数据采集与融合技术实践第四次作业
-
作业1:
-
要求:熟练掌握 Selenium 查找HTML元素、爬取Ajax网页数据、等待HTML元素等内容。使用Selenium框架+ MySQL数据库存储技术路线爬取“沪深A股”、“上证A股”、“深证A股”3个板块的股票数据信息。
-
Gitee文件夹链接:题目一
-
代码如下所示
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
import mysql.connector
# 初始化数据库连接
mydb = mysql.connector.connect(
host="localhost",
user="root",
password="yx20021207",
database="homework4"
)
mycursor = mydb.cursor()
# 创建数据表
mycursor.execute("""
CREATE TABLE IF NOT EXISTS hushenjing (
id INT AUTO_INCREMENT PRIMARY KEY,
bStockNo VARCHAR(255),
name VARCHAR(255),
price FLOAT,
percentage_change FLOAT,
absolute_change FLOAT,
volume VARCHAR(255),
turnover VARCHAR(255),
amplitude FLOAT,
high FLOAT,
low FLOAT,
opening FLOAT,
closing FLOAT
)
""")
mycursor.execute("""
CREATE TABLE IF NOT EXISTS shangzheng (
id INT AUTO_INCREMENT PRIMARY KEY,
bStockNo VARCHAR(255),
name VARCHAR(255),
price FLOAT,
percentage_change FLOAT,
absolute_change FLOAT,
volume VARCHAR(255),
turnover VARCHAR(255),
amplitude FLOAT,
high FLOAT,
low FLOAT,
opening FLOAT,
closing FLOAT
)
""")
mycursor.execute("""
CREATE TABLE IF NOT EXISTS shenzheng (
id INT AUTO_INCREMENT PRIMARY KEY,
bStockNo VARCHAR(255),
name VARCHAR(255),
price FLOAT,
percentage_change FLOAT,
absolute_change FLOAT,
volume VARCHAR(255),
turnover VARCHAR(255),
amplitude FLOAT,
high FLOAT,
low FLOAT,
opening FLOAT,
closing FLOAT
)
""")
# 使用selenium
option = webdriver.ChromeOptions() # 创建一个配置对象
option.add_argument("--headless") # 开启无界面模式
option.add_argument("--disable-gpu") # 禁用gpu
browser = webdriver.Chrome(options=option)
# 选择想要爬取的板块
# 沪深京http://quote.eastmoney.com/center/gridlist.html#hs_a_board
# 上证http://quote.eastmoney.com/center/gridlist.html#sh_a_board
# 深证http://quote.eastmoney.com/center/gridlist.html#sz_a_board
url = "http://quote.eastmoney.com/center/gridlist.html#hs_a_board"
browser.get(url)
# 等待页面加载完成
time.sleep(2)
rows1 = browser.find_elements(By.CSS_SELECTOR, "table tbody tr")
for row in rows1:
