概述
hash table 和 B+ Tree 可以说是数据库中最重要的两种数据结构。DBMS 的 page table 或者 page directory 都可以说用到了 hash table。
hash function
sha-256 的计算成本过高(我们无需关心它在密码学方面的特性),xxhash 算法非常快。
完美哈希函数 $f$ 定义如下: $$ if\ a \neq b,\ then\ f(a) \neq f(b)$$
现实中并不存在完美的哈希函数。
推荐使用 xxhash3。
hash schemes
即哈希碰撞(hash collision)时的处理方案。我们考虑哈希表像数组那样组织,通过哈希函数可以计算出 key 对应的数组索引,即 key <> slot(这里将数组的每个位置称为 slot)。
static hash scheme
linear probe hashing
它的原理非常简单,假设 key a 被映射到 slot A,之后假设 key a1 也被映射到 slot A,然而 slot A 已经被占用了,那么它就会往下遍历,直到找到一个新的空 slot。
当需要从哈希表中删除元素时,我们一般不真正执行删除(这里的删除可以类比删除数组元素),而是将这个 slot 标记为空(可能需要用到额外的一个 bit)。
当一个 key 对应着多个 value 时,我们的做法有两个,一是建立一个链表,链表中的元素的 key 都相同;还有一种做法是,采用 linear probe hashing,依次填入 slot。
后面这个做法更常见一些。
robin hood hashing
它是线性探测方法的一种拓展,会记录每个 key 与它本来应该存在的位置(即 $hash(key)$ 之间的位置偏移),如果当前位置的寻址次数小于新加入元素的寻址次数,就把新加入的元素放在当前位置,让原来的那个位置的键值对再继续寻找新的位置,即尽量平均寻址次数。
cuckoo hashing
使用多个哈希表,哈希函数相同,但是 hash function seed 不同。
cuckoo hash 真正实现起来比较复杂。
dynamic hash scheme
