注意力机制的原理和实现
在Attention出来之前,以前人们使用RNN和CNN来获得语义信息,但是RNN需要逐步递归才可以获得全局的信息,而通过滑动窗口进行编码的CNN,更侧重于捕获局部信息,难以建模长距离的语义依赖。Attention可以使得每个词具有上下文的语义信息。
1、原理
Attention的实现方式有多种,常见的是Scaled Dot-product Attention。

Attention 有三个输入(query,key,value),若三个输入是相同的称为Self-Attention,若三个输入不同为Cross-Attention,公式如下。
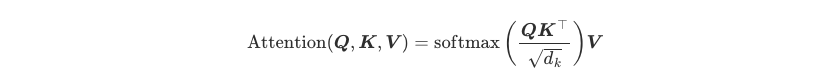
以Self-Attention举例,Q,K,V都是相同的输入,通过Q和K的点积运算,来获得注意力分数矩阵,由于点积会产生任意大的数,通过乘以一个缩放因子来标准化他的方差,并通过Softmax来对数据进行标准化,这样就得到了注意权重,将注意力与对应的V相乘,来获得Q更新的向量。综上通过Q和K的点积来获得注意力矩阵,知道句中的词之间的相关性,然后乘以V来更新向量,这个新向量中每个词可以具有上下文的语义信息,而且更有侧重性。
2、实现
scaled_dot_product_attention的简单实现
# attention 的实现 def scaled_dot_product_attention(query,key,value,query_mask=None,key_mask=None,mask=None): dim_k=query.size(-1) scores=torch.bmm(query,key.transpose(1,2))/sqrt(dim_k) if query_mask is not None and key_mask is not None: mask=torch.bmm(query_mask.unsqueeze(-1),key_mask.unsqueeze(1)) if mask is not None: # 填充padding字符不应该参与计算,因此将注意力分数设置为负无穷,这样softmaxt之后对应的注意力权重为0 scores=scores.masked_fill(mask==0,-float("inf")) weight=F.softmax(scores,dim=-1) return torch.bmm(weight,value)
多头注意力机制的工程化封装(pytorch的实现)
def scaled_dot_product_attention(query,key,value,query_mask=None,key_mask=None,mask=None): dim_k=query.size(-1) scores=torch.bmm(query,key.transpose(1,2))/sqrt(dim_k) if query_mask is not None and key_mask is not None: mask=torch.bmm(query_mask.unsqueeze(-1),key_mask.unsqueeze(1)) if mask is not None: # 填充padding字符不应该参与计算,因此将注意力分数设置为负无穷,这样softmaxt之后对应的注意力权重为0 scores=scores.masked_fill(mask==0,-float("inf")) weight=F.softmax(scores,dim=-1) return torch.bmm(weight,value) # 多头注意力 class AttentionHead(nn.Module): def __init__(self,embed_dim,head_dim): super().__init__() self.q=nn.Linear(embed_dim,head_dim) self.k=nn.Linear(embed_dim,head_dim) self.v=nn.Linear(embed_dim,head_dim) def forward(self,query,key,value,query_mask=None,key_mask=None,mask=None): attn_outputs=scaled_dot_product_attention( self.q(query),self.k(key),self.v(value),query_mask,key_mask,mask ) return attn_outputs # 多头注意力机制 class MultiHeadAttention(nn.Module): def __init__(self,config): super().__init__() embed_dim=config.hidden_size num_heads=config.num_attention_heads head_dim=embed_dim//num_heads self.heads=nn.ModuleList( [AttentionHead(embed_dim,head_dim) for _ in range(num_heads)] ) self.output_linear=nn.Linear(embed_dim,embed_dim) def forward(self,query,key,value,query_mask=None,key_mask=None,mask=None): x=torch.cat( [h(query,key,value,query_mask,key_mask,mask) for h in self.heads],dim=-1 ) x=self.output_linear(x) return x
到此,注意力机制的原理和实现都以完成。