一、打造基于Prometheus的全方位监控平台
1.1 前言
官网:https://prometheus.io/docs/prometheus/latest/getting_started/
- 灵活的时间序列数据库
- 定制各式各样的监控规则
- Prometheus的开发人员和用户社区非常活跃
- 独立的开源项目,不依赖于任何公司
- 继Kubernetes之后第二个入驻的项目
1.2 Prometheus架构

Prometheus的工作原理主要分5个步骤:
- 数据采集(Exporters):Prometheus 定期通过HTTP请求从目标资源中拉取数据。目标资源可以是应用程序、系统、服务或其他资源
- 数据存储(Storage):Prometheus 将采集到的数据存储在本地存储引擎中。存储引擎以时间序列方式存储数据,其中每个时间序列都由指标名称和一组键值对组成。
- 数据聚合(PromQL):Prometheus 通过查询表达式聚合数据。PromQL是Prometheus的查询语言,它允许用户通过查询表达式从存储引擎中检索指标的特定信息。
- 告警处理(Alertmanger):Prometheus 可以根据用户指定的规则对数据进行警报。当指标的值超出特定阈值时,Prometheus向Alertmanager 发出警报。Alertmanger 可以帮助用户对警报进行分组、消除和路由,并将警报发送到相应的接收器,例如邮件、企微、钉钉等。
- 数据大盘(Grafana):帮助用户通过可视化方式展示Prometheus的数据,包括仪表盘、图标、日志和警报等。
1.3 Prometheus时间序列数据
1.3.1 什么是序列数据?
时间序列数据(TimeSeries Data):按照时间顺序记录系统、设备状态裱花的数据称为时序数据
1.3.2 时间序列数据特点
- 性能好:关系数据库对于大规模数据的处理性能很糟。NOSQL可以很好的处理大规模数据,依然比不上时间序列数据库
- 存储成本低:高效的压缩算法,节省存储空间,有效降低IO
官方数据:Prometheus有非常高效的时间序列数据存储方法,每个采样数据仅仅3.5byte作用空间,上百万条时间序列数据,30秒间隔,保留60天,大概200多G。
1.3.3 Prometheues 适合场景
Prometheus非常适合记录任何纯数字时间序列。它既适合以机器为中心的监控,也适合监控高度动态的面向服务的体系架构。
2、部署配置
整个监控体系设计的技术栈较多,集合覆盖真实企业中的所有场景。主要技术栈如下:
- Prometheus:监控主服务
- node-exporter:数据采集器
- kube-state-metrics:数据采集器
- metrics-server:数据采集器
- Consul:自动发现
- blackbox:黑盒拨测
- Alermanager:监控告警服务
- Grafana:数据展示服务
- prometheusAlert:告警消息转发服务
2.1 Prometheus部署
部署对外可访问Prometheus:
- 创建Prometheus所在的命名空间
- 创建Prometheus使用的RBAC规则
- 创建Prometheus的configmap保存配置文件
- 创建service暴露Prometheus服务
- 创建deployment部署Prometheus容器
- 创建Ingress实现外部域名访问Prometheus
部署顺序如下图:
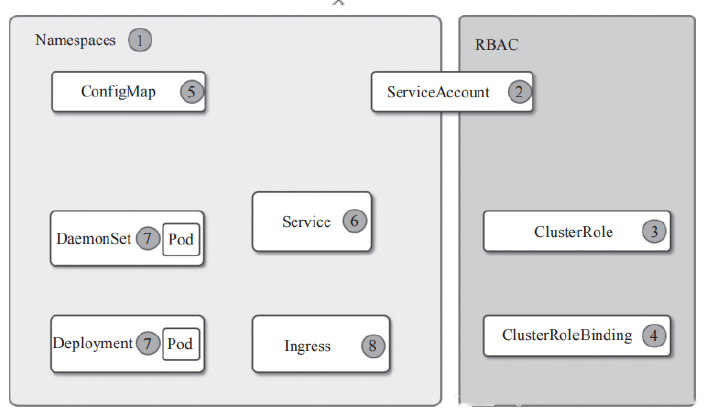
2.1.1 创建命名空间
[root@master-1-230 ~]# kubectl create namespace monitor
namespace/monitor created2.1.2 创建RBAC规则
创建RBAC规则:包括ServiceAccount、ClusterRole、ClusterRoleBinding 三类YAML文件
[root@master-1-230 7.1]# cat RBAC.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
name: prometheus
namespace: monitor
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: prometheus
rules:
- apiGroups: [""]
resources: ["nodes","nodes/proxy","services","endpoints","pods"]
verbs: ["get", "list", "watch"]
- apiGroups: ["extensions"]
resources: ["ingress"]
verbs: ["get", "list", "watch"]
- nonResourceURLs: ["/metrics"]
verbs: ["get"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: prometheus
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: cluster-admin
subjects:
- kind: ServiceAccount
name: prometheus
namespace: monitor应用yaml
[root@master-1-230 7.1]# kubectl apply -f RBAC.yaml
serviceaccount/prometheus created
clusterrole.rbac.authorization.k8s.io/prometheus created
clusterrolebinding.rbac.authorization.k8s.io/prometheus created验证:
[root@master-1-230 7.1]# kubectl get sa prometheus -n monitor
NAME SECRETS AGE
prometheus 0 17m
[root@master-1-230 7.1]# kubectl get clusterrole prometheus
NAME CREATED AT
prometheus 2023-12-16T00:37:08Z
[root@master-1-230 7.1]# kubectl get clusterrolebinding prometheus
NAME ROLE AGE
prometheus ClusterRole/cluster-admin 19m2.1.3 创建ConfigMap类型的Prometheus配置文件
[root@master-1-230 7.1]# cat configmap.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: prometheus-config
namespace: monitor
data:
prometheus.yml: |
global:
scrape_interval: 15s
evaluation_interval: 15s
external_labels:
cluster: "kubernetes"
############ 数据采集job ###################
scrape_configs:
- job_name: prometheus
static_configs:
- targets: ['127.0.0.1:9090']
labels:
instance: prometheus
############ 指定告警规则文件路径位置 ###################
rule_files:
- /etc/prometheus/rules/*.rules[root@master-1-230 7.1]# kubectl apply -f configmap.yaml
configmap/prometheus-config created验证:
[root@master-1-230 7.1]# kubectl get cm prometheus-config -n monitor
NAME DATA AGE
prometheus-config 1 42s2.1.4 创建ConfigMap类型的prometheus rules配置文件
使用ConfigMap方式创建prometheus rules的配置文件
包含的内容是两块:分别是general.rules 和node.rules
[root@master-1-230 7.1]# cat rules.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: prometheus-rules
namespace: monitor
data:
general.rules: |
groups:
- name: general.rules
rules:
- alert: InstanceDown
expr: |
up{job=~"k8s-nodes|prometheus"} == 0
for: 1m
labels:
severity: critical
annotations:
summary: "Instance {{ $labels.instance }} 停止工作"
description: "{{ $labels.instance }} 主机名:{{ $labels.hostname }} 已经停止1分钟以上."
