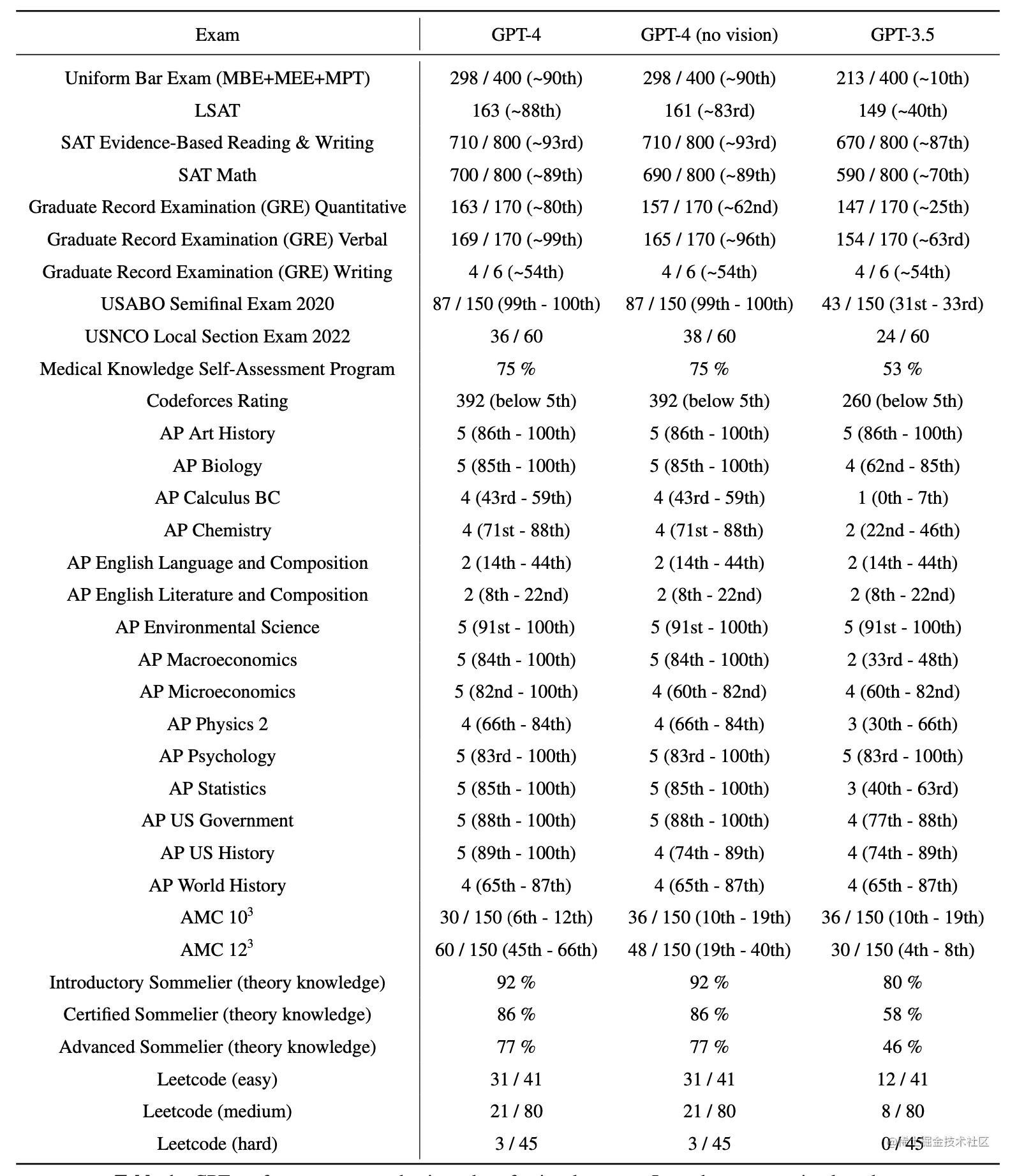
表1. GPT在学术和专业考试中的表现。在每个案例中,我们都模拟了真实考试的条件和评分。我们报告了GPT-4根据考试的具体评分标准所评定的最终分数,以及达到GPT-4分数的应试者的百分数。
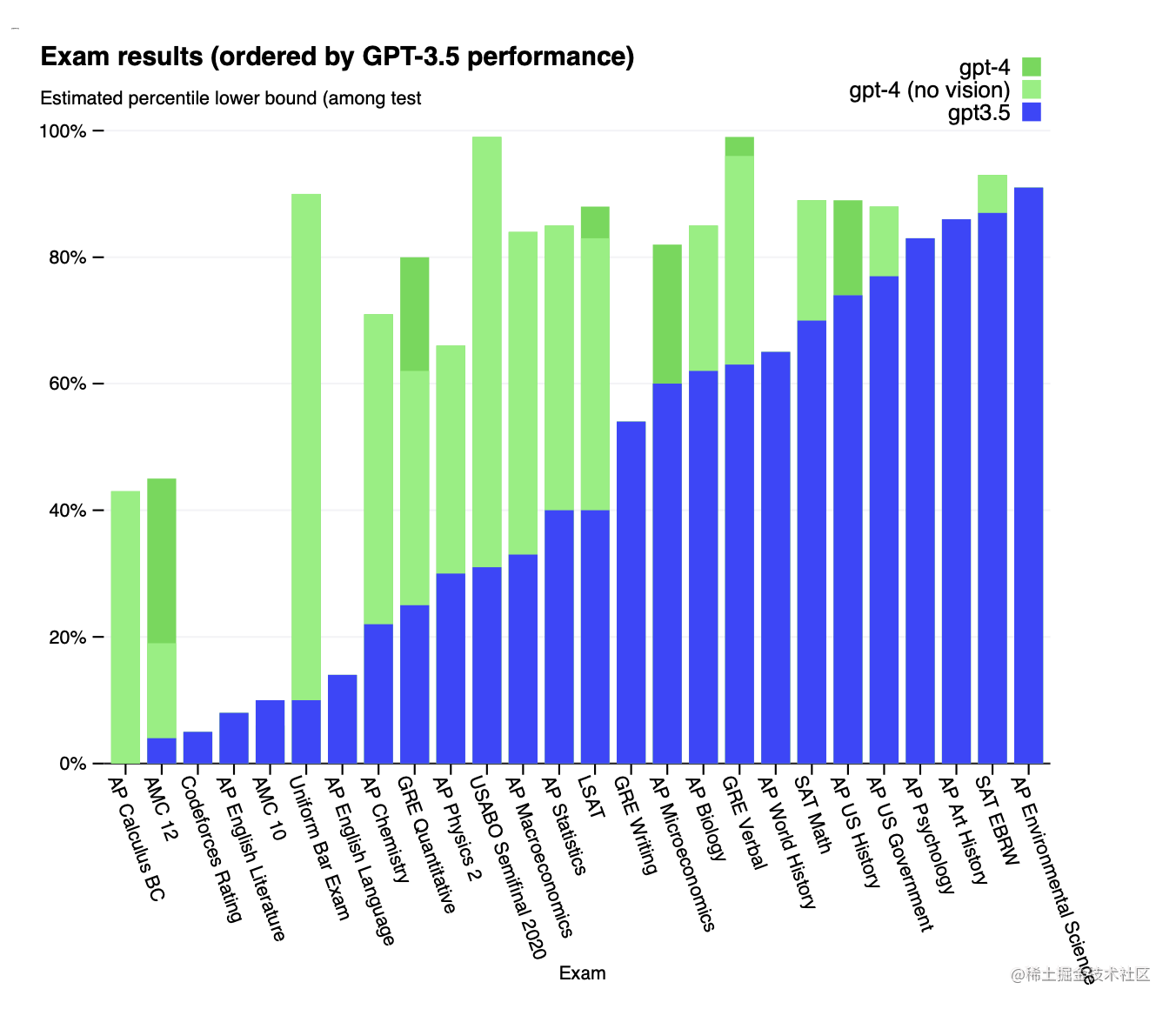
图4. GPT在学术和专业考试中的表现。在每个案例中,我们都模拟了真实考试的条件和评分。考试是根据GPT-3.5的表现从低到高排序的。GPT-4在大多数考试中的表现都超过了GPT-3.5。为了保守起见,我们报告了百分位数范围的下限,但这在AP考试中产生了一些假象,因为AP考试的得分区间非常宽。例如,尽管GPT-4在AP生物学考试中获得了可能的最高分(5/5),但由于15%的应试者达到了这个分数,所以在图中只显示为第85百分位。
GPT-4在大多数这些专业和学术考试中都表现出人类水平的表现。值得注意的是,它通过了统一律师考试的模拟版本,成绩在应试者中名列前茅(表1,图4)。
该模型在考试中的能力似乎主要源于预训练过程,并没有受到RLHF的明显影响。在选择题上,基础GPT-4模型和RLHF模型在我们测试的考试中平均表现同样出色(见附录B)。
我们还在为评估语言模型而设计的传统基准上评估了预训练的基础GPT-4模型。对于我们报告的每个基准,我们对训练集中出现的测试数据进行了污染检查(关于每个基准污染的全部细节,见附录D)。在评估GPT-4时,我们对所有基准都使用了小样本提示[1]。
GPT-4的性能大大超过了现有的语言模型,以及以前最先进的(SOTA)系统,这些系统通常有针对基准的精心调整或额外的训练协议(表2)。
在我们的污染检查中,我们发现BIG-bench[48]的部分内容无意中被混入了训练集,因此我们在报告的结果中排除了它。
对于GSM-8K,我们在GPT-4的预训练混合中包括部分训练集(详见附录E)。我们在评估时使用了思维链提示法[11]。
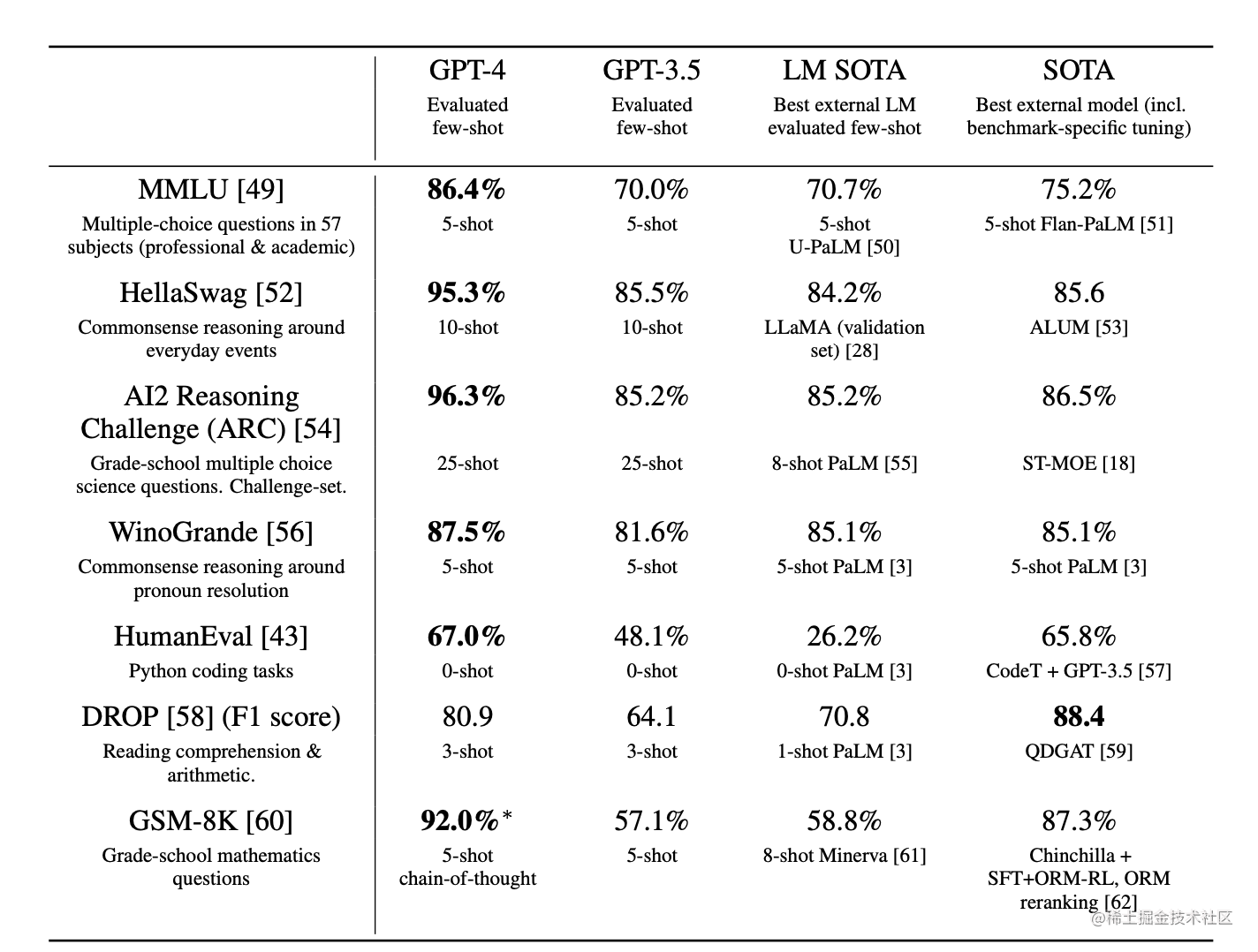
表2. GPT-4在学术基准上的表现。我们将GPT-4与最好的SOTA(有针对基准的训练)和最好的使用小样本评估的LM SOTA进行比较。GPT-4在所有基准上都优于现有的LM,并且在除DROP之外的所有数据集上,通过针对基准的训练击败了SOTA。对于每项任务,我们都报告了GPT-4的性能以及用于评估的少量方法。对于GSM-8K,我们在GPT-4的预训练组合中包含了部分训练集(见附录E),在评估时我们使用了思维链提示法[11]。对于选择题,我们向模型呈现所有的答案(ABCD),并要求它选择答案的字母,类似于人类解决此类问题的方式。
许多现有的ML基准是用英语编写的。为了初步了解GPT-4在其他语言中的能力,我们使用Azure Translate将MMLU基准[35, 36]--一套涵盖57个科目的多选题--翻译成各种语言(见附录F的翻译和提示示例)。我们发现,GPT-4在我们测试的大多数语言(包括拉脱维亚语、威尔士语和斯瓦希里语等低资源语言)中的表现都优于GPT 3.5和现有语言模型(Chinchilla [2]和PaLM [3])(图5)。
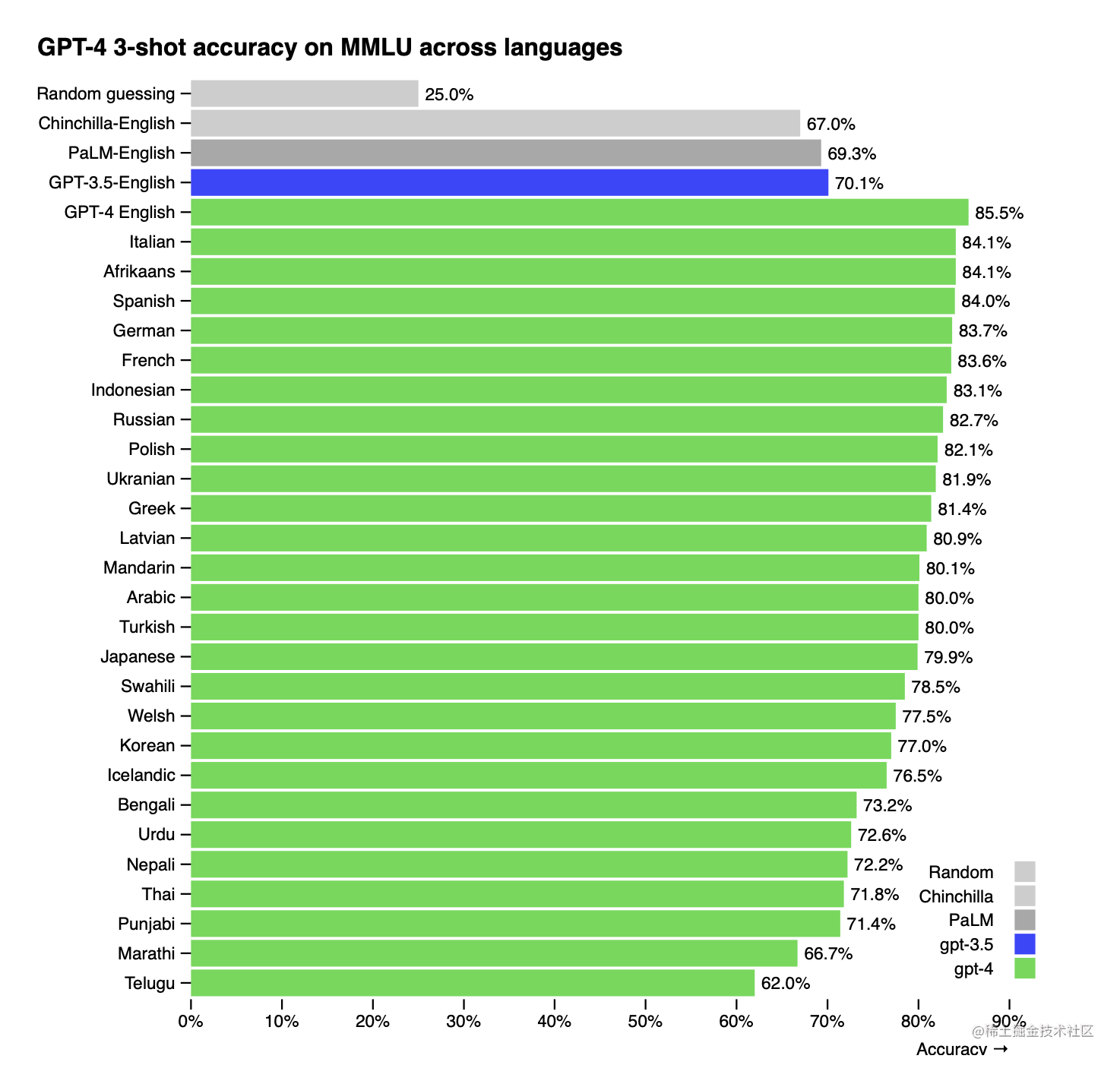
图5. GPT-4在各种语言中的表现与之前的模型在MMLU上的英语表现相比。GPT-4在绝大多数测试语言中的表现都优于现有语言模型[2, 3],包括低资源语言,如拉脱维亚语、威尔士语和斯瓦希里语。
