LLVM优化示例
10.1 LLVM优化示例介绍
10.1.1 编译器优化目标
一个优化的、领先的编译器通常被组织为:
1)一个将源代码翻译为一个中间表示(IR)的前端。
2)一个目标无关的优化流水线:一系列遍,它们持续重写IR,以消除低效性以及不能容易翻译为机器码的形式。有时称之为中端(middle end)。
3)一个目标相关的后端,生成汇编代码或机器码。
在某些编译器中,在整个优化流水线中IR格式保持不变,在其他编译器里,格式或语义改变。在LLVM里,格式与语义是固定的,因此,在不引入错误编译或导致编译器崩溃的情况下,应该可以运行任何希望的遍序列。
优化流水线中的遍序列由编译器开发者设计;其目标是在合理的时间内完成相当好的工作。它不时会被调整,当然,在每个优化级别,运行着不同的遍集合。编译器研究中的一个长期存在的话题是,使用机器学习或其他方法来提供更好的优化流水线,无论在一般的还是特定的应用领域,缺省流水线都不能出色工作。
遍设计的一些原则是最小性与正交性:每个遍应该做好一件事,在功能上不应该有太多的重叠。在实践中,有时会做出妥协。例如,当两个遍倾向于重复为彼此生成工作,它们可能被整合为单个、更大的遍。同样,某些IR层面的功能,比如常量折叠是如此广泛使用,作为一个遍是不合理的;例如,LLVM在创建指令时隐含折叠掉常量操作。
10.1.2 LLVM优化遍如何工作
先看一下某些LLVM优化遍如何工作。假设已经看过了关于Clang如何编译一个函数,或者知道LLVM IR怎么工作。理解SSA(静态单赋值)形式特别有用。另外,可参考
LLVM语言参考与
优化遍列表。
研究Clang/LLVM 6.0.1如何优化这个C++代码:
bool is_sorted(int *a, int n)
for (int i = 0; i < n - 1; i++)
if (a[i] > a[i + 1])
return false;
return true;
记住优化流水线是一个忙碌的地方,将略过许多有趣的内容,比如:
1)内联,一个容易但超级重要的优化,它不会在这里出现,因为只看一个函数。
2)基本上相对C,特定于C++的所有内容。
3)自动向量化,它被早期循环退出所挫败。
在下面将跳过不改变代码的每个遍。同样,不会看后端,在那里也有很多遍。即使这样,这将是一个有点艰难的过程!(抱歉在下面使用图形,但它看起来是避免格式难题的最好方式,讨厌与WP主题斗争。点击图形获取更大的版本。使用
icdiff)。
opt -O2 -print-before-all -print-after-all is_sorted2.ll
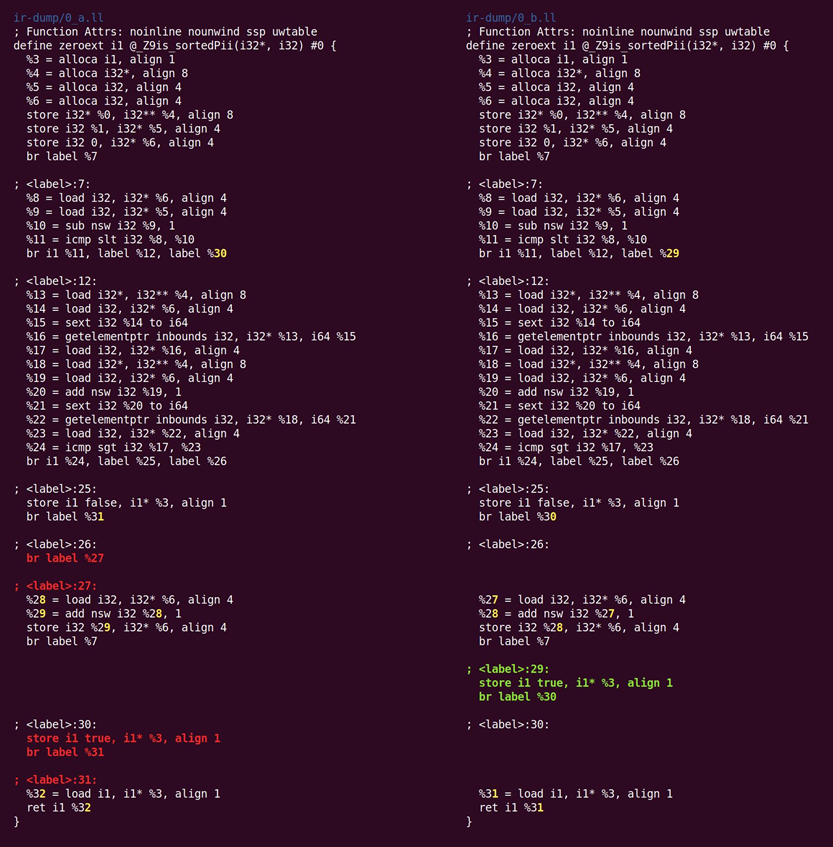
第一个遍是
简化CFG(控制流图)。因为Clang不进行优化,它发布的IR通常包含清除的机会,如图10.1所示:
这里,基本块26只是跳转到块27。这类块可以被消除,到它的跳转将被转发到目标块。Diff更令人困惑,因为由LLVM执行的隐含的块重编码。SimplifyCFG执行的整组转换,列出在遍头部的注释里:
这个文件实现死代码消除与基本块合并,连同一组其他控制流优化。例如:
1)删除没有前驱的基本块。
2)如果仅有一个前驱且该前驱仅有一个后继,将基本块与且前驱合并。
3)消除只有一个前驱的基本块的PHI节点。
4)消除仅包含无条件分支的基本块。
5)将invoke指令改为调用nounwind函数。
6)把形如if (x) if (y)的情形改为if (x&y)。
CFG清理的大多数机会是其他LLVM遍的结果。例如,死代码消除与循环不变代码移动,可以容易地创建空基本块。
下一个运行的遍,
SROA(聚集对象的标量替换,scalar replacement of aggregate),是其中一个重量级击打者。这个名字有点误导,因为SROA仅是它其中一个功能。这个遍消除每条alloca指令(函数域的内存分配),并尝试把它提升到SSA寄存器。在alloca被多次静态分配,或者是一个可以被分解为其组成的class或struct时(这个分解就是这个遍名字中提到的标量替换),单个alloc将被转换为多个寄存器。如图10.2所示,SROA的一个简单版本会放弃地址被获取的栈变量,但LLVM的版本与别名分析相互作用,是相当智能的(虽然在例子里这个智能是不需要的)。
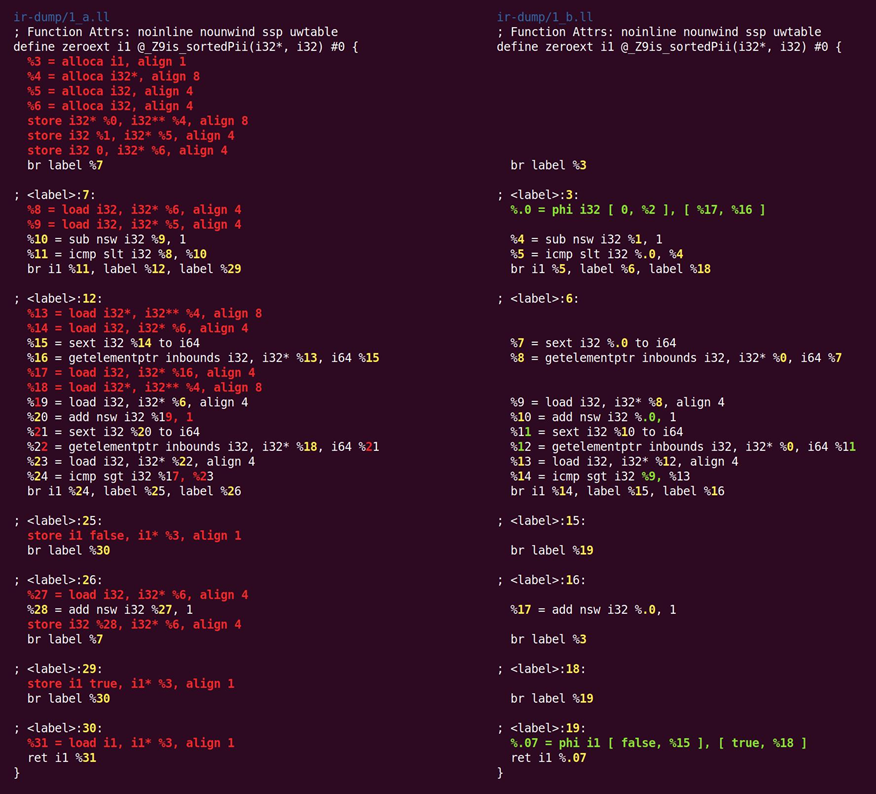
图10.2 SROA(聚集对象的标量替换,scalar replacement of aggregate)遍