node.rules: |
groups:
- name: node.rules
rules:
- alert: NodeFilesystemUsage
expr: |
100 - (node_filesystem_avail_bytes / node_filesystem_size_bytes) * 100 > 85
for: 1m
labels:
severity: warning
annotations:
summary: "Instance {{ $labels.instance }} : {{ $labels.mountpoint }} 分区使用率过高"
description: "{{ $labels.instance }} 主机名:{{ $labels.hostname }} : {{ $labels.mountpoint }} 分区使用大于85% (当前值: {{ $value }})"验证确认:
[root@master-1-230 7.1]# kubectl apply -f rules.yaml
configmap/prometheus-rules created
[root@master-1-230 7.1]# kubectl get cm -n monitor prometheus-rules
NAME DATA AGE
prometheus-rules 2 65s2.1.5 创建prometheus svc
[root@master-1-230 7.1]# cat p_svc.yaml
apiVersion: v1
kind: Service
metadata:
name: prometheus
namespace: monitor
labels:
k8s-app: prometheus
spec:
type: LoadBalancer
ports:
- name: http
port: 9090
targetPort: 9090
selector:
k8s-app: prometheus验证:
[root@master-1-230 7.1]# kubectl apply -f p_svc.yaml
service/prometheus created
[root@master-1-230 7.1]# kubectl get svc -n monitor
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
prometheus LoadBalancer 10.110.122.35 192.168.1.200 80:31370/TCP 7s2.1.6 创建prometheus deploy
由于Prometheus 需要对数据进行持久化,以便在重启后能够恢复历史数据。本次选择NFS做存储实现持久化
[root@master-1-230 7.1]# kubectl get sc
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
nfs-client k8s-sigs.io/nfs-subdir-external-provisioner Delete Immediate false 20d
nfs-storageclass (default) k8s-sigs.io/nfs-subdir-external-provisioner Retain Immediate false 20d使用NFS提供的StorageClass做数据存储
[root@master-1-230 7.1]# cat pvc.yaml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: prometheus-data-pvc
namespace: monitor
spec:
accessModes:
- ReadWriteMany
storageClassName: "nfs-storageclass"
resources:
requests:
storage: 10Gi[root@master-1-230 7.1]# kubectl apply -f pvc.yaml
persistentvolumeclaim/prometheus-data-pvc created
[root@master-1-230 7.1]# kubectl get pvc prometheus-data-pvc -n monitor
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
prometheus-data-pvc Bound pvc-f3669c79-a0ce-4593-8ced-72af4abe3a2a 10Gi RWX nfs-storageclass 32sPrometheus 控制器文件
apiVersion: apps/v1
kind: Deployment
metadata:
name: prometheus
namespace: monitor
labels:
k8s-app: prometheus
spec:
replicas: 1
selector:
matchLabels:
k8s-app: prometheus
template:
metadata:
labels:
k8s-app: prometheus
spec:
serviceAccountName: prometheus
containers:
- name: prometheus
image: prom/prometheus:v2.36.0
imagePullPolicy: IfNotPresent
ports:
- name: http
containerPort: 9090
securityContext:
runAsUser: 65534
privileged: true
command:
- "/bin/prometheus"
args:
- "--config.file=/etc/prometheus/prometheus.yml"
- "--web.enable-lifecycle"
- "--storage.tsdb.path=/prometheus"
- "--storage.tsdb.retention.time=10d"
- "--web.console.libraries=/etc/prometheus/console_libraries"
- "--web.console.templates=/etc/prometheus/consoles"
resources:
limits:
cpu: 2000m
memory: 2048Mi
requests:
cpu: 1000m
memory: 512Mi
readinessProbe:
httpGet:
path: /-/ready
port: 9090
initialDelaySeconds: 5
timeoutSeconds: 10
livenessProbe:
httpGet:
path: /-/healthy
port: 9090
initialDelaySeconds: 30
timeoutSeconds: 30
volumeMounts:
- name: data
mountPath: /prometheus
subPath: prometheus
- name: config
mountPath: /etc/prometheus
- name: prometheus-rules
mountPath: /etc/prometheus/rules
- name: configmap-reload
image: jimmidyson/configmap-reload:v0.5.0
imagePullPolicy: IfNotPresent
args:
- "--volume-dir=/etc/config"
- "--webhook-url=http://localhost:9090/-/reload"
resources:
limits:
cpu: 100m
memory: 100Mi
requests:
cpu: 10m
memory: 10Mi
volumeMounts:
- name: config
mountPath: /etc/config
readOnly: true
volumes:
- name: data
persistentVolumeClaim:
claimName: prometheus-data-pvc
- name: prometheus-rules
configMap:
name: prometheus-rules
- name: config
configMap:
name: prometheus-config[root@master-1-230 7.1]# kubectl apply -f deployment.yaml
deployment.apps/prometheus created验证:
[root@master-1-230 7.1]# kubectl get pod -n monitor
NAME READY STATUS RESTARTS AGE
prometheus-7c45654c5f-hwdg7 2/2 Running 0 38s
[root@master-1-230 7.1]#
您在 /var/spool/mail/root 中有新邮件
[root@master-1-230 7.1]# kubectl get deploy -n monitor
NAME READY UP-TO-DATE AVAILABLE AGE
prometheus 1/1 1 1 67s部署的Deployment 资源文件中containers部分配置了两个容器,分别是
- configmap-reload:用于监听Configmap文件内容,如果内容发送变化,执行webhook url 请求,因为Prometheus 支持通过接口重新加载配置文件,所以使用容器提供的机制完成Prometheus Configmap配置文件内容一样改动,就会执行Prometheus 的- reload 接口,更新配置
- prometheus:Prometheus 容器是主容器,用于运行Prometheus 进行。
上面资源文件中Prometheus参数说明:
- --web.enable-lifecycle: 启用 Prometheus 用于重新加载配置的 /-/reload 接口
- --config.file: 指定 Prometheus 配置文件所在地址,这个地址是相对于容器内部而言的
- --storage.tsdb.path: 指定 Prometheus 数据存储目录地址,这个地址是相对于容器而言的
- --storage.tsdb.retention.time: 指定删除旧数据的时间,默认为 15d
- --web.console.libraries: 指定控制台组件依赖的存储路径
- --web.console.templates: 指定控制台模板的存储路径
2.1.7 创建Prometheus ingress 实现外部域名访问
[root@master-1-230 7.1]# cat ingress.yaml
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
namespace: monitor
name: prometheus-ingress
spec:
ingressClassName: nginx
rules:
- host: prometheus.ikubernetes.cloud
http:
paths:
- pathType: Prefix
backend:
service:
name: prometheus
port:
number: 9090
path: /[root@master-1-230 7.1]# kubectl apply -f ingress.yaml
ingress.networking.k8s.io/prometheus-ingress created验证
[root@master-1-230 7.1]# kubectl get ingress -n monitor
NAME CLASS HOSTS ADDRESS PORTS AGE
prometheus-ingress nginx prometheus.ikubernetes.cloud 192.168.1.204 80 32s
[root@master-1-230 7.1]# curl prometheus.ikubernetes.cloud
<a href="/graph">Found</a>.