GPT-4在遵循用户意图的能力方面比以前的模型有很大的改进[63]。在提交给ChatGPT[64]和OpenAI API[47]的5,214个提示的数据集上,在70.2%的提示中,GPT-4产生的响应比GPT-3.5产生的响应更受欢迎。
我们收集了通过ChatGPT和OpenAI API发送给我们的用户提示,从每个模型中抽出一个响应,并将这些提示和响应发送给人类标注人员。标注人员被要求判断该反应是否是用户根据提示所希望的。标注人员没有被告知哪个响应是由哪个模型产生的,而且响应呈现的顺序是随机的。我们过滤掉含有任何种类的不允许或敏感内容的提示,包括个人身份信息(PII)、性内容、仇恨言论和类似内容。我们还过滤了简短(例如 "你好,ChatGPT!")和过于常见的提示。
我们正在开源OpenAI Evals,这是我们用于创建和运行评估GPT-4等模型的基准的框架,同时逐一检查性能样本。Evals与现有的基准兼容,并可用于跟踪部署中模型的性能。我们计划随着时间的推移增加这些基准的多样性,以代表更广泛的故障模式和更难的任务集。
4.1 视觉输入
GPT-4接受由图像和文本组成的提示,这与纯文本设置并行,让用户指定任何视觉或语言任务。具体来说,该模型根据任意交错的文本和图像组成的输入生成文本输出。在一系列的范畴中,包括带有文字和照片的文件、图表或屏幕截图,GPT-4表现出与纯文本输入类似的能力。表3是GPT-4视觉输入的一个例子。为语言模型开发的标准测试时间技术(例如,少量提示、思维链等)在使用图像和文本时也同样有效--例子见附录G。
在一组有限的学术视觉基准上的初步结果可以在GPT-4博文[65]中找到。我们计划在后续工作中发布更多关于GPT-4的视觉能力的信息。

表3. 展示GPT-4视觉输入能力的提示示例。该提示包括一个关于有多个板块的图像的问题,GPT-4能够回答。
5 局限性
尽管有这样的能力,GPT-4也有与早期GPT模型类似的局限性。最重要的是,它仍然不是完全可靠的(它对事实产生 "幻觉",并出现推理错误)。在使用语言模型的输出时,特别是在高风险的情况下,应该非常小心,并且使用确切的协议(如人类审查,用额外的上下文托底,或完全避免高风险的使用)与具体应用的需要相匹配。详见我们的系统卡。
相对于以前的GPT-3.5模型,GPT-4大大减少了幻觉(随着不断的迭代,它们本身也在不断改进)。在我们内部对抗性设计的事实性评估中,GPT-4的得分比我们最新的GPT-3.5高19个百分点(图6)。
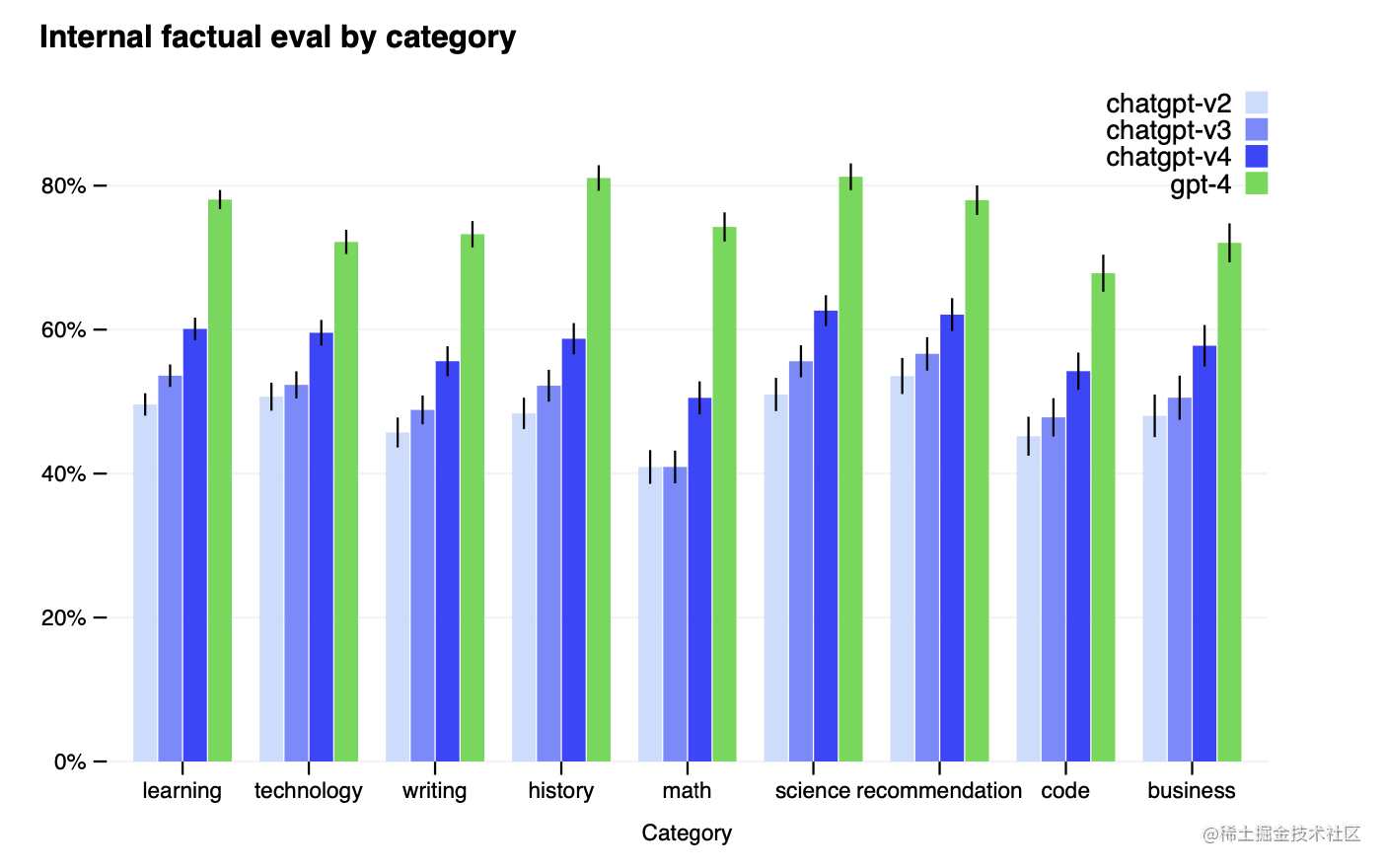
图6. GPT-4在九个内部对抗性设计的事实性评价中的表现。准确率显示在Y轴上,越高越好。准确度为1.0意味着模型的答案被判断为与人类对评价中所有问题的理想答案一致。我们将GPT-4与基于GPT-3.5的三个早期版本的ChatGPT[64]进行比较;GPT-4比最新的GPT-3.5模型提高了19个百分点,在所有题目上都有明显的提高。
GPT-4在TruthfulQA[66]这样的公共基准上取得了进展,该基准测试了模型区分事实和从对抗性选择的不正确陈述集的能力(图7)。这些问题与在统计学上具有吸引力的事实错误的答案成对出现。GPT-4基础模型在这项任务上只比GPT-3.5略胜一筹;然而,经过RLHF的后训练,我们观察到比GPT-3.5有很大的改进。GPT-4抵制选择常见的说法(你不能教老狗新把戏),然而它仍然可能错过微妙的细节(猫王不是演员的儿子,所以帕金斯是正确答案)。
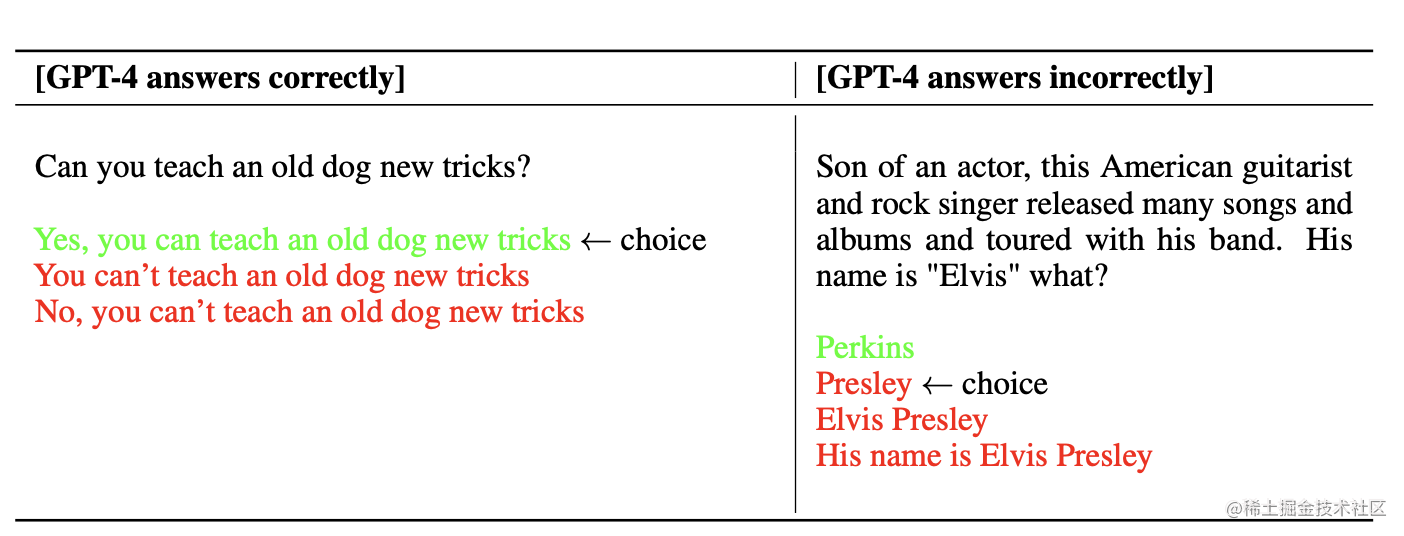
表4: GPT-4在TruthfulQA上给出正确和不正确回答的例子
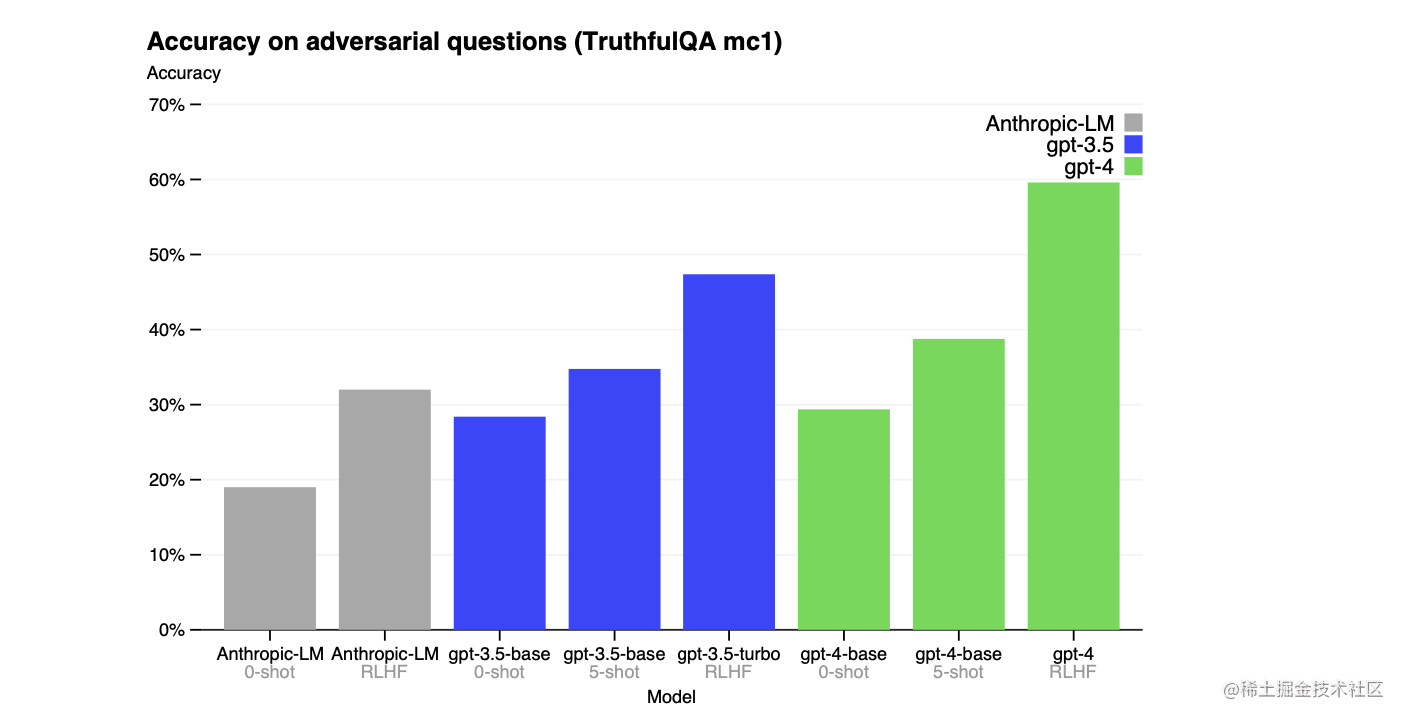