columns = row.find_elements(By.TAG_NAME, "td")
bStockNo = columns[1].text
name = columns[2].text
price = float(columns[4].text)
percentage_change = float(columns[5].text.rstrip('%'))
absolute_change = float(columns[6].text)
volume = columns[7].text
turnover = columns[8].text
amplitude = float(columns[9].text.rstrip('%'))
high = float(columns[10].text)
low = float(columns[11].text)
opening = float(columns[12].text)
closing = float(columns[13].text)
sql = """
INSERT INTO hushenjing (bStockNo, name, price, percentage_change, absolute_change, volume, turnover, amplitude, high, low, opening, closing)
VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)
"""
val = (bStockNo, name, price, percentage_change, absolute_change, volume, turnover, amplitude, high, low, opening, closing)
mycursor.execute(sql, val)
mydb.commit()
next_page_button1 = browser.find_element(By.LINK_TEXT, "上证A股")
next_page_button1.click()
time.sleep(2)
rows2 = browser.find_elements(By.CSS_SELECTOR, "table tbody tr")
for row in rows2:
columns = row.find_elements(By.TAG_NAME, "td")
bStockNo = columns[1].text
name = columns[2].text
price = float(columns[4].text)
percentage_change = float(columns[5].text.rstrip('%'))
absolute_change = float(columns[6].text)
volume = columns[7].text
turnover = columns[8].text
amplitude = float(columns[9].text.rstrip('%'))
high = float(columns[10].text)
low = float(columns[11].text)
opening = float(columns[12].text)
closing = float(columns[13].text)
sql = """
INSERT INTO shangzheng (bStockNo, name, price, percentage_change, absolute_change, volume, turnover, amplitude, high, low, opening, closing)
VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)
"""
val = (
bStockNo, name, price, percentage_change, absolute_change, volume, turnover, amplitude, high, low, opening, closing)
mycursor.execute(sql, val)
mydb.commit()
next_page_button1 = browser.find_element(By.LINK_TEXT, "深证A股")
next_page_button1.click()
time.sleep(2)