3、初始Prometheus 监控平台
Prometheus 监控平台:
- Graph:用于绘制图标,选择不同的时间范围、指标和标签,还可以添加多个图标进行比较
- Alert:用于设置告警规则,当指标达到预定的阈值,会发送告警通知
- Expore:用于查询和浏览指标数据,通过查询表达式或标签过滤器来查找数据
- Status:用于查看Prometheus的状态信息,包括当前的targets、rules、alerts等
- Config:用于编辑prometheus的配置文件,可以添加、修改和删除配置项
4、总结
- 全面的监控:Prometheus可以监控各种数据源,比如服务器、容器等,还支持度量数据和日志数据等多种类型的监控。
- 支持动态服务发现:Prometheus可以自动地发现并监控正在运行的服务,从而避免手动配置。
- 灵活的告警机制:Prometheus支持可配置的告警规则,可以根据不同的情况发出不同的告警信息,并且可以通过API通知其他服务。
- 多维数据模型:Prometheus的数据模型支持多维度的数据,可以使用标准的PromQL查询语言对数据进行分析和展示。
- 高效的存储:Prometheus使用自己的时间序列数据库存储数据,采用一种基于时间的存储方式,可以高效地处理大量数据。
二、K8S集群层面监控(上)
1、KubeStateMetrics简介
kube-state-metrics 是kubernetes组件,通过查询Kubernetes的API服务器,收集关于Kubernetes中各种资源(如:节点、pod、服务等)的状态信息,并将这些信息转换成Prometheus可以使用的指标
kube-state-metrics 主要功能
- 节点状态信息:如节点CPU和内存使用情况、节点状态、节点标签等
- Pod的状态信息,如Pod状态、容器状态、容器镜像信息、Pod的标签和注释等
- Deployment、Daemonset、Statefulset 和ReplicaSet等控制器的状态信息,如副本数、副本状态、创建时间等
- Service的状态信息,如服务类型、服务IP和端口等
- 存储卷的状态信息。如存储卷类型、存储卷容量等
- Kubernetes的API服务器状态信息,如API服务器的状态、请求次数、响应时间等
通过kube-state-metrics 方便的对Kubernetes 集群进行监控,发现问题,以及提前预警。
2、KubeStateMetrics
包含ServceAccount、ClusterRole、ClusterRoleBinding、Deployment、ConfigMap、Service流泪YAML
[root@master-1-230 7.2]# cat kubeStateMetrics.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
name: kube-state-metrics
namespace: monitor
labels:
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: kube-state-metrics
labels:
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
rules:
- apiGroups: [""]
resources:
- configmaps
- secrets
- nodes
- pods
- services
- resourcequotas
- replicationcontrollers
- limitranges
- persistentvolumeclaims
- persistentvolumes
- namespaces
- endpoints
verbs: ["list", "watch"]
- apiGroups: ["apps"]
resources:
- statefulsets
- daemonsets
- deployments
- replicasets
verbs: ["list", "watch"]
- apiGroups: ["batch"]
resources:
- cronjobs
- jobs
verbs: ["list", "watch"]
- apiGroups: ["autoscaling"]
resources:
- horizontalpodautoscalers
verbs: ["list", "watch"]
- apiGroups: ["networking.k8s.io", "extensions"]
resources:
- ingresses
verbs: ["list", "watch"]
- apiGroups: ["storage.k8s.io"]
resources:
- storageclasses
verbs: ["list", "watch"]
- apiGroups: ["certificates.k8s.io"]
resources:
- certificatesigningrequests
verbs: ["list", "watch"]
- apiGroups: ["policy"]
resources:
- poddisruptionbudgets
verbs: ["list", "watch"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
name: kube-state-metrics-resizer
namespace: monitor
labels:
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
rules:
- apiGroups: [""]
resources:
- pods
verbs: ["get"]
- apiGroups: ["extensions","apps"]
resources:
- deployments
resourceNames: ["kube-state-metrics"]
verbs: ["get", "update"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: kube-state-metrics
labels:
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: kube-state-metrics
subjects:
- kind: ServiceAccount
name: kube-state-metrics
namespace: monitor
---
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: kube-state-metrics
namespace: monitor
labels:
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: Role
name: kube-state-metrics-resizer
subjects:
- kind: ServiceAccount
name: kube-state-metrics
namespace: monitor
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: kube-state-metrics
namespace: monitor
labels:
k8s-app: kube-state-metrics
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
version: v1.3.0
spec:
selector:
matchLabels:
k8s-app: kube-state-metrics
version: v1.3.0
replicas: 1
template:
metadata:
labels:
k8s-app: kube-state-metrics
version: v1.3.0
annotations:
scheduler.alpha.kubernetes.io/critical-pod: ''
spec:
priorityClassName: system-cluster-critical
serviceAccountName: kube-state-metrics
containers:
- name: kube-state-metrics
image: k8s.gcr.io/kube-state-metrics/kube-state-metrics:v2.4.2
ports:
- name: http-metrics ## 用于公开kubernetes的指标数据的端口
containerPort: 8080
- name: telemetry ##用于公开自身kube-state-metrics的指标数据的端口
containerPort: 8081
readinessProbe:
httpGet:
path: /healthz
port: 8080
initialDelaySeconds: 5
timeoutSeconds: 5
- name: addon-resizer ##addon-resizer 用来伸缩部署在集群内的 metrics-server, kube-state-metrics等监控组件
image: mirrorgooglecontainers/addon-resizer:1.8.6
resources:
limits:
cpu: 200m
memory: 200Mi
requests:
cpu: 100m
memory: 30Mi
env:
- name: MY_POD_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: MY_POD_NAMESPACE
valueFrom:
fieldRef:
fieldPath: metadata.namespace
volumeMounts:
- name: config-volume
mountPath: /etc/config
command:
- /pod_nanny
- --config-dir=/etc/config
- --container=kube-state-metrics
- --cpu=100m
- --extra-cpu=1m
- --memory=100Mi
- --extra-memory=2Mi
- --threshold=5
- --deployment=kube-state-metrics
volumes:
- name: config-volume
configMap:
name: kube-state-metrics-config
---
# Config map for resource configuration.
apiVersion: v1
kind: ConfigMap
metadata:
name: kube-state-metrics-config
namespace: monitor
labels:
k8s-app: kube-state-metrics
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
data:
NannyConfiguration: |-
apiVersion: nannyconfig/v1alpha1
kind: NannyConfiguration
---
apiVersion: v1
kind: Service
metadata:
name: kube-state-metrics
namespace: monitor
labels:
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
kubernetes.io/name: "kube-state-metrics"
annotations:
prometheus.io/scrape: 'true'
spec:
ports:
- name: http-metrics
port: 8080
targetPort: http-metrics
protocol: TCP
- name: telemetry
port: 8081
targetPort: telemetry
protocol: TCP
selector:
k8s-app: kube-state-metrics应用yaml
[root@master-1-230 7.2]# kubectl apply -f kubeStateMetrics.yaml
serviceaccount/kube-state-metrics created
clusterrole.rbac.authorization.k8s.io/kube-state-metrics created
role.rbac.authorization.k8s.io/kube-state-metrics-resizer created
clusterrolebinding.rbac.authorization.k8s.io/kube-state-metrics created
rolebinding.rbac.authorization.k8s.io/kube-state-metrics created
Warning: spec.template.metadata.annotations[scheduler.alpha.kubernetes.io/critical-pod]: non-functional in v1.16+; use the "priorityClassName" field instead
deployment.apps/kube-state-metrics created
configmap/kube-state-metrics-config created
service/kube-state-metrics created验证:
[root@master-1-230 7.2]# kubectl get all -n monitor|grep kube-state-metrics
pod/kube-state-metrics-6bddcbb99b-g8wlh 2/2 Running 0 2m31s
service/kube-state-metrics ClusterIP 10.100.166.82 <none> 8080/TCP,8081/TCP 2m31s
deployment.apps/kube-state-metrics 1/1 1 1 2m31s
replicaset.apps/kube-state-metrics-6bddcbb99b 1 1 1 2m31s
[root@master-1-230 7.2]# kubectl get service -n monitor |grep kube-state-metrics|awk '{print $3}'
10.100.166.82
[root@master-1-230 7.2]# curl -kL $(kubectl get service -n monitor |grep kube-state-metrics|awk '{print $3}'):8080/metrics|more
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
0 0 0 0 0 0 0 0 --:--:-- --:--:-- --:--:-- 0# HELP kube_certificatesigningrequest_annotations Kubernetes annotations converted to Prometheus labels.
# TYPE kube_certificatesigningrequest_annotations gauge
# HELP kube_certificatesigningrequest_labels Kubernetes labels converted to Prometheus labels.
# TYPE kube_certificatesigningrequest_labels gauge
# HELP kube_certificatesigningrequest_created Unix creation timestamp2.1 新增kubernetes 集群架构监控
在prometheus-config.yaml 依次添加如下采集数据
2.1.1 kube-apiserver
使用https访问时,需要tls相关配置,可指定ca证书或insecure_skip_verify: true 跳过证书验证
除此之外,还要指定bearer_token_file,否则会提示
- job_name: kube-apiserver
kubernetes_sd_configs:
- role: endpoints
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
relabel_configs:
- source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name]
action: keep
regex: default;kubernetes
- source_labels: [__meta_kubernetes_endpoints_name]
action: replace
target_label: endpoint
- source_labels: [__meta_kubernetes_pod_name]
action: replace
target_label: pod
- source_labels: [__meta_kubernetes_service_name]
action: replace
target_label: service
- source_labels: [__meta_kubernetes_namespace]
action: replace
target_label: namespace2.1.2 controller-manager
查看controller-manager信息
[root@master-1-230 7.2]# kubectl describe pod -n kube-system kube-controller-manager-master-1-230
Name: kube-controller-manager-master-1-230
Namespace: kube-system
Priority: 2000001000
Priority Class Name: system-node-critical
Node: master-1-230/192.168.1.230
Start Time: Sat, 16 Dec 2023 07:43:31 +0800
Labels: component=kube-controller-manager
tier=control-plane
Annotations: kubernetes.io/config.hash: 4d3871ae35ea8b984896a345e1d6c048
kubernetes.io/config.mirror: 4d3871ae35ea8b984896a345e1d6c048
kubernetes.io/config.seen: 2023-11-11T00:27:09.604675091+08:00
kubernetes.io/config.source: file
Status: Running
SeccompProfile: RuntimeDefault
IP: 192.168.1.230
IPs:
IP: 192.168.1.230
Controlled By: Node/master-1-230
Containers:
kube-controller-manager:
Container ID: containerd://5351b33b7274398c0aef10a2b68b5394e4e2a1eadbc920fe18008056ef7c5f33
Image: registry.aliyuncs.com/google_containers/kube-controller-manager:v1.27.6
Image ID: registry.aliyuncs.com/google_containers/kube-controller-manager@sha256:01c7d6d2711510ccaaaaff4a4d9887d7cdc06ea6765e2410098ec14012277ae8
Port: <none>
Host Port: <none>
Command:
kube-controller-manager
--allocate-node-cidrs=true
--authentication-kubeconfig=/etc/kubernetes/controller-manager.conf
--authorization-kubeconfig=/etc/kubernetes/controller-manager.conf
--bind-address=127.0.0.1
--client-ca-file=/etc/kubernetes/pki/ca.crt
--cluster-cidr=10.224.0.0/16
--cluster-name=kubernetes
--cluster-signing-cert-file=/etc/kubernetes/pki/ca.crt
--cluster-signing-key-file=/etc/kubernetes/pki/ca.key
--controllers=*,bootstrapsigner,tokencleaner