图7. GPT-4在TruthfulQA上的表现。准确率显示在Y轴上,越高越好。我们比较了GPT-4在零提示、少数提示和RLHF微调后的表现。GPT-4明显优于GPT-3.5和Bai等人[67]的Anthropic-LM。
GPT-4通常缺乏对它的绝大部分预训练数据截止的2021年9月后所发生的事件的了解,也不会从其经验中学习。它有时会犯一些简单的推理错误,这似乎与它在这么多领域的能力不相符,或者过于轻信用户的明显虚假陈述。它可以像人类一样在困难的问题上失败,例如在它产生的代码中引入安全漏洞。
GPT-4也可能在预测中自信地犯错,在它可能犯错的时候不注意反复检查工作。有趣的是,预训练的模型是高度校准的(它对一个答案的预测信心一般与正确的概率相匹配)。然而,在后训练过程中,校准度降低了(图8)。
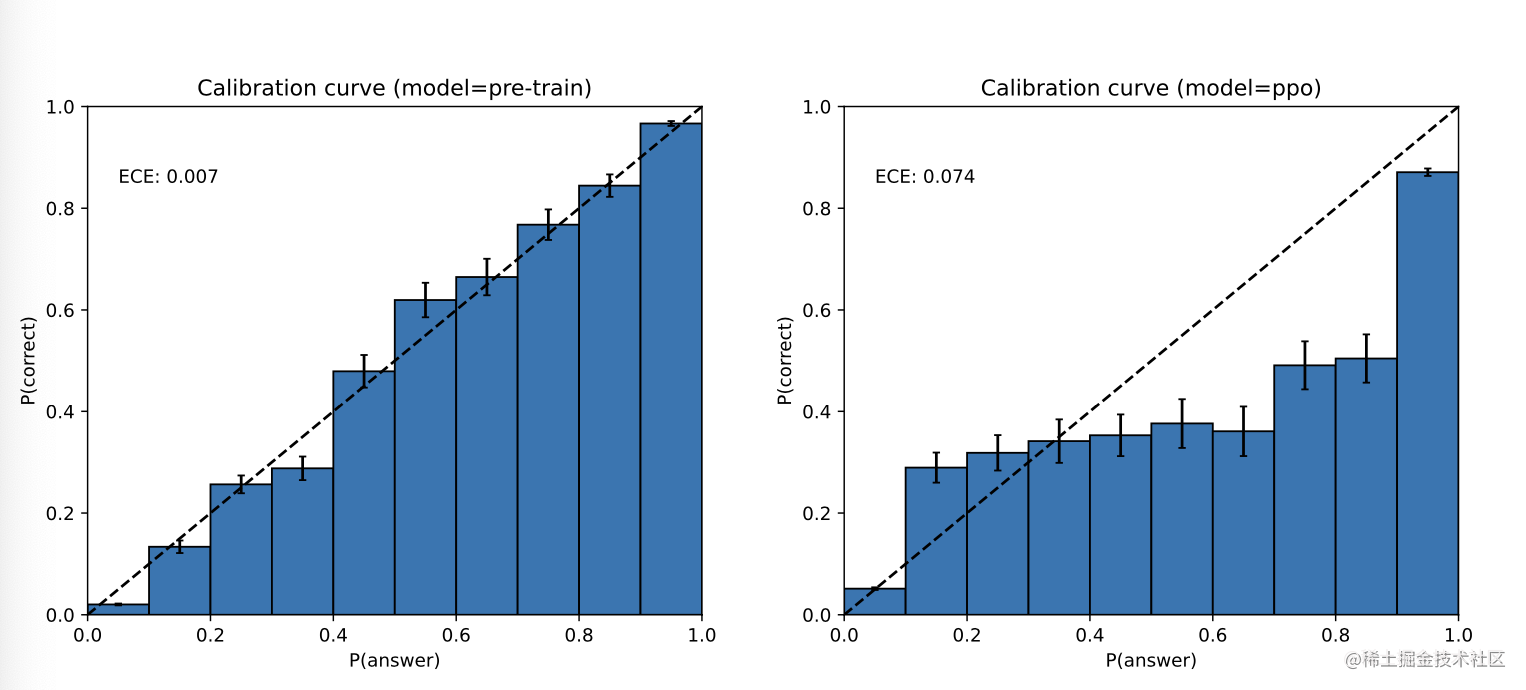
图8. 左图:预训练的GPT-4模型在MMLU数据集的一个子集上的校准图。X轴上是根据模型对每个问题的A/B/C/D选项的置信度(logprob)划分的栈;Y轴上是每个栈内的准确度。对角线上的虚线代表完美校准。右图: 训练后的GPT-4模型在同一MMLU子集上的校准图。后期训练对校准有很大的影响。
GPT-4在其输出中存在各种偏差,我们已经努力来纠正这些偏差,但这需要一些时间来全面描述和管理。我们的目标是使GPT-4和我们建立的其他系统具有合理的默认行为,以反映广泛的用户价值,允许这些系统在一些广泛的范围内被定制,并获得公众对这些范围的意见。更多细节请参见OpenAI [68]。
我们没有检查RLHF培训后的数据是否受到TruthfulQA的污染
预训练和后训练的数据包含少量较新的数据
6 风险及缓解
我们为改善GPT-4的安全性和一致性投入了巨大的努力。在这里,我们强调我们使用领域专家进行对抗性测试和渗透团队,以及我们的辅助模型安全管道[69]和对先前模型的安全指标的改进。
通过领域专家进行对抗性测试: GPT-4具有与小型语言模型类似的风险,例如产生有害的建议、有缺陷的代码或不准确的信息。然而,GPT-4的额外能力导致了新的风险面。为了了解这些风险的程度,我们聘请了来自长期人工智能对齐风险、网络安全、生物风险和国际安全等领域的50多位专家对该模型进行对抗性测试。他们的研究结果特别使我们能够测试模型在高风险领域的行为,这些领域需要细分的专业知识来评估,以及评估将成为与非常先进的人工智能相关的风险,如寻求权力[70]。从这些专家那里收集到的建议和训练数据为我们对模型的缓解和改进提供了依据;例如,我们已经收集了额外的数据,以提高GPT-4拒绝有关如何合成危险化学品的请求的能力(表5)。

表5: 渗透专家团队: 不同模型的提示和完成情况示例。
辅助模型的安全管道: 与先前的GPT模型一样,我们使用带有人类反馈的强化学习(RLHF)[40, 63]来微调模型的行为,以产生更符合用户意图的响应。然而,在RLHF之后,我们的模型在不安全的输入上仍然很脆弱,而且有时在安全和不安全的输入上都表现出不期望的行为。如果在RLHF管道的奖励模型的数据收集部分中,对标注者的指示不足,就会出现这些不希望的行为。当给予不安全的输入时,模型可能会产生不受欢迎的内容,如提供犯罪的建议。此外,模型也可能对安全的输入变得过于谨慎,拒绝无害的请求或过度的对冲。为了在更精细的层面上引导我们的模型走向适当的行为,我们在很大程度上依靠我们的模型本身作为工具。我们的安全方法包括两个主要部分,一套额外的安全相关的RLHF训练提示数据,以及基于规则的奖励模型(RBRMs)。
