作业①
要求
- 熟练掌握 Selenium 查找HTML元素、爬取Ajax网页数据、等待HTML元素等内容。
- 使用Selenium框架+ MySQL数据库存储技术路线爬取“沪深A股”、“上证A股”、“深证A股”3个板块的股票数据信息。
候选网站
输出信息:
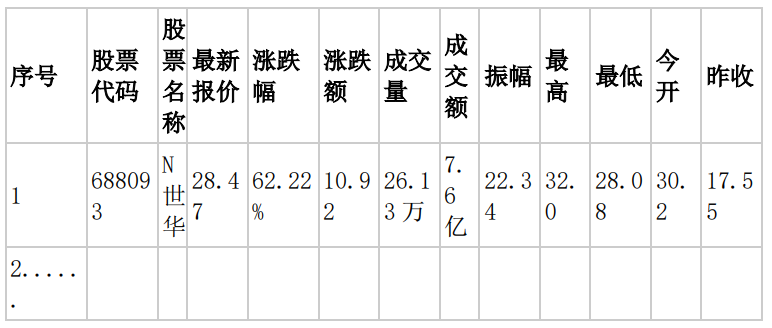
- MYSQL 数据库存储和输出格式如下,表头应是英文命名例如:序号,id,股票代码:bStockNo……,由同学们自行定义设计表头:
思路
- 之前处理这个网站主要是通过json请求的截获,而Selenium则可以直接爬取网站,不需要翻找页面数据流向找json文件的链接。
代码
StockSelenium.py
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.chrome.service import Service
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
from bs4 import BeautifulSoup
import time
import pymysql
def mysql_init():
con = pymysql.connect(host="localhost", port=3306, user="root",passwd = "", charset = "utf8")
cursor = con.cursor(pymysql.cursors.DictCursor)
cursor.execute("use zhangh")
cursor.execute('''create table if not exists stock
(id int AUTO_INCREMENT PRIMARY KEY,
股票代码 varchar(20),
名称 varchar(20),
最新价 varchar(20),
涨跌幅 varchar(20),
涨跌额 varchar(20),
成交量 varchar(20),
成交额 varchar(20),
振幅 varchar(20),
最高 varchar(20),
最低 varchar(20),
今开 varchar(20),
昨收 varchar(20),
量比 varchar(20),
换手率 varchar(20),
市盈率 varchar(20),
市净率 varchar(20))''')
cursor.execute("delete from stock")
return cursor, con
def driver_init():
chrome_path = "Q:\\Program Files\\scoop\\apps\\vivaldi\\current\\Application\\vivaldi.exe"
driver_path = "Q:\\Program Files\\scoop\\apps\\chromedriver\\119.0.6045.105\\chromedriver.exe"
# "Q:\Program Files\scoop\apps\chromedriver\118.0.5993.70\chromedriver.exe"
# options = Options()
# options.binary_location = chrome_path
# s = Service(chrome_path)
driver = webdriver.Chrome(executable_path=driver_path)
return driver
def crawl(driver, cursor):
# 上证A股
button_sh = driver.find_element(By.CSS_SELECTOR, 'li[id="nav_sh_a_board"] > a')
button_sh.click()
time.sleep(3)
button_next = driver.find_element(By.CSS_SELECTOR, 'a[class="next paginate_button"]')
while button_next:
data = driver.page_source
saveToDB(data, cursor)
print(button_next)
button_next.click()
time.sleep(3)
button_next = driver.find_element(By.CSS_SELECTOR, 'a[class="next paginate_button"]')
def saveToDB(data, cursor):
bs = BeautifulSoup(data, 'lxml')
table = bs.select_one('table[id="table_wrapper-table"]')
# 表的标题
table_head = table.select("thead > tr > th")
thead = [x.text for x in table_head]
print('\t'.join(thead))
table_body = table.select("tbody > tr")
for tr in table_body:
# print("")
imformations = [x.text for x in tr]
imformations.pop(3)
imformations.pop(-1)
print(imformations)
cursor.execute('''insert into stock (股票代码,名称,最新价,涨跌幅,涨跌额,成交量,成交额,振幅,最高,最低,今开,昨收,量比,换手率,市盈率,市净率)
values(%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)''', imformations[1:])
# time.sleep(3)
def spider(driver, cursor):
main_url = "http://quote.eastmoney.com/center/gridlist.html#hs_a_board"
driver.get(main_url)
time.sleep(3)
crawl(driver, cursor)
def end(driver, connect):
driver.close()
connect.commit()
connect.close()
# '''table[id="table_wrapper-table"] > tbody > tr'''
if __name__ == "__main__":
try:
cursor, con = mysql_init()
driver = driver_init()
spider(driver, cursor)
except Exception as e :
print(e)
finally:
end(driver, con)