rows3 = browser.find_elements(By.CSS_SELECTOR, "table tbody tr")
for row in rows3:
columns = row.find_elements(By.TAG_NAME, "td")
bStockNo = columns[1].text
name = columns[2].text
price = float(columns[4].text)
percentage_change = float(columns[5].text.rstrip('%'))
absolute_change = float(columns[6].text)
volume = columns[7].text
turnover = columns[8].text
amplitude = float(columns[9].text.rstrip('%'))
high = float(columns[10].text)
low = float(columns[11].text)
opening = float(columns[12].text)
closing = float(columns[13].text)
sql = """
INSERT INTO shenzheng (bStockNo, name, price, percentage_change, absolute_change, volume, turnover, amplitude, high, low, opening, closing)
VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)
"""
val = (
bStockNo, name, price, percentage_change, absolute_change, volume, turnover, amplitude, high, low, opening, closing)
mycursor.execute(sql, val)
mydb.commit()
browser.quit()
- 用Navicat可视化爬取到的数据
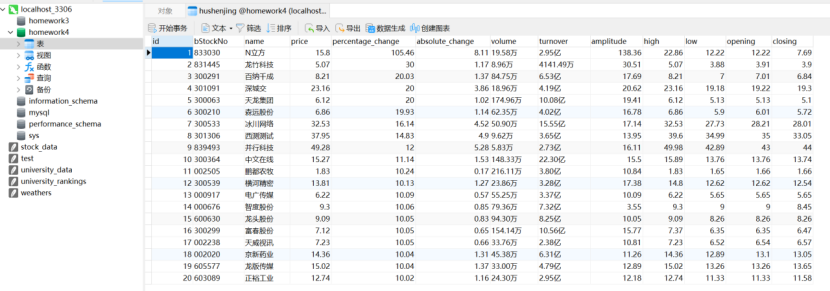
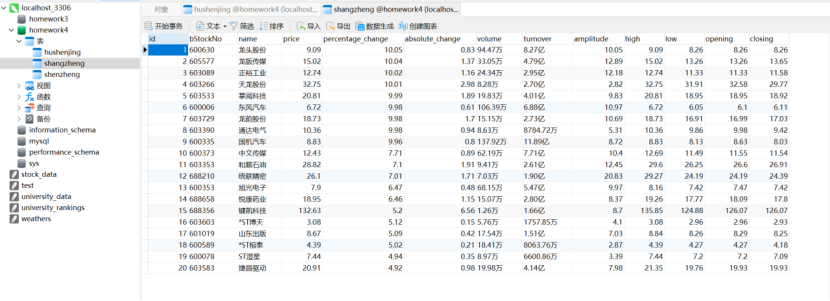
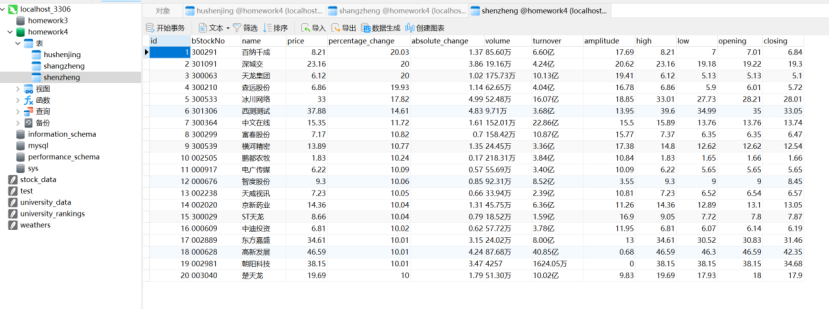
-
心得体会:
明白了如何使用selenium爬取数据并连接数据库,然后将数据存储到本地数据库中,对于如何使用click点击滑块翻页有了初步的理解,知道了隐藏爬取过程的办法。
-
作业二:
-
要求:熟练掌握 Selenium 查找HTML元素、实现用户模拟登录、爬取Ajax网页数据、等待HTML元素等内容。使用Selenium框架+MySQL爬取中国mooc网课程资源信息(课程号、课程名称、学校名称、主讲教师、团队成员、参加人数、课程进度、课程简介)
-
候选网站:中国mooc网
-
Gitee文件夹链接:题目二
-
代码如下
from selenium import webdriver
from selenium.webdriver.common.by import By
import mysql.connector
import time
import configparser
config = configparser.ConfigParser()
config.read('config.ini')
username = config['credentials']['username']
password = config['credentials']['password']
# 初始化Chrome浏览器和数据库连接
# option = webdriver.ChromeOptions() # 创建一个配置对象
# option.add_argument("--headless") # 开启无界面模式
# option.add_argument("--disable-gpu") # 禁用gpu
# driver = webdriver.Chrome(options=option)
driver = webdriver.Chrome() # 观察浏览器操作
# 访问中国mooc网站
driver.get("https://www.icourse163.org")
time.sleep(1)
