前两个也许跟上了,后两个完全没跟上,以后再详细读读吧qwq
反正组会跟不上才是正常现象。
AugGPT: Leveraging ChatGPT for Text Data Augmentation
摘要、引言、相关工作
当下数据增强两个缺陷
- 真实性不足,有的跟原始 label 有偏移
- 生成的数据缺乏紧凑性
利用 ChatGPT 改进先前的数据增强方法
FSL(few shot learning):
- 下游上只有 1-2 个样本
RW
数据增强方法:
- character level
- OCR 这种自带的缺陷做数据增强,比如 O -> 0
- word level
- 随机替换、反转、删除
- 同义词替换
- contextual
- 利用预训练模型本身自有的知识做数据增强
- sequence
- 翻译过去再翻译回来
模型
AugGPT 的框架
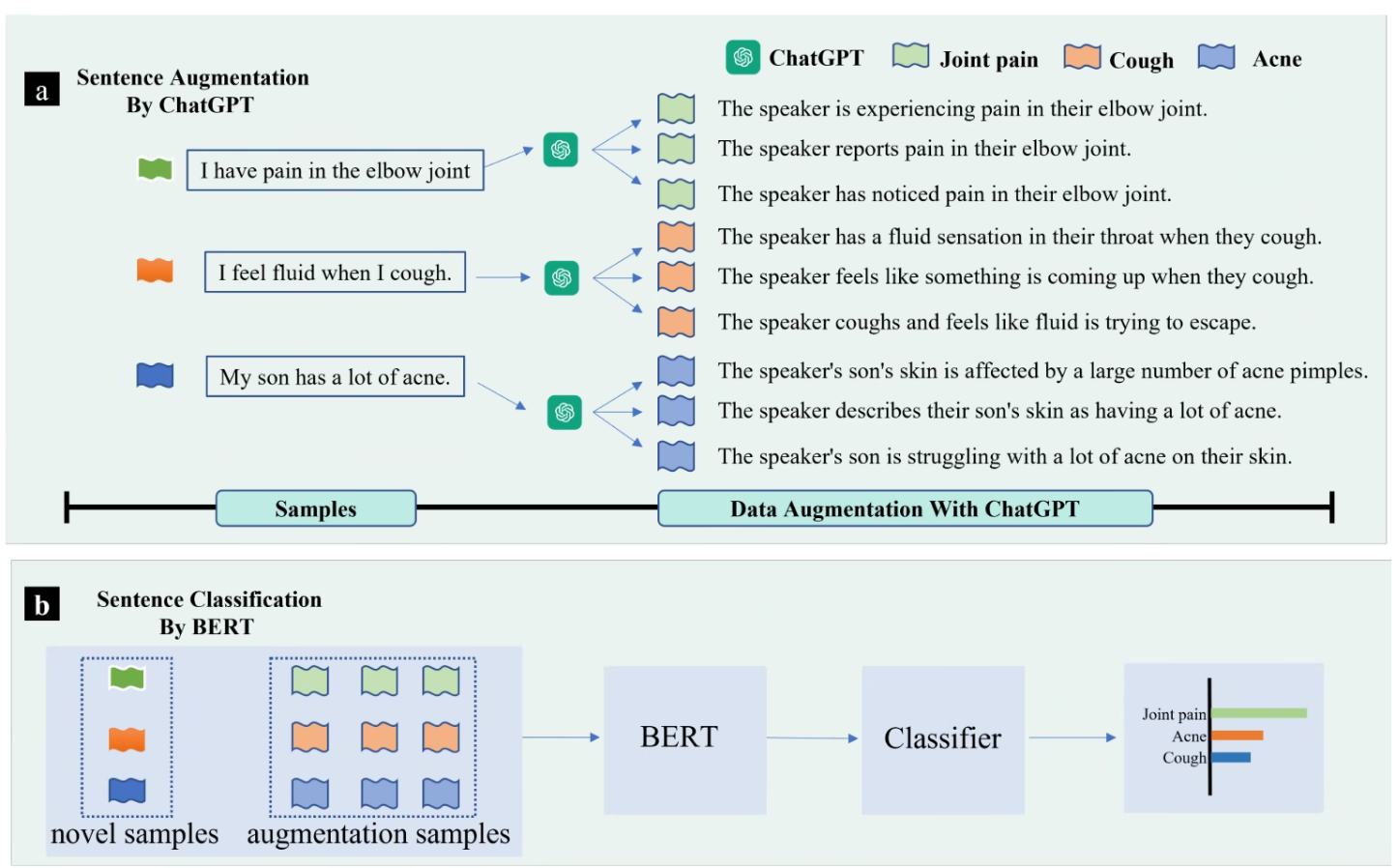
- 把原始的话输入 ChatGPT 中,然后让它改写。
- BERT 做 mask 的预测

Loss
做了对比损失
实验
数据集
- Amazon dataset:24 类,分类
- Symptoms Dataset:分类症状
- PubMed20k Dataset:分类
指标
- 余弦相似度
- 跟 BERT 类似,把 [CLS] 取出来,然后比较余弦相似度
- 信息熵相关的某个指标(Transrate)
结果
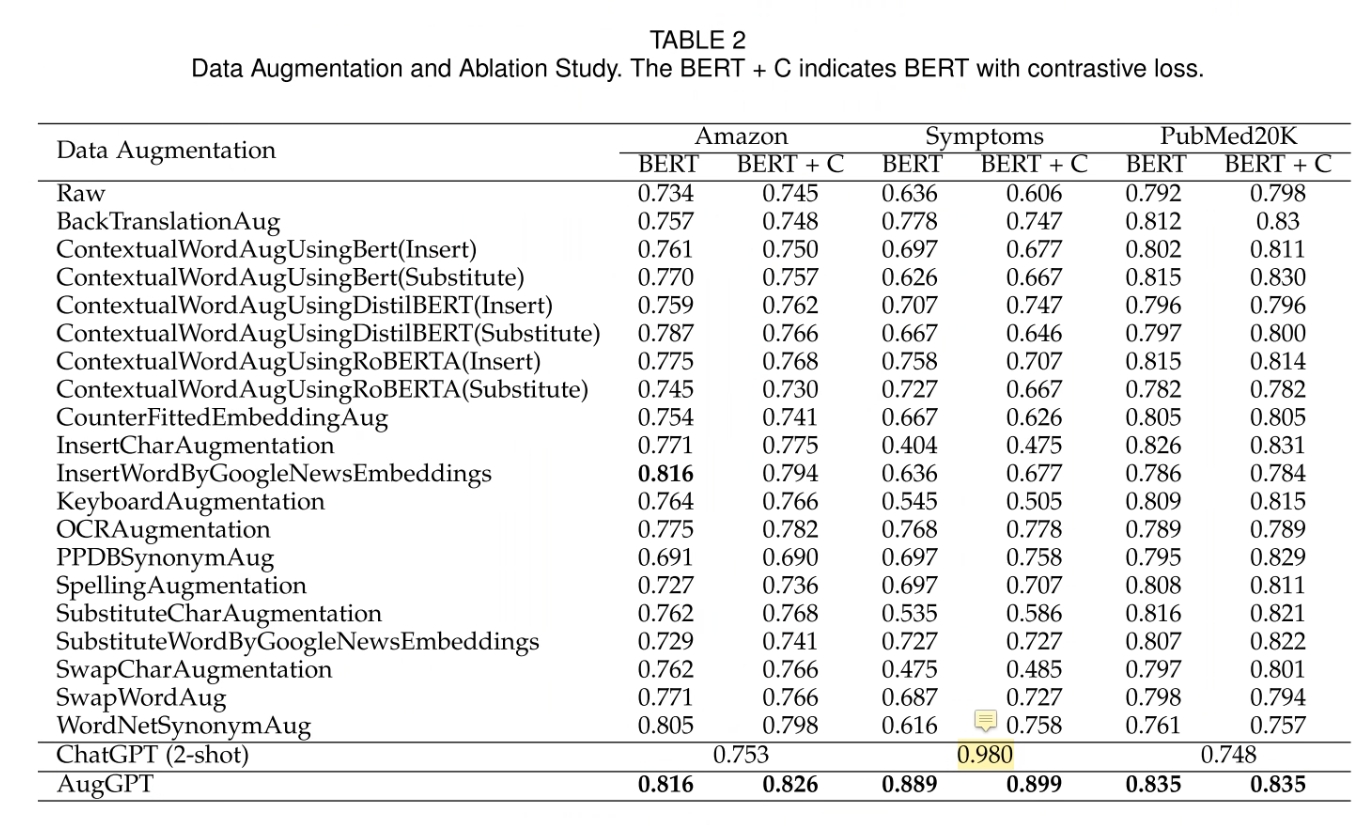
ChatGPT 在 Symptoms 上取得了爆炸的效果(我估计是练过),作者认为是这个数据集比较简单
prompt design
On the Robustness of ChatGPT: An Adversarial and Out-of-distribution Perspective