# driver.
运行截图

心得体会
- 翻页功能的实现主要是查找“next”按钮,并模拟点击进行刷新数据
- 之前的爬取json数据使用的是sqlite,这次采用了mysql,将之前乱糟糟的代码进行了重构,再加上思路本来就清晰,这个作业完整十分顺利
作业二
要求
- 熟练掌握 Selenium 查找 HTML 元素、实现用户模拟登录、爬取 Ajax 网页数据、
- 等待 HTML 元素等内容。
候选网站
输出信息:
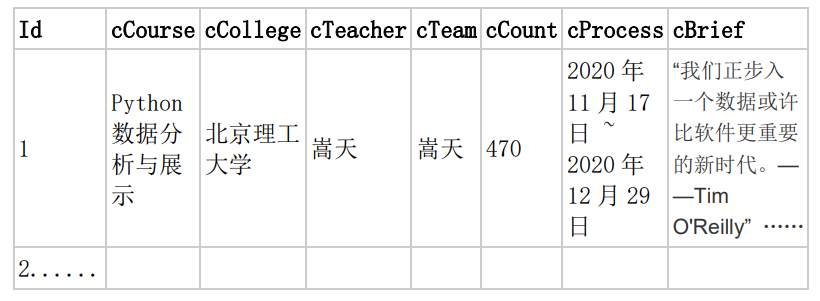
- MYSQL 数据库存储和输出格式
代码
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
import time
import random
import pymysql
# 声明一个谷歌驱动器,并设置不加载图片,间接加快访问速度
options = Options()
options.add_experimental_option('prefs', {'profile.managed_default_content_settings.images': 2})
browser = webdriver.Chrome(chrome_options=options)
url = "https://www.icourse163.org/search.htm?search=%E5%A4%A7%E6%95%B0%E6%8D%AE#/"
# 声明一个list,存储dict
data_list = []
def start_spider():
# 请求url
browser.get(url)
# 显示等待商品信息加载完成
WebDriverWait(browser, 1000).until(
EC.presence_of_all_elements_located(
(By.ID, "j-courseCardListBox")
)
)