--kubeconfig=/etc/kubernetes/controller-manager.conf
--leader-elect=true
--requestheader-client-ca-file=/etc/kubernetes/pki/front-proxy-ca.crt
--root-ca-file=/etc/kubernetes/pki/ca.crt
--service-account-private-key-file=/etc/kubernetes/pki/sa.key
--service-cluster-ip-range=10.96.0.0/12
--use-service-account-credentials=true
State: Running
Started: Sat, 16 Dec 2023 07:55:21 +0800
Last State: Terminated
Reason: StartError
Message: failed to start containerd task "5b99a3f7349b712245e8147961cfa5191802d9107b9138767c0ed896d88266d9": context canceled: unknown
Exit Code: 128
Started: Thu, 01 Jan 1970 08:00:00 +0800
Finished: Sat, 16 Dec 2023 07:55:27 +0800
Ready: True
Restart Count: 92
Requests:
cpu: 200m
Liveness: http-get https://127.0.0.1:10257/healthz delay=10s timeout=15s period=10s #success=1 #failure=8
Startup: http-get https://127.0.0.1:10257/healthz delay=10s timeout=15s period=10s #success=1 #failure=24
Environment: <none>
Mounts:
/etc/kubernetes/controller-manager.conf from kubeconfig (ro)
/etc/kubernetes/pki from k8s-certs (ro)
/etc/pki from etc-pki (ro)
/etc/ssl/certs from ca-certs (ro)
/usr/libexec/kubernetes/kubelet-plugins/volume/exec from flexvolume-dir (rw)
Conditions:
Type Status
Initialized True
Ready True
ContainersReady True
PodScheduled True
Volumes:
ca-certs:
Type: HostPath (bare host directory volume)
Path: /etc/ssl/certs
HostPathType: DirectoryOrCreate
etc-pki:
Type: HostPath (bare host directory volume)
Path: /etc/pki
HostPathType: DirectoryOrCreate
flexvolume-dir:
Type: HostPath (bare host directory volume)
Path: /usr/libexec/kubernetes/kubelet-plugins/volume/exec
HostPathType: DirectoryOrCreate
k8s-certs:
Type: HostPath (bare host directory volume)
Path: /etc/kubernetes/pki
HostPathType: DirectoryOrCreate
kubeconfig:
Type: HostPath (bare host directory volume)
Path: /etc/kubernetes/controller-manager.conf
HostPathType: FileOrCreate
QoS Class: Burstable
Node-Selectors: <none>
Tolerations: :NoExecute op=Exists
Events: <none>由上可知,匹配pod对象,lable标签为componnet=kube-controller-manager 即可,需要注意的是controller-manager默认只运行127.0.0.1 访问,需要修改controller-manager配置
- 修改 /etc/kubernetes/manifests/kube-controller-manager.yaml
[root@master-1-230 7.2]# cat /etc/kubernetes/manifests/kube-controller-manager.yaml
apiVersion: v1
kind: Pod
metadata:
creationTimestamp: null
labels:
component: kube-controller-manager
tier: control-plane
name: kube-controller-manager
namespace: kube-system
spec:
containers:
- command:
- kube-controller-manager
- --allocate-node-cidrs=true
- --authentication-kubeconfig=/etc/kubernetes/controller-manager.conf
- --authorization-kubeconfig=/etc/kubernetes/controller-manager.conf
- --bind-address=0.0.0.0
- --client-ca-file=/etc/kubernetes/pki/ca.crt
- --cluster-cidr=10.224.0.0/16
- --cluster-name=kubernetes
- --cluster-signing-cert-file=/etc/kubernetes/pki/ca.crt
- --cluster-signing-key-file=/etc/kubernetes/pki/ca.key
- --controllers=*,bootstrapsigner,tokencleaner
- --kubeconfig=/etc/kubernetes/controller-manager.conf
- --leader-elect=true
- --requestheader-client-ca-file=/etc/kubernetes/pki/front-proxy-ca.crt
- --root-ca-file=/etc/kubernetes/pki/ca.crt
- --service-account-private-key-file=/etc/kubernetes/pki/sa.key
- --service-cluster-ip-range=10.96.0.0/12
- --use-service-account-credentials=true
image: registry.aliyuncs.com/google_containers/kube-controller-manager:v1.27.6- 编写prometheus配置文件,需要注意,默认匹配是80端口需要手动改为10252端口
- job_name: kube-controller-manager
kubernetes_sd_configs:
- role: pod
relabel_configs:
- source_labels: [__meta_kubernetes_pod_label_component]
regex: kube-controller-manager
action: keep
- source_labels: [__meta_kubernetes_pod_ip]
regex: (.+)
target_label: __address__
replacement: ${1}:10252
- source_labels: [__meta_kubernetes_endpoints_name]
action: replace
target_label: endpoint
- source_labels: [__meta_kubernetes_pod_name]
action: replace
target_label: pod
- source_labels: [__meta_kubernetes_service_name]
action: replace
target_label: service
- source_labels: [__meta_kubernetes_namespace]
action: replace
target_label: namespace2.1.3 scheduler
[root@master-1-230 7.1]# kubectl get pod -n kube-system
NAME READY STATUS RESTARTS AGE
calico-kube-controllers-6c99c8747f-xlzv2 1/1 Running 38 35d
calico-node-48d9c 1/1 Running 38 35d
calico-node-cllhw 1/1 Running 48 (135m ago) 35d
calico-node-f6jwr 1/1 Running 40 35d
calico-node-vgcr6 1/1 Running 39 (134m ago) 34d
coredns-7bdc4cb885-dmc9h 1/1 Running 37 (136m ago) 35d
coredns-7bdc4cb885-qltr7 1/1 Running 37 35d
etcd-master-1-230 1/1 Running 38 (131m ago) 35d
kube-apiserver-master-1-230 1/1 Running 43 (130m ago) 35d
kube-controller-manager-master-1-230 1/1 Running 0 2m40s
kube-proxy-7wqfk 1/1 Running 37 (136m ago) 35d
kube-proxy-8krnv 1/1 Running 37 (135m ago) 35d
kube-proxy-dtp8f 1/1 Running 36 (135m ago) 35d
kube-proxy-nsvtw 1/1 Running 35 (134m ago) 34d
kube-scheduler-master-1-230 1/1 Running 92 (126m ago) 35d