在SROA后,所有alloca指令(以及它们对应的load与store)都消失了,代码变得干净得多,更适合后续的优化(当然,SROA通常不能消除所有的alloca——仅在指针分析可以完全消除别名二义性时,这才能工作)。作为这个过程的部分,SROA必须插入某些phi指令。Phi是SSA表示的核心,由Clang发布代码缺少phi告诉,Clang发布SSA的一个平凡类型,其中基本块间的通信是通过内存,而不是通过SSA寄存器。
接下来是
早期公共子表达式消除(CSE)。CSE尝试消除人们编写的代码和部分优化的代码中出现的冗余子计算。早期CSE是快速的,一种查找平凡冗余计算的简单CSE,如图10.3所示。
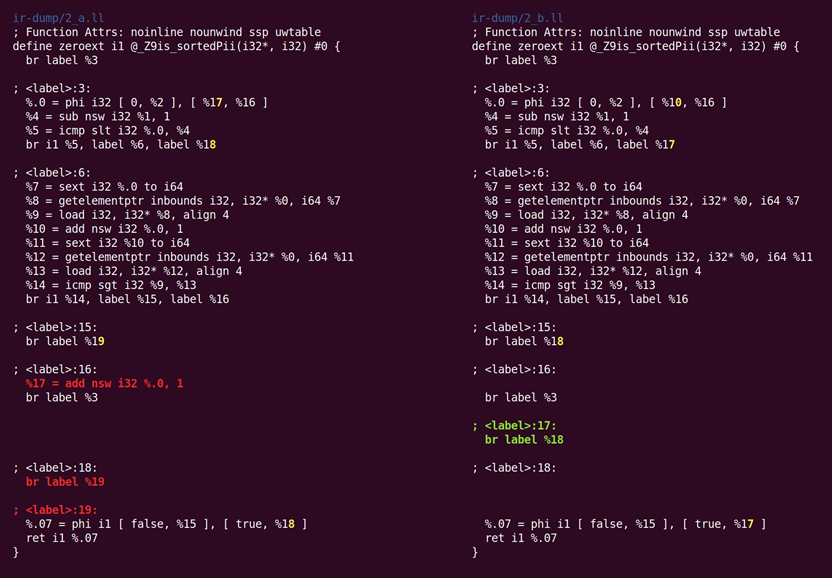
图10.3 早期公共子表达式消除(CSE)遍
这里%10与%17做相同的事情,因此其中一个值的使用可以被重写为另一个值的使用,然后消除了冗余指令。了解一下的SSA的优点:因为每个寄存器仅分配一次,没有寄存器多个版本这样的内容。因此,可以使用语法等价检测冗余计算,不依赖更深入的程序分析(对内存位置不成立,它在SSA世界之外)。
这个遍将改变简单的、地址没有被获取的全局变量。如果显然成立,它将读/写全局全局标记为常量,删除仅写入的变量等。
如图10.4所示,它进行了以下改变:
添加的内容是一个函数属性:由编译器一部分用来向另一个部分保存可能有用的事实的元数据。
不像已经看过的其他优化,全局变量优化器是过程间的,它查看整个LLVM模块。模块或多或少等价于C或C++中的编译单元。相反过程内优化一次仅查看一个函数。
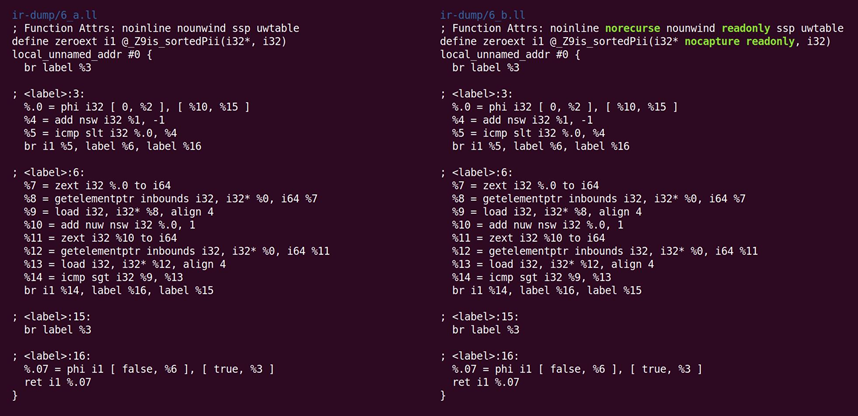
下一个遍是
指令合并器:InstCombine。它是一大组多种多样的窥孔优化,它们(通常)将一组由数据流连接的指令重写为更高效的形式。InstCombine将不改变函数的控制流。如图10.5所示,在这个例子中,它没有太多事情可做:
这里不是从%1减去1来计算%4,决定加上-1。这是一个规范化而不是优化。当有多种方式表示一个计算时,LLVM尝试规范化到一个形式(通常任意选择),这个形式是LLVM遍与后端期望看到的。由InstCombine进行的第二个改变是将计算%7与%11的两个符号扩展操作规范化为零扩展(zext)。在编译器可以证明sext的操作数是非负时,这是一个安全的或转换。这里就是这个情形,因为循环归纳变量从零开始,在到达n之前停止(如果n是负的,循环永远不会执行)。最后的改变是向产生%10的指令添加nuw(没有无符号回绕)标记。可以看到这是安全,通过观察到:
1)归纳变量总是递增的。
2)如果一个变量从零开始且递增,在到达仅次于UINT_MAX的无符号回绕边界前,穿过仅次于INT_MAX的有符号回绕边界,它将变成未定义的。这个标记可用于证明后续优化的合理性。
接着,如图10.6所示,SimplifyCFG第二次运行,删除两个空的基本块:
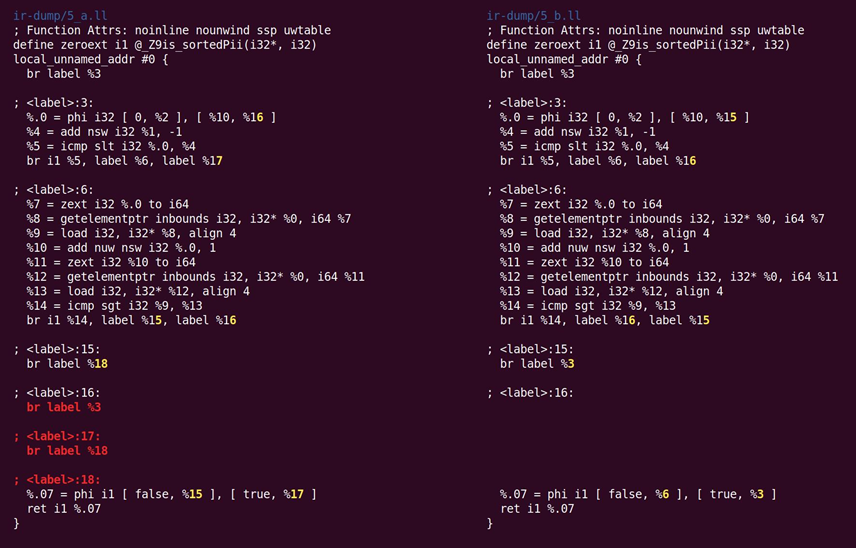
图10.6 SimplifyCFG第二次运行,删除两个空的基本块
Norecurse表示该函数没有涉及在任何递归循环中,而一个readonly函数不改变全局状态。在函数返回后,不保存nocapture参数,而readonly参数援引没有被函数修改的储存对象。
10.2 改进优化条件
接着,
偏转循环移动代码,尝试改进后续优化的条件,如图10.8所示:
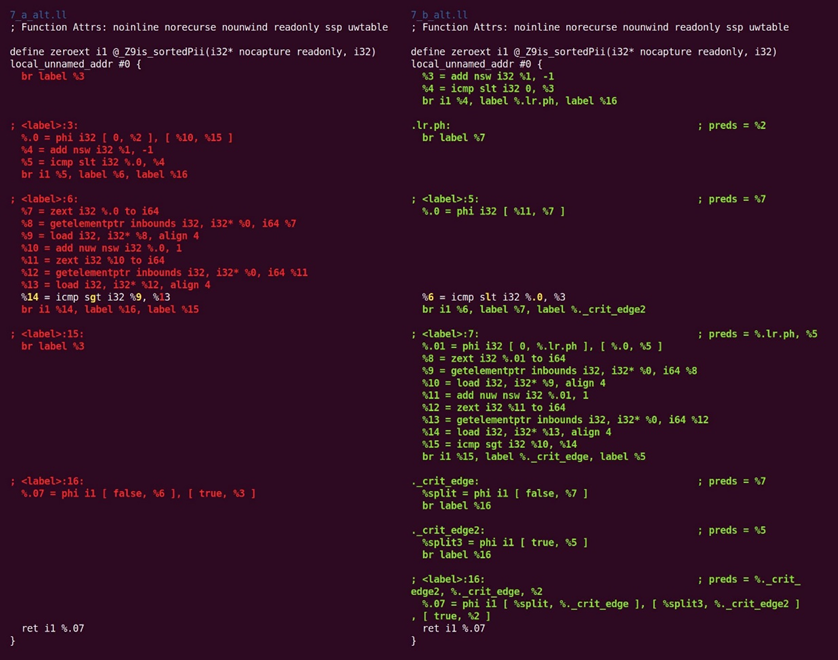
图10.8 偏转循环移动代码,改进后续优化的条件
虽然这个diff看起来有点令人担忧,但发生的事情并不多。通过要求LLVM绘制循环偏转前后的控制流图,可以更容易看到发生了什么。如图10.9所示,这是前(左)后(右)的视图:
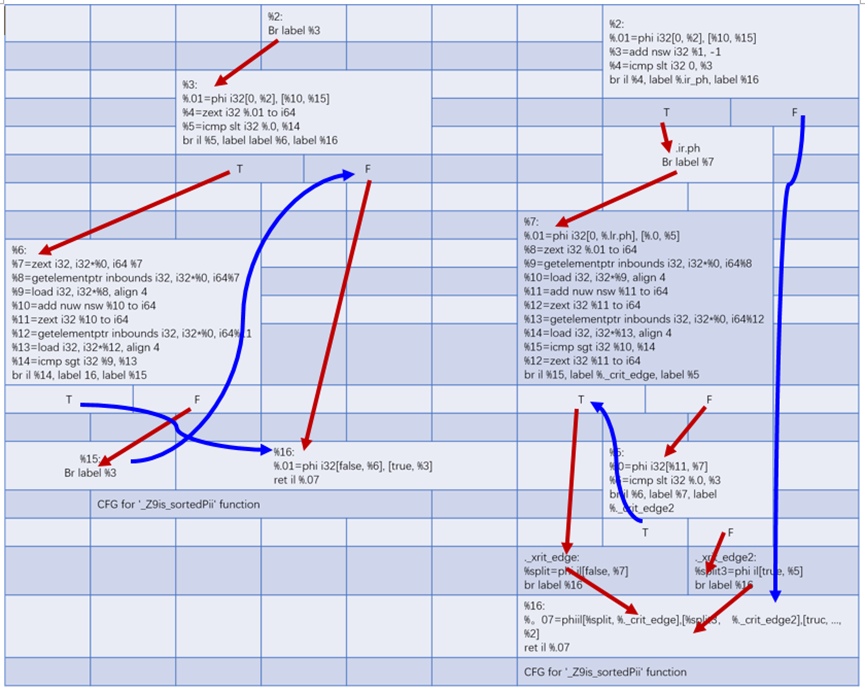
图10.9 LLVM绘制循环偏转前后的控制流图
原始的代码仍然匹配由Clang发布的循环结构:
initializer
goto COND
COND:
if (condition)
goto BODY
else
goto EXIT
BODY:
body
modifier
goto COND
EXIT:
而偏转循环是这样的:
initializer
if (condition)
goto BODY
else
goto EXIT
BODY:
body
modifier
if (condition)
goto BODY
else
goto EXIT
EXIT:
循环偏转的要点是删除一个分支并激活后续优化。目前没有找到这个转换的更好的描述。
如图10.10所示,CFG简化折叠掉了两个仅包含退化(单输入)phi节点的基本块:
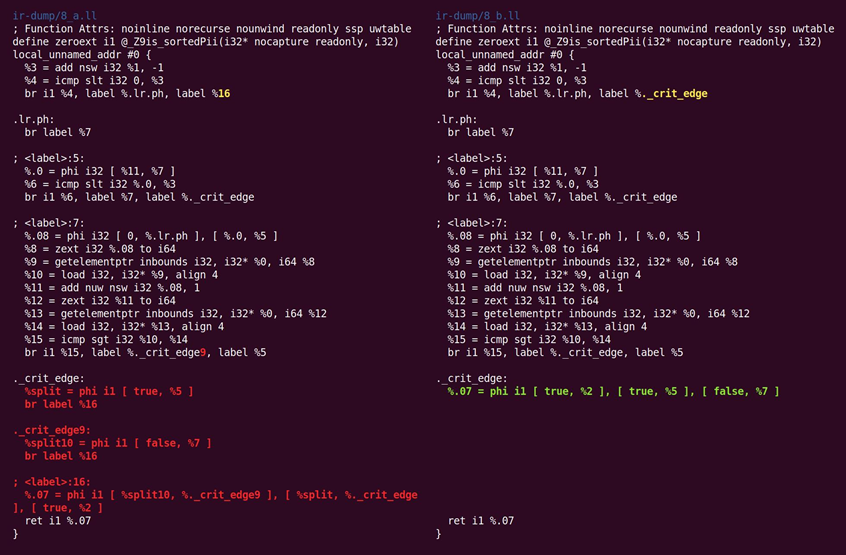
图10.10 CFG简化折叠掉退化(单输入)phi节点的基本块