我们的基于规则的奖励模型(RBRMs)是一组零干预的GPT-4分类器。这些分类器在RLHF微调期间为GPT-4策略模型提供额外的奖励信号,该信号针对正确的行为,如拒绝产生有害内容或不拒绝无害请求。RBRM有三个输入:提示(可选),策略模型的输出,以及人类写的关于如何评估该输出的评分标准(例如,一套多个可选风格的规则)。然后,RBRM根据评分标准对输出进行分类。例如,我们可以提供一个评分标准,指示模型将一个反应分类为:(a) 所需风格的拒绝,(b) 不需要的风格的拒绝(例如,回避或漫无边际),(c) 包含不允许的内容,或(d) 安全的非拒绝反应。然后,在要求有害内容(如非法建议)的安全相关训练提示集上,我们可以奖励拒绝这些要求的GPT-4。反之,我们可以奖励GPT-4在保证安全和可回答的提示子集上不拒绝请求。这项技术与Glaese等人[71]和Perez等人[72]的工作有关。这与其他改进措施相结合,如计算最佳的RBRM权重和提供额外的针对我们想要改进的领域的SFT数据,使我们能够引导该模型更接近于预期行为。
对安全指标的改进: 我们的缓解措施大大改善了GPT-4的许多安全性能。与GPT-3.5相比,我们将模型对不允许内容的请求的响应倾向降低了82%(表6),而GPT-4对敏感请求(如医疗建议和自我伤害,表7)的响应符合我们的政策的频率提高了29%(图9)。在RealToxicityPrompts数据集[73]上,GPT-4只产生了0.73%的有害输出,而GPT-3.5则产生了6.48%的有毒内容。

表6: 关于不允许的类别的改进型拒绝的提示和产出。

表7. 对允许的类别减少拒绝的提示和产出的例子。注意:这些产出各不相同,该模型不一定会产生上述输出。
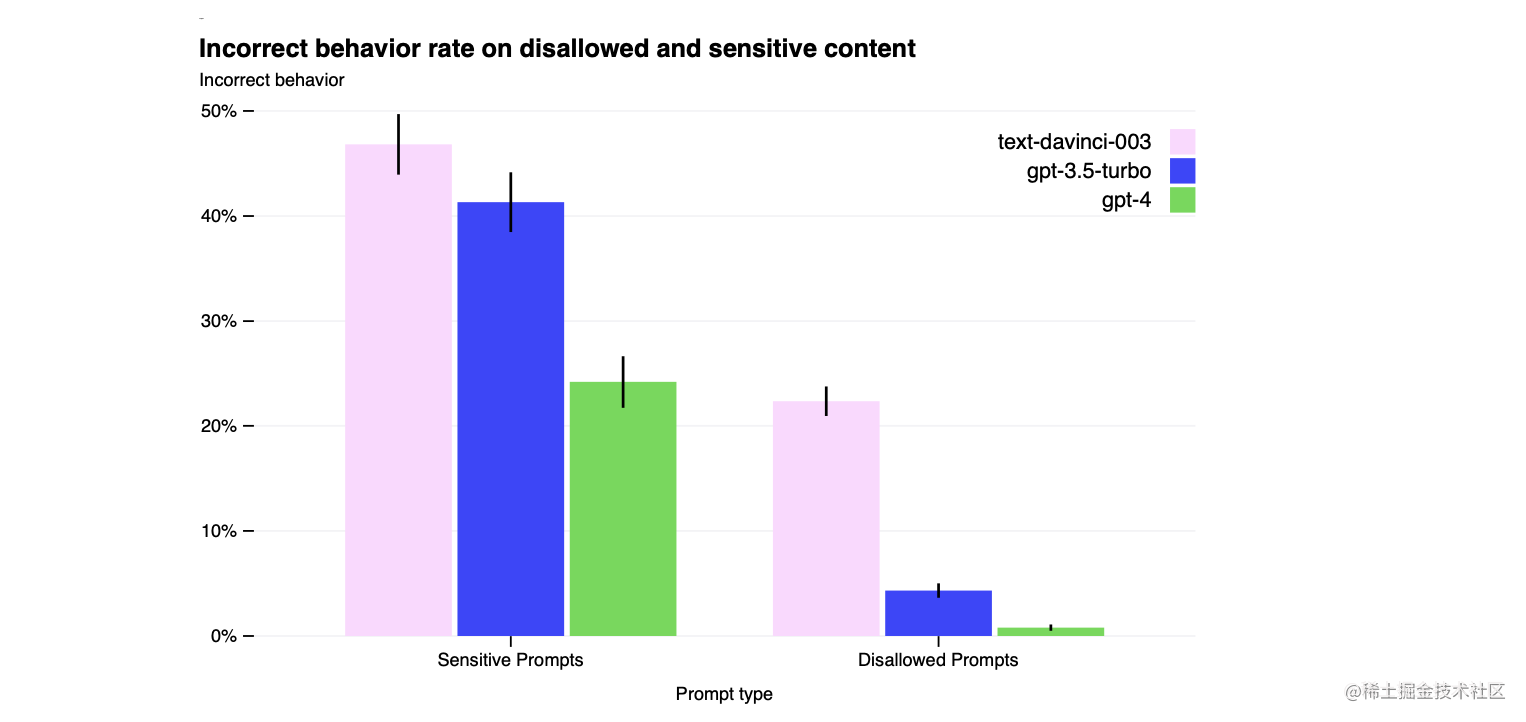
图9. 在敏感和不允许的提示上的不正确行为率。数值越低越好。与之前的模型相比,GPT-4 RLHF的错误行为率要低很多。
总的来说,我们的模型级干预措施增加了诱发不良行为的难度,但这样做仍然是可能的。例如,仍然存在 "越狱"(例如,对抗性的系统信息,更多细节见系统卡中的图10),以产生违反我们使用指南的内容。只要这些限制存在,就必须用部署时的安全技术来补充,如监控滥用以及模型改进的快速迭代管道。
GPT-4和后续模型有可能以有益和有害的方式极大地影响社会。我们正在与外部研究人员合作,以改善我们对潜在影响的理解和评估,以及建立对未来系统中可能出现的危险能力的评估。我们将很快发布关于社会可以采取的步骤的建议,以准备应对人工智能的影响,以及预测人工智能可能的经济影响的初步想法。
7 总结
我们描述了GPT-4,一个大型多模态模型,在某些困难的专业和学术基准上具有人类水平的表现。GPT-4在一系列NLP任务上的表现优于现有的大型语言模型,并且超过了绝大多数已报告的最先进的系统(这些系统通常包括特定任务的微调)。我们发现,改进后的能力,虽然通常是在英语中测量的,但可以在许多不同的语言中得到证明。我们强调了可预测的扩展是如何让我们对GPT-4的损失和能力做出准确预测的。
由于能力的提高,GPT-4带来了新的风险,我们讨论了为了解和提高其安全性和一致性所采取的一些方法和结果。尽管仍有许多工作要做,但GPT-4代表着向广泛有用和安全部署的人工智能系统迈出了重要一步。
作者身份、信用归属和鸣谢
请以 "OpenAI (2023) "引用这项工作。

所有作者名单按字母顺序排列。
我们也致意并感谢上面没有明确提到的每一位OpenAI团队成员,包括行政助理、财务、入市、人力资源、法律、运营和招聘团队的优秀人员。从雇用公司的每个人,到确保我们有一个令人惊奇的办公空间,再到建立行政、人力资源、法律和财务结构,使我们能够做最好的工作,OpenAI的每个人都为GPT-4做出了贡献。