nfs-client-provisioner-79994856c4-jtvxq 1/1 Running 103 (134m ago) 20d
[root@master-1-230 7.1]#
[root@master-1-230 7.1]#
[root@master-1-230 7.1]# kubectl describe pod kube-scheduler-master-1-230 -n kube-system
Name: kube-scheduler-master-1-230
Namespace: kube-system
Priority: 2000001000
Priority Class Name: system-node-critical
Node: master-1-230/192.168.1.230
Start Time: Sat, 16 Dec 2023 07:43:30 +0800
Labels: component=kube-scheduler
tier=control-plane
Annotations: kubernetes.io/config.hash: c4cf881c382a45ca014a4d689a1a32c7
kubernetes.io/config.mirror: c4cf881c382a45ca014a4d689a1a32c7
kubernetes.io/config.seen: 2023-11-11T00:27:09.604675736+08:00
kubernetes.io/config.source: file
Status: Running
SeccompProfile: RuntimeDefault
IP: 192.168.1.230
IPs:
IP: 192.168.1.230
Controlled By: Node/master-1-230
Containers:
kube-scheduler:
Container ID: containerd://81ee74ee06c4f8301a070f2b7ce9bc167369515a784c25ea7f0d42d544265ce7
Image: registry.aliyuncs.com/google_containers/kube-scheduler:v1.27.6
Image ID: registry.aliyuncs.com/google_containers/kube-scheduler@sha256:65b97e34aaf862a76304ef4e10115c6db0e0c437cd35063ca1feeb4a08f89e54
Port: <none>
Host Port: <none>
Command:
kube-scheduler
--authentication-kubeconfig=/etc/kubernetes/scheduler.conf
--authorization-kubeconfig=/etc/kubernetes/scheduler.conf
--bind-address=127.0.0.1
--kubeconfig=/etc/kubernetes/scheduler.conf
--leader-elect=true
State: Running
Started: Sat, 16 Dec 2023 07:59:10 +0800
Last State: Terminated
Reason: Error
Exit Code: 1
Started: Sat, 16 Dec 2023 07:43:36 +0800
Finished: Sat, 16 Dec 2023 07:52:55 +0800
Ready: True
Restart Count: 92
Requests:
cpu: 100m
Liveness: http-get https://127.0.0.1:10259/healthz delay=10s timeout=15s period=10s #success=1 #failure=8
Startup: http-get https://127.0.0.1:10259/healthz delay=10s timeout=15s period=10s #success=1 #failure=24
Environment: <none>
Mounts:
/etc/kubernetes/scheduler.conf from kubeconfig (ro)
Conditions:
Type Status
Initialized True
Ready True
ContainersReady True
PodScheduled True
Volumes:
kubeconfig:
Type: HostPath (bare host directory volume)
Path: /etc/kubernetes/scheduler.conf
HostPathType: FileOrCreate
QoS Class: Burstable
Node-Selectors: <none>
Tolerations: :NoExecute op=Exists
Events: <none>由上可知,匹配pod对象,label标签为commponent=kube-scheduler即可,scheduler 和controller-manager 一样,默认监听0 端口需要注释
[root@master-1-230 7.1]# kubectl describe pod kube-scheduler-master-1-230 -n kube-system
Name: kube-scheduler-master-1-230
Namespace: kube-system
Priority: 2000001000
Priority Class Name: system-node-critical
Node: master-1-230/192.168.1.230
Start Time: Sat, 16 Dec 2023 07:43:30 +0800
Labels: component=kube-scheduler
tier=control-plane
Annotations: kubernetes.io/config.hash: c4cf881c382a45ca014a4d689a1a32c7
kubernetes.io/config.mirror: c4cf881c382a45ca014a4d689a1a32c7
kubernetes.io/config.seen: 2023-11-11T00:27:09.604675736+08:00
kubernetes.io/config.source: file
Status: Running
SeccompProfile: RuntimeDefault
IP: 192.168.1.230
IPs:
IP: 192.168.1.230
Controlled By: Node/master-1-230
Containers:
kube-scheduler:
Container ID: containerd://81ee74ee06c4f8301a070f2b7ce9bc167369515a784c25ea7f0d42d544265ce7
Image: registry.aliyuncs.com/google_containers/kube-scheduler:v1.27.6
Image ID: registry.aliyuncs.com/google_containers/kube-scheduler@sha256:65b97e34aaf862a76304ef4e10115c6db0e0c437cd35063ca1feeb4a08f89e54
Port: <none>
Host Port: <none>
Command:
kube-scheduler
--authentication-kubeconfig=/etc/kubernetes/scheduler.conf
--authorization-kubeconfig=/etc/kubernetes/scheduler.conf
--bind-address=127.0.0.1
--kubeconfig=/etc/kubernetes/scheduler.conf
--leader-elect=true
State: Running
Started: Sat, 16 Dec 2023 07:59:10 +0800
Last State: Terminated
Reason: Error
Exit Code: 1
Started: Sat, 16 Dec 2023 07:43:36 +0800
Finished: Sat, 16 Dec 2023 07:52:55 +0800
Ready: True
Restart Count: 92
Requests:
cpu: 100m
Liveness: http-get https://127.0.0.1:10259/healthz delay=10s timeout=15s period=10s #success=1 #failure=8
Startup: http-get https://127.0.0.1:10259/healthz delay=10s timeout=15s period=10s #success=1 #failure=24
Environment: <none>
Mounts:
/etc/kubernetes/scheduler.conf from kubeconfig (ro)
Conditions:
Type Status
Initialized True
Ready True
ContainersReady True
PodScheduled True
Volumes:
kubeconfig:
Type: HostPath (bare host directory volume)
Path: /etc/kubernetes/scheduler.conf
HostPathType: FileOrCreate
QoS Class: Burstable
Node-Selectors: <none>
Tolerations: :NoExecute op=Exists
Events: <none>修改/etc/kubernetes/manifests/kube-scheduler.yaml
[root@master-1-230 7.1]# cat /etc/kubernetes/manifests/kube-scheduler.yaml
apiVersion: v1
kind: Pod
metadata:
creationTimestamp: null
labels:
component: kube-scheduler
tier: control-plane
name: kube-scheduler
namespace: kube-system
spec:
containers:
- command:
- kube-scheduler
- --authentication-kubeconfig=/etc/kubernetes/scheduler.conf
- --authorization-kubeconfig=/etc/kubernetes/scheduler.conf
