如何在不重建容器不中断服务的情况下升级Kubernetes集群大版本,一些探索,方案实现于2021年9月
该功能已上线一段时间,因为一些原因文章迟迟没有发布,升级肯定会有还没有触及到的未知问题,该方案也不是十全十美,但目前上线后也基本平稳,能够处理大部分情况,把自己在这方面的思路和方案的迭代发出来,供大家参考。
背景介绍
Kubernetes版本更新迭代速度很快,大约每个季度发布一个大版本,每次更新都有新的特性加入或修复了之前存在的bug,但是这些特性不会及时或者不能同步到之前的历史大版本中,如果要体验这些特性,需要升级到较新的版本。
当前TKE客户集群中存在着大量的老版本集群,横跨1.8,1.10,1.12,1.14,1.16等版本,部分客户对Kubernetes大版本有强烈的升级需求;同时,用户的线上集群中的业务种类较为复杂,许多业务对于可用性的要求很高,希望保持升级过程中集群中的服务稳定,不受到升级的影响,因此保障Kubernetes集群大版本升级过程的稳定可用十分重要。
本文概述了TKE在Kubernetes大版本升级过程中的一些探索和总结,并按顺序介绍了考虑或设计过的六种升级方式。分别概述了各方案的内容并且指出了方案存在的一些问题,并在该方案的基础上逐步完善,从而推出下一种方案,我们最终采用的是方案6。
升级方案
方案1 滚动升级
● 方案概述:
滚动升级是指升级集群的master节点后,分批次逐步将node节点移出集群,再重新加入集群并对节点进行重新初始化,安装新版本的Kubernetes节点组件,最终该节点的组件会更新为新的版本。
该方式可以使得升级过程复用节点的初始化流程,流程相对较简单;目前TKE可以通过滚动升级的方式对客户集群进行小版本的升级。
● 该方案存在的问题:
显而易见,这种滚动升级(移出移入节点)的方式,由于升级过程中对节点的驱逐,会造成节点上的全部pod被删除和重建,之前对节点的一些自定义设置和部署的内容会丢失,原先部署的环境也会被清理,需要升级后重新部署和设置,代价非常大。
另外,如果客户只有一个节点,或者应用pod实例数较少,亦或是应用没有使用一些高级的资源对象,如支持滚动更新的Deployment等,则会造成pod在升级的这段时间内,服务无法正常运行和被访问。
移入移出和初始化都是过重的操作,升级过程中是否能够不移入移出节点?不对节点进行重新初始化操作呢?直接替换重启Kubernetes组件是否可行?
方案2 原地升级
● 方案概述:
不驱逐节点,而是停止节点Kubernetes组件运行后,替换客户节点上的Kubernetes组件为高版本,之后重启;这种方案相对上一种方案明显更为轻量,操作也很简单,不需要节点的移出移入,对服务的影响更小。
● 存在的问题
我们发现采用这种方案升级之后,节点上的部分或者全部的pod发生了重启,原因是节点上的容器被删除后重建了。
容器为什么会被重建
kubelet中SyncPod(pod *v1.Pod, podStatus *PodStatus, pullSecrets []v1.Secret, backOff *flowcontrol.Backoff) PodSyncResult方法通过如下步骤同步pod到指定的期望状态:
1. Compute sandbox and container changes.
2. Kill pod sandbox if necessary.
3. Kill any containers that should not be running.
4. Create sandbox if necessary.
5. Create ephemeral containers.
6. Create init containers.
7. Create normal containers.
其中的第一步由computePodActions来执行,该方法会检查Pod Sandbox是否发生变更、各个Container的status等因素来决定是否要重建整个Pod,同时计算出了待启动的和待Kill的容器列表; 这其中造成容器重启的核心在于containerChanged方法,如果容器的Spec发生变更,则无论重启策略是什么,都要根据新的Spec重建容器,并将Container添加到待启动容器列表中(changes.ContainersToStart):
var message string
restart := shouldRestartOnFailure(pod)
if _, _, changed := containerChanged(&container, containerStatus); changed {
message = fmt.Sprintf("Container %s definition changed", container.Name)
// Restart regardless of the restart policy because the container
// spec changed.