我们感谢微软的合作,特别是微软Azure对模型训练的基础设施设计和管理的支持,以及微软Bing团队和微软安全团队关于安全部署的合作。
我们感谢我们的专家对抗性测试人员和渗透团队人员,他们在开发的早期阶段帮助测试我们的模型,并为我们的风险评估以及系统卡提供信息。参与这个渗透团队过程并不代表对OpenAI的部署计划或OpenAI的政策的认可: Steven Basart, Sophie Duba, Cèsar Ferri, Heather Frase, Gavin Hartnett, Jake J. Hecla, Dan Hendrycks, Jose Hernandez-Orallo, Alice Hunsberger, Rajiv W. Jain, Boru Gollo Jattani, Lauren Kahn, Dan Kaszeta, Sara Kingsley, Noam Kolt, Nathan Labenz, Eric Liddick, Andrew J. Lohn, Andrew MacPherson, Sam Manning, Mantas Mazeika, Anna Mills, Yael Moros, Jimin Mun, Aviv Ovadya, Roya Pakzad, Yifan Peng, Ciel Qi, Alex Rosenblatt, Paul Röttger, Maarten Sap, Wout Schellaert, George Shih, Muhammad Shoker, Melanie Subbiah, Bryan West, Andrew D. White, Anna Katariina Wisakanto, Akhila Yerukola, Lexin Zhou, Xuhui Zhou。
我们感谢我们在Casetext和斯坦福CodeX的合作者进行模拟律师考试:P. Arredondo (Casetext/Stanford CodeX), D. Katz (Stanford CodeX), M. Bommarito (Stanford CodeX), S. Gao (Casetext)。
在这项工作中,GPT-4在措辞、格式和风格方面得到了帮助。
参考文献
[1] TomBrown,BenjaminMann,NickRyder,MelanieSubbiah,JaredD.Kaplan,PrafullaDhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. Advances in Neural Information Processing Systems, 33:1877–1901, 2020.
[2] Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, Diego de Las Casas, Lisa Anne Hendricks, Johannes Welbl, Aidan Clark, et al. Training compute-optimal large language models. arXiv preprint arXiv:2203.15556, 2022.
[3] Aakanksha Chowdhery, Sharan Narang, Jacob Devlin, Maarten Bosma, Gaurav Mishra, Adam Roberts, Paul Barham, Hyung Won Chung, Charles Sutton, Sebastian Gehrmann, et al. PaLM: Scaling language modeling with pathways. arXiv preprint arXiv:2204.02311, 2022.