指令合并器将%4 = 0 s< (%1 – 1)重写为%4 = %1 s> 1,这种操作很有用,因为它减少了依赖链的长度,还可能创建死指令。这个遍还消除了另一个在循环偏转期间增加的平凡phi节点,如图10.11所示:
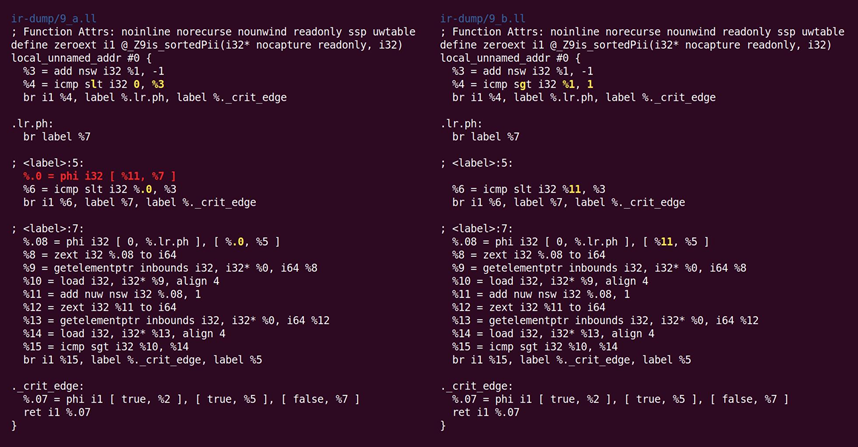
图10.11 消除在循环偏转期间增加的平凡phi节点
这个遍执行几个转换将自然循环转换为更简单的形式,这使得后续分析与转换更简单、高效。循环头前(pre-header)插入,确保从循环外部到循环头有单个非关键入口边。这简化了若干分析与转换,比如LICM。
循环退出块插入确保循环的所有退出块(前驱在循环内的循环外部块),仅有来自循环内部的前驱(因而由循环头支配)。这简化了构建在LICM里诸如储存下沉(store-sinking)的转换。
这个遍还保证循环将仅有一条回边。
间接br指令引入几个复杂性。如果该循环包含一条间接br指令,或由一条间接br指令进入,转换该循环并得到这些保证可能是不可能的。在依赖它们之前,客户代码应该检查这些条件成立。
注意simplifycfg遍将清除被拆分出但最终无用的块,因此使用这个遍不应该对生成的代码感到悲观。
这个遍显然修改了CFG,但更新了循环信息与支配者信息。
如图10.12所示,可以看到插入了循环退出块:
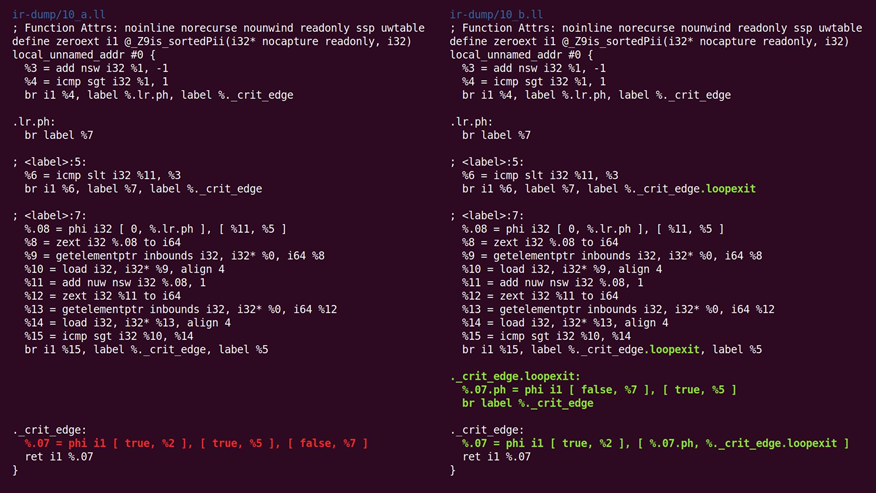
图10.12 插入了循环退出块
这个转换分析并把归纳变量(以及从它们导出的计算),转换为适合后续分析与转换的更简单形式。
如果循环的行程计数是可计算的,这个遍也进行下面的改变:
1)循环的退出条件被规范化为将归纳变量与退出值比较。这将像for (i = 7; i*I < 1000; ++i)的循环转换为for (i = 0; i != 25; ++i)。
2)从归纳变量推导的表达式,在循环外的任意使用被改变为计算循环外的推导值,消除了对归纳变量推导值的依赖。如果循环的仅有目的是计算某个推导表达式的退出值,这个转换将使得这个循环死亡。
这个遍的效果只是将32位归纳变量重写为64位,如图10.13所示:
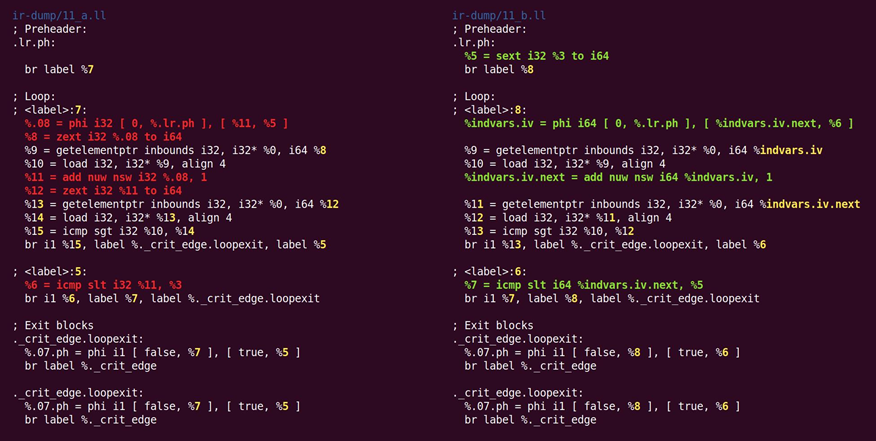
图10.13 将32位归纳变量重写为64位
不知道为什么zext——之前从sext规范化的——被转换回sext。
现在
全局值编号执行一个非常聪明的优化。看是否能通过这个diff找出它,如图10.14所示:
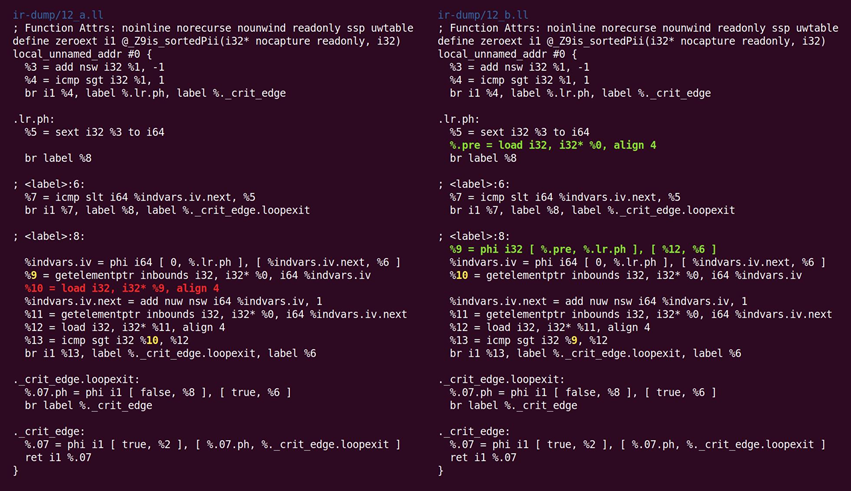
图10.14 全局值编号通过diff优化
找到了吗?左边循环里的两个load对应a[i]与a[i+1]。这里GVN断定载入a[i]是不必要的,因为来自一次循环迭代的a[i+1],可以转发到下一次迭代作为a[i]。这个简单的技巧,将这个函数发出的载入数减半。LLVM与GCC都是最近得到这个转换的。
这个文件实现了比特追踪死代码消除遍。某些指令(偏转,某些and、or等)终结某些输入比特。追踪这些死比特并删除仅计算这些死比特的指令。
但事实证明这个额外的清理是不需要的,因为仅有的死代码是GEP,它是明显死的(GVN删除了之前使用它计算的地址的load),如图10.15所示:
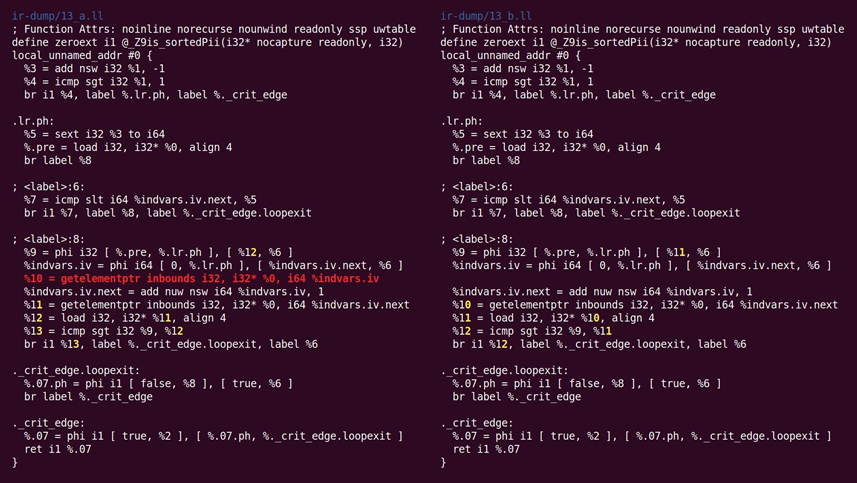
图10.15 额外的清理是不需要的,因为死代码是GEP是死的
现在指令合并器将一个add下沉到另一个基本块。将这个转换放入InstCombine背后的基本原理不清楚。也许没有比这更明显的地方了,如图10.16所示:
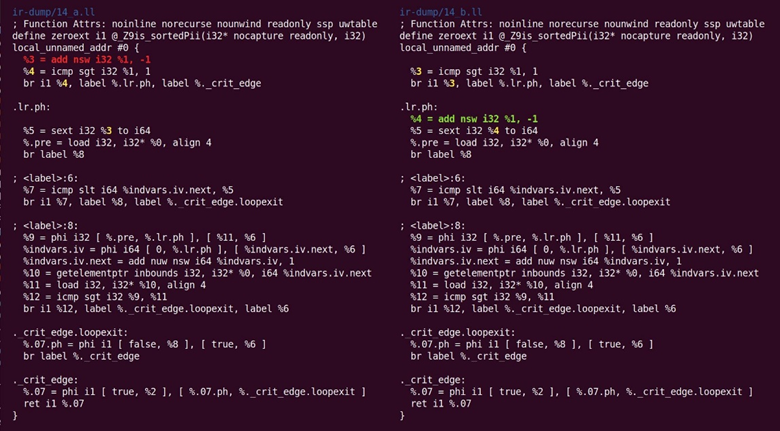
图10.16 指令合并器将add下沉到基本块
现在事情有点奇怪了,
跳转线程化撤销了规范化自然循环之前做的事情,如图10.17所示:
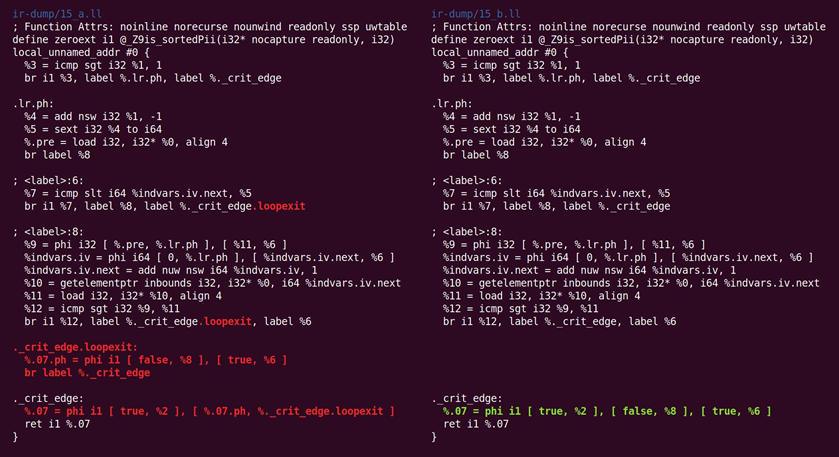
图10.17 跳转线程化撤销规范化自然循环之前的操作
如图10.18所示,然后规范化它回来:
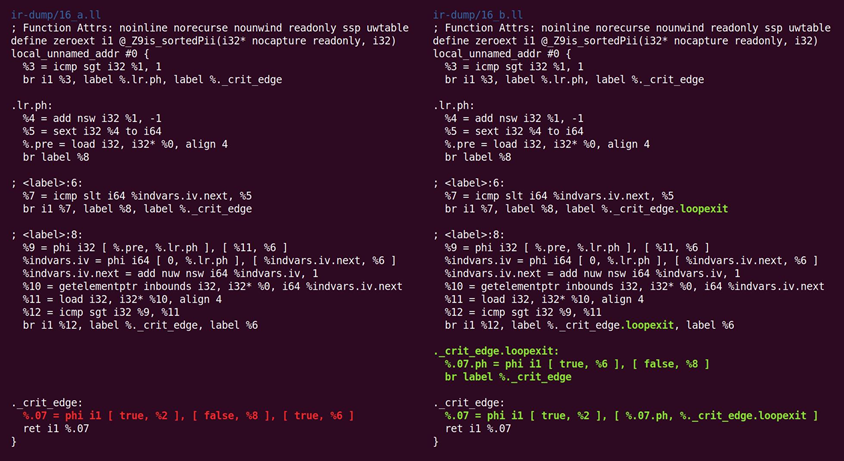
图10.18 规范化回来操作
CFG简化又把它翻过来了,如图10.19所示:
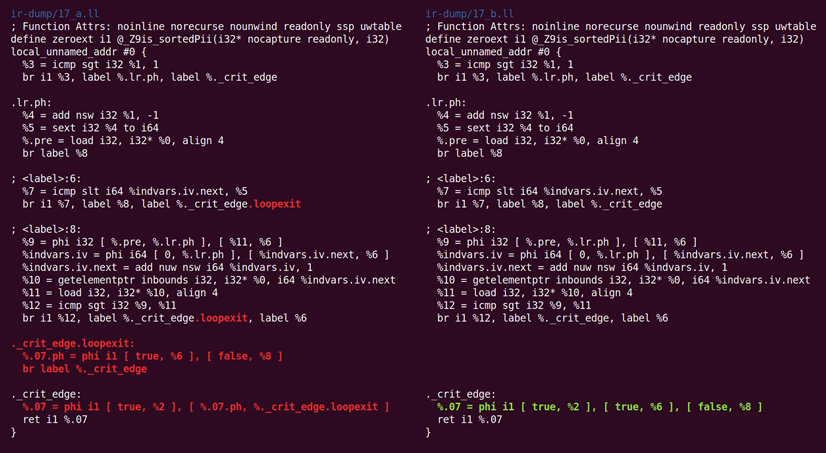
图10.19 CFG简化翻过来的操作
如图10.20所示,又回来:
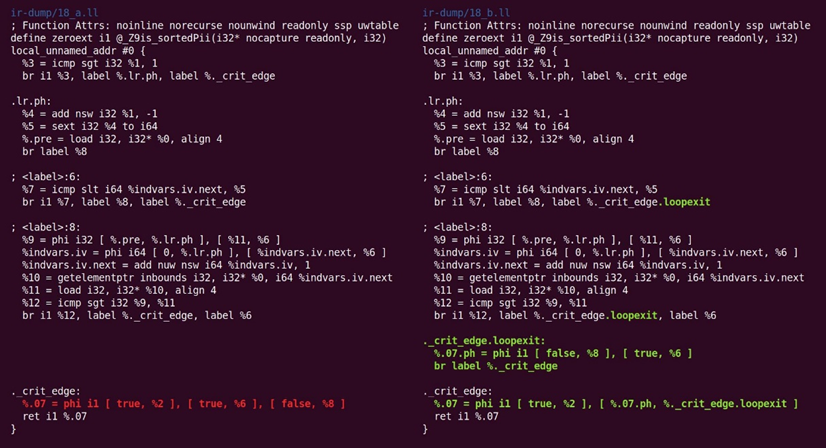
图10.20 规范化重新回来操作
如图10.21所示,又回去:
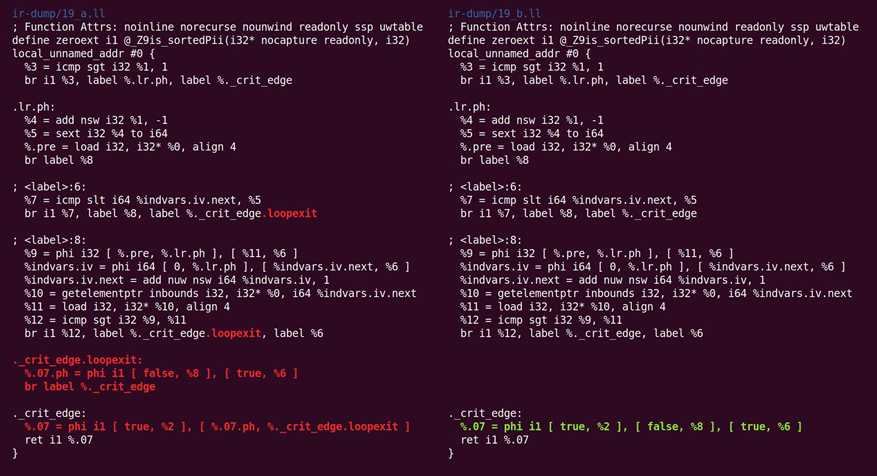
图10.21 CFG简化又翻过来的操作
如图10.22所示,又回来:
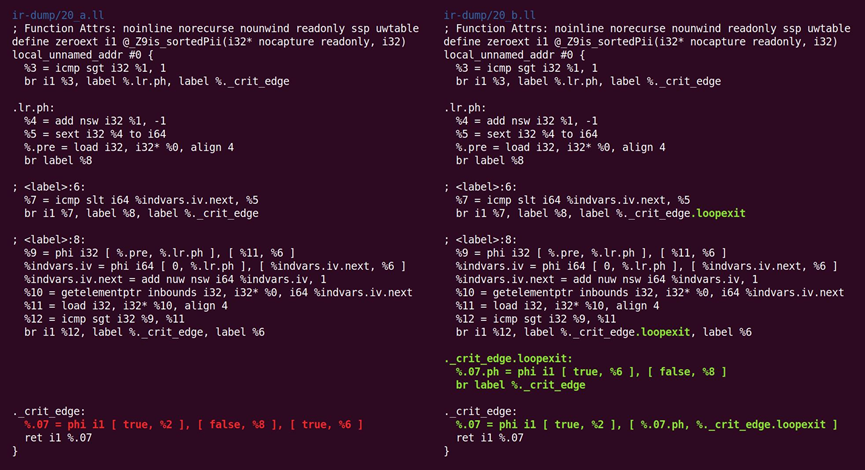
图10.22 规范化又回来操作
如图10.23所示,又回去:
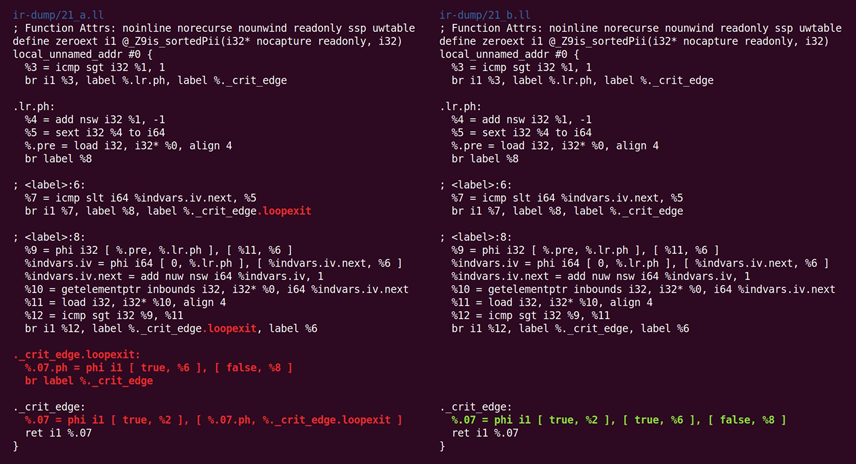
图10.23 CFG简化又翻过来的操作
终于完成了中端。右边的代码是(在这个情形里)传递给x86-64后端的代码。可能想知道在遍流水线末尾的震荡行为是否是编译器的缺陷,但记住这个函数真的是简单,在翻来覆去中混合了一大群遍,但没有提到它们,因为它们没有改变代码。就中端优化流水线的后半部分而言,基本上在这里看到的是一个退化的执行。
10.3 LTO(Link Time Optimization)链接时优化
10.3.1 LTO基本概念
官方说得很清楚,开启LTO主要有这几点好处
1)将一些函数內联化。
2)去除了一些无用代码。
3)对程序有全局的优化作用。
所以对包大小造成影响的应该是前面两点。
什么是LTO?参考如图10.24所示说明。

图10.24 什么是LTO?
LTO就是build设置中的一个编译选项,正如其名一样,Link Time Optimization,就是在链接的时候对程序进行了一些优化。具体来看看到底怎么优化的,如图10.25所示。
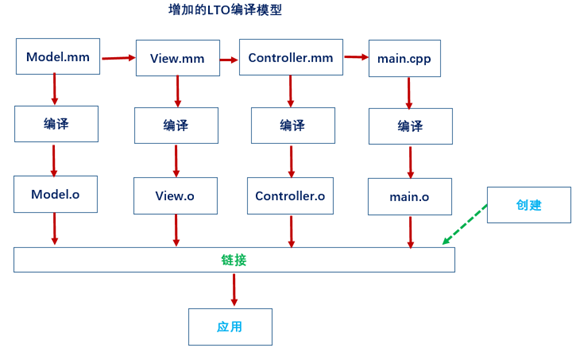
图10.25 LTO优化方法
一个程序的运行过程如图10.26所示,所有的文件编译成.o文件,然后所有的.o文件与一些需要的framework再通过链接生成一个.app文件,也就是最后的可执行文件。
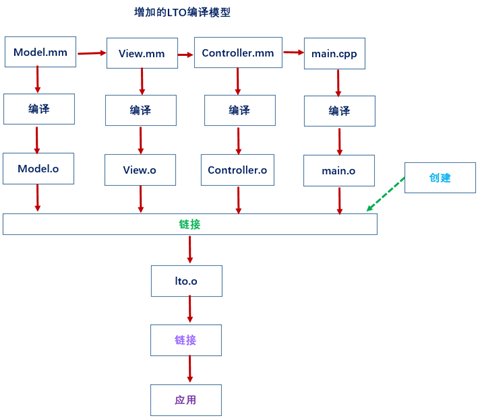
图10.26 一个编译程序的运行过程
在开启LTO(Monolithic)后这些.o文件会附带一些优化信息,让它们在link的时候生成一个单一的整体的.o文件,再与需要的framework链接生成可执行文件。
10.3.2 LTO优化处理
苹果官方称,已经在应用软件中大量使用LTO,并且相比常规release模式在运行速度上提升了10%。此外它还会使用PGO(按配置优化)来优化代码,并且还能减小代码体积。
这里也带来了很明显的缺点,特别是在有调试信息的时候,代码编译耗时和更大的内存占用,且二次编译的时候得全部重新编译。
1)LTO以编译时间换取运行时性能。
2)大内存需求。
3)优化不是并行进行的。
4)增量构建重复所有工作。
于是苹果又做了一个优化,就是仅开启表行。官方描述如下:
1)调试信息级别
2)切换启用调试符号时发出的调试信息量。这可能会影响生成的调试信息的大小,这在某些情况下对大型项目很重要(例如使用LTO时)。
在开启表行后LTO内存占用提升百分之四十,如图10.27所示。

图10.27 开启表行后LTO内存提升百分之四十
开启前,如图10.28所示。
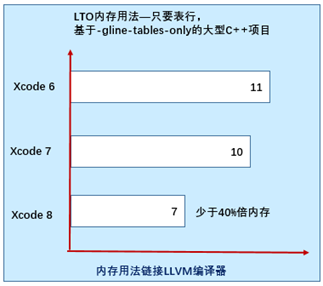
图10.28 开启表行前
开启后
这就是LTO开启monolithic所进行的优化,所以苹果之前也是建议在开启LTO的同时开启表行。不过这还没完,后来苹果又有了一个新的技术,也就是LTO的incremental。
新的LTO主要又做了下面这几个改进。
1)分析和内联不合并目标文件。
2)提升编译速度。
3)二次编译有链接器缓存。
下面看看开启incremental后的build过程,如图10.29所示:
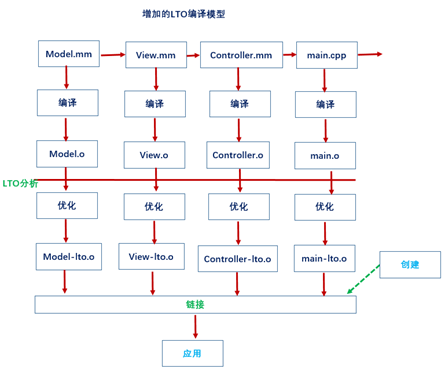
图10.29 开启incremental后的build过程
这里主要过程是,在生成.o文件后,会产生一个analysis文件由于链接的优化。然后每个.o文件通过优化后生成一个新的.o文件,再与其它framework进行链接。这里通过LTO链接后会有一个link cache,当下次build的时候,如果没有修改,就不需要重新编译,所以二次编译就会很快,只需要编译和链接少数修改过的文件。
苹果再次优化了incremental LTO,让link的时间有了更显著的提升,所以现在即使不开启表行,也是可以开启LTO的了。
10.3.3 linkmap分析
由于在项目中开启LTO后包大小反而增大,感觉这不太符合预期。于是查看了一下linkmap,发现TEXT、DATA、Symbols这些字段,在开启LTO后确实都有减小,而Dead Stripped Symbols显示的符号大大的减少了。猜测是因为项目中开启了符号剥离,在没有开启LTO的时候,符号剥离比较完全,而开启LTO后对符号剥离造成了影响,使符号剥离的数量大大减小,从而对包大小也带来了影响。