restart = true
} else if liveness, found := m.livenessManager.Get(containerStatus.ID); found && liveness == proberesults.Failure {
// If the container failed the liveness probe, we should kill it.
message = fmt.Sprintf("Container %s failed liveness probe", container.Name)
} else {
// Keep the container.
keepCount++
continue
}
func containerChanged(container *v1.Container, containerStatus *kubecontainer.ContainerStatus) (uint64, uint64, bool) {
expectedHash := kubecontainer.HashContainer(container)
return expectedHash, containerStatus.Hash, containerStatus.Hash != expectedHash
}
kubelet会根据pod.spec.containers[*]计算hash, 跟之前计算的容器元数据中的hash值对比,如果不一致,就重建容器;要确保一旦容器的spec发生变化,由于hash的改变,kubelet能够重建容器。其中元数据是kubelet创建容器时,根据pod.spec.containers[*]计算出的hash,并把此hash值传递给运行时保存,通过获取容器状态接口获取。
该值在docker中是以类似"annotation.io.kubernetes.container.hash": "6ffb14db"的一个label存在的;在containerd中,是以元数据存储在cri-plugin中的。
hash值为什么会变
随着Kubernetes版本的不停迭代,在跨大版本开发时,Pod中的Container 结构体会发生变化,造成kubelet升级大版本以后,新版本kubelet运行后计算出来的hash值跟老版本计算hash值不一样,于是重建容器。 比如:
● 版本之间的差异
○ 1.14相较1.12
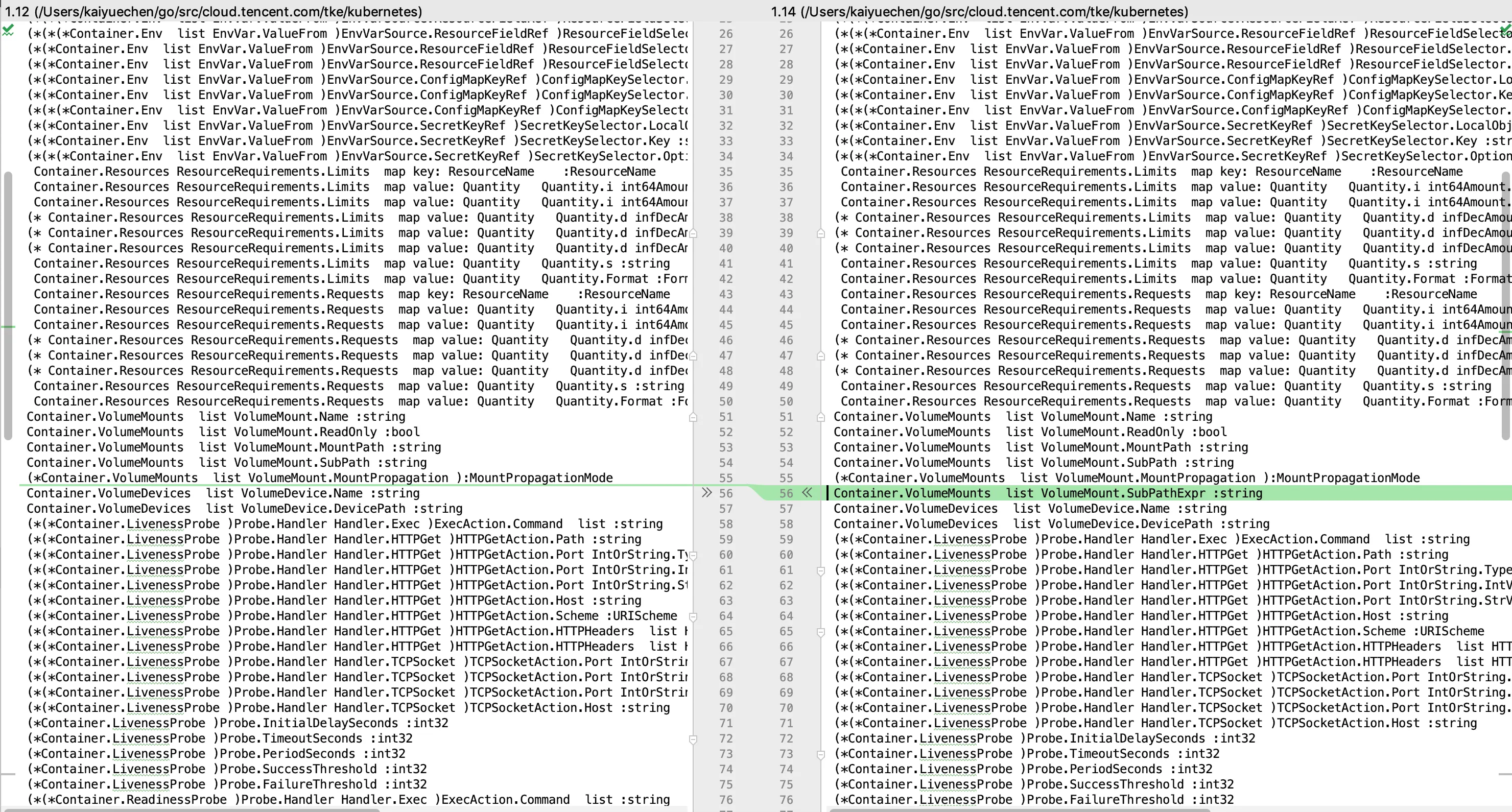
VolumeMounts字段多了SubPathExpr string字段
○ 1.12相较1.10
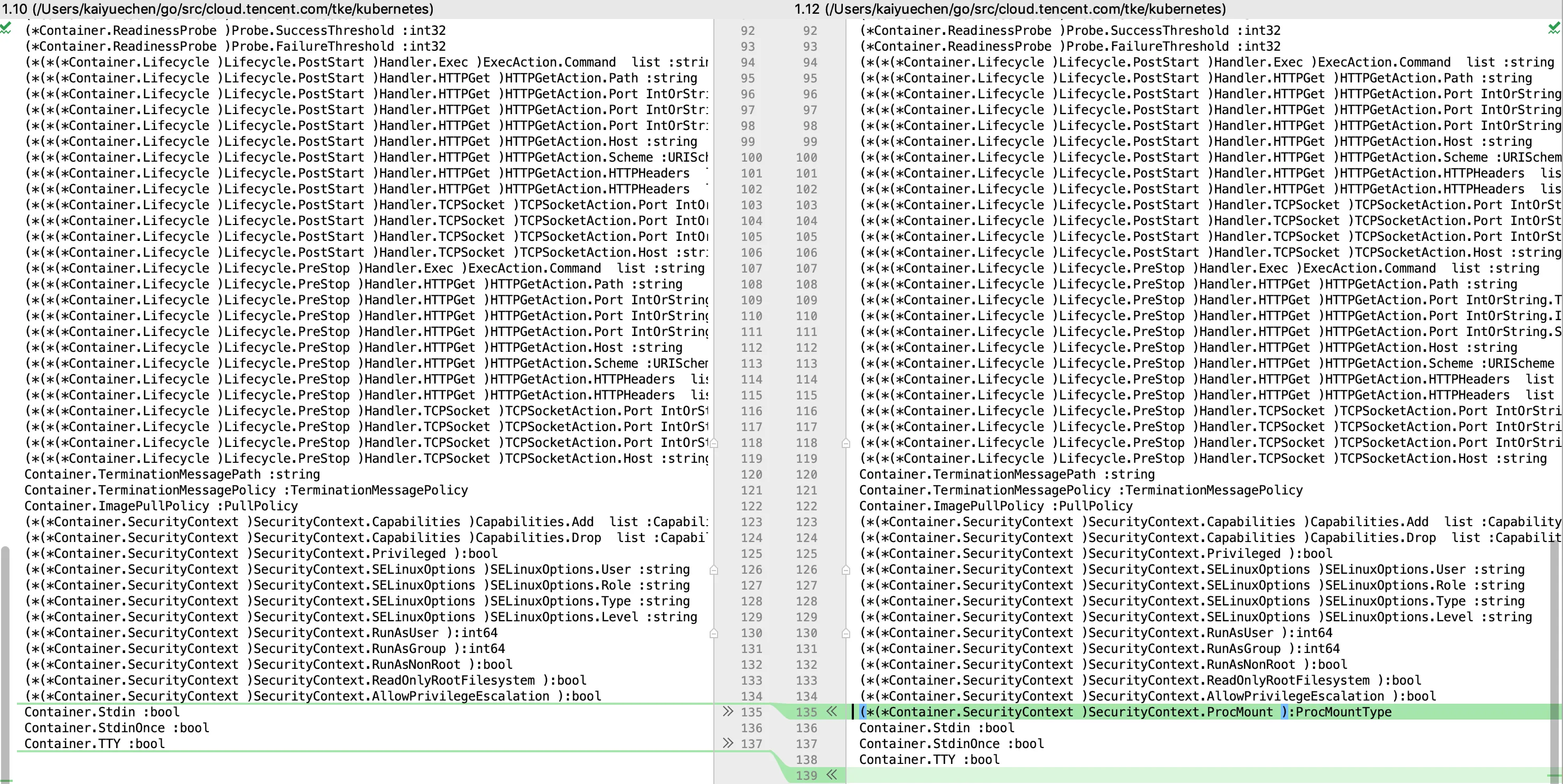
securitycontext字段多了ProcMount *ProcMountType字段