- --bind-address=0.0.0.0
- --kubeconfig=/etc/kubernetes/scheduler.conf
- --leader-elect=true
image: registry.aliyuncs.com/google_containers/kube-scheduler:v1.27.6
imagePullPolicy: IfNotPresent编写prometheus配置文件,需要注意,默认匹配到80 端口,需要手动指定为10251端口,同时指定token,否则会提示 `server returned HTTP status 400 Bad Request`;
- job_name: kube-scheduler
kubernetes_sd_configs:
- role: pod
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
relabel_configs:
- source_labels: [__meta_kubernetes_pod_label_component]
regex: kube-scheduler
action: keep
- source_labels: [__meta_kubernetes_pod_ip]
regex: (.+)
target_label: __address__
replacement: ${1}:10251
- source_labels: [__meta_kubernetes_endpoints_name]
action: replace
target_label: endpoint
- source_labels: [__meta_kubernetes_pod_name]
action: replace
target_label: pod
- source_labels: [__meta_kubernetes_service_name]
action: replace
target_label: service
- source_labels: [__meta_kubernetes_namespace]
action: replace
target_label: namespace2.1.4 kube-state-metrics
编写prometheus配置文件,需要注意,默认匹配8080 和8081端口,需要手动修改为8080端口
- job_name: kube-state-metrics
kubernetes_sd_configs:
- role: endpoints
relabel_configs:
- source_labels: [__meta_kubernetes_service_name]
regex: kube-state-metrics
action: keep
- source_labels: [__meta_kubernetes_pod_ip]
regex: (.+)
target_label: __address__
replacement: ${1}:8080
- source_labels: [__meta_kubernetes_endpoints_name]
action: replace
target_label: endpoint
- source_labels: [__meta_kubernetes_pod_name]
action: replace
target_label: pod
- source_labels: [__meta_kubernetes_service_name]
action: replace
target_label: service
- source_labels: [__meta_kubernetes_namespace]
action: replace
target_label: namespace2.1.5 coredns
编写prometheus 配置文件,默认匹配是53 端口,需手动指定9153端口
- job_name: coredns
kubernetes_sd_configs:
- role: endpoints
relabel_configs:
- source_labels:
- __meta_kubernetes_service_label_k8s_app
regex: kube-dns
action: keep
- source_labels: [__meta_kubernetes_pod_ip]
regex: (.+)
target_label: __address__
replacement: ${1}:9153
- source_labels: [__meta_kubernetes_endpoints_name]
action: replace
target_label: endpoint
- source_labels: [__meta_kubernetes_pod_name]
action: replace
target_label: pod
- source_labels: [__meta_kubernetes_service_name]
action: replace
target_label: service
- source_labels: [__meta_kubernetes_namespace]
action: replace
target_label: namespace2.1.6 etcd
[root@master-1-230 7.1]# kubectl describe pod etcd-master-1-230 -n kube-system
Name: etcd-master-1-230
Namespace: kube-system
Priority: 2000001000
Priority Class Name: system-node-critical
Node: master-1-230/192.168.1.230
Start Time: Sat, 16 Dec 2023 07:43:31 +0800
Labels: component=etcd
tier=control-plane
Annotations: kubeadm.kubernetes.io/etcd.advertise-client-urls: https://192.168.1.230:2379
kubernetes.io/config.hash: 6de1ba327232702baa2108cf53f3d599
kubernetes.io/config.mirror: 6de1ba327232702baa2108cf53f3d599
kubernetes.io/config.seen: 2023-11-11T00:27:09.604668219+08:00
kubernetes.io/config.source: file
Status: Running
SeccompProfile: RuntimeDefault
IP: 192.168.1.230
IPs:
IP: 192.168.1.230
Controlled By: Node/master-1-230
Containers:
etcd:
Container ID: containerd://0a1e50bc42df80496b9b5d87311e3769635783355aa9b06495a6ea9cb41400ab
Image: registry.aliyuncs.com/google_containers/etcd:3.5.7-0
Image ID: registry.aliyuncs.com/google_containers/etcd@sha256:e85dab14e03d2468bedd3f908898982ed0ef2622d3764cc7746eb51555fae06e
Port: <none>
Host Port: <none>
Command:
etcd
--advertise-client-urls=https://192.168.1.230:2379
--cert-file=/etc/kubernetes/pki/etcd/server.crt
--client-cert-auth=true
--data-dir=/var/lib/etcd
--experimental-initial-corrupt-check=true
--experimental-watch-progress-notify-interval=5s
--initial-advertise-peer-urls=https://192.168.1.230:2380
--initial-cluster=master-1-230=https://192.168.1.230:2380
--key-file=/etc/kubernetes/pki/etcd/server.key
--listen-client-urls=https://127.0.0.1:2379,https://192.168.1.230:2379
--listen-metrics-urls=http://127.0.0.1:2381
--listen-peer-urls=https://192.168.1.230:2380
--name=master-1-230
--peer-cert-file=/etc/kubernetes/pki/etcd/peer.crt
--peer-client-cert-auth=true
--peer-key-file=/etc/kubernetes/pki/etcd/peer.key
--peer-trusted-ca-file=/etc/kubernetes/pki/etcd/ca.crt
--snapshot-count=10000
--trusted-ca-file=/etc/kubernetes/pki/etcd/ca.crt
State: Running
Started: Sat, 16 Dec 2023 07:48:18 +0800
Last State: Terminated
Reason: Error
Exit Code: 2
Started: Sat, 16 Dec 2023 07:43:37 +0800
Finished: Sat, 16 Dec 2023 07:48:06 +0800
Ready: True
Restart Count: 38
Requests:
cpu: 100m
memory: 100Mi
Liveness: http-get http://127.0.0.1:2381/health%3Fexclude=NOSPACE&serializable=true delay=10s timeout=15s period=10s #success=1 #failure=8
Startup: http-get http://127.0.0.1:2381/health%3Fserializable=false delay=10s timeout=15s period=10s #success=1 #failure=24
Environment: <none>
Mounts:
/etc/kubernetes/pki/etcd from etcd-certs (rw)
