一、案例概述
1、第一步--变成偏移量的K1,V1(这一步不需要我们自己写)
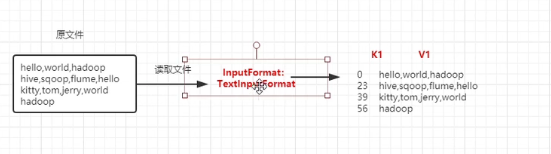
2、进入Map阶段
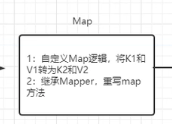
输出新的<K2,V2>的键值对;
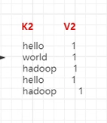
3、Shuffle阶段
分区、排序、规约、分组
输出新的键值对:

4、Reduce阶段
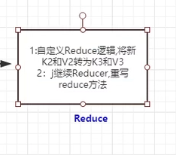
转换为<K3,V3>的新的形式的键值对;
利用TextOutputFormat的类实现结果的输出;
二、具体实践
1、准备一个.txt文件

2、Mapper阶段
在新建的Maven项目中导入相关依赖:
hadoop-common/hadoop-hdfs/hadoop-client/hadoop-mapreduce-client-core/junit
新建一个mapper的类(可以自定义名称为:WordCountMapper),并继承于Mapper(hadoop.mapreduce)


重写里面的map方法:




具体代码如下图:

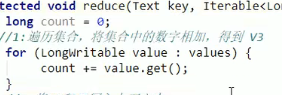
3、Reduce阶段
新建一个类(可以自定义命名为WordCountReduce),并继承于Reducer类;

重写reduce方法:



4、主类代码编写
新建一个自定义名为JobMain的类,并继承于Configured类,且实现名为Tool(hadoop.util)的接口:


在main函数里面启动job任务:



在run函数里面进行job任务的设置:

第一步--指定文件的读取和读取路径

第二步--指定Map阶段的处理方式和数据类型
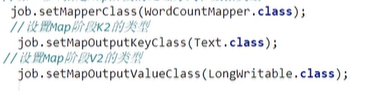
第三、四、五、六步(Shuffle阶段)--采用默认方式,暂时不做处理;
第七步--指定Reduce阶段的处理方式和数据类型
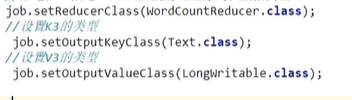
第八步--设置输出类型

最后,等待任务结束:
