前言 动动鼠标,让图片变「活」,成为你想要的模样。
本文转载自机器之心
仅用于学术分享,若侵权请联系删除
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【CV技术指南】CV全栈指导班、基础入门班、论文指导班 全面上线!!
在 AIGC 的神奇世界里,我们可以在图像上通过「拖曳」的方式,改变并合成自己想要的图像。比如让一头狮子转头并张嘴:
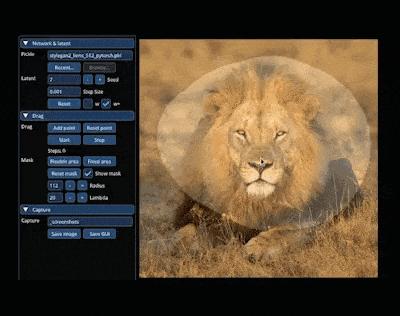
实现这一效果的研究出自华人一作领衔的「Drag Your GAN」论文,于上个月放出并已被 SIGGRAPH 2023 会议接收。
一个多月过去了,该研究团队于近日放出了官方代码。短短三天时间,Star 量便已突破了 23k,足可见其火爆程度。
GitHub 地址:https://github.com/XingangPan/DragGAN
无独有偶,今日又一项类似的研究 —— DragDiffusion 进入了人们的视线。此前的 DragGAN 实现了基于点的交互式图像编辑,并取得像素级精度的编辑效果。但是也有不足,DragGAN 是基于生成对抗网络(GAN),通用性会受到预训练 GAN 模型容量的限制。
在新研究中,新加坡国立大学和字节跳动的几位研究者将这类编辑框架扩展到了扩散模型,提出了 DragDiffusion。他们利用大规模预训练扩散模型,极大提升了基于点的交互式编辑在现实世界场景中的适用性。
虽然现在大多数基于扩散的图像编辑方法都适用于文本嵌入,但 DragDiffusion 优化了扩散潜在表示,实现了精确的空间控制。

- 论文地址:https://arxiv.org/pdf/2306.14435.pdf
- 项目地址:https://yujun-shi.github.io/projects/dragdiffusion.html
研究者表示,扩散模型以迭代方式生成图像,而「一步」优化扩散潜在表示足以生成连贯结果,使 DragDiffusion 高效完成了高质量编辑。
他们在各种具有挑战性的场景(如多对象、不同对象类别)下进行了广泛实验,验证了 DragDiffusion 的可塑性和通用性。相关代码也将很快放出、
下面我们看看 DragDiffusion 效果如何。
首先,我们想让下图中的小猫咪的头再抬高一点,用户只需将红色的点拖拽至蓝色的点就可以了:

接下来,我们想让山峰变得再高一点,也没有问题,拖拽红色关键点就可以了:

还想让雕塑的头像转个头,拖拽一下就能办到:

让岸边的花,开的范围更广一点:

方法介绍
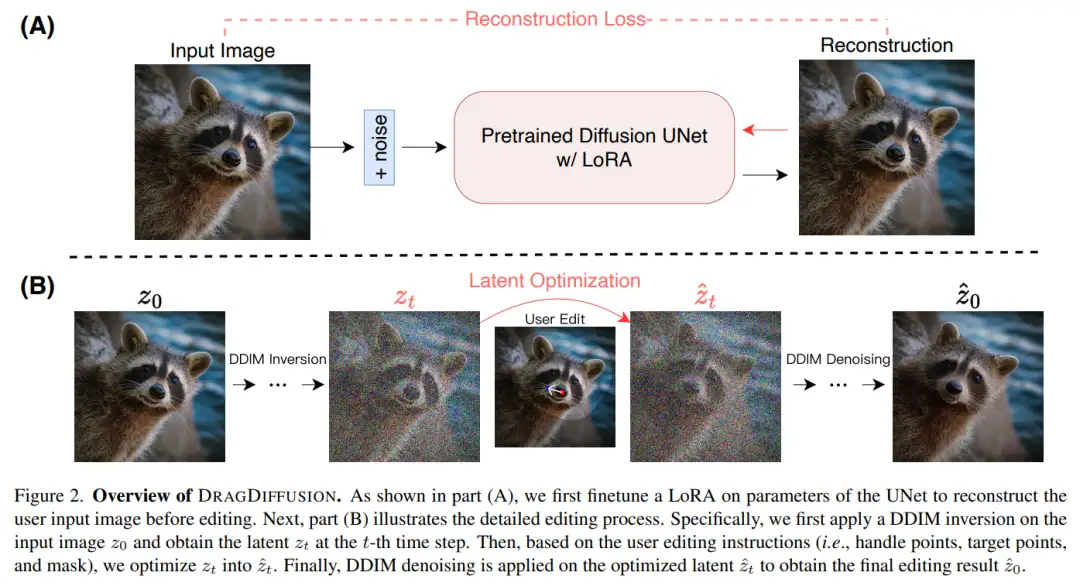
本文提出的 DRAGDIFFUSION 旨在优化特定的扩散潜变量,以实现可交互的、基于点的图像编辑。
为了实现这一目标,该研究首先在扩散模型的基础上微调 LoRA,以重建用户输入图像。这样做可以保证输入、输出图像的风格保持一致。
接下来,研究者对输入图像采用 DDIM inversion(这是一种探索扩散模型的逆变换和潜在空间操作的方法),以获得特定步骤的扩散潜变量。
在编辑过程中,研究者反复运用动作监督和点跟踪,以优化先前获得的第 t 步扩散潜变量,从而将处理点的内容「拖拽(drag)」到目标位置。编辑过程还应用了正则化项,以确保图像的未掩码区域保持不变。
最后,通过 DDIM 对优化后的第 t 步潜变量进行去噪,得到编辑后的结果。总体概览图如下所示:
实验结果
给定一张输入图像,DRAGDIFFUSION 将关键点(红色)的内容「拖拽」到相应的目标点(蓝色)。例如在图(1)中,将小狗的头转过来,图(7)将老虎的嘴巴合上等等。

下面是更多示例演示。如图(4)将山峰变高,图(7)将笔头变大等等。

欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【技术文档】《从零搭建pytorch模型教程》122页PDF下载
QQ交流群:470899183。群内有大佬负责解答大家的日常学习、科研、代码问题。
其它文章
中科院自动化所发布FastSAM | 精度相当,速度提升50倍!!!
大核卷积网络是比 Transformer 更好的教师吗?ConvNets 对 ConvNets 蒸馏奇效
MaskFormer:将语义分割和实例分割作为同一任务进行训练
CVPR 2023 VAND Workshop Challenge零样本异常检测冠军方案
沈春华团队最新 | SegViTv2对SegViT进行全面升级,让基于ViT的分割模型更轻更强
刷新20项代码任务SOTA,Salesforce提出新型基础LLM系列编码器-解码器Code T5+
CVPR最佳论文颁给自动驾驶大模型!中国团队第一单位,近10年三大视觉顶会首例
最新轻量化Backbone | FalconNet汇聚所有轻量化模块的优点,成就最强最轻Backbone
libtorch教程(一)开发环境搭建:VS+libtorch和Qt+libtorch
NeRF与三维重建专栏(三)nerf_pl源码部分解读与colmap、cuda算子使用
NeRF与三维重建专栏(二)NeRF原文解读与体渲染物理模型
BEV专栏(一)从BEVFormer深入探究BEV流程(上篇)
可见光遥感图像目标检测(三)文字场景检测之Arbitrary