一种方案是,将发生 hash collision 的键值对组织成链表。
extendible hashing
extendible hash 的主要组成部分有两个:
- directories: directories 存储着 bucket 的地址,每个 directory entry 都有一个 id 与之对应,随着 directory 的扩张,这个 id 会随之变化;
- buckets:bucket 用于对实际数据进行哈希处理,$hash(key)$ 的计算结果相同的 key 会位于同一个 bucket。
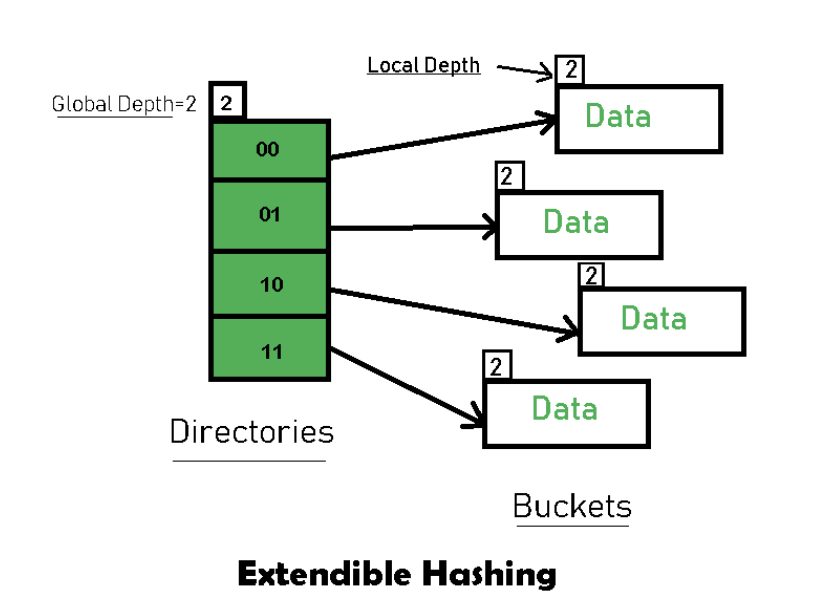
extendible hash 中还有几个比较重要的概念:
- global depth:$global\ depth\ =\ number\ of\ bits\ in\ directory\ id$,上图中的 global depth 就是 $2$,directories 的数量等于 $2^{global\ depth}$;
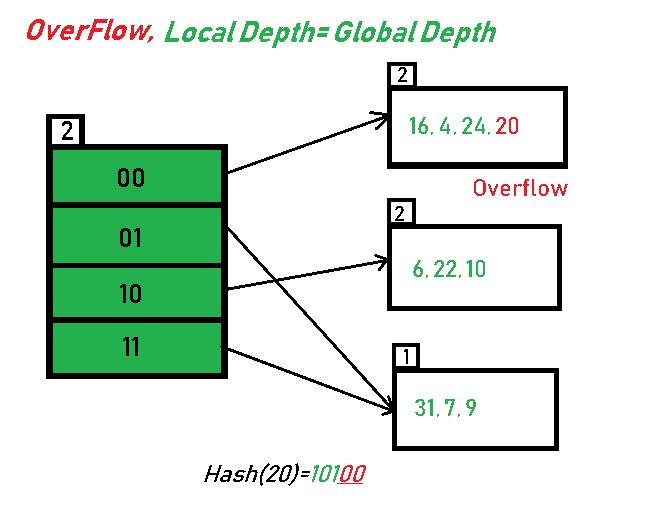
- local depth: 它决定了当 bucket 发生溢出(overflow)时,我们应该如何处理。local depth 总是不大于 global depth;
- directory expansion: 当 bucket 发生溢出时并且 local depth 等于 global depth 时,会发生 directory expansion。
extendible hash 的基础工作机制如下:

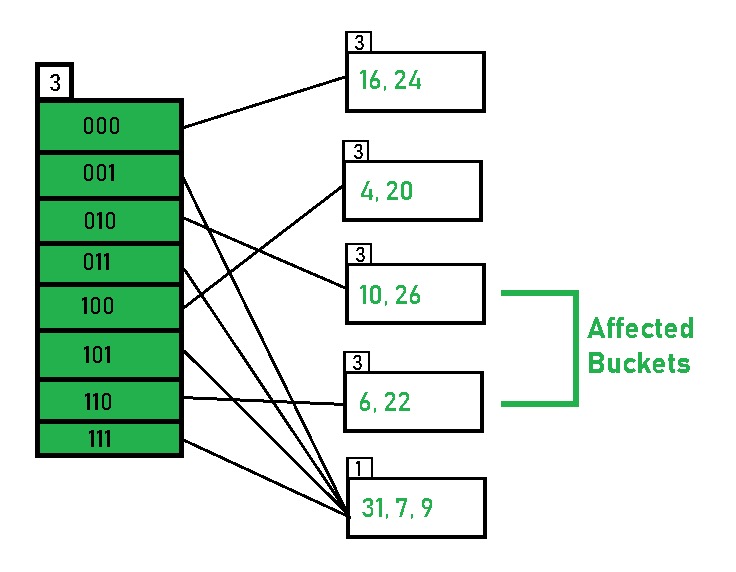
计算哈希值时,一般都是利用 key 的二进制数据来进行计算的,与 key 本身的数据类型关系不大。例如整数 $49$ 对应二进制数 $1100001$,这里我们假设 global depth 为 $3$,那么哈希函数的返回值就是 $001$,即低三位,然后将键值对插入到 id 为 $001$ 的 directory 对应的 bucket 中去。
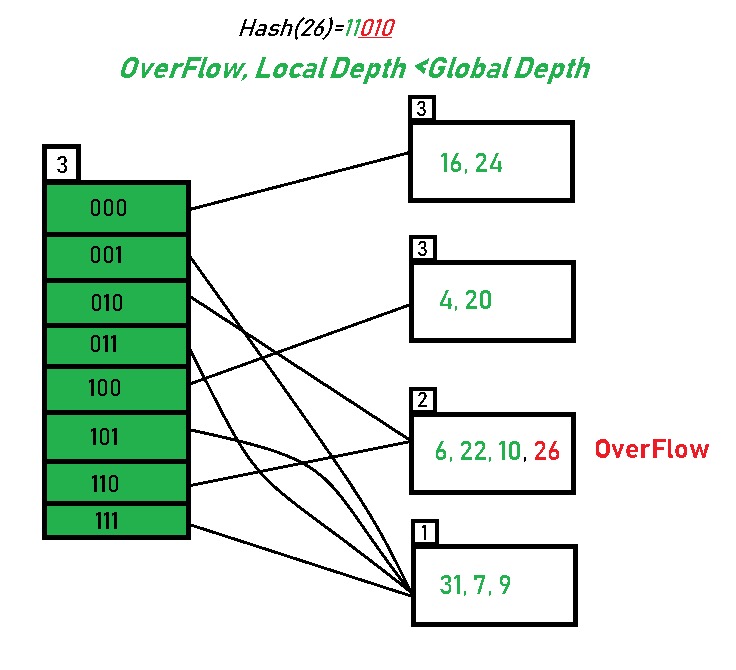