开启LTO主要是对链接过程的一个优化,并且有link cache,使二次编译的速度更快,另一方面它还很有可能减小代码大小,在前面的linkmap分析中,确实基本可以保证开启LTO能对代码进行优化,但是由于对符号剥离的影响,具体是否能减小包大小还是得通过打包测试。这里建议还是在release模式下开启LTO。由于开启LTO后会对断点的单步执行有影响,如图10.30所示。

图10.30 开启LTO后会对断点的单步执行有影响
所以debug模式下还是不建议开启。
10.4 Nutshell LLVM LTO(Link Time Optimizer) 链接时优化
10.4. 1 ThinLTO
1. ThinLTO概述
如图10.31所示为ThinLTO基础架构。图10.31右边英文对应的中文解释如下:
1)本地参考/调用图
2)模块Hash(对于增加的构建)
3)完全参考/调用图
4)基于分析结构的并行过程转换
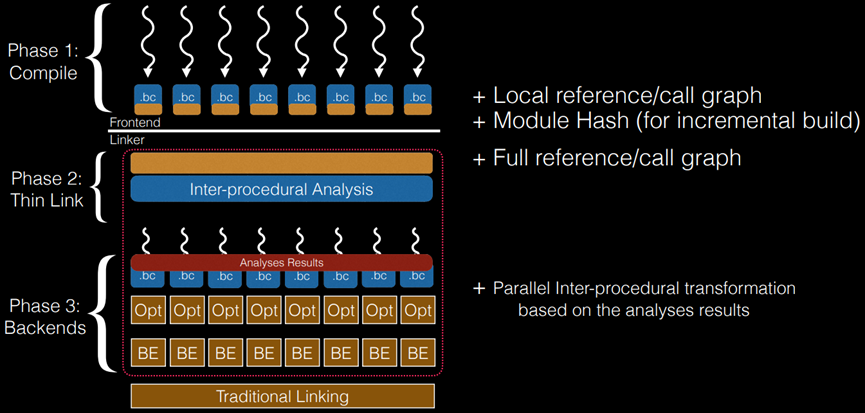
图10.31 ThinLTO基础架构
2. ThinLTO设计
1)从一开始就为大型(谷歌规模)应用程序设计。
2)完全并行的编译步骤和后端支持分布式构建。
3)模块是编译单元,支持增量构建。
4)仅对每个模块执行有利可图的跨模块优化。
5)存储器缩放。
6)精简串行同步步骤。
7)完全并行(非常无聊)的常规优化和CodeGen。
如图10.32所示表示ThinLTO设计方法。
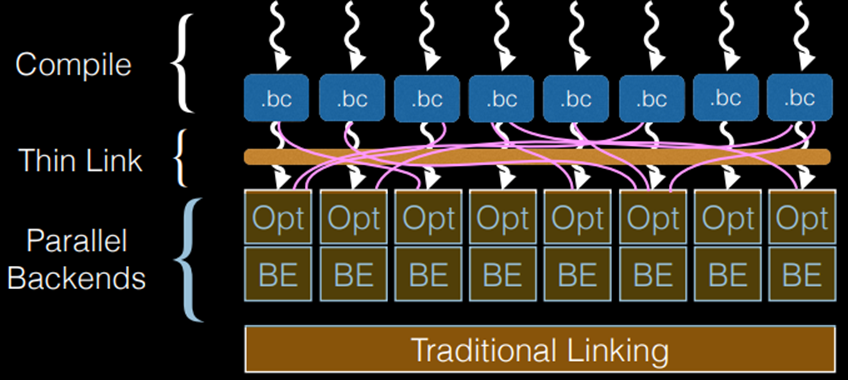
图10.32 ThinLTO设计
生成了.o文件,但实际上是LLVM LTO中原始位代码文件main.o test1.o test2.o,在Nutshell静态存档中将包含这些位代码文件。生成了.o文件,但它们实际上是原始位代码文件main.o test1.o test2.o LLVM LTO:在Nutshell静态存档中,将包含这些位代码文件,如图10.33所示。
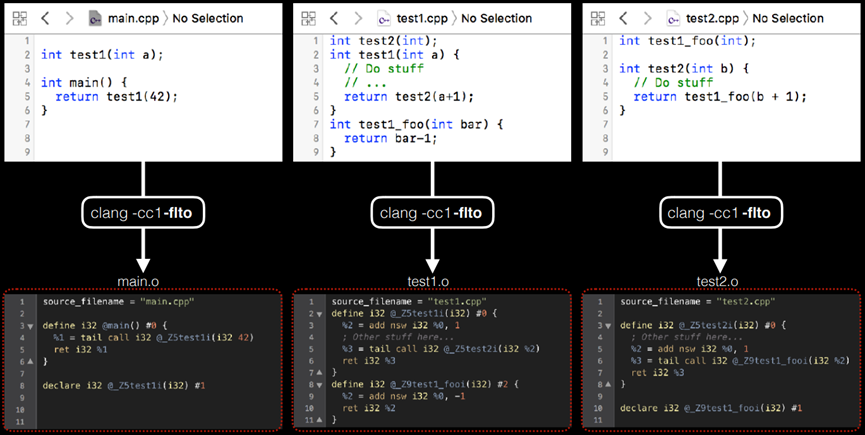
图10.33 在Nutshell静态存档的位代码文件
10.4.2高度并行的前端处理+初始优化
将所有位代码链接到一个单一的,模块优化器/内嵌单线程非常复杂的,常规优化潜在线程CodeGen中,如图10.34所示。
图10.34中右边英文对应中文解释如下:
+高并行前端处理
+初始化优化
在一个模块中链接所有位码
+单片LTO实现
+单线程
+潜在的线程
+代码生成
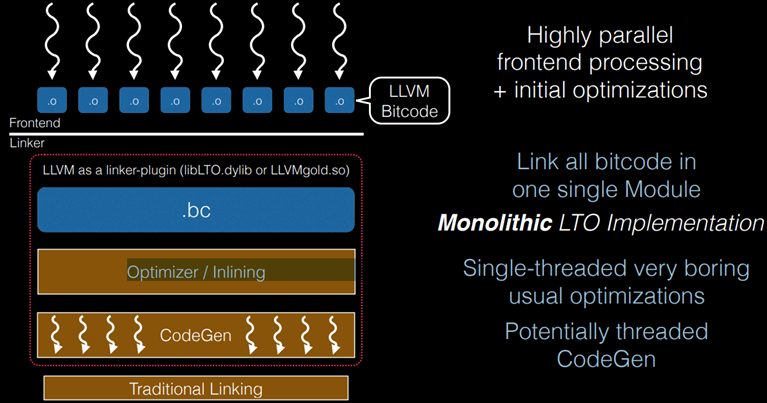
图10.34将所有位代码链接到CodeGen中
1. 性能:Clang的链接时间
如图10.35表示 Clang的链接时间。
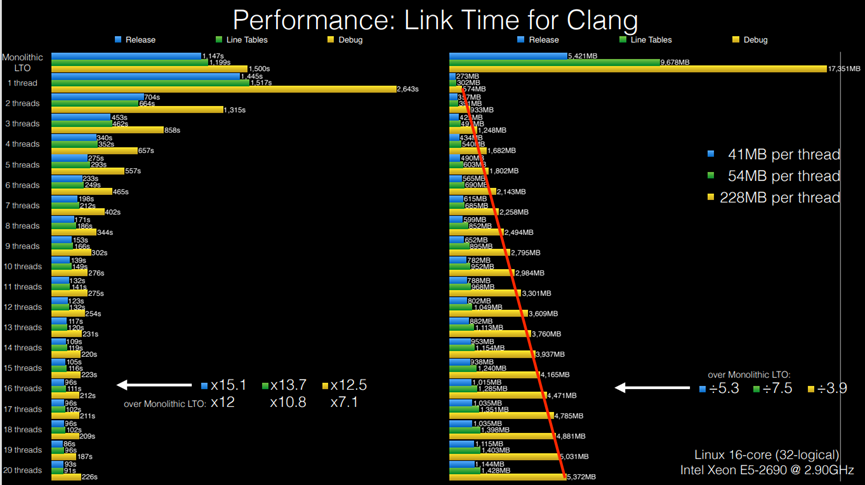
图10.35 Clang的链接时间
2. ThinLTO: 分布式构建
图10.36表示ThinLTO的分布式构建。图10.36右边英文对应中文解释如下:
1)流式输出每个后端作业
2)分析结果生成相关模块列表:
构建系统为每个作业捆绑模块独立索引文件封装了增量构建决策所需的信息。基于分析结果的分布式过程间转换。
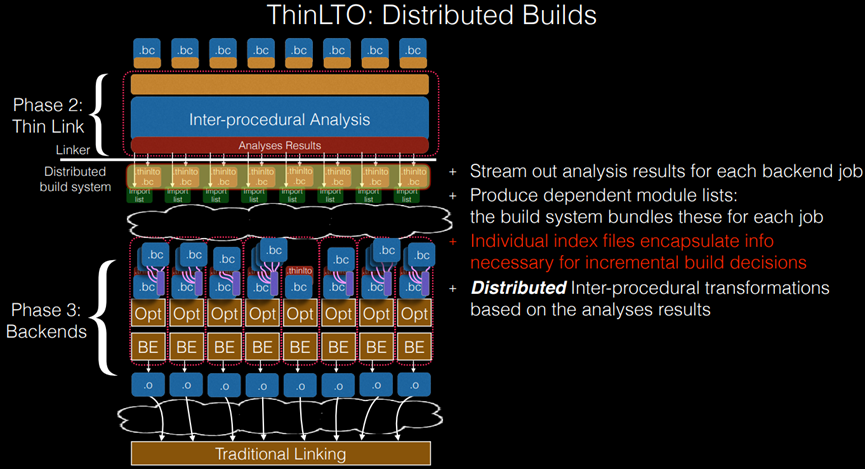
图10.36 ThinLTO的分布式构建
3. 重新审视ThinLTO:增量构建
如图10.37所示表示重新审视ThinLTO的增量构建。
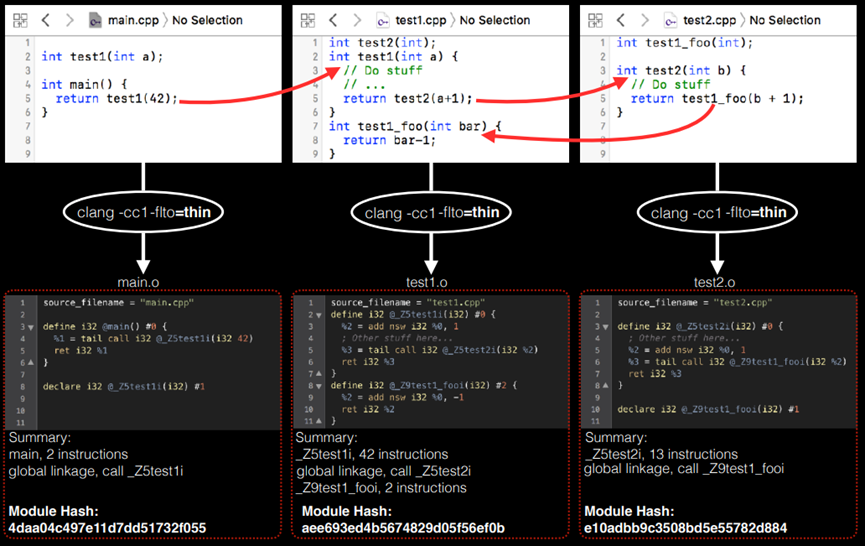
图10.37 重新审视ThinLTO的增量构建
配置文件导向优化(PGO):导入启发式。
只有cold会被内联。
导入程序只会导入cold。
对于PGO数据,cold将不会被内联,hot将被内联(如果可用的话)。
镜像内联启发式,为热边提供奖励,为冷边提供惩罚。如图10.38所示表示镜像内联启发式方法。
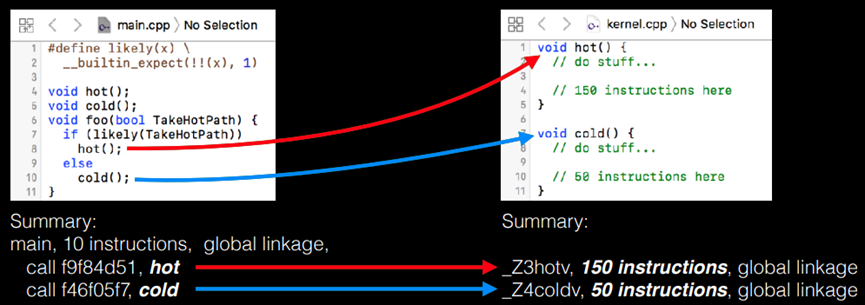
图10.38 镜像内联启发式方法
PGO间接调用升级
总结记录了可能的间接调用。目标为定期调用(推测)。图10.39所示表示 PGO间接调用升级。
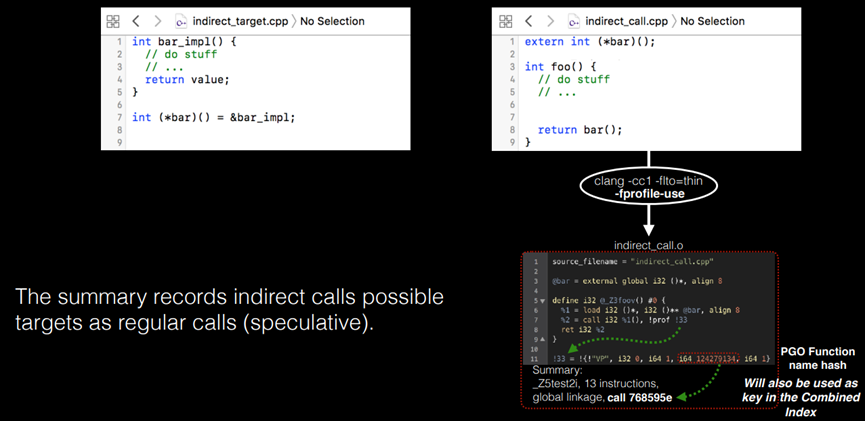
图10.39 PGO间接调用升级
4. Thin-Link IPA未来优化示例:全局变量
如图10.40所示表示Thin-Link IPA未来全局变量优化示例。
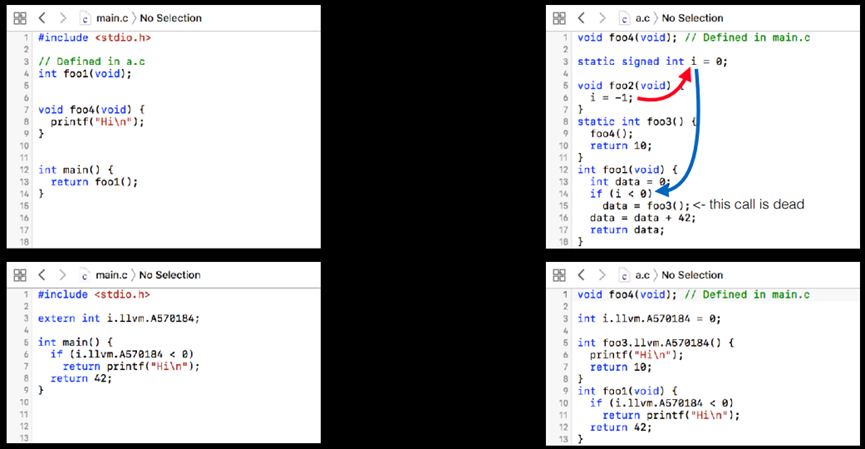
图10.40 Thin-Link IPA未来全局变量优化示例
(左边)已知i.llvm.A570184的范围(这里更容易:它是一个常数),可以将测试折叠为false。(右边)所有这些代码都可以被链接器完全剥离,但是需要时间来优化/codegen。这只是更好地基于关键优化机会的一个例子。