○ 1.10相较1.8
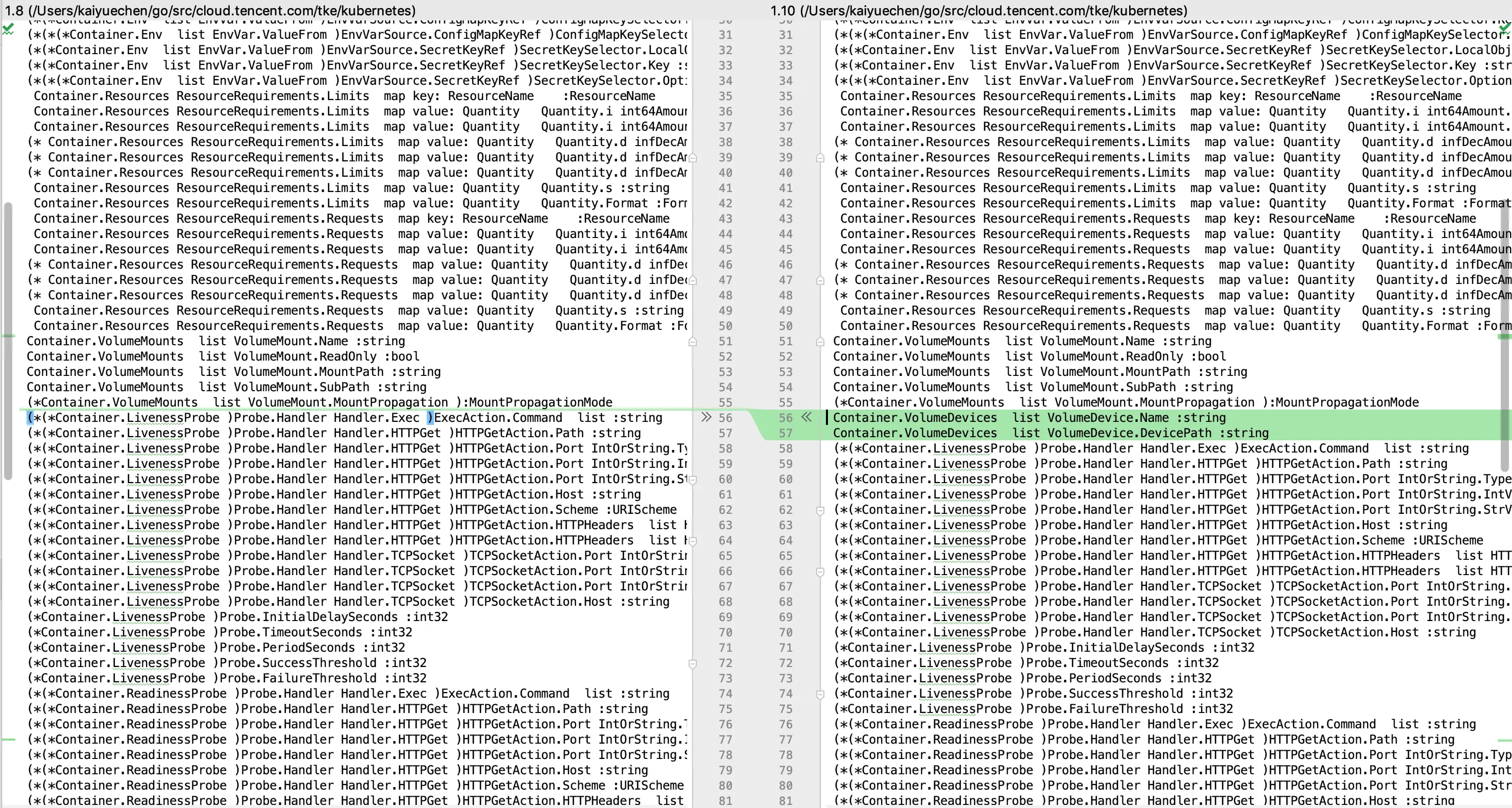
container根结构多了volumeDevices字段
● 由于container结构不同,新版本相对老版本中多出来的字段会造成计算出来的hash值不同
社区中也有对该升级过程中容器重启问题的反馈
容器重建有什么影响,是否可以接受
1. 重建首先会造成已连接的服务中断,会造成服务的波动或者不可用,如果应用实例数量较少,也会造成个别pod负载过高
2. 一些没有按照云原生方式使用Kubernetes的用户希望pod的ip保持不变,服务强依赖pod的固定ip,pod重建可能会带来pod ip的改变,客户需要重新部署服务
3. 一个节点上的容器重建过程可能会伴随着大量的镜像重新下载,内部环境初始化等操作,会造成短时间内节点的网络和磁盘IO负载变高,影响服务的性能
可见,容器重建和我们希望集群服务稳定的需求是冲突的,应当尽量避免;能否在升级过程中避免对容器的重建呢?
方案3 社区方案
● 方案概述
针对因为container结构体变动造成的hash改动,社区在1.16版本中合入了一个修复方案
该方案主要是在计算container hash的时候忽略container结构体中的nil或空的字段:在升级情况下,老版本的container结构体中由于不包含新的字段,所以在新的结构体中,新增字段必然为空,通过该方式,忽略掉新增字段,如release中的fieldN+1字段
