Deformable ConvNets V2: More Deformable, Better Results
* Authors: [[Xizhou Zhu]], [[Han Hu]], [[Stephen Lin]], [[Jifeng Dai]]
初读印象
comment:: (可变形卷积v2)增加了可变形卷积的数量、调制因子和额外的用来特征模仿的网络。
deformable convolution可变形卷积(4uiiurz1-pytorch版)源码分析 - 知乎 (zhihu.com)
Deformable Convolution可变形卷积pytorch版代码逐行解读(非常详细) - 知乎 (zhihu.com)
动机
前文[[@Dai2017|Dai2017]](Deformable Convolutional Networks)
可变形卷积网络的优越性能来源于其适应物体几何变化的能力。通过对其自适应行为的研究,观察到虽然其神经特征的空间支持比常规的卷积神经网络更符合物体结构,但这种支持可能远远超出感兴趣区域,导致特征受到无关图像内容的影响。
三种空间支持可视化方法
- Effective receptive fields:并非网络节点感受野内的所有像素对其响应的贡献都相等。这些贡献的差异由一个有效的感受野表示,其值被计算为节点响应对每个图像像素的强度扰动的梯度。我们利用有效感受野来考察单个像素对网络节点的相对影响,但需要注意的是,该测度并不能反映全图区域的结构化影响。
- Effective sampling / bin locations:对(堆叠)卷积层的采样位置和RoIpooling层中的采样仓进行可视化,以了解可变形卷积神经网络的行为。然而,这些采样位置对网络节点的相对贡献并没有被揭示。我们将包含这些信息的有效采样位置可视化,计算为网络节点相对于采样/ bin位置的梯度,以了解它们的贡献强度。
- Error-bounded saliency regions:正如最近关于图像显著性的研究所证明的那样,如果移除不影响网络节点的图像区域,网络节点的响应不会改变。基于这个性质,我们可以在一个小的误差范围内,将一个节点的支持区域确定为给出与全图相同响应的最小图像区域。我们将其称为误差有界显著性区域,可以通过逐步掩盖图像的部分并计算得到的节点响应来找到,如附录中更详细的描述。误差估计显著性区域便于比较来自不同网络的支持区域。
 可见,可变形卷积神经网络相对于普通卷积神经网络,其适应几何变化的能力显著提高,但也可以看出其空间支持范围可能超出感兴趣区域。因此,我们寻求对Deformable卷积神经网络进行升级,使其能够更好地聚焦于相关的图像内容,并提供更高的检测精度。### 方法
可见,可变形卷积神经网络相对于普通卷积神经网络,其适应几何变化的能力显著提高,但也可以看出其空间支持范围可能超出感兴趣区域。因此,我们寻求对Deformable卷积神经网络进行升级,使其能够更好地聚焦于相关的图像内容,并提供更高的检测精度。### 方法
堆叠更多的可变形卷积层 Stacking More Deformable Conv Layers
将可变形卷积应用于ResNet - 50中的conv3、conv4和conv5阶段的所有3 × 3 conv层,共12个。先前的工作中只用了三层可变形卷积,都是在conv5阶段。
可调制变形模块Modulated Deformable Modules
利用它,变形卷积神经网络模块不仅可以调节感知输入特征的偏移,还可以从不同的空间位置/面元对输入特征幅值进行调制。在极端情况下,模块可以通过将其特征幅度设置为零来决定不感知来自特定位置/ bin的信号。因此,对应空间位置的图像内容对模块输出的影响会大幅降低或无影响。因此,调制机制为网络模块提供了另一个维度的自由度来调整其空间支持区域。
可调制卷积:

可调制RoI池化与其差不多
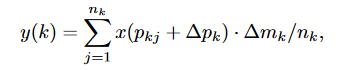 ^bcbry8#### R - CNN特征模仿R-CNN Feature Mimicking
^bcbry8#### R - CNN特征模仿R-CNN Feature Mimicking
对于普通卷积神经网络和可变形卷积神经网络,每个RoI分类节点的误差估计显著性区域都可以延伸到RoI之外。RoI以外的图像内容可能会影响提取的特征,从而降低目标检测的最终结果。
由于R - CNN分类得分集中于输入RoI中裁剪后的图像内容,因此在可变形Faster R - CNN的per - RoI特征上引入了特征模仿损失,以迫使它们与从裁剪图像中提取的R - CNN特征相似。该辅助训练目标旨在驱动Deformable Faster R - CNN学习更多类似R - CNN的"聚焦"特征表示。
具体做法:
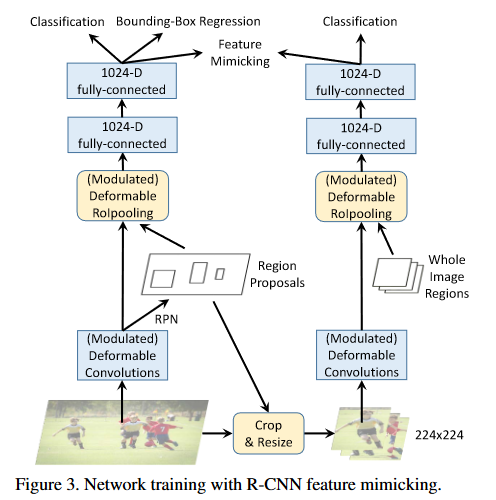
除了Faster R-CNN意外,增加了一个额外R-CNN分支用于特征模仿。
- 给定用于特征模仿的RoI b,裁剪与之对应的图像块并调整大小为224 × 224像素。
- 对输入图像b的R-CNN特征表示\(f_{RCNN}(b)\)和Faster R-CNN对应特征\(f_{FRCNN}(b)\)计算特征拟态损失,即计算余弦相似度:
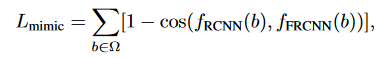
其中Ω表示用于特征模仿训练的RoIs采样集合。
启发
在原可变形卷积和池化的基础上加入调制因子,实际上是增加了模型复杂度,但是可以说出花来。
用额外的一个已知有特定特征提取功能的网络的结果和自己的网络的结果进行余弦相似度损失计算,让自己的网络能够在一定程度上学习该网络的能力。