产品官网:https://www.huaweicloud.com/product/hecs-light.html

今天我们采用可靠更安全、智能不卡顿、价优随心用、上手更简单、管理特省心的华为云耀云服务器L实例为例,我们将在华为云耀云服务器L实例上配置使用 Scikit-learn 进行鸢尾花分类的识别,作为使用云服务器进行深度学习环境配置的进阶
以下是一个简单的Sklearn鸢尾花分类项目的部署步骤。在这个例子中,我们将使用Flask作为Web框架,通过HTTP请求调用Sklearn模型进行鸢尾花分类。
### 步骤概览:
1. **安装必要的库:** 确保服务器上已经安装了Python和相关依赖。
2. **编写Flask应用:** 创建一个简单的Flask应用,用于接收HTTP请求,并使用Sklearn模型进行鸢尾花分类。
3. **导出Sklearn模型:** 如果还没有训练好的Sklearn模型,首先训练一个,并将其导出保存。
4. **设置虚拟环境:** 可选但推荐,使用虚拟环境隔离项目依赖。
5. **部署Flask应用:** 使用一个Web服务器(比如Gunicorn)来部署Flask应用。
6. **配置反向代理:** 配置反向代理(比如Nginx或Apache),以便将用户请求传递给Flask应用。
### 具体步骤:
#### 1. 安装必要的库:
```bash
pip install flask scikit-learn gunicorn
```

#### 2. 编写Flask应用:
```python
from flask import Flask, request, jsonify
import joblib
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
app = Flask(__name__)
# Train and save the Sklearn model in the current directory
iris = load_iris()
X_train, X_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.2, random_state=42)
model = RandomForestClassifier(n_estimators=100, random_state=42)
model.fit(X_train, y_train)
joblib.dump(model, 'sklearn_model.pkl')
# Load the trained Sklearn model
model = joblib.load('sklearn_model.pkl')
@app.route('/predict', methods=['POST'])
def predict():
try:
data = request.json # Assuming JSON input like {"sepal_length": 5.1, "sepal_width": 3.5, "petal_length": 1.4, "petal_width": 0.2}
features = [[data['sepal_length'], data['sepal_width'], data['petal_length'], data['petal_width']]]
prediction = model.predict(features)[0]
return jsonify({'prediction': int(prediction)})
except Exception as e:
return jsonify({'error': str(e)})
if __name__ == '__main__':
app.run(debug=True)
```
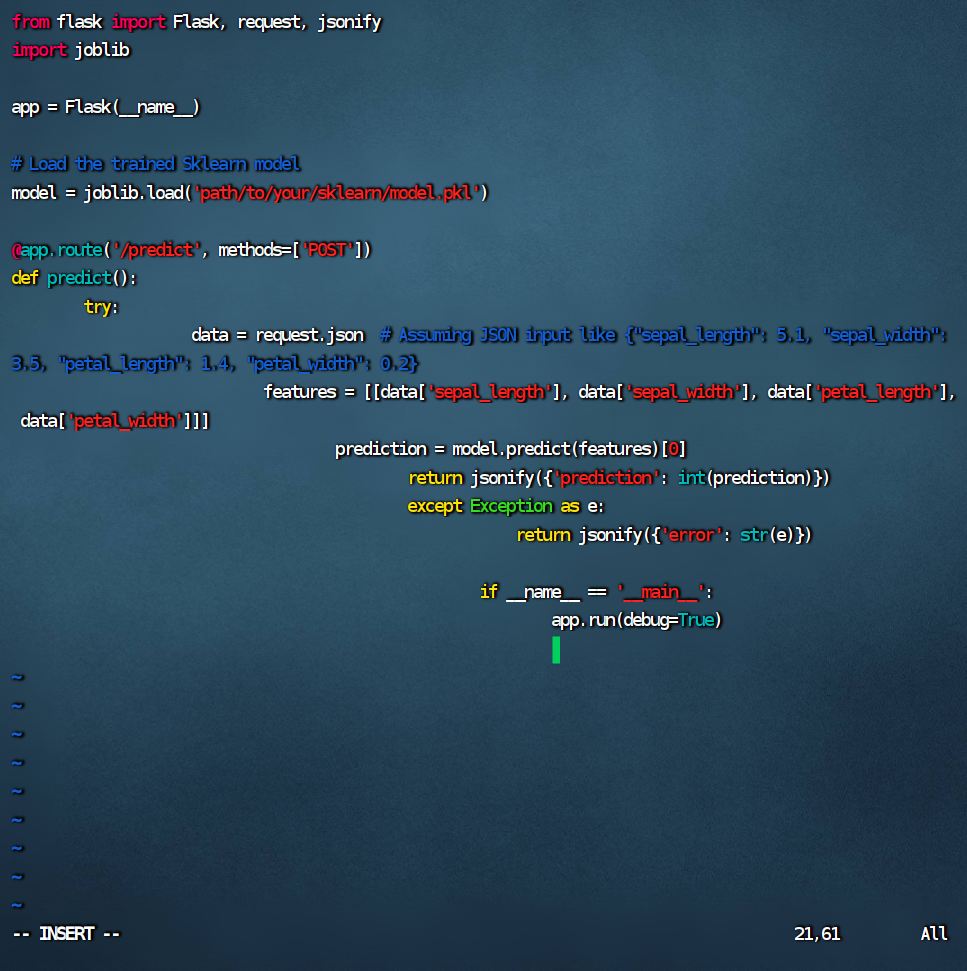
```python
# app.py
from flask import Flask, request, jsonify
import joblib
app = Flask(__name__)
# Load the trained Sklearn model
model = joblib.load('path/to/your/sklearn/model.pkl')
@app.route('/predict', methods=['POST'])
def predict():
data = request.json # Assuming JSON input like {"sepal_length": 5.1, "sepal_width": 3.5, "petal_length": 1.4, "petal_width": 0.2}
features = [[data['sepal_length'], data['sepal_width'], data['petal_length'], data['petal_width']]]
prediction = model.predict(features)[0]
return jsonify({'prediction': int(prediction)})
if __name__ == '__main__':
app.run(debug=True)
```
#### 3. 导出Sklearn模型:
```python
# train_sklearn_model.py
# Assuming you have a trained model
import joblib
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
# Load Iris dataset
iris = load_iris()
X_train, X_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.2, random_state=42)
# Train a simple RandomForestClassifier
model = RandomForestClassifier(n_estimators=100, random_state=42)
model.fit(X_train, y_train)
# Save the trained model
joblib.dump(model, 'path/to/your/sklearn/model.pkl')
```
#### 4. 设置虚拟环境:
```bash
# Create a virtual environment (optional but recommended)
python -m venv venv
source venv/bin/activate # On Windows, use "venv\Scripts\activate"
```
#### 5. 部署Flask应用:
使用Gunicorn启动Flask应用:
```bash
gunicorn -w 4 -b 0.0.0.0:5000 app:app
```
#### 6. 配置反向代理:
使用Nginx作为反向代理(示例配置):
```nginx
server {
listen 80;
server_name your_domain.com;
location / {
proxy_pass http://127.0.0.1:5000;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
}
}
```
这样,我们就可以通过访问 `http://your_domain.com/predict` 来调用Sklearn模型进行鸢尾花分类了。确保替换其中的 `your_domain.com` 为你的实际域名或IP地址。
通过这些步骤,我们成功在 华为云耀云服务器L实例上成功配置并运行使用 Scikit-learn 进行鸢尾花分类识别的进阶操作,使用Flask作为Web框架,通过HTTP请求调用Sklearn模型进行鸢尾花分类。