摘要、引言、相关工作
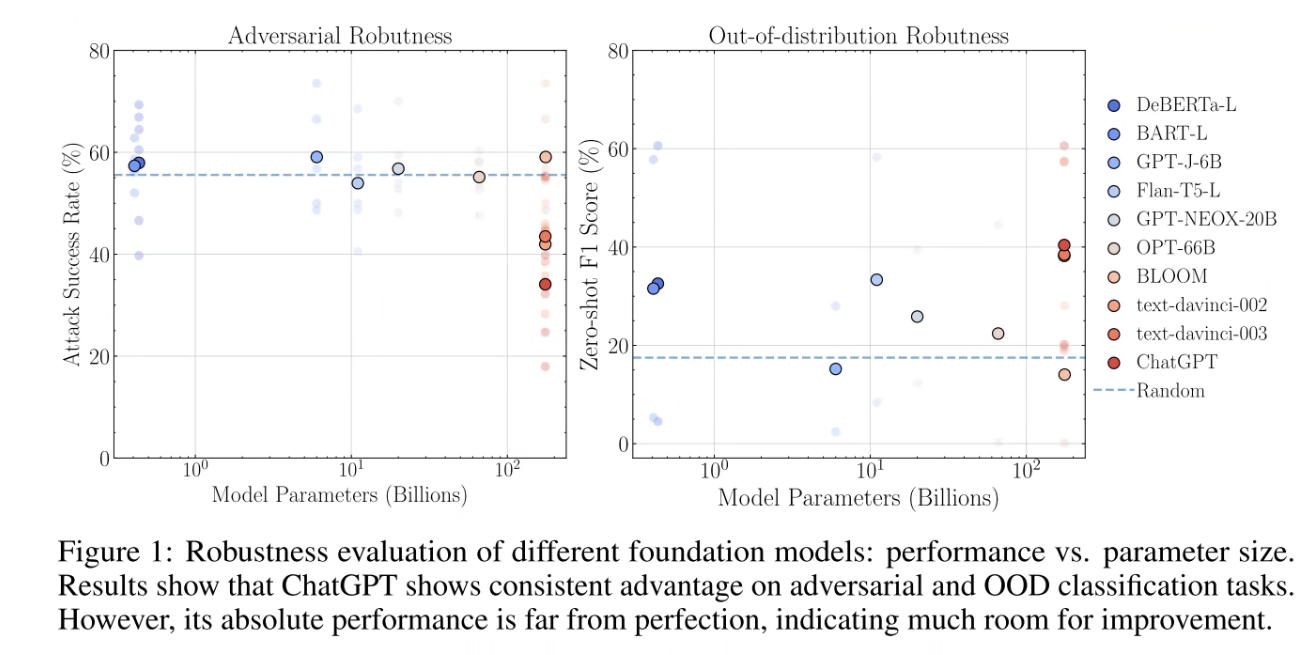
鲁棒性是可解释性的一个指标,因此本文从对抗和 OOD(这个 OOD 只能拿 22 年以后数据的测试)做分析。
例如,尝试用虚假新闻骗过 ChatGPT。
9 个任务,超过 2089 个样本上分析。
ChatGPT 在 Adverseral 和 OOD 上都优于先前的模型。
- ChatGPT 在哪些方面做的好
- ChatGPT 翻译任务上表现比较好
- ChatGPT 在 Adverseral 和 OOD 上都比较好
- 对话表现好
- 表现不好:
- ChatGPT 和人类认为它的水平有差距
- 翻译任务上不如 text-davinci-003
- ChatGPT 对于医学领域相关的问题无法给出确定答案,只能给出一些建议。