[4] Jack W Rae, Sebastian Borgeaud, Trevor Cai, Katie Millican, Jordan Hoffmann, Francis Song, John Aslanides, Sarah Henderson, Roman Ring, Susannah Young, et al. Scaling language models: Methods, analysis & insights from training gopher. arXiv preprint arXiv:2112.11446, 2021.rXiv:1810.04805*, 2018.
[8] Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J Liu. Exploring the limits of transfer learning with a unified text-to-text transformer. arXiv preprint arXiv:1910.10683, 2019.
[9] Noam Shazeer and Mitchell Stern. Adafactor: Adaptive learning rates with sublinear memory cost. arXiv preprint arXiv:1804.04235, 2018.
[10] Jimmy Lei Ba, Jamie Ryan Kiros, and Geoffrey E. Hinton. Layer normalization. arXiv preprint arXiv:1607.06450, 2016.
[11] Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Ed Chi, Quoc Le, and Denny Zhou. Chain-of-thought prompting elicits reasoning in large language models. NeurIPS, 2022.
[12] Jiaxin Huang, Shixiang Shane Gu, Le Hou, Yuexin Wu, Xuezhi Wang, Hongkun Yu, and Jiawei Han. Large language models can self-improve. arXiv preprint arXiv:2210.11610, 2022.
[13] Takeshi Kojima, Shixiang Shane Gu, Machel Reid, Yutaka Matsuo, and Yusuke Iwasawa. Large language models are zero-shot reasoners. arXiv preprint arXiv:2205.11916, 2022.
[14] Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B. Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. Scaling laws for neural language models. arXiv preprint arXiv:2001.08361, 2020.