# 将滚动条拉到最下面的位置,因为往下拉才能将这一页的商品信息全部加载出来
browser.execute_script('document.documentElement.scrollTop=10000')
# 随机延迟,等下元素全部刷新
time.sleep(random.randint(3, 6))
# browser.execute_script('document.documentElement.scrollTop=0')
# <li class="ux-pager_btn ux-pager_btn__next">
# <a class="th-bk-main-gh">下一页</a>
# <[表情]>
for link in browser.find_elements(By.XPATH,'//div[@class="u-clist f-bgw f-cb f-pr j-href ga-click"]'):
#课程号
# course_id = link.find_element(By.XPATH,'.//div[@class="p-name"]//em').text
#课程名称
course_name = link.find_element(By.XPATH,'.//span[@class=" u-course-name f-thide"]').text
print("course name ",course_name)
school_name = link.find_element(By.XPATH,'.//a[@class="t21 f-fc9"]').text
print("school ", school_name)
#主讲教师
m_teacher = link.find_element(By.XPATH,'.//a[@class="f-fc9"]').text
print("teacher:", m_teacher)
#团队成员
try:
team_member = link.find_element(By.XPATH,'.//span[@class="f-fc9"]').text
except Exception as err:
team_member = 'only'
#print("团队:",team_member)
#参加人数
join = link.find_element(By.XPATH,'.//span[@class="hot"]').text
join.replace('参加','')
print("参加人数",join)
#课程进度
process = link.find_element(By.XPATH,'.//span[@class="txt"]').text
print('进度 ',process)
#课程简介
introduction = link.find_element(By.XPATH,'.//span[@class="p5 brief f-ib f-f0 f-cb"]').text
print(introduction)
conn = pymysql.connect(host="127.0.0.1", port=3306, user="root", passwd="", db="zhangh", charset="utf8")
# 获取游标
cursor = conn.cursor()
# 插入数据,注意看有变量的时候格式
try:
cursor.execute("create table if not exists mc(id int AUTO_INCREMENT primary key,course varchar(20),college varchar(20),teacher varchar(20),team varchar(20),count varchar(20),process varchar(20),brief varchar(100))")
cursor.execute(
"INSERT INTO mc (`course`,`college`,`teacher`,`team`,`count`,`process`,`brief`) VALUES (%s,%s,%s,%s,%s,%s,%s)",
