推荐:使用NSDT场景编辑器助你快速搭建可二次编辑器的3D应用场景
介绍
在用西班牙语(您的首选语言)向语音助手询问某些内容后,您有多少次不得不暂停,然后用语音助手理解的语言(可能是英语)重述您的问题,因为语音助手无法理解您的西班牙语请求?或者,当你要求你的语音助手播放他们的音乐时,你有多少次不得不故意念错你最喜欢的艺术家A. R. Rahman的名字,因为你知道如果你说出他们的名字是正确的,语音助手根本听不懂,但如果你说A.R.拉面,语音助手会明白吗?此外,当语音助手用他们舒缓、无所不知的声音,屠宰你最喜欢的音乐剧《悲惨世界》的名字并明确地将其发音为“Les Miz-er-ables”时,你有多少次畏缩?
尽管语音助手在大约十年前已成为主流,但它们仍然保持简单化,特别是在理解多语言环境中的用户请求方面。在一个多语言家庭正在崛起,现有和潜在用户群变得越来越全球化和多样化的世界中,语音助手在理解用户请求时变得无缝至关重要,无论他们的语言、方言、口音、语气、调制和其他语音特征如何。然而,语音助手在能够以人类彼此的方式与用户顺利交谈方面继续严重滞后。在本文中,我们将深入探讨使语音助手多语言运行的最大挑战是什么,以及缓解这些挑战的一些策略可能是什么。在本文中,我们将使用假设的语音助手 Nova,用于说明目的。
语音助手的工作原理
在深入探讨使语音助手用户体验多语言的挑战和机遇之前,让我们大致了解一下语音助手的工作原理。使用 Nova 作为假设的语音助手,我们看看请求音乐曲目的端到端流程是什么样的(参考)。
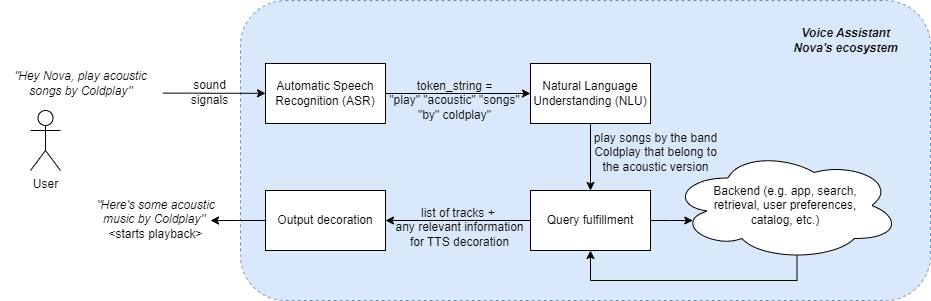
1. 假设语音助手Nova的端到端概述
如图所示。1.当用户要求Nova播放流行乐队酷玩乐队的原声音乐时,用户的这个声音信号首先被转换为一串文本令牌,作为人-语音助手交互的第一步。此阶段称为自动语音识别 (ASR) 或语音转文本 (STT)。一旦令牌字符串可用,它就会传递到自然语言理解步骤,语音助手将尝试理解用户意图的语义和句法含义。在这种情况下,语音助手的NLU解释用户正在寻找酷玩乐队的歌曲(即解释酷玩乐队是一个乐队),这些歌曲本质上是原声的(即在该乐队的唱片中查找歌曲的元数据,并且只选择版本=原声的歌曲)。然后,此用户意图理解用于查询后端以查找用户要查找的内容。最后,用户正在寻找的实际内容以及向用户呈现此输出所需的任何其他附加信息将转到下一步。在此步骤中,响应和任何其他可用信息用于修饰用户的体验,并令人满意地响应用户查询。在这种情况下,它将是文本到语音转换 (TTS) 输出(“这是酷玩乐队的一些原声音乐”),然后播放为此用户查询选择的实际歌曲。
构建多语言语音助手的挑战
多语言语音助手 (VA) 意味着能够理解和响应多种语言的 VA,无论它们是由同一个人或多人说的,还是由同一个人用与另一种语言混合的同一个句子说的(例如“Nova,arrêt!玩别的东西“)。以下是语音助手在多模式环境中无缝操作时面临的主要挑战。
语言资源的数量和数量不足
为了使语音助手能够很好地解析和理解查询,需要对该语言的大量训练数据进行训练。这些数据包括来自人类的语音数据、地面真相注释、大量文本语料库、用于改进 TTS 发音的资源(例如发音词典)和语言模型。虽然这些资源很容易用于英语、西班牙语和德语等流行语言,但对于斯瓦希里语、普什图语或捷克语等语言,它们的可用性有限甚至不存在。即使有足够多的人使用这些语言,也没有结构化的资源可用于这些语言。为多种语言创建这些资源可能很昂贵、复杂且需要大量人力,从而为进展带来阻力。
语言变化
语言有不同的方言、口音、变体和区域适应。处理这些变化对于语音助手来说具有挑战性。除非语音助手适应这些语言上的细微差别,否则很难正确理解用户请求或能够以相同的语言语气做出响应,以提供自然的声音和更像人类的体验。例如,仅英国就有40多种英语口音。另一个例子是墨西哥使用的西班牙语与西班牙使用的西班牙语不同。
语言识别和适应
多语言用户在与其他人的交互过程中切换语言是很常见的,他们可能期望与语音助手进行相同的自然交互。例如,“Hinglish”是一个常用术语,用于描述在说话时使用印地语和英语单词的人的语言。能够识别用户与语音助手交互的语言并相应地调整响应是一项艰巨的挑战,这是当今主流语音助手无法做到的艰巨挑战。