5. 重新审视ThinLTO:编译阶段
如图10.41所示表示重新审视ThinLTO的编译。
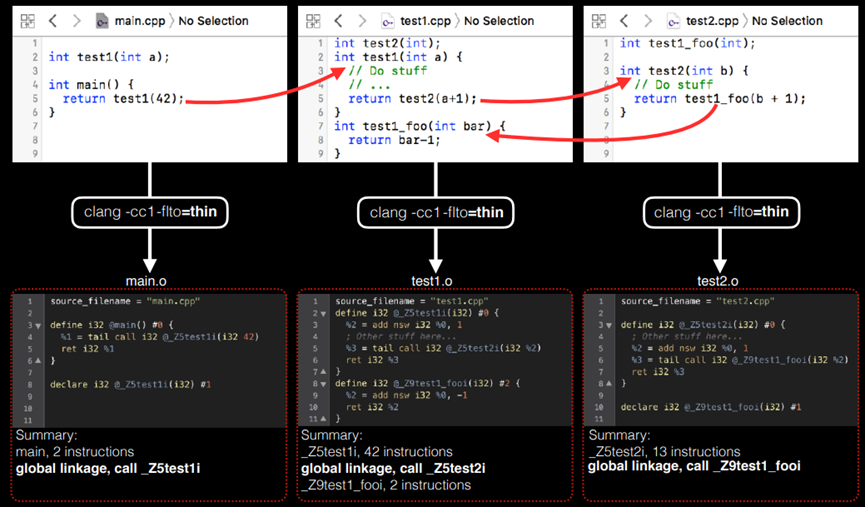
图10.41 重新审视ThinLTO的编译阶段
6. ThinLTO模型:摘要生成
如图10.43所示表示ThinLTO模型的摘要生成。
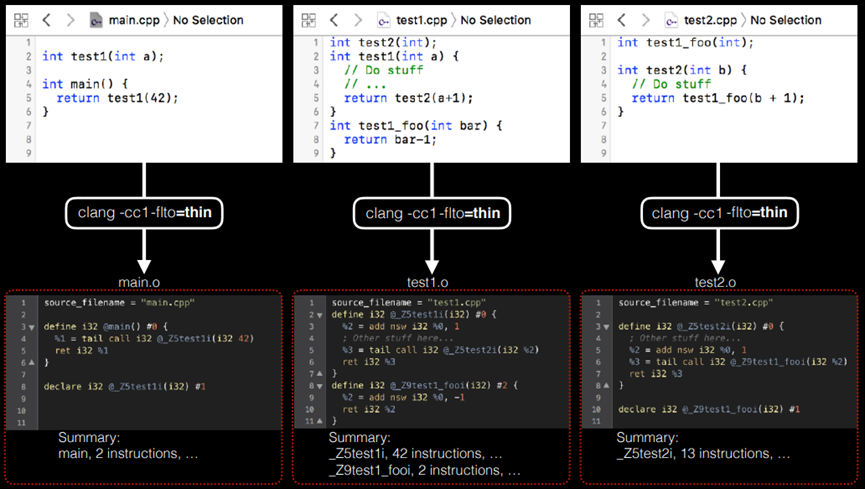
图10.43 ThinLTO模型的摘要生成
如图10.44所示,摘要也可以包含配置文件数据(PGO),也可以使用其他属性进行扩展。
图10.44 摘要包含配置文件数据(PGO),也可使用其他属性进行扩展
10.5 LLVM完全LTO(link time optimization)
10.5.1 LLVM LTO目标都包含了哪些?
使用链接时间优化LTO方法的示例,如下所示。
--- a.h ---
extern int foo1(void);
extern void foo2(void);
extern void foo4(void);
--- a.c ---
#include "a.h"
static signed int i = 0;
void foo2(void) {
i = -1;
}
static int foo3() {
foo4();
return 10;
}
int foo1(void) {
int data = 0;
if (i < 0)
data = foo3();
data = data + 42;
return data;
}
--- main.c ---
#include <stdio.h>
#include "a.h"
void foo4(void) {
printf("Hi\n");
}
int main() {
return foo1();
}
编译 LTO 的版本,可以看到 a_lto.o 比 a.o 多了1.2 K的内容。
$ clang -flto -c a.c -o a_lto.o
$ clang -c a.c -o a.o
$ ls -alh
...
-rw-r--r-- 1 xxx 1.6K Feb 2 14:41 a.o
-rw-r--r-- 1 xxx 2.8K Feb 2 14:41 a_lto.o
使用 hexdump 来打印目标文件中的内容,知道魔幻数字通常用来识别文件格式。a.o 肯定是普通的ELF文件,ELF 文件的魔幻数字是 7F 45(E) 4C(L) 46(F)。所以把焦点专注在a_lto.o 的魔幻数字4342 dec0上。
$ hexdump a_lto.o | head
0000000 4342 dec0 1435 0000 0005 0000 0c62 2430
0000010 594d 66be fb8d 4fb4 c81b 4424 3201 0005
0000020 0c21 0000 0262 0000 020b 0021 0002 0000
0000030 0016 0000 8107 9123 c841 4904 1006 3932
$ hexdump a.o | head
0000000 457f 464c 0102 0001 0000 0000 0000 0000
0000010 0001 003e 0001 0000 0000 0000 0000 0000
通过 man ascii 知道,42 43 分别是 B C,llvm IR 有三种表示形式:文本,内存,以及 bitcode。所以猜测 BC 就是 bitcode的意思。
Oct Dec Hex Char Oct Dec Hex Char
------------------------------------------------------------------------
# ...
002 2 02 STX (start of text) 102 66 42 B
003 3 03 ETX (end of text) 103 67 43 C
# ...
由此按图搜索,找到位码的魔幻数字如下。正好与 4342 dec0 进行对应,总共 4 个字节。
[‘B’8,‘C’8,0x04,0xC4,0xE4,0xD4]
对于位代码文件格式,有专门的工具LLVM比特码分析器进行分析,dump 出来的数据很多。
$ llvm-bcanalyzer -dump a_lto.o
# ...
Summary of a_lto.o:
Total size: 22592b/2824.00B/706W
Stream type: LLVM IR
# Toplevel Blocks: 4
# ...
Block ID #12 (FUNCTION_BLOCK):
Num Instances: 3
Total Size: 956b/119.50B/29W
Percent of file: 4.2316%
Average Size: 318.67/39.83B/9W
Tot/Avg SubBlocks: 6/2.000000e+00
Tot/Avg Abbrevs: 0/0.000000e+00
Tot/Avg Records: 20/6.666667e+00
Percent Abbrevs: 35.0000%
Record Histogram:
Count # Bits b/Rec % Abv Record Kind
4 184 46.0 INST_STORE
3 57 19.0 100.00 INST_LOAD
3 24 8.0 100.00 INST_RET
3 66 22.0 DECLAREBLOCKS
2 128 64.0 INST_CALL
2 56 28.0 INST_BR
1 40 INST_CMP2
1 46 INST_ALLOCA
1 28 100.00 INST_BINOP
Block ID #13 (IDENTIFICATION_BLOCK_ID):
# ...
Block ID #14 (VALUE_SYMTAB):
# ...
Block ID #15 (METADATA_BLOCK):
# ...
Block ID #17 (TYPE_BLOCK_ID):
# ...
Block ID #21 (OPERAND_BUNDLE_TAGS_BLOCK):
# ...
Block ID #22 (METADATA_KIND_BLOCK):
# ...
Block ID #23 (STRTAB_BLOCK):
# ...
Block ID #24 (FULL_LTO_GLOBALVAL_SUMMARY_BLOCK):
# ...
Block ID #25 (SYMTAB_BLOCK):
# ...
根据位代码文件按照一定格式对数据进行了组织,不做详细分析。使用 llvm-dis 将其转换为人类可读的形式。可以看到 a_lto.o 中编码的就是LLVM IR。
如果仔细阅读LLVM文档的话,可以发现:
在ThinLTO模式中,与常规LTO一样,clang在编译阶段后输出LLVM位代码。ThinLTO位代码增加了模块的紧凑摘要。在链接步骤中,只读取摘要并将其合并到一个组合摘要索引中,该索引包括一个功能位置索引,用于以后跨模块导入功能。然后对组合的汇总索引执行快速且高效的整个程序分析。
// ThinLTO
; ModuleID = 'a_lto.o'
source_filename = "a.c"
target datalayout = "e-m:e-p270:32:32-p271:32:32-p272:64:64-i64:64-f80:128-n8:16:32:64-S128"
target triple = "x86_64-unknown-linux-gnu"
@i = internal global i32 0, align 4
; Function Attrs: noinline nounwind optnone uwtable
define dso_local void @foo2() #0 {
entry:
store i32 -1, i32* @i, align 4
ret void
}
; Function Attrs: noinline nounwind optnone uwtable
define dso_local i32 @foo1() #0 {
entry:
%data = alloca i32, align 4
store i32 0, i32* %data, align 4
%0 = load i32, i32* @i, align 4
%cmp = icmp slt i32 %0, 0
br i1 %cmp, label %if.then, label %if.end
if.then: ; preds = %entry
%call = call i32 @foo3()
store i32 %call, i32* %data, align 4
br label %if.end
if.end: ; preds = %if.then, %entry
%1 = load i32, i32* %data, align 4
%add = add nsw i32 %1, 42
store i32 %add, i32* %data, align 4
%2 = load i32, i32* %data, align 4
ret i32 %2
}
; Function Attrs: noinline nounwind optnone uwtable
define internal i32 @foo3() #0 {
entry:
call void @foo4()
ret i32 10
}
declare dso_local void @foo4() #1
attributes #0 = { noinline nounwind optnone uwtable "frame-pointer"="all" "min-legal-vector-width"="0" "no-trapping-math"="true" "stack-protector-buffer-size"="8" "target-cpu"="x86-64" "target-features"="+cx8,+fxsr,+mmx,+sse,+sse2,+x87" "tune-cpu"="generic" }
attributes #1 = { "frame-pointer"="all" "no-trapping-math"="true" "stack-protector-buffer-size"="8" "target-cpu"="x86-64" "target-features"="+cx8,+fxsr,+mmx,+sse,+sse2,+x87" "tune-cpu"="generic" }
!llvm.module.flags = !{!0, !1, !2, !3, !4}
!llvm.ident = !{!5}
!0 = !{i32 1, !"wchar_size", i32 4}
!1 = !{i32 7, !"uwtable", i32 1}
!2 = !{i32 7, !"frame-pointer", i32 2}
!3 = !{i32 1, !"ThinLTO", i32 0}
!4 = !{i32 1, !"EnableSplitLTOUnit", i32 1}
!5 = !{!"clang version 14.0.0 (https://github.com/llvm/llvm-project.git 58e7bf78a3ef724b70304912fb3bb66af8c4a10c)"}
^0 = module: (path: "a_lto.o", hash: (0, 0, 0, 0, 0))
^1 = gv: (name: "foo2", summaries: (function: (module: ^0, flags: (linkage: external, visibility: default, notEligibleToImport: 1, live: 0, dsoLocal: 1, canAutoHide: 0), insts: 2, funcFlags: (readNone: 0, readOnly: 0, noRecurse: 0, returnDoesNotAlias: 0, noInline: 1, alwaysInline: 0, noUnwind: 1, mayThrow: 0, hasUnknownCall: 0, mustBeUnreachable: 0), refs: (^2)))) ; guid = 2494702099028631698
^2 = gv: (name: "i", summaries: (variable: (module: ^0, flags: (linkage: internal, visibility: default, notEligibleToImport: 1, live: 0, dsoLocal: 1, canAutoHide: 0), varFlags: (readonly: 1, writeonly: 1, constant: 0)))) ; guid = 2708120569957007488
^3 = gv: (name: "foo1", summaries: (function: (module: ^0, flags: (linkage: external, visibility: default, notEligibleToImport: 1, live: 0, dsoLocal: 1, canAutoHide: 0), insts: 13, funcFlags: (readNone: 0, readOnly: 0, noRecurse: 0, returnDoesNotAlias: 0, noInline: 1, alwaysInline: 0, noUnwind: 1, mayThrow: 0, hasUnknownCall: 0, mustBeUnreachable: 0), calls: ((callee: ^5)), refs: (^2)))) ; guid = 7682762345278052905
^4 = gv: (name: "foo4") ; guid = 11564431941544006930
^5 = gv: (name: "foo3", summaries: (function: (module: ^0, flags: (linkage: internal, visibility: default, notEligibleToImport: 1, live: 0, dsoLocal: 1, canAutoHide: 0), insts: 2, funcFlags: (readNone: 0, readOnly: 0, noRecurse: 0, returnDoesNotAlias: 0, noInline: 1, alwaysInline: 0, noUnwind: 1, mayThrow: 0, hasUnknownCall: 0, mustBeUnreachable: 0), calls: ((callee: ^4))))) ; guid = 17367728344439303071
^6 = flags: 8
^7 = blockcount: 5
但是这里有一个问题,如果链接时没有添加 -flto 选项的话,不会进行 lto 优化的。那么编译时添加 -flto 链接时没有 -flto,那么 linker 直接处理是 LLVM IR,链接能够通过吗?是可以直接处理的。例如对于 lld 来说,它会根据目标文件的类型,选择合适的函数来对 lto 位码文件进行处理。这里是 LinkDriver::link -> compileBitcodeFiles。
// 进行实际链接。注意,当调用该函数时,所有链接器脚本都已解析。
template <class ELFT> void LinkerDriver::link(opt::InputArgList &args) {
// ...
if (!bitcodeFiles.empty()) {
// ...
// 如果给定的文件是LLVM位代码文件,请执行链接时间优化。
// 这会将位代码文件编译为实际目标文件。
//
// 这样,符号表应该是完整的。在这之后,除了一些链接器合成的名称之外,没// 有任何新名称将被添加到符号表中。
compileBitcodeFiles<ELFT>();
// ...
}
// ...