mydb = mysql.connector.connect(
host="localhost",
user="root",
password="yx20021207",
database="homework4"
)
cursor = mydb.cursor()
cursor.execute('''CREATE TABLE IF NOT EXISTS MoocCourses (
id INT AUTO_INCREMENT PRIMARY KEY,
cCourse VARCHAR(255),
cCollege VARCHAR(255),
cTeacher VARCHAR(255),
cTeam VARCHAR(255),
cCount VARCHAR(255),
cProcess VARCHAR(255),
cBrief TEXT)''')
# currentHandle = driver.current_window_handle
driver.find_element(By.XPATH,"/html/body/div[4]/div[2]/div[1]/div/div/div[1]/div[3]/div[3]/div").click()
time.sleep(5)
# 切换到登录 iframe
login_iframe = driver.find_element(By.XPATH, "/html/body/div[13]/div[2]/div/div/div/div/div/div[1]/div/div[1]/div[2]/div[2]/div[1]/div/iframe")
driver.switch_to.frame(login_iframe)
input1 = driver.find_element(By.XPATH,"/html/body/div[2]/div[2]/div[2]/form/div/div[2]/div[2]/input")
# 通过xpath获取账号文本框的对象
input2 = driver.find_element(By.XPATH,"/html/body/div[2]/div[2]/div[2]/form/div/div[4]/div[2]/input[2]")
# 通过xpath获取密码文本框的对象
input1.send_keys(username)#输入账号
time.sleep(1)
input2.send_keys(password)#输入密码
time.sleep(1)
#向文本框传入账号密码
driver.find_element(By.XPATH,"/html/body/div[2]/div[2]/div[2]/form/div/div[6]/a").click()
# 取消免密登录
driver.find_element(By.XPATH,"/html/body/div[2]/div[2]/div[2]/form/div/div[7]/div/span").click()
#获取登录按钮的id并设置点击事件
time.sleep(10)
#设置响应时间
driver.switch_to.default_content()
# courses =driver.find_elements(By.CLASS_NAME,"_3hfsT")
# for course in courses:
# course.click()
# # 跳转到新的想要跳转的页面
# for handle in driver.window_handles:
# # 切换到新的页面
# driver.switch_to.window(handle)
#
# # 这时因为已经跳转到想要跳转的页面了,所以此时的标题就是新页面的标题了
# print(driver.title)
#
# driver.switch_to.window(currentHandle)
# time.sleep(5)
key = "python"
driver.find_element(By.XPATH,"/html/body/div[4]/div[1]/div/div/div/div/div[7]/div[1]/div/div/div[1]/div/div/div/div/div/div/input").send_keys(key)
time.sleep(1)
driver.find_element(By.XPATH,"/html/body/div[4]/div[1]/div/div/div/div/div[7]/div[1]/div/div/div[2]/span").click()
