集合
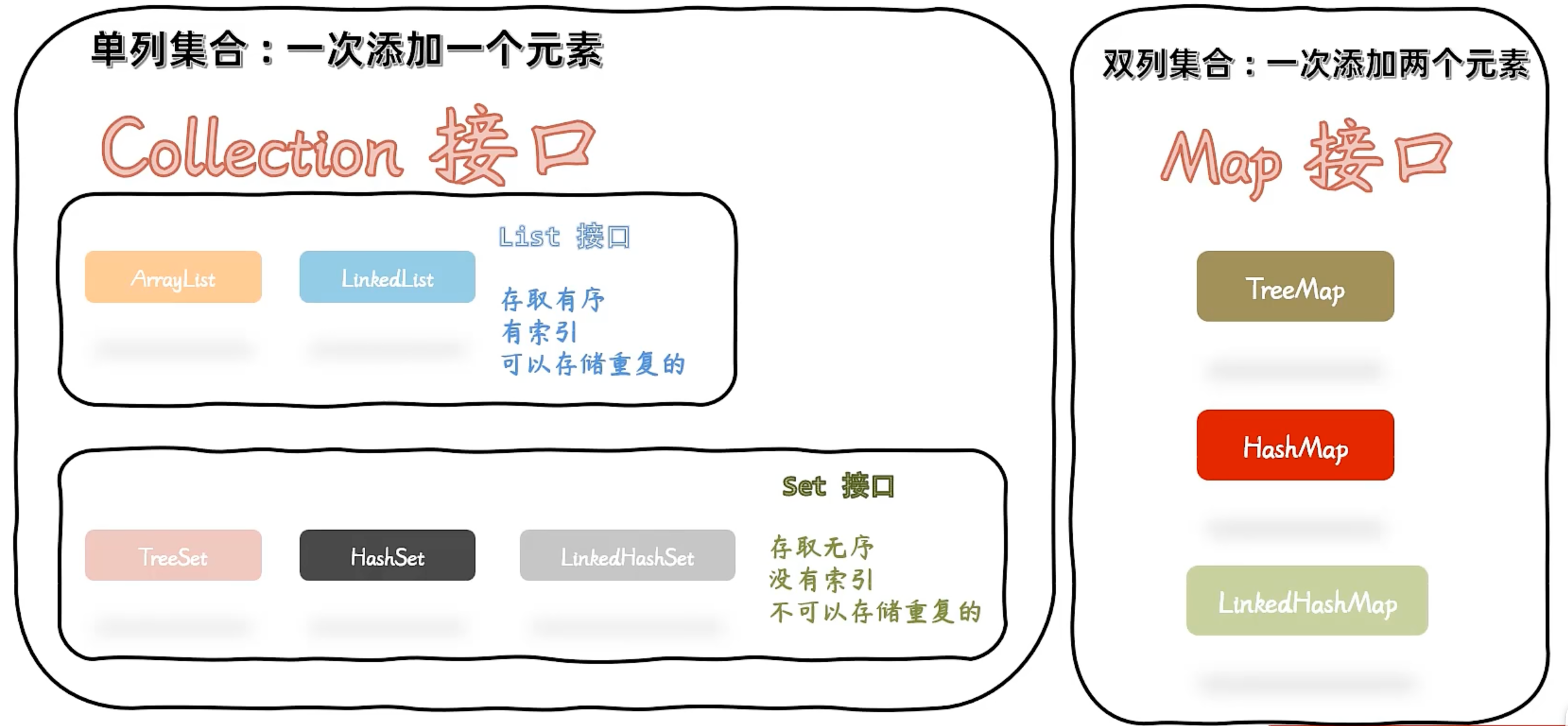
单列集合:Collection接口
单列集合:一次添加一个元素;

如果集合中添加的是类,要重写equals方法,否则比较的是地址,无法正常删除内容相同的元素。
单列集合通用遍历方式
1. 迭代器遍历

2. 增强for循环遍历

- 增强for循环底层逻辑还是迭代器,字节码文件反编译为java会发现还是迭代器遍历。
3. forEach方法
- 底层仍然是迭代器遍历
- forEach需要实现一个函数式接口,因此使用匿名函数类/lambda表达式都可
forEach方法举例
Collection<String> c = new ArrayList<>();
c.add("abc");
c.add("def");
c.add("abc");
// 匿名函数类
c.forEach(new Consumer<String>() {
@Override
public void accept(String s) {
System.out.println(s);
}
});
// lambda表达式
c.forEach(s -> System.out.println(s));
List接口
- 存取有序,有索引,可以存储重复数据
List独有API