}
至此知道了,对于完全LTO 来说,生成的出来就是位码,存储的就是LLVM IR。lld会根据目标文件类型来选择合适的函数进行处理。
LTO 过程是如何进行的。
首先给出 lld 在处理 lto目标时的完整命令。
~/workspace/llvm-project/build/bin/ld.lld --hash-style=both --eh-frame-hdr -m elf_x86_64 -dynamic-linker /lib64/ld-linux-x86-64.so.2 -o exe /lib/x86_64-linux-gnu/crt1.o /lib/x86_64-linux-gnu/crti.o /usr/lib/gcc/x86_64-linux-gnu/8/crtbegin.o -L/usr/lib/gcc/x86_64-linux-gnu/8 -L/usr/lib/gcc/x86_64-linux-gnu/8/../../../../lib64 -L/lib/x86_64-linux-gnu -L/lib/../lib64 -L/usr/lib/x86_64-linux-gnu -L/usr/lib/../lib64 -L/usr/local/bin/../lib -L/lib -L/usr/lib -plugin-opt=mcpu=x86-64 a-lto.o main-lto.o -lgcc --as-needed -lgcc_s --no-as-needed -lc -lgcc --as-needed -lgcc_s --no-as-needed /usr/lib/gcc/x86_64-linux-gnu/8/crtend.o /lib/x86_64-linux-gnu/crtn.o
10.5.2 lld整个执行流程
接下来,给出 lld 整个的执行流程,整体分为三个部分,如图10.45所示:
1. 准备过程,主要包括配置的处理,搜索并打开文件,为这些文件创建对应的 lld 处理对象;
2. LTO 后端,如果 lld 在处理的过程中,发现有 lto 目标 (前面提到 lto 目标 其实就是位码格式文件)的话,设置 BitcodeCompiler,然后转入 lld lto 过程;
1)计算死函数。
2)将它们连接成一个整体的 IR 模块。
3)更新 visibility。
4)构建 LTO优化管道。
5)执行真正的优化。
6)代码生成。
3. LLD 的链接过程
1)此时所有的文件已经准备好了,将输入部分聚合在一起。
2)gc-sections。
3)计算各个部分聚合在一起后,各个symbol的offset等信息,并进行重定位。
4)相同代码折叠。
5)最终的结果输出。
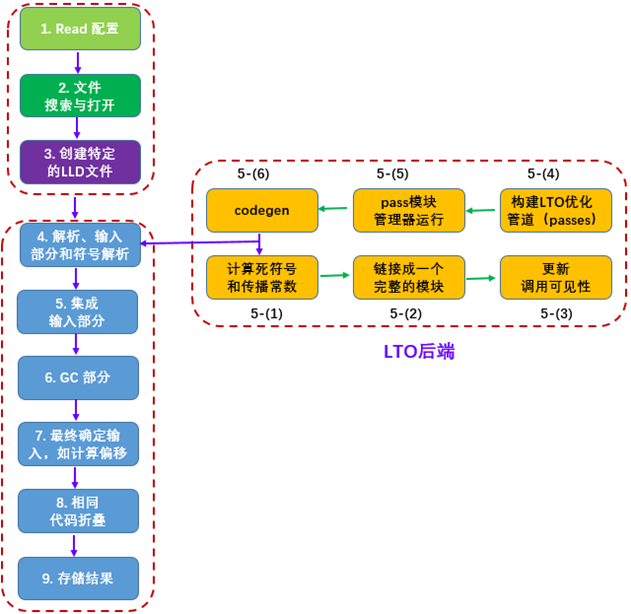
图10.45 lld整个执行流程包括三部分
详细过程如下图10.46所示:
图10.46左下部的英文部分对应中文解释如下:
此函数用于链接时间的所有优化进行优化。使用LTO时,一些输入文件不是本机对象文件格式,而是LLVM格式比特码格式。因为该程序的所有位代码文件的组成被立即传递给编译器,它可以执行整个程序优化。
lld::elf::LinkDriver{
std::unique_ptr<BitcodeCompiler> lto;
std::vector<InputFile*> files;
}
如果允许,升级公共vcall可见性元数据在整个程序之前连接单元的可见性优化器中的机会不足。
合并扫描的所有位代码文件,codegen结果,并返回生成的ObjectFile。
基于传递的LTO默认优化管道构建经理这提供了良好的默认优化用于链路时间优化和代码生成的流水线。它经过特别调整,在IR进入时非常适合LTO阶段首先通过addPreLinkLTODefaultPipeline运行,二者密切配合。
终于进入了LLVM后端优化部分。
现在有了一个完整的输入文件列表。
然后,它最终确定每个合成部分,以便计算每件的输出偏移输入部分。
现在有了一套完整的输出部分。此函数完成部分内容。例如,需要在字符串中添加字符串表,并将条目添加到.get和.plt,finalizeSections就是这样做的。
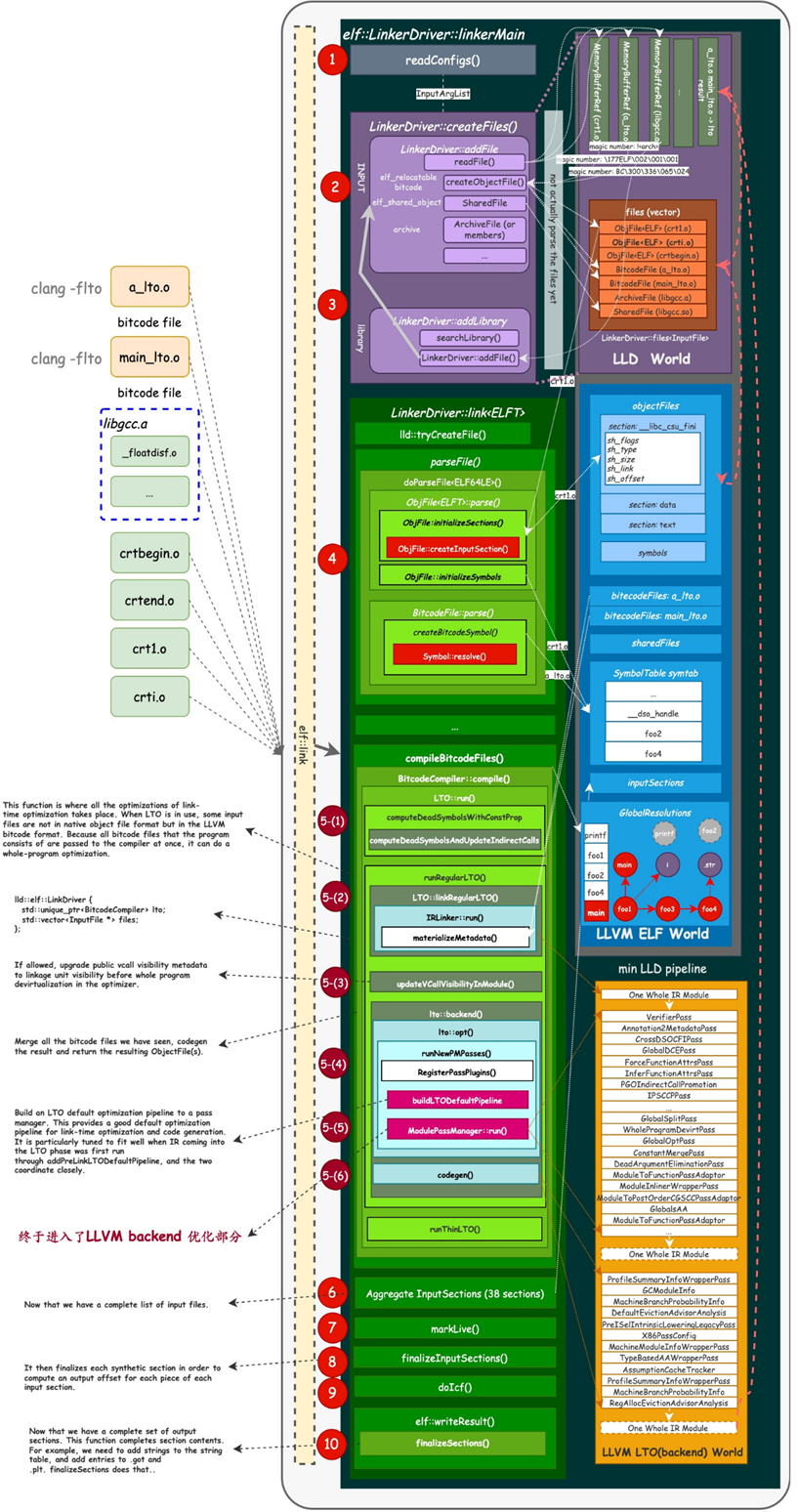
图10.46 lld整个执行流程详细过程
准备
1)配置。
2)搜索和打开文件。
3)添加和创建文件。
4)分析文件。
LTO后端
5-(1) 计算死函数。
前面使用 llvm-dis 将 lto 编译后,得到的位码文件进行处理后得到的IR中,有一系列的 gv,表示的是全局值摘要条目(Global Variable)。
对于链接较弱的符号,组合摘要索引中可以有多个条目。
使用ThinLTO进行编译可以生成一个紧凑的模块摘要,该摘要将被发送到位代码中。摘要被发送到LLVM程序集中,并在语法中由插入符号(“^”)标识。
如图10.47所示是 main_lto.o 中的全局变量信息。
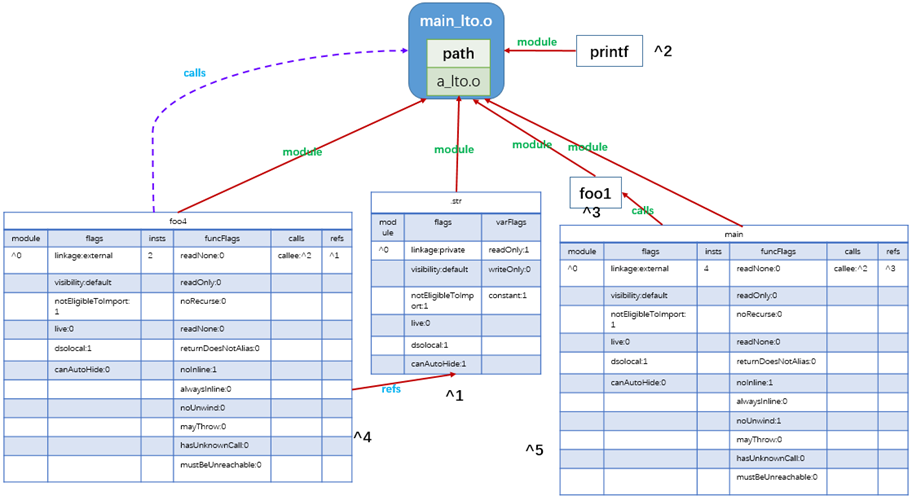
图10.47 main_lto.o 中的 gv 信息
如图10.48所示是 a_lto.o 中的全局变量信息。
computeDeadSymbolsWithConstProp 会调用 computeDeadSymbolsAndUpdateIndirectCalls,该函数基于一个根集,使用 worklist 算法来计算得到 live sets。
根集目前只有一个 main 函数,首先将其设置为 live,将其压到 Worklist 中,然后根据 refs 和 calls 关系不停地迭代这个 Worklist。
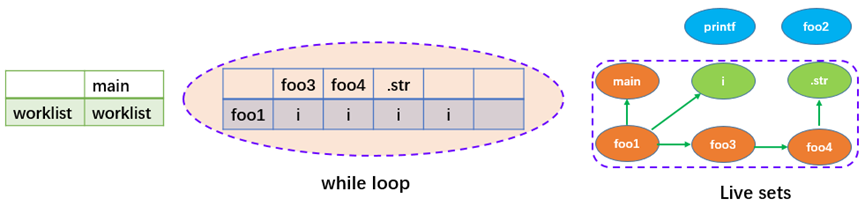
图10.48 a_lto.o 中的 gv 信息
5-(2) 将IR连接在一起,如图10.49所示。
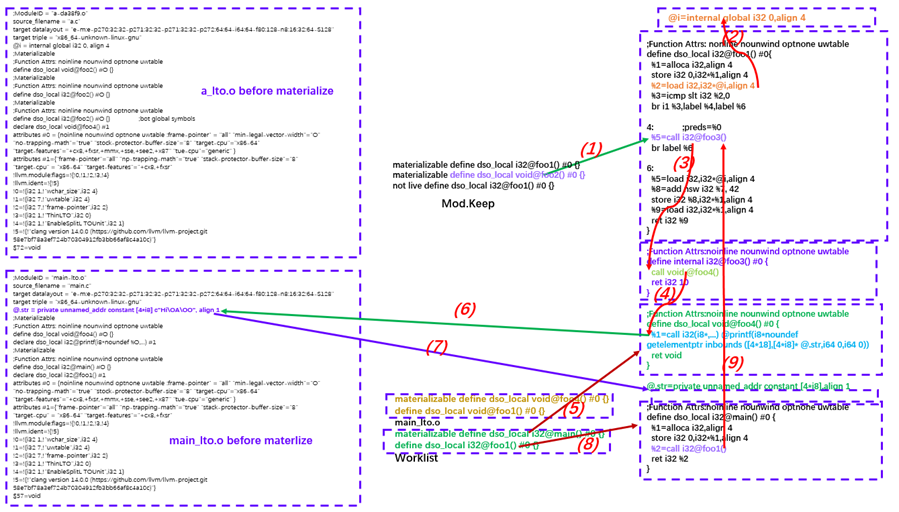
图10.49将IR连接在一起
整个过程是 IRLinker 基于前面 live 信息、符号决议信息,以及符号 visibility 来将各个源模块链接到目标模块,主要是按需实现的过程。
5-(3) 更新调用可见性。
5-(4) 构建LTO优化管道。
buildLTODefaultPipeline预定义一组 passes,然后添加到 ModulePassManager 中。
// 构建到pass管理器的LTO默认优化管道。
//
// This provides a good default optimizationpipelinefor link-time
// 这为链路时间优化和代码生成提供了一个良好的默认优化管道。当进入
// LTO阶段的IR首次通过\c addPreLinkLTODefaultPipeline运行时,它特别适合,
// 并且两者密切协调。
// 优化和代码生成。当进入LTO阶段的IR首次通过时,它被特别调整为非常适合
// addPreLinkLTODefaultPipeline,两者密切配合。请注意,此处/p级别不能为
// “O0”。生成的管道仅用于尝试优化代码时使用。如果前端由于语义原因需要一些
// 转换,那么应该显式地构建它们。
ModulePassManager buildLTODefaultPipeline(OptimizationLevel Level,
ModuleSummaryIndex *ExportSummary);
5-(5) 优化
/// 在给定的IR单元上运行此管理器中的所有pass。ExtraArgs将传递给每个pass。
PreservedAnalyses run(IRUnitT &IR, AnalysisManagerT &AM,
ExtraArgTs... ExtraArgs) {
}
5-(6) 代码生成
在 LTO 执行完成以后,会根据前面 codegen 得到的内容,调用 createObjectFile 创建一个 lld 能够处理的 InputFile,名字为 lto.tmp,按照常规文件,对 lto.tmp 执行一遍解析操作。
6. 集成链接InputSections
如表10.1所示,所有链接的准备工作都已经做完了,目前的 sections 总共有 38 个,可以看到已经没有 a_lto.o 和 main_lto.o,只剩一个 main_lto.o 了。
|
/lib/x86_64-linux-gnu/crt1.o
|
/lib/x86_64-linux-gnu/crti.o
|
/usr/lib/gcc/x86_64-linux-gnu/8/crtbegin.o
|
|
0
|
.note.ABI-tag
|
6
|
.text
|
11
|
.text
|
|
1
|
.text
|
7
|
.data
|
12
|
.data
|
|
2
|
.rodata.cst4
|
8
|
.bss
|
13
|
.bss
|
|
3
|
.eh_frame
|
9
|
.init
|
14
|
.tm_clone_table
|
|
4
|
.data
|
10
|
.fini
|
15
|
.fini_array
|
|
5
|
.bss
|
|
|
|
|
|
p inputSextions[32]
|
/usr/lib/gcc/x86_64-linux-gnu/8/crtend.o
|
/lib/x86_64-linux-gnu/crtn.o
|
|
18
|
.text
|
22
|
.text
|
28
|
.text
|
|
19
|
.data
|
23
|
.data
|
29
|
.data
|
|
20
|
.bss
|
24
|
.bss
|
30
|
.bss
|
|
21
|
.eh_frame
|
25
|
.eh_frame
|
31
|
.init
|
| |
|
26
|
.tm_clone_table
|
32
|
.fini
|
| |
|
27
|
.comment
|
|
|
|
lto.temp
|
|
|
|
|
|
33
|
.text
|
|
|
|
|
|
34
|
.text.fool
|
|
|
|
|
|
35
|
.text.main
|
|
|
|
|
|
36
|
.comment
|
|
|
|
|
|
37
|
.eh_frame
|
|
|
|
|
表10.1 集成链接InputSections
7. GC Sections
8. 完成输入,计算偏移
// 此函数扫描InputSectionBase列表sectionBases以创建
// InputSectionDescription::sections。
//
// 它从输入部分数组中删除MergeInputSections,并在替换的第一个输入部分的位置// 添加新的合成部分。然后,最终确定每个合成部分,以便为每个输入部分的每一部// 分计算输出偏移。
void OutputSection::finalizeInputSections() {}
// 这个函数非常热复杂(即可能需要几秒钟才能完成),因为有时输入的数量是数百// 万的数量级。因此,使用多线程。
// 对于任何字符串S和T,知道如果S的散列为不同于T的值。如果是这样的话,可// 以安全地将s和T转换为不同的字符串生成器,而不用担心合并失败。
// 并行进行。.