time.sleep(5)
for i in range(5):
courses = driver.find_elements(By.XPATH,"/html/body/div[4]/div[2]/div[2]/div[2]/div/div[6]/div[2]/div[1]/div/div/div")
for course in courses:
try:
cCourse = course.find_element(By.XPATH, './div[2]/div/div/div[1]/a/span').text
cCollege = course.find_element(By.XPATH, './div[2]/div/div/div[2]/a[1]').text
cTeacher = course.find_element(By.XPATH, './div[2]/div/div/div[2]/a[2]').text
cTeam = course.find_element(By.XPATH, './div[2]/div/div/div[2]/span/span').text
cBrief = course.find_element(By.XPATH, './div[2]/div/div/a/span').text
cCount = course.find_element(By.XPATH, './div[2]/div/div/div[3]/span[2]').text
cProcess = course.find_element(By.XPATH, './div[2]/div/div/div[3]/div/span[2]').text
print(cCourse,cCollege,cTeacher,cTeam,cCount,cProcess,cBrief)
# 存入数据库
cursor.execute(
"INSERT INTO MoocCourses (cCourse, cCollege, cTeacher, cTeam, cCount, cProcess, cBrief) VALUES (%s, %s, %s, %s, %s, %s, %s)",
(cCourse, cCollege, cTeacher, cTeam, cCount, cProcess, cBrief))
except:
continue
driver.find_element(By.XPATH,"/html/body/div[4]/div[2]/div[2]/div[2]/div/div[6]/div[2]/div[2]/ul/li[10]/a").click()
time.sleep(5)
mydb.commit()
cursor.close()
mydb.close()
driver.quit()
- 配置文件如下(这里没有提供真实账号和密码)
[credentials]
username = xxxxxx
password = xxxxxx
- Navicat可视化查看爬取到的数据
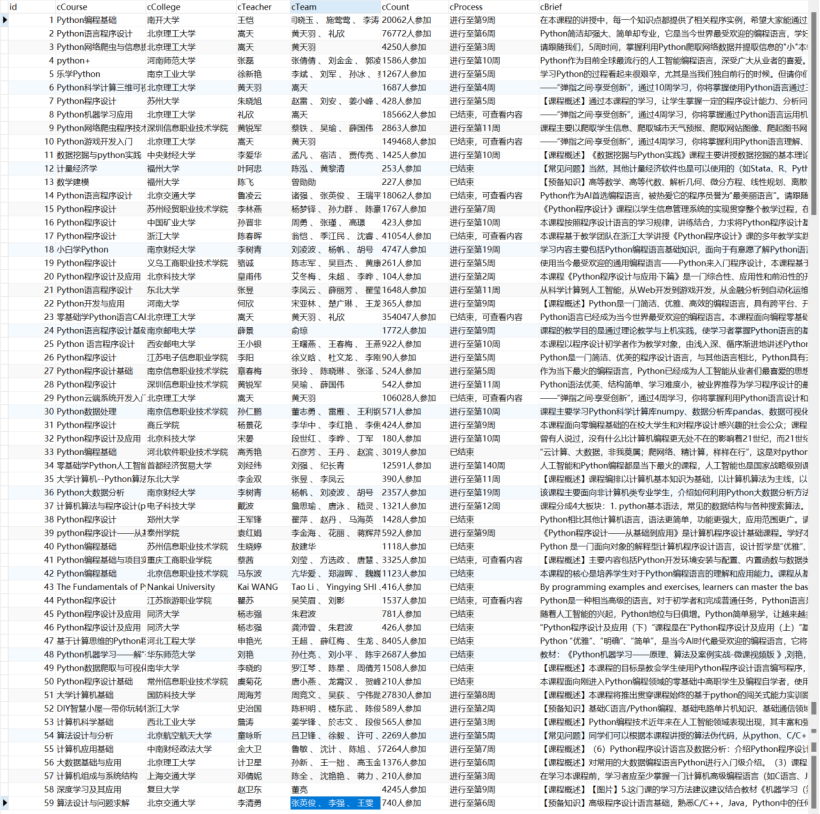
-
心得体会:
在登录过程中屡次遇到问题,无法查找到隐藏窗口的元素,通过了解后才明白应该用switch_to.frame来切换从而实现模拟登陆,登录后还需切换回来,同时学会了通过配置文件来隐藏代码中的真实账号和密码。后续尝试从首页中通过句柄一个个爬取课程信息,但还未熟练掌握。通过该次实践发现,取消隐式爬取,通过观察浏览器行为更容易发现代码的问题所在。
-
作业三:
-
要求:掌握大数据相关服务,熟悉Xshell的使用完成文档 华为云_大数据实时分析处理实验手册-Flume日志采集实验(部分)v2.docx 中的任务,即为下面5个任务,具体操作见文档。
-
环境搭建:
-
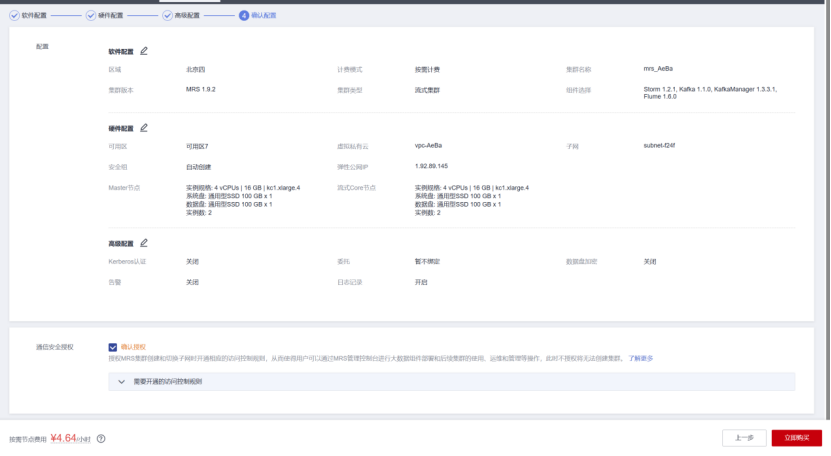
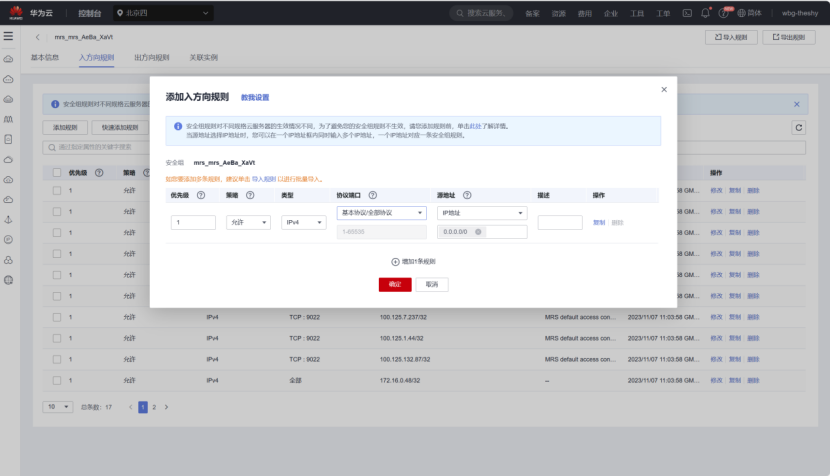
任务一:开通MapReduce服务
-
实时分析开发实战:
-
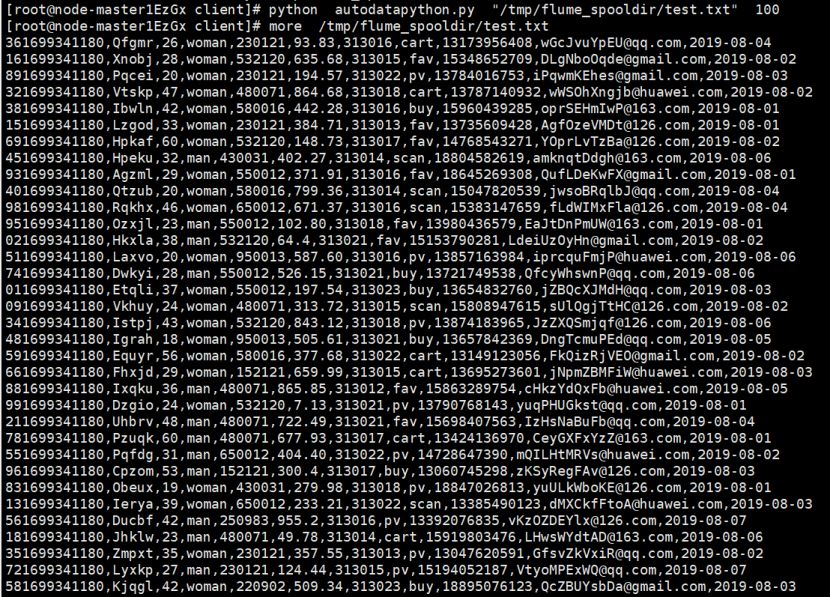
任务一:Python脚本生成测试数据
-
任务二:配置Kafka

-
任务三: 安装Flume客户端

-
任务四:配置Flume采集数据


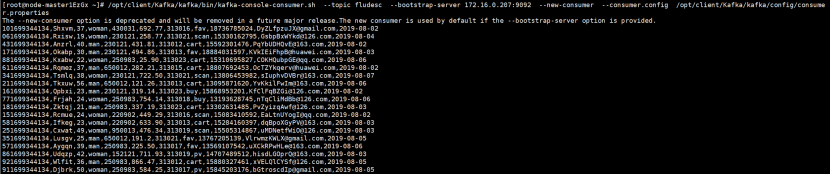
-
心得体会