并发修改异常

List集合的遍历方式

其中ListIterator迭代器中独有的逆序遍历Previous方法前必须通过正序遍历让cursor指到集合最后才可以正常逆序遍历成功
逆序遍历Previous方法
List<String> c = new ArrayList<>();
c.add("abc");
c.add("def");
c.add("xyz");
ListIterator<String> it = c.listIterator();
while(it.hasNext()) {
System.out.println(it.next());
}
System.out.println("------------------------");
while(it.hasPrevious()) {
System.out.println(it.previous());
}
ArrayList【List中用得最多】
底层数据结构是数组
ArrayList详解
LinkedList
底层数据结构是双链表
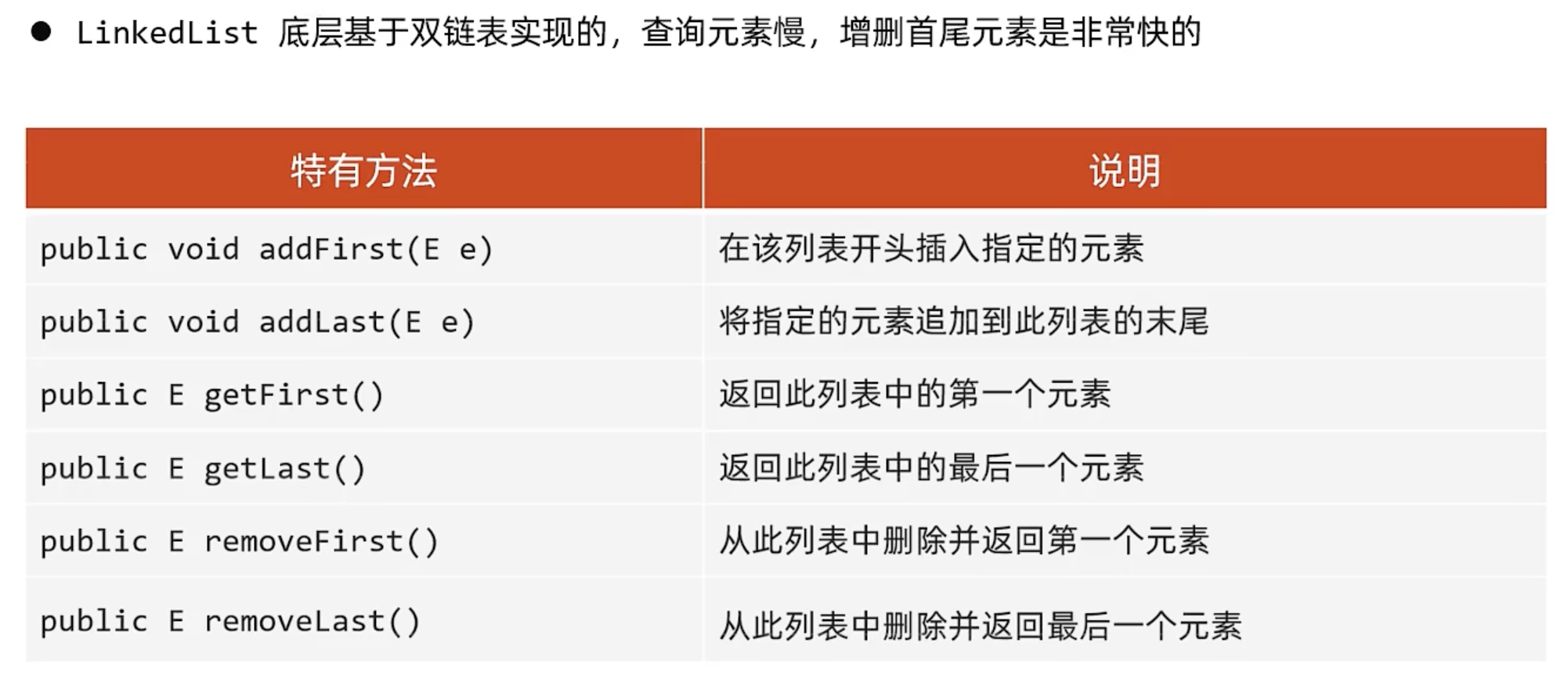
注意:LinkedList的get(index)方法复杂度是O(n)
因为LinkedList是List体系中的集合,继承了List接口,因此也有get(index)方法可以根据索引获取元素。但是底层实现逻辑仍然是基于双向链表,判断索引靠链表头还是链表尾,然后再从头/尾进行遍历查询,因此复杂度还是O(n)
Set接口
存取无序,无索引,不可以存储重复数据
TreeSet
底层数据结构是红黑树,可以对集合中的元素进行排序操作
特点:排序,去重
自然排序
- 类实现Comparable接口
- 重写compareTo方法
- 根据方法返回值组织排序规则
compareTo方法返回值:
0: 元素相同,不存
1: 大的右边走
-1: 小的左边走
当调用add方法,向TreeSet添加元素时,内部会自动调用compareTo方法,根据这个方法的返回值决定节点怎么走
public class Xxx implements Comparable<Xxx>{
@Override
public int compareTo(Student o) {
return this.xxx - o.xxx; // 按xxx正序排列
return o.xxx - this.xxx; // 按xxx降序排列
}
}
[自然排序]多属性排序Student类
public class Student implements Comparable<Student>{
@Override
public int compareTo(Student o) {
// 以年龄做主要排序条件,姓名做次要排序条件
if(this.age != o.age) return this.age - o.age;
return this.name.compareTo(o.name);
}
private String name;
private int age;
}
比较器排序
- 在TreeSet构造方法中传入Comparable接口的实现类对象
- 重写compareTo方法
- 根据方法返回值组织排序规则