local depth 小于 global depth 的 bucket 会同时被多个 directory 指向。
如果发生了 bucket 的溢出,就会递增该 bucket 的 local depth,然后分裂这个 bucket 为两个,分裂后的 local depth 继承原来的 local depth,如果这个 bucket 的 local depth 等于 global depth,那么就递增 global depth,direcoties 的那些 id 也会相应增加一位,directories 的数量会翻倍。
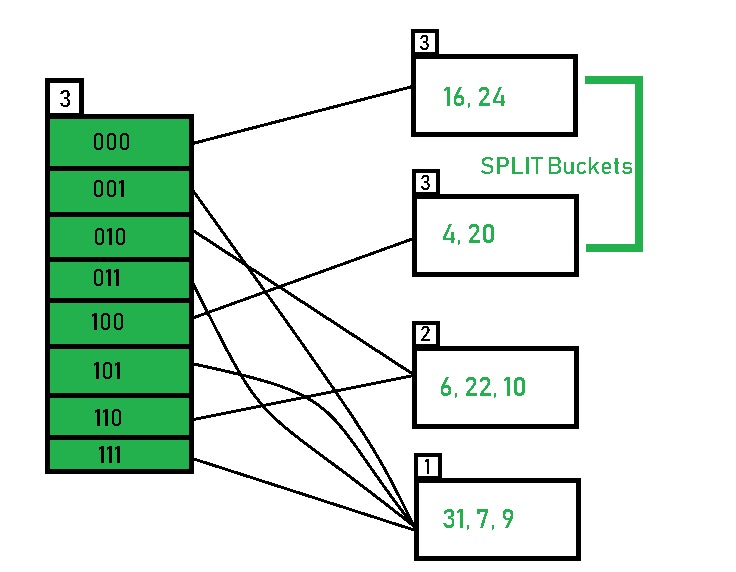
如果分裂后的 local depth 小于原来的 local depth,那么就不会再发生变化。
linear hashing
linear hashing 的思想在于,维护一个指向某个 bucket 的指针,这个指针指向的 bucket 是我们要进行分割的 bucket,即当某个 bucket 出现 overflow 时,我们会立即分割的 bucket 一定是指针指向的 bucket,而不一定是这个出现 overflow 的 bucket,对于出现 overflow 的 bucket,我们用扩展一个新的 bucket 来存放,相同 key 之间的 bucket 以链表形式组织。
linear hashing 有一系列的哈希函数 $h_n$,分裂 bucket 时,会使用当前哈希函数 $h_k$ 的下一个哈希函数 $h_{k + 1}$,对该 bucket 的 key,执行 $h_{k+1}(key)$,从而使这个 bucket 分裂到不同的 bucket 中去。分裂完 bucket 之后,我们将分割点递增。
当执行 $h_k(key)$ 得到的索引小于分割点索引,说明这个索引的 bucket 已经被分割过了,因此我们需要用 $h_{k+1}(key)$ 重新计算一次 bucket 的索引。
总结
事实上,考虑到编码复杂性等原因,当前主流数据库采取的 hash scheme 似乎还是 linera probe hashing。