void MergeNoTailSection::finalizeContents() {}
9. 相同代码折叠
//ICF是相同代码折叠的缩写。这是一个大小优化,用于识别和合并碰巧具有相同内容// 的两个或多个只读部分(通常是函数)。它通常会将输出大小减少百分之几.
//
// 在ICF中,如果两个节具有相同的节标志、节数据和重新定位,则认为它们是相同// 的。重新定位是很棘手的,因为如果两个重新定位具有相同的重新定位类型、值,// 并且在ICF*方面指向相同的部分*,则它们被认为是相同的。
// 安全ICF: 指针安全和可解卷的gold链接器中的相同代码折叠
//http://static.googleusercontent.com/media/research.google.com/en//pubs/archive/36912.pdf
10. 输出结果
如图10.50所示表示整个输出结果的流程。
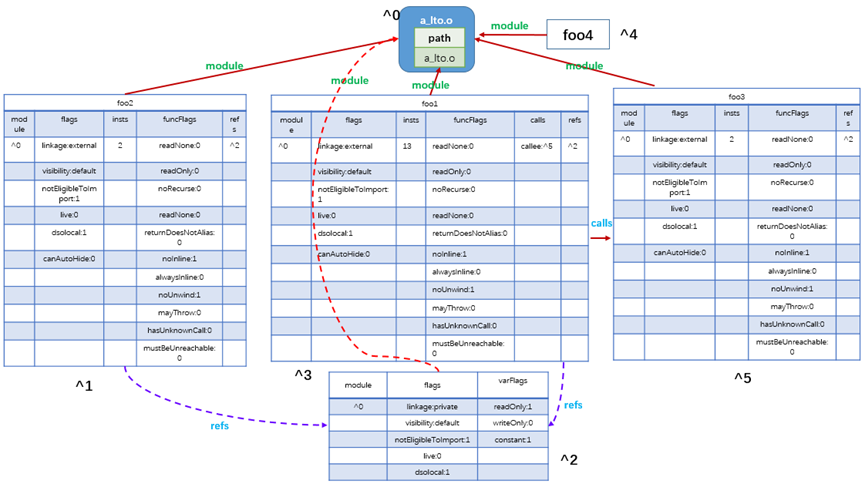
图10.50输出结果流程
10.6 LLVM核心类简明示例
1. llvm::Value
LLVM 核心类简明示例: llvm::Value && llvm::Type && llvm::Constant。
llvm核心类位于 include/llvm/IR中,用以表示机器无关且表现力极强的LLVM IR。
llvm::Value则是这其中的重中之重,它用来表示一个具有类型的值。它是类图如下图10.51所示:
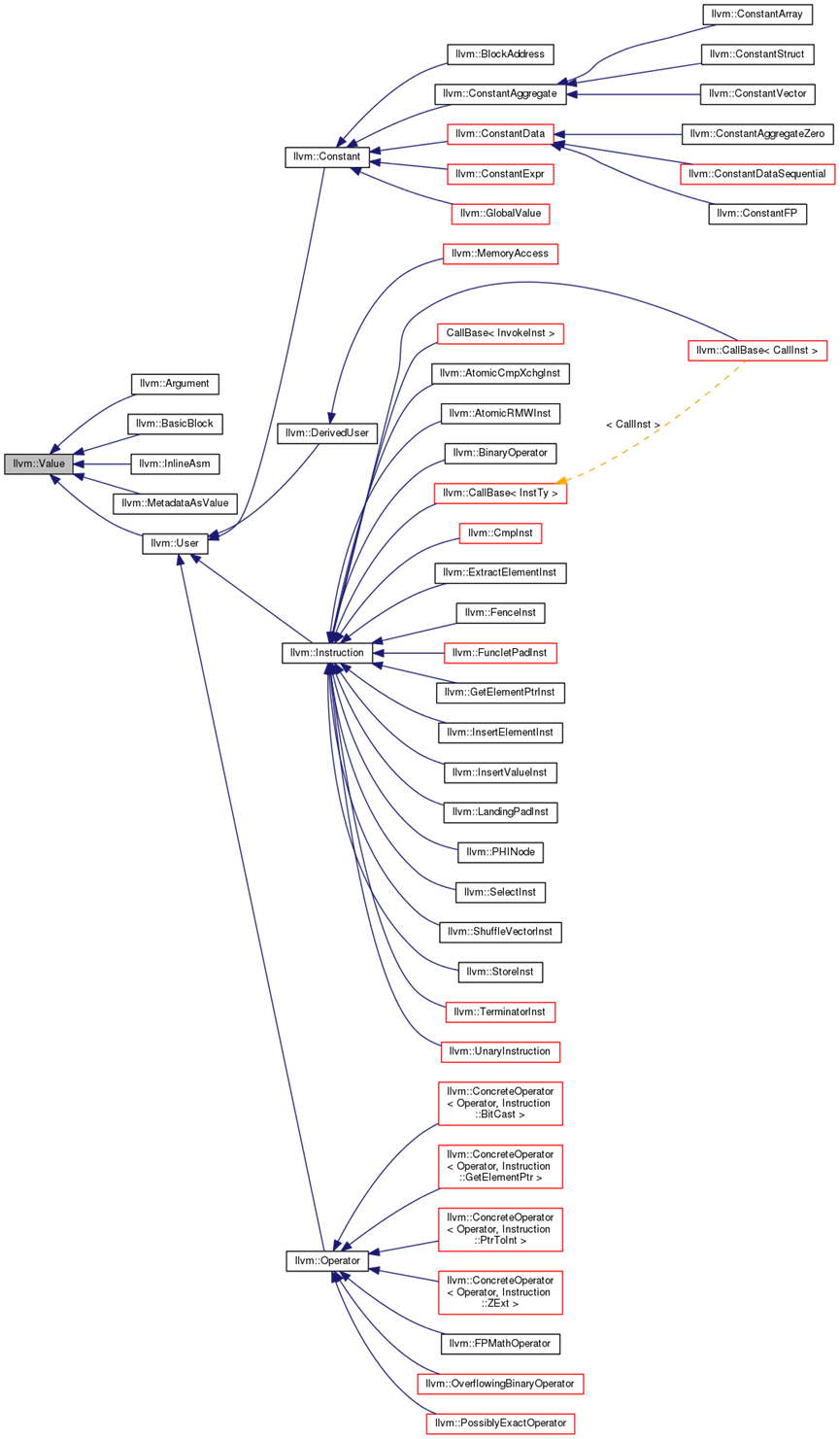
图10.51 llvm::Value类图概貌
llvm::Argument,llvm::BasicBlock,llvm::Constant,llvm::Instruction这些很重要的类都是它的子类。
llvm::Value有一个llvm::Type*成员和一个use list。后者可以跟踪有哪些其他Value使用了自己,可以使用下面的迭代器对它进行访问:
1)unsigned use_size 返回有多少Value使用它。
1) bool use_empty 是否没有Value使用它。
3)use_iterator use_begin 返回use list的迭代器头。
2) use_iterator use_end 返回尾。
3) User *use_back 返回use list的最后一个元素。
int main() {
Value* val1 = ConstantFP::get(theContext, APFloat(3.2)); if (val1->use_empty()) {
std::cout << "no one use it\n";
}
system("pause"); return 0;
}
2. llvm:Type
前者顾名思义表示一个类型。可以通过Value::getType获取到这个llvm::Type*,有一些is*成员函数,可以判断是下面哪种类型:
enum TypeID { // PrimitiveTypes - make sure LastPrimitiveTyID stays up to date.
VoidTyID = 0, ///< 0: type with no size
HalfTyID, ///< 1: 16-bit floating point type
FloatTyID, ///< 2: 32-bit floating point type
DoubleTyID, ///< 3: 64-bit floating point type
X86_FP80TyID, ///< 4: 80-bit floating point type (X87)
FP128TyID, ///< 5: 128-bit floating point type (112-bit mantissa)
PPC_FP128TyID, ///< 6: 128-bit floating point type (two 64-bits, PowerPC)
LabelTyID, ///< 7: Labels
MetadataTyID, ///< 8: Metadata
X86_MMXTyID, ///< 9: MMX vectors (64 bits,X86specific)
TokenTyID, ///< 10: Tokens
// Derived types... see DerivedTypes.h file.
// Make sure FirstDerivedTyID stays up to date!
IntegerTyID, ///< 11: Arbitrary bit width integers
FunctionTyID, ///< 12: Functions
StructTyID, ///< 13: Structures
ArrayTyID, ///< 14: Arrays
PointerTyID, ///< 15: Pointers
VectorTyID ///< 16: SIMD 'packed' format, or other vector type
};
比如这样:
int main() {
Value* val1 = ConstantFP::get(theContext, APFloat(3.2));
Type* t = val1->getType(); if (t->isDoubleTy()) {
std::cout << "val1 is typed as double(" << t->getTypeID() <<")\n";
}
system("pause"); return 0;
}
除此之外llvm::Type还有很多成员函数。
还可以对 llvm::Value 进行命名
bool hasName() const
std::string getName() const
void setName(const std::string &Name)
3. llvm::Constant
llvm::Constant表示一个各种常量的基类,基于它派生出了ConstantInt 整型常量,ConstantFP 浮点型常量,ConstantArray 数组常量,ConstantStruct 结构体常量:
int main() { // 构造一个32位,无符号的整型值,值为1024
APInt ci = APInt(32, 1024);
ConstantInt* intVal = ConstantInt::get(theContext, ci);
std::cout << "bit width:" << intVal->getBitWidth()
<< "\nvalue:" << intVal->getValue().toString(16, false);
system("pause"); return 0;
}