比较器排序优先级高于自然排序
如果需要修改Java已经写好的类的自然排序规则(String,Integer等),就用比较器排序覆盖
[比较器排序]多属性排序Student类
// 匿名内部类实现
TreeSet<Student> set = new TreeSet<>(new Comparator<Student>() {
@Override
public int compare(Student o1, Student o2) {
if(o1.getAge() != o2.getAge()) return o2.getAge() - o1.getAge();
return o2.getName().compareTo(o1.getName());
}
});
// lambda表达式实现
TreeSet<Student> set = new TreeSet<>((o1, o2) -> {
if(o1.getAge() != o2.getAge()) return o2.getAge() - o1.getAge();
return o2.getName().compareTo(o1.getName());
});
HashSet【Set中用得最多】
底层数据结构:哈希表,且依赖于HashMap,[哈希表存储原理及源码分析]
特点:去重——可以保证元素的唯一性
去重原理:需要重写自定义类的equals方法和hashCode方法

- 如何避免哈希冲突?
重写hashCode方法时把类的成员属性都考虑到,以尽量避免哈希冲突
LinkedHashSet
底层数据结构:哈希表,另外每个元素又额外多了一个双链表的机制记录存储的顺序
特点:有序,去重,无索引
单列集合使用场景

单列集合工具类:Collections


双列集合:Map接口

- 双列集合底层的数据结构,都是针对键有效,跟值没有关系
Map常见API

Map集合遍历方式
1. 键找值

2. 通过键值对对象获取键和值

- 通过forEach方法遍历

TreeMap
底层数据结构:红黑树
特点:键排序(实现Comparable接口,重写compareTo方法)
HashMap
底层数据结构:哈希表
特点:键唯一(重写hashCode和equals方法)

LinkedHashMap
底层数据结构:哈希表+双向链表
特点:键唯一,且可以保证存取顺序
- LinkedHashSet LinkedHashMap Collection LinkedList ArrayListlinkedhashset linkedhashmap collection linkedlist linkedlist arraylist linkedlist arraylist java linkedlist arraylist vector java linkedlist arraylist框架vector linkedlist arraylist vector list 相同点linkedlist arraylist vector linkedlist arraylist vector collection linkedlist源码 linkedlist arraylist源码