模型
两个任务的目标函数

实验
数据集
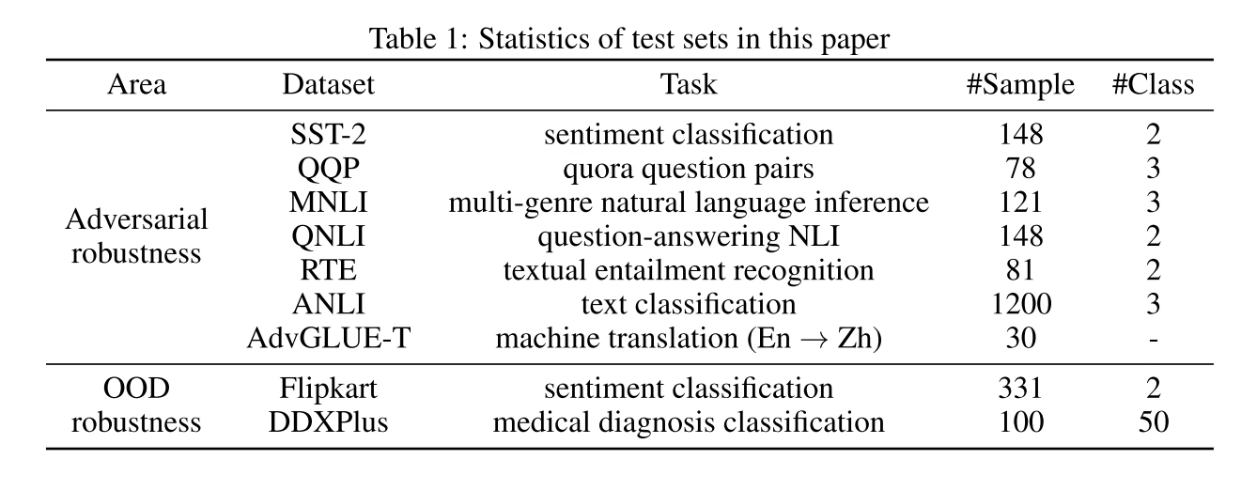
结果
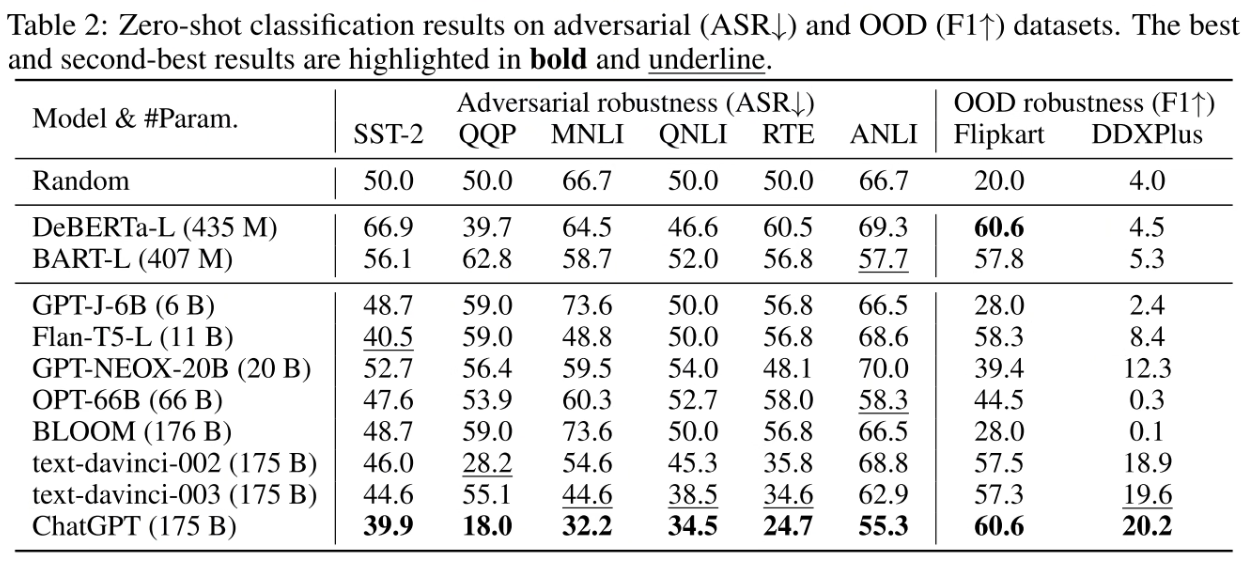
ChatGPT 表现最好
- ChatGPT 在对抗数据集上都表现很好
- 所有 GPT-2 这一系列的模型都在 OOD 数据集上表现很好
- ChatGPT 比较其他的大模型在基于对话的理解上表现更好
Dense Passage Retrieval for Open-Domain Question Answering
摘要、引言、相关工作
- Sparse Retrieval
- Dense Retrieval
- 自回归检索(Autoregressive retrieval)

作者提问:是否可以只用(问题,文章)对在没有额外的与训练是训练一个更好的 dense 潜入模型?