release1: {field1, field2...fieldN}
release2: {field1, field2...fieldN, fieldN+1}
● 存在的问题
不过,这个方案有个很明显的问题在于,从原先的hash计算方法切换到这种新的hash计算方案,即使对于相同版本的同一个container结构体,算出来的hash值也是不同的,因为新方法忽略掉了为空的部分字段。
所以存量用户在使用的时候必须要经历一次全范围的容器重启,以切换到新的hash计算方法,之后才能保证升级后的hash不变;这个方案显然不够完美,只是对于最初就使用了该方法的新版集群,可以一劳永逸,然而大量的存量集群是无法满足条件的。
方案4 原地无损升级-增加运行时接口直接修改hash信息
● 方案概述
在上文中,我们提到过,hash值在docker中是以类似"annotation.io.kubernetes.container.hash": "6ffb14db"的一个label存在的;在containerd中,是以元数据存储在cri-plugin中的。
如果我们能提前计算出新版本容器的hash值,并修改容器的label或者元数据的值为新值,这样新的kubelet启动后计算的值不就和容器中的元数据的值一样了么,也就不会触发重建了。
但是,目前docker不支持label的更新, cri也没有修改这个元数据的原生能力。
因此,我们为当前TKE支持的两种运行时docker和containerd提供了上面这两种接口,赋予了这种定制版本修改元数据的能力。
此时,整体的升级流程如下:
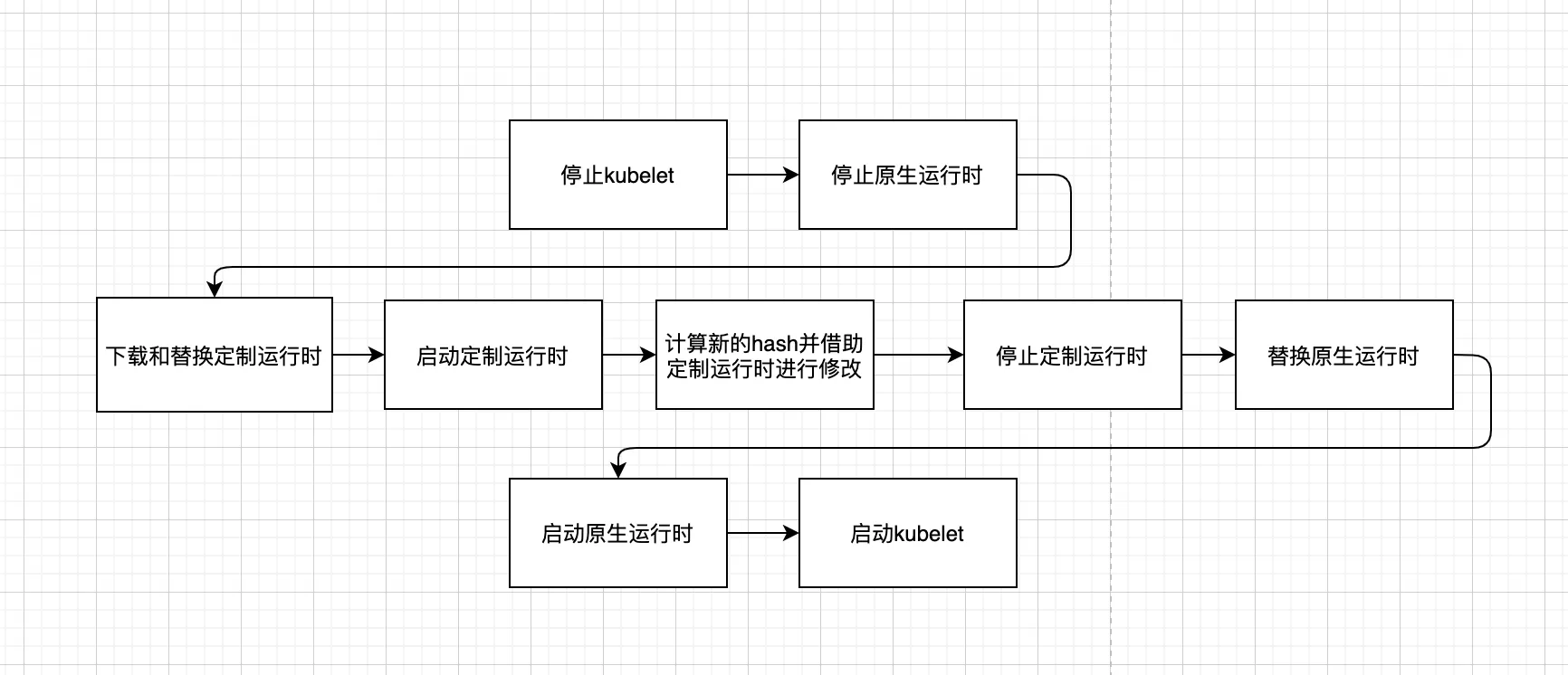
● 存在的问题
可以看到,这个过程中进行了2次运行时的替换,进行了2次运行时的停止和启动,这是一个相对较重的操作,无疑是有一定风险的,尤其是对负载较高的节点。
另外,虽然有很多讨论
https://github.com/moby/moby/issues/15496
https://github.com/moby/moby/issues/21721
https://github.com/moby/moby/issues/20356
https://github.com/moby/moby/pull/18958
但由于社区一直没有同意对容器的label进行修改,或者只新增了小范围的支持,我们的功能始终只能自行维护,针对不同的运行时版本,我们需要维护不同的定制版本,包括多个版本的dockerd,docker-cli,containerd,crictl,如果后期新增了新的运行时版本,还需要对该特性进行迁移,维护和开发量较大。
方案5 原地无损升级-修改运行时持久化数据
● 方案概述
容器的数据最终都是需要持久化的,可否停止运行时后直接去修改持久化的数据,之后重启运行时读取数据。