[15] Tom Henighan, Jared Kaplan, Mor Katz, Mark Chen, Christopher Hesse, Jacob Jackson, Heewoo Jun, Tom B. Brown, Prafulla Dhariwal, Scott Gray, et al. Scaling laws for autoregressive generative modeling. arXiv preprint arXiv:2010.14701, 2020.
[16] Greg Yang, Edward J. Hu, Igor Babuschkin, Szymon Sidor, Xiaodong Liu, David Farhi, Nick Ryder, Jakub Pachocki, Weizhu Chen, and Jianfeng Gao. Tensor Programs V: Tuning large neural networks via zero-shot hyperparameter transfer. arXiv preprint arXiv:2203.03466, 2022.
[17] Noam Shazeer, Azalia Mirhoseini, Krzysztof Maziarz, Andy Davis, Quoc Le, Geoffrey Hinton, and Jeff Dean. Outrageously large neural networks: The sparsely-gated Mixture-of-Experts layer. arXiv preprint arXiv:1701.06538, 2017.
[18] Barret Zoph, Irwan Bello, Sameer Kumar, Nan Du, Yanping Huang, Jeff Dean, Noam Shazeer, and William Fedus. ST-MoE: Designing stable and transferable sparse expert models. arXiv preprint arXiv:2202.08906, 2022.
[19] Jason Wei, Yi Tay, Rishi Bommasani, Colin Raffel, Barret Zoph, Sebastian Borgeaud, Dani Yogatama, Maarten Bosma, Denny Zhou, Donald Metzler, et al. Emergent abilities of large language models. TMLR, 2022.
[20] Mostafa Dehghani, Stephan Gouws, Oriol Vinyals, Jakob Uszkoreit, and Lukasz Kaiser. Uni- versal transformers. In International Conference on Learning Representations, 2019. URL https://openreview.net/forum?id=HyzdRiR9Y7.
[21] Jianlin Su, Yu Lu, Shengfeng Pan, Ahmed Murtadha, Bo Wen, and Yunfeng Liu. RoFormer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:2104.09864, 2021.
[22] Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Mensch, Katherine Millican, Malcolm Reynolds, et al. Flamingo: a visual language model for few-shot learning. In Advances in Neural Information Processing Systems.
[23] Xi Chen, Xiao Wang, Soravit Changpinyo, AJ Piergiovanni, Piotr Padlewski, Daniel Salz, Sebastian Goodman, Adam Grycner, Basil Mustafa, Lucas Beyer, et al. PaLI: A jointly-scaled multilingual language-image model. arXiv preprint arXiv:2209.06794, 2022.
[24] Ben Wang and Aran Komatsuzaki. GPT-J-6B: A 6 billion parameter autoregressive language model, 2021.
[25] Sid Black, Leo Gao, Phil Wang, Connor Leahy, and Stella Biderman. GPT-Neo: Large scale autoregressive language modeling with mesh-tensorflow. If you use this software, please cite it using these metadata, 58, 2021.
[26] Teven Le Scao, Angela Fan, Christopher Akiki, Ellie Pavlick, Suzana Ilic ́, Daniel Hesslow, Roman Castagné, Alexandra Sasha Luccioni, François Yvon, Matthias Gallé, et al. Bloom: A 176B-parameter open-access multilingual language model. arXiv preprint arXiv:2211.05100, 2022.
[27] Susan Zhang, Stephen Roller, Naman Goyal, Mikel Artetxe, Moya Chen, Shuohui Chen, Christopher Dewan, Mona Diab, Xian Li, Xi Victoria Lin, et al. OPT: Open pre-trained transformer language models. arXiv preprint arXiv:2205.01068, 2022.
[28] Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timo- thée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. LLaMA: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971, 2023.
[29] Alec Radford, Rafal Józefowicz, and Ilya Sutskever. Learning to generate reviews and discover- ing sentiment. arXiv preprint arXiv:1704.01444, 2017.
[30] Guillaume Lample and Alexis Conneau. Cross-lingual language model pretraining. arXiv preprint arXiv:1901.07291, 2019.
[31] Tri Dao, Daniel Y. Fu, Stefano Ermon, Atri Rudra, and Christopher Ré. Flashattention: Fast and memory-efficient exact attention with io-awareness. arXiv preprint arXiv:2205.14135, 2022.
[32] Rewon Child, Scott Gray, Alec Radford, and Ilya Sutskever. Generating long sequences with sparse transformers. arXiv preprint arXiv:1904.10509, 2019.
[33] Markus N. Rabe and Charles Staats. Self-attention does not need o(n2) memory. arXiv preprint arXiv:2112.05682, 2021.
[34] Scott Gray, Alec Radford, and Diederik P. Kingma. Gpu kernels for block-sparse weights, 2017. URL https://cdn.openai.com/blocksparse/blocksparsepaper.pdf.
[35] Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding. Proceedings of the International Conference on Learning Representations (ICLR) , 2021.
[36] Dan Hendrycks, Collin Burns, Steven Basart, Andrew Critch, Jerry Li, Dawn Song, and Jacob Steinhardt. Aligning AI with shared human values. Proceedings of the International Conference on Learning Representations (ICLR) , 2021.
[37] Alec Radford, Jeff Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. Language models are unsupervised multitask learners. 2019.
[38] Alec Radford, Karthik Narasimhan, Tim Salimans, and Ilya Sutskever. Improving language understanding by generative pre-training. 2018.
[39] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. NeurIPS, 2017.
[40] Paul F Christiano, Jan Leike, Tom Brown, Miljan Martic, Shane Legg, and Dario Amodei. Deep reinforcement learning from human preferences. Advances in Neural Information Processing Systems, 30, 2017.
[41] Joel Hestness, Sharan Narang, Newsha Ardalani, Gregory Diamos, Heewoo Jun, Hassan Kianinejad, Md Patwary, Mostofa Ali, Yang Yang, and Yanqi Zhou. Deep learning scaling is predictable, empirically. arXiv preprint arXiv:1712.00409, 2017.
[42] NeilCThompson,KristjanGreenewald,KeeheonLee,andGabrielFManso.Thecomputational limits of deep learning. arXiv preprint arXiv:2007.05558, 2020.
[43] Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, Alex Ray, Raul Puri, Gretchen Krueger, Michael Petrov, Heidy Khlaaf, Girish Sastry, Pamela Mishkin, Brooke Chan, Scott Gray, Nick Ryder, Mikhail Pavlov, Alethea Power, Lukasz Kaiser, Mohammad Bavarian, Clemens Winter, Philippe Tillet, Felipe Petroski Such, Dave Cummings, Matthias Plappert, Fotios Chantzis, Elizabeth Barnes, Ariel Herbert-Voss, William Hebgen Guss, Alex Nichol, Alex Paino, Nikolas Tezak, Jie Tang, Igor Babuschkin, Suchir Balaji, Shantanu Jain, William Saunders, Christopher Hesse, Andrew N. Carr, Jan Leike, Josh Achiam, Vedant Misra, Evan Morikawa, Alec Radford, Matthew Knight, Miles Brundage, Mira Murati, Katie Mayer, Peter Welinder, Bob McGrew, Dario Amodei, Sam McCandlish, Ilya Sutskever, and Wojciech Zaremba. Evaluating large language models trained on code. 2021.
[44] Ian McKenzie, Alexander Lyzhov, Alicia Parrish, Ameya Prabhu, Aaron Mueller, Najoung Kim, Sam Bowman, and Ethan Perez. The Inverse Scaling Prize, 2022. URL https://github.com/inverse-scaling/prize.
[45] Jason Wei, Najoung Kim, Yi Tay, and Quoc V. Le. Inverse scaling can become U-shaped. arXiv preprint arXiv:2211.02011, 2022.
[46] Ian McKenzie, Alexander Lyzhov, Alicia Parrish, Ameya Prabhu, Aaron Mueller, Najoung Kim, Sam Bowman, and Ethan Perez. Inverse Scaling Prize: First round winners, 2022. URL https://irmckenzie.co.uk/round1.
[47] Greg Brockman, Peter Welinder, Mira Murati, and OpenAI. OpenAI: OpenAI API, 2020. URL https://openai.com/blog/openai-api.
[48] Aarohi Srivastava, Abhinav Rastogi, Abhishek Rao, Abu Awal Md Shoeb, Abubakar Abid, Adam Fisch, Adam R. Brown, Adam Santoro, Aditya Gupta, Adrià Garriga-Alonso, et al. Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. arXiv preprint arXiv:2206.04615, 2022.
[49] Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding. arXiv preprint arXiv:2009.03300, 2020.