(course_name,school_name,m_teacher,m_teacher+team_member,join,process,introduction))
# 提交
except Exception as err:
print("error is ")
print(err)
# 关闭连接
conn.commit()
conn.close()
def main():
start_spider()
if __name__ == '__main__':
main()
# 退出浏览器
browser.quit()
运行截图

心得体会
- 这里有点取巧了,原本老师的本意是登录实现爬取,然而我这里直接绕过了登录,直接使用url进行访问(本来登录存储cookie就是个大问题)
作业③
要求
- 掌握大数据相关服务,熟悉 Xshell 的使用
- 完成文档 华为云_大数据实时分析处理实验手册-Flume 日志采集实验(部分)v2.docx 中的任务,即为下面 5 个任务,具体操作见文档。
环境搭建
-
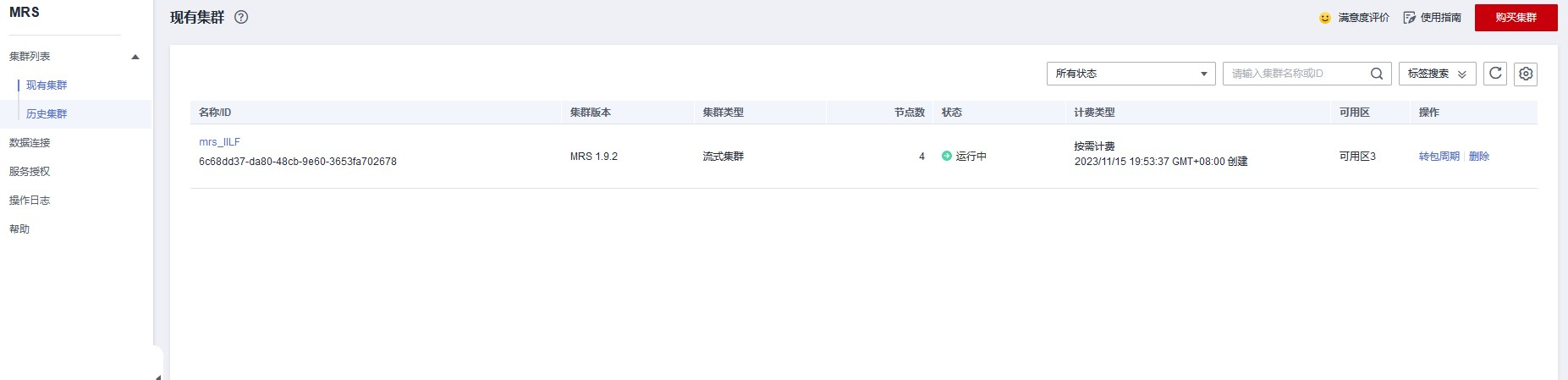
任务一:开通 MapReduce 服务
实时分析开发实战
-
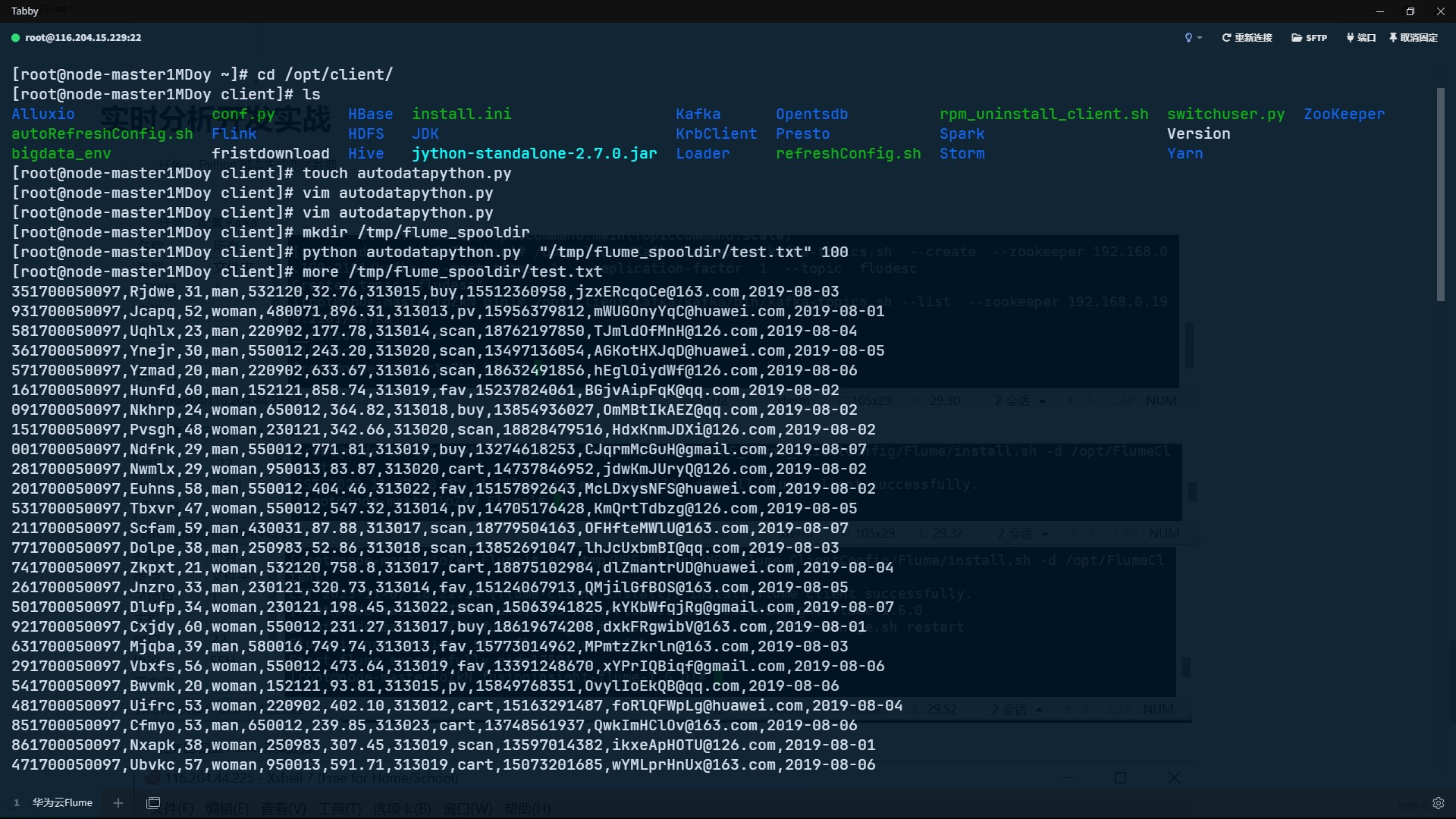
任务一:Python 脚本生成测试数据
-
任务二:配置 Kafka

- 任务三: 安装 Flume 客户端
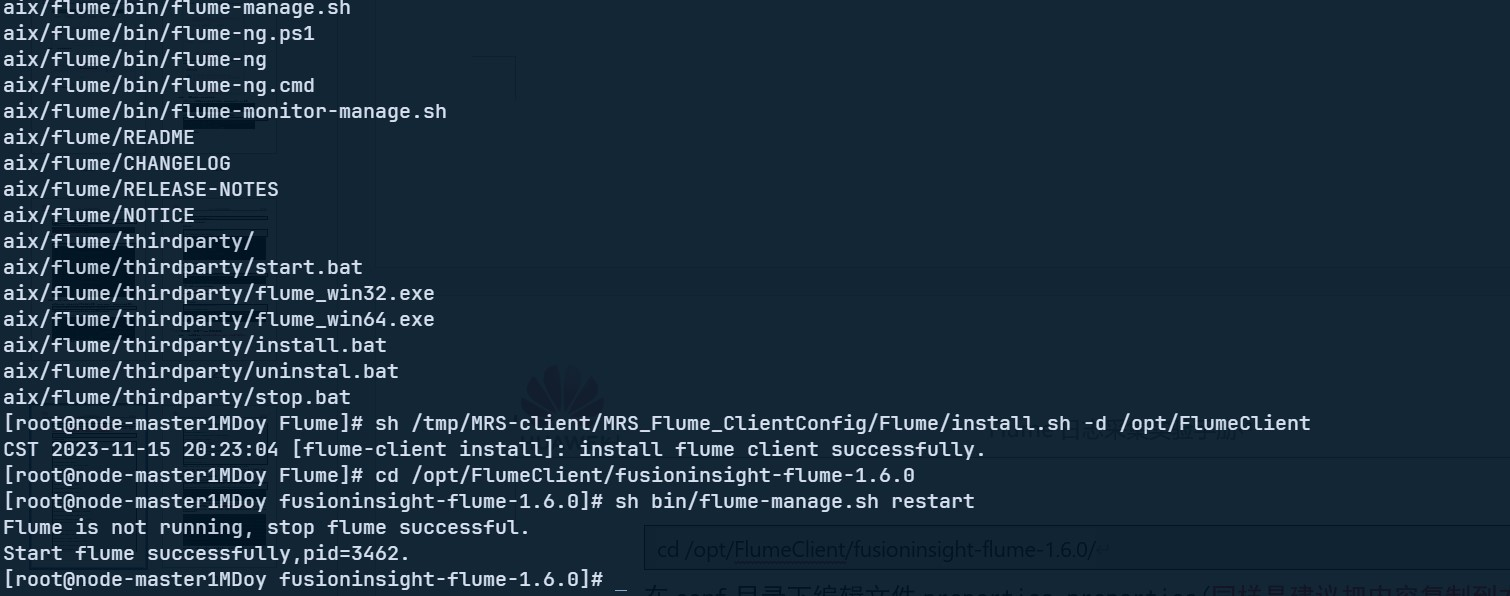
- 任务四:配置 Flume 采集数据


心得体会
- 学会了运用华为公有云的MRS服务,了解了Flume的作用和环境搭建的过程。
- 老师的教程很详细,不仅详细地给出了每一步的具体命令,还细心地解释了每一步的疑难点,真的很难做错
- 这里没有使用Xshell,而是使用了github上开源的项目Tabby Terminal(主要是好看)