通过这种方式,可以很方便地对hash信息进行修改,开发量也很小,同时,我们不再需要维护多版本的定制运行时,保持了和社区的一致;最重要的是,整个升级过程只需进行一次容器的启停,而且无需进行运行时的替换
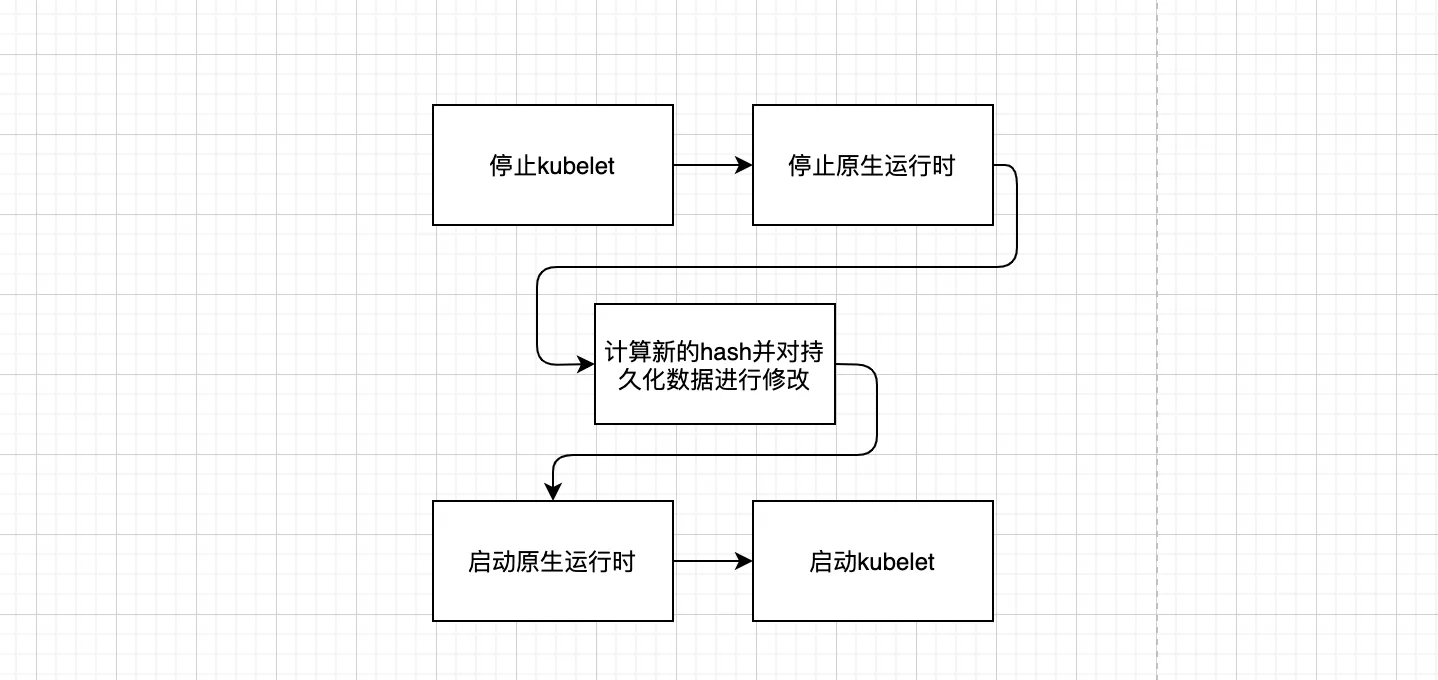
可以看到,中间层略去了许多步骤,升级过程更为轻量。
经过验证,这种方式是可行的,最终的升级流程如下:

方案6 原地无损升级-特殊情况也要保障服务稳定
经过几版迭代,方案5已经较为成熟;但有同学提出如果升级时间过长,kubelet停止时间过长会造成node Ready status变为Unknown后造成pod被驱逐和迁移。
仔细分析确实是存在这种情况的,甚至还会造成pod被从service 的endpoint列表中删除,造成对服务的一部分访问无响应;如果客户设置的服务后端实例pod数量较少,甚至会造成一定时间内服务的完全不可用。
我们提出的解决方案是在方案5的基础上在升级过程中限制对升级节点的node taint的添加和对endpoint列表的更改。保证在升级过程中node,pod,endpoint的稳定。
Webhook开发中,我们也发现了一个node taint相关的Kubernetes 社区bug并提出了修复方案。
还有一些诸如pod日志路径变化,cgroup路径变化等,也通过脚本进行修正适配。