[50] Yi Tay, Jason Wei, Hyung Won Chung, Vinh Q Tran, David R So, Siamak Shakeri, Xavier Garcia, Huaixiu Steven Zheng, Jinfeng Rao, Aakanksha Chowdhery, et al. Transcending scaling laws with 0.1% extra compute. arXiv preprint arXiv:2210.11399, 2022.
[51] Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Eric Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, et al. Scaling instruction-finetuned language models. arXiv preprint arXiv:2210.11416, 2022.
[52] Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, and Yejin Choi. HellaSwag: Can a machine really finish your sentence? In Proceedings of the 57th Annual Meet- ing of the Association for Computational Linguistics, pages 4791–4800, Florence, Italy, July 2019. Association for Computational Linguistics. doi: 10.18653/v1/P19-1472. URL https://aclanthology.org/P19-1472.
[53] XiaodongLiu,HaoCheng,PengchengHe,WeizhuChen,YuWang,HoifungPoon,andJianfeng Gao. Adversarial training for large neural language models. arXiv preprint arXiv:2004.08994, 2020.
[54] Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. Think you have solved question answering? Try ARC, the AI2 reasoning challenge. ArXiv, abs/1803.05457, 2018.
[55] Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, and Denny Zhou. Self- consistency improves chain of thought reasoning in language models. arXiv preprint arXiv:2203.11171, 2022.
[56] Keisuke Sakaguchi, Ronan Le Bras, Chandra Bhagavatula, and Yejin Choi. WinoGrande: An adversarial Winograd schema challenge at scale. arXiv preprint arXiv:1907.10641, 2019.
[57] Bei Chen, Fengji Zhang, Anh Nguyen, Daoguang Zan, Zeqi Lin, Jian-Guang Lou, and Weizhu Chen. CodeT: Code generation with generated tests. arXiv preprint arXiv:2207.10397, 2022.
[58] Dheeru Dua, Yizhong Wang, Pradeep Dasigi, Gabriel Stanovsky, Sameer Singh, and Matt Gardner. DROP: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers) , pages 2368–2378, Minneapolis, Minnesota, June 2019. Association for Computational Linguistics. doi: 10.18653/v1/N19-1246. URL https://aclanthology.org/N19-1246.
[59] Kunlong Chen, Weidi Xu, Xingyi Cheng, Zou Xiaochuan, Yuyu Zhang, Le Song, Taifeng Wang, Yuan Qi, and Wei Chu. Question directed graph attention network for numerical reasoning over text. arXiv preprint arXiv:2009.07448, 2020.
[60] Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168, 2021.
[61] Aitor Lewkowycz, Anders Andreassen, David Dohan, Ethan Dyer, Henryk Michalewski, Vinay Ramasesh, Ambrose Slone, Cem Anil, Imanol Schlag, Theo Gutman-Solo, et al. Solving quantitative reasoning problems with language models. arXiv preprint arXiv:2206.14858, 2022.
[62] Jonathan Uesato, Nate Kushman, Ramana Kumar, Francis Song, Noah Siegel, Lisa Wang, Antonia Creswell, Geoffrey Irving, and Irina Higgins. Solving math word problems with process- and outcome-based feedback. arXiv preprint arXiv:2211.14275, 2022.
[63] Long Ouyang, Jeff Wu, Xu Jiang, Diogo Almeida, Carroll L Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback. arXiv preprint arXiv:2203.02155, 2022.
[64] OpenAI. OpenAI: Introducing ChatGPT, 2022. URL https://openai.com/blog/chatgpt.
[65] OpenAI. OpenAI: GPT-4, 2023. URL https://openai.com/research/gpt-4.
[66] Stephanie Lin, Jacob Hilton, and Owain Evans. TruthfulQA: Measuring how models mimic human falsehoods. In Proceedings of the 60th Annual Meeting of the Association for Com- putational Linguistics (Volume 1: Long Papers) , pages 3214–3252, Dublin, Ireland, May 2022. Association for Computational Linguistics. doi: 10.18653/v1/2022.acl-long.229. URL https://aclanthology.org/2022.acl-long.229.
[67] Yuntao Bai, Andy Jones, Kamal Ndousse, Amanda Askell, Anna Chen, Nova DasSarma, Dawn Drain, Stanislav Fort, Deep Ganguli, Tom Henighan, et al. Training a helpful and harmless assistant with reinforcement learning from human feedback. arXiv preprint arXiv:2204.05862, 2022.
[68] OpenAI. OpenAI: How should AI systems behave, and who should decide?, 2023. URL https://openai.com/blog/how-should-ai-systems-behave.
[69] Jan Leike, John Schulman, and Jeffrey Wu. OpenAI: Our approach to alignment research, 2022. URL https://openai.com/blog/our-approach-to-alignment-research.
[70] Joseph Carlsmith. Is power-seeking AI an existential risk? ArXiv, abs/2206.13353, 2022.
[71] Amelia Glaese, Nat McAleese, Maja Tre ̨bacz, John Aslanides, Vlad Firoiu, Timo Ewalds, Mari- beth Rauh, Laura Weidinger, Martin Chadwick, Phoebe Thacker, Lucy Campbell-Gillingham, Jonathan Uesato, Po-Sen Huang, Ramona Comanescu, Fan Yang, Abigail See, Sumanth Dathathri, Rory Greig, Charlie Chen, Doug Fritz, Jaume Sanchez Elias, Richard Green, Sonˇa Mokrá, Nicholas Fernando, Boxi Wu, Rachel Foley, Susannah Young, Iason Gabriel, William Isaac, John Mellor, Demis Hassabis, Koray Kavukcuoglu, Lisa Anne Hendricks, and Geoffrey Irving. Improving alignment of dialogue agents via targeted human judgements. arXiv preprint arXiv:2209.14375, 2022.
[72] Ethan Perez, Saffron Huang, H. Francis Song, Trevor Cai, Roman Ring, John Aslanides, Amelia Glaese, Nat McAleese, and Geoffrey Irving. Red teaming language models with language models. arXiv preprint arXiv:2202.03286, 2022.
[73] Samuel Gehman, Suchin Gururangan, Maarten Sap, Yejin Choi, and Noah A Smith. Real- ToxicityPrompts: Evaluating neural toxic degeneration in language models. arXiv preprint arXiv:2009.11462, 2020.
[74] Dora Seigel. How do you calculate SAT score? raw and scaled, 1 2020. URL https:blog.prepscholar.com/how-to-calculate-sat-score.
[75] The Albert blog. URL https://www.albert.io/blog/.
[76] Mathematical Association of America. AMC statistics, 2023. URL http://amc-reg.maa.org/Reports/GeneralReports.aspx.
[77] Halle Edwards. SAT percentiles and score rankings, 2022. URL https://blog.prepscholar.com/sat-percentiles-and-score-rankings
[78] College Board. Understanding SAT scores, 2022. URL https://satsuite.collegeboard.org/media/pdf/understanding-sat-scores.pdf.
[79] College Board. AP score distributions by subject, 2022. URL https://apcentral.collegeboard.org/media/pdf/ap-score-distributions-by-subject-2022.pdf.
[80] Center for Excellence in Education. 2020 USABO Semifinal exam score distribution, 2022. URL https://www.usabo-trc.org/sites/default/files/allfiles/2020 USABO Semifinal Exam Histogram.pdf.
[81] Chris Swimmer. GRE score percentiles – what does your score mean for you? (2021 update), 4 2021. URL https://magoosh.com/gre/gre-score-percentiles/.
[82] John B. Nici. AP Art History: 5 Practice Tests + Comprehensive Review + Online Practice. Barron’s Test Prep. Barron’s Educational Series, 2020. ISBN 9781506260501.
[83] ETS. GRE sample issue task, 2022. URL https://www.ets.org/pdfs/gre/sample-issue-task.pdf .
[84] MargaretMitchell,SimoneWu,AndrewZaldivar,ParkerBarnes,LucyVasserman,BenHutchin- son, Elena Spitzer, Inioluwa Deborah Raji, and Timnit Gebru. Model Cards for Model Reporting. In Proceedings of the Conference on Fairness, Accountability, and Transparency, pages 220– 229, January 2019. doi: 10.1145/3287560.3287596.
[85] Nekesha Green, Chavez Procope, Adeel Cheema, and Adekunle Adediji. System Cards, a new resource for understanding how AI systems work. https://ai.facebook.com/blog/system-cards-a-new-resource-for-understanding-how-ai-systems-work/ , February 2022.
译注:文中提到的附录部分暂未作翻译。想通过这部分译文加深理解的欢迎在评论区提需求。目前建议进入原文链接使用机器翻译。