模型
Loss
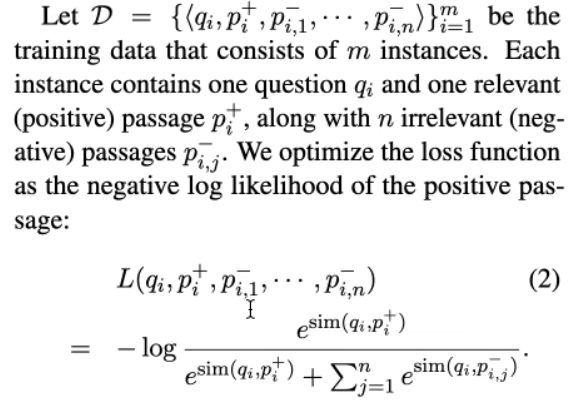
以下有几种负例构建方式:
- 随机从语料库中选负例
- BM25 找出来不包括答案但是匹配大多数问题词元的负例
- Gold:与训练集中出现的其他问题配对的积极段落
实验
结果
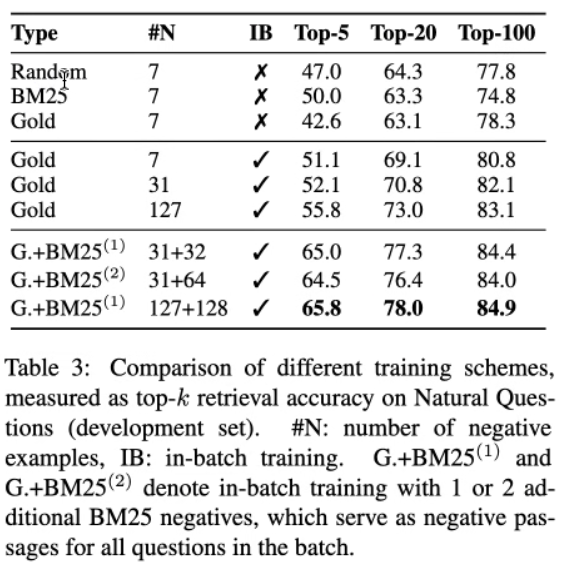
负例越多,效果可能越好
A Neural Corpus Indexer for Document Retrieval
据说本篇有很大争议
摘要、引言、相关工作
作者认为:
- dense retrieval 和 term-based retrieval 都没有办法充分利用神经网络的能力。
- 模型不能合成深度的 查询-文档 交互。
模型
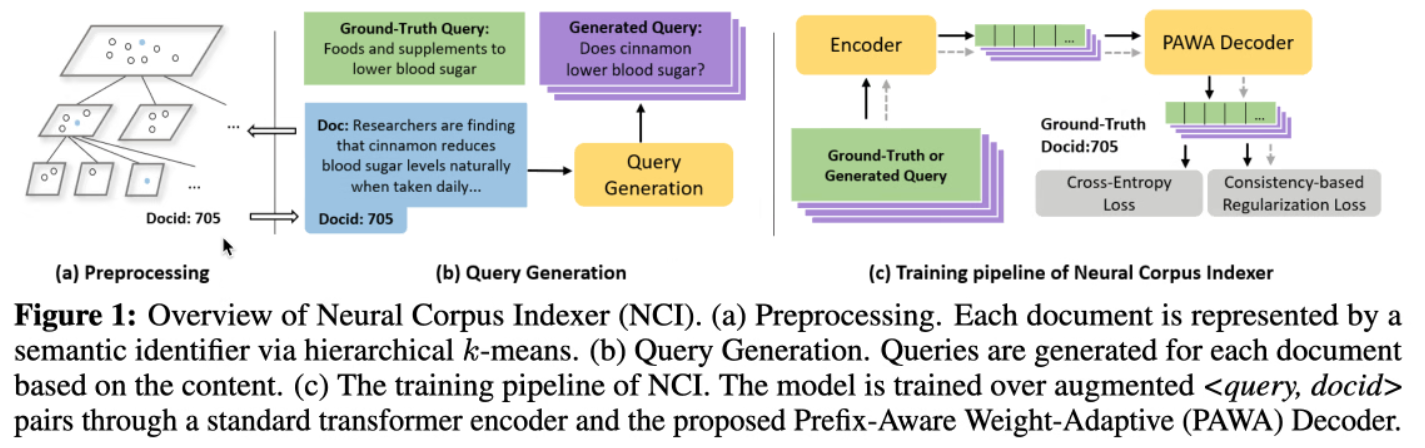
实验
后面跟不上了