语言翻译
将语音助手扩展到多种语言的一种方法是将 ASR 输出从卢森堡语等非主流语言翻译成 NLU 层可以更准确地解释的语言,例如英语。常用的翻译技术包括使用一种或多种技术,如神经机器翻译 (NMT)、统计机器翻译 (SMT)、基于规则的机器翻译 (RBMT) 等。但是,这些算法可能无法很好地针对不同的语言集进行扩展,并且可能还需要大量的训练数据。此外,语言特定的细微差别经常丢失,翻译版本往往显得尴尬和不自然。在能够扩展多语言语音助手方面,翻译质量仍然是一个持续的挑战。翻译步骤中的另一个挑战是它引入的延迟,降低了人与语音助手交互的体验。
真正的语言理解
语言通常具有独特的语法结构。例如,英语有单数和复数的概念,梵语有3(单数,对偶,复数)。也可能有不同的习语不能很好地翻译成其他语言。最后,可能还有文化细微差别和文化参考,除非翻译技术具有高质量的语义理解,否则翻译可能很差。开发特定于语言的 NLU 模型是昂贵的。
克服构建多语言语音助手的挑战
上面提到的挑战是难以解决的问题。但是,有一些方法可以立即部分(如果不是完全)缓解这些挑战。以下是一些可以解决上述一个或多个挑战的技术。
利用深度学习检测语言
解释句子含义的第一步是知道句子属于哪种语言。这就是深度学习的用武之地。深度学习使用人工神经网络和大量数据来创建看起来像人类的输出。基于转换器的架构(例如BERT)在语言检测方面已经证明是成功的,即使在资源匮乏的语言中也是如此。基于转换器的语言检测模型的替代方法是递归神经网络 (RNN)。这些模型应用的一个例子是,如果一个平时用英语说话的用户有一天突然用西班牙语与语音助手交谈,语音助手可以正确检测和识别西班牙语。
使用上下文机器翻译来“理解”请求
一旦检测到语言,解释句子的下一步是获取 ASR 阶段的输出,即标记字符串,并将该字符串(不仅从字面上而且在语义上)转换为可以处理以生成响应的语言。而不是使用翻译 API,这些 API 可能并不总是知道语音界面的上下文和特性,并且由于高延迟而在响应中引入次优延迟,从而降低用户体验。但是,如果将上下文感知机器翻译模型集成到语音助手中,则由于特定于域或会话上下文,翻译可以具有更高的质量和准确性。例如,如果语音助手主要用于娱乐,它可以利用上下文机器翻译来正确理解和回答有关音乐流派和子流派、乐器和音符、某些曲目的文化相关性等问题。
利用多语言预训练模型
由于每种语言都有独特的结构和语法、文化参考、短语、习语和表达方式以及其他细微差别,因此处理不同的语言具有挑战性。鉴于特定于语言的模型很昂贵,预先训练的多语言模型可以帮助捕获特定于语言的细微差别。像BERT和XLM-R这样的模型是预先训练模型的很好的例子,可以捕获语言特定的细微差别。最后,这些模型可以微调到一个领域,以进一步提高其准确性。例如,对于在音乐领域训练的模型,可能不仅能够理解查询,还可以通过语音助手返回丰富的响应。如果这个语音助手被问到一首歌歌词背后的含义是什么,语音助手将能够以比简单解释单词更丰富的方式回答问题。
使用代码切换模型
实现代码切换模型以便能够处理混合使用不同语言的语言输入,可以在用户与语音助手的交互中使用多种语言的情况下提供帮助。例如,如果语音助手是专门为加拿大用户经常混淆法语和英语的地区设计的,则可以使用代码切换模型来理解指向语音助手的句子,这些句子是两种语言的混合,语音助手将能够处理它。
利用迁移学习和零镜头学习来开发低资源语言
迁移学习是 ML 中的一种技术,其中模型在一项任务上训练,但用作第二个任务的模型的起点。它利用从第一个任务中学习来提高第二个任务的性能,从而在一定程度上克服了冷启动问题。零镜头学习是指使用预先训练的模型来处理以前从未见过的数据。迁移学习和零镜头学习都可以用于将知识从高资源语言转移到低资源语言。例如,如果语音助手已经接受了世界上最常用的 10 种语言的培训,则可以利用它来理解斯瓦希里语等低资源语言的查询。
结论
总之,在语音助手上构建和实现多语言体验具有挑战性,但也有一些方法可以缓解其中一些挑战。通过解决上述挑战,语音助手将能够为用户提供无缝体验,无论其语言如何。