/var/lib/etcd from etcd-data (rw)
Conditions:
Type Status
Initialized True
Ready True
ContainersReady True
PodScheduled True
Volumes:
etcd-certs:
Type: HostPath (bare host directory volume)
Path: /etc/kubernetes/pki/etcd
HostPathType: DirectoryOrCreate
etcd-data:
Type: HostPath (bare host directory volume)
Path: /var/lib/etcd
HostPathType: DirectoryOrCreate
QoS Class: Burstable
Node-Selectors: <none>
Tolerations: :NoExecute op=Exists
Events: <none>由上可知,启动参数有--listen-metrics-urls=http://127.0.0.1:2381的配置项,该参数用来指定Metrics接口运行在2381 端口下,而且是http的协议,所有不用配置证书。但是需要修改配置文件,地址修改为0.0.0.0
[root@master-1-230 7.1]# cat /etc/kubernetes/manifests/etcd.yaml
apiVersion: v1
kind: Pod
metadata:
annotations:
kubeadm.kubernetes.io/etcd.advertise-client-urls: https://192.168.1.230:2379
creationTimestamp: null
labels:
component: etcd
tier: control-plane
name: etcd
namespace: kube-system
spec:
containers:
- command:
- etcd
- --advertise-client-urls=https://192.168.1.230:2379
- --cert-file=/etc/kubernetes/pki/etcd/server.crt
- --client-cert-auth=true
- --data-dir=/var/lib/etcd
- --experimental-initial-corrupt-check=true
- --experimental-watch-progress-notify-interval=5s
- --initial-advertise-peer-urls=https://192.168.1.230:2380
- --initial-cluster=master-1-230=https://192.168.1.230:2380
- --key-file=/etc/kubernetes/pki/etcd/server.key
- --listen-client-urls=https://127.0.0.1:2379,https://192.168.1.230:2379
- --listen-metrics-urls=http://0.0.0.0:2381
- --listen-peer-urls=https://192.168.1.230:2380
- --name=master-1-230
- --peer-cert-file=/etc/kubernetes/pki/etcd/peer.crt
- --peer-client-cert-auth=true
- --peer-key-file=/etc/kubernetes/pki/etcd/peer.key
- --peer-trusted-ca-file=/etc/kubernetes/pki/etcd/ca.crt
- --snapshot-count=10000
- --trusted-ca-file=/etc/kubernetes/pki/etcd/ca.crt
image: registry.aliyuncs.com/google_containers/etcd:3.5.7-0编写prometheus配置文件,默认匹配2379 端口,需要手动指定为2381 端口
- job_name: etcd
kubernetes_sd_configs:
- role: pod
relabel_configs:
- source_labels:
- __meta_kubernetes_pod_label_component
regex: etcd
action: keep
- source_labels: [__meta_kubernetes_pod_ip]
regex: (.+)
target_label: __address__
replacement: ${1}:2381
- source_labels: [__meta_kubernetes_endpoints_name]
action: replace
target_label: endpoint
- source_labels: [__meta_kubernetes_pod_name]
action: replace
target_label: pod
- source_labels: [__meta_kubernetes_namespace]
action: replace
target_label: namespace上面部分参数简介如下:
- kubernetes_sd_configs: 设置发现模式为 Kubernetes 动态服务发现
- kubernetes_sd_configs.role: 指定 Kubernetes 的服务发现模式,这里设置为endpoints 的服务发现模式,该模式下会调用 kube-apiserver 中的接口获取指标数据。并且还限定只获取 kube-state-metrics 所在 - Namespace 的空间 kubesystem中的 Endpoints 信息
- kubernetes_sd_configs.namespace: 指定只在配置的 Namespace 中进行endpoints 服务发现
- relabel_configs: 用于对采集的标签进行重新标记
热加载prometheus,使configmap配置文件生效(也可以等待prometheus的自动热加载):
curl -XPOST http://prometheus.ikubernetes.cloud/-/reload三、K8S集群层面监控(下)
3、cAdvisor
cAdvisor主要功能
- 对容器资源的使用情况和性能进行监控。它以守护进程方式运行,用于收集、聚合、处理和导出正在运行容器的有关信息。
- cAdvisor 本身就对 Docker 容器支持,并且还对其它类型的容器尽可能的提供支持,力求兼容与适配所有类型的容器。
- Kubernetes 已经默认将其与 Kubelet 融合,所以我们无需再单独部署 cAdvisor 组件来暴露节点中容器运行的信息。
3.1 Prometheus 添加cAdvisor配置
由于 Kubelet 中已经默认集成 cAdvisor 组件,所以无需部署该组件。需要注意的是,他的指标采集地址为 /metrics/cadvisor ,需要配置https访问,可以设置insecure_skip_verify: true 跳过证书验证;
- job_name: kubelet
metrics_path: /metrics/cadvisor
scheme: https
tls_config:
insecure_skip_verify: true
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
kubernetes_sd_configs:
- role: node
relabel_configs:
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
- source_labels: [__meta_kubernetes_endpoints_name]
action: replace
target_label: endpoint
- source_labels: [__meta_kubernetes_pod_name]
action: replace
target_label: pod
- source_labels: [__meta_kubernetes_namespace]
action: replace
target_label: namespace热加载prometheus,使configmap配置生效
curl -XPOST http://prometheus.ikubernetes.cloud/-/reload4、 node-exporter
Node Exporter 是 Prometheus 官方提供的一个节点资源采集组件,可以用于收集服务器节点的数据,如 CPU频率信息、磁盘IO统计、剩余可用内存等等。
部署创建:
由于是针对K8S-node节点,so 使用DaemonSet方式部署
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: node-exporter
namespace: monitor
labels:
name: node-exporter
spec:
selector:
matchLabels:
name: node-exporter
template:
metadata:
labels:
name: node-exporter
spec:
hostPID: true
hostIPC: true
hostNetwork: true
containers:
- name: node-exporter
image: prom/node-exporter:latest
ports:
- containerPort: 9100
resources:
requests:
cpu: 0.15
securityContext:
privileged: true
args:
- --path.procfs
- /host/proc
- --path.sysfs
- /host/sys
- --collector.filesystem.ignored-mount-points
- '"^/(sys|proc|dev|host|etc)($|/)"'
volumeMounts:
- name: dev
mountPath: /host/dev
- name: proc
mountPath: /host/proc
- name: sys
mountPath: /host/sys
- name: rootfs
mountPath: /rootfs
tolerations:
- key: "node-role.kubernetes.io/master"
operator: "Exists"
effect: "NoSchedule"
volumes:
- name: proc
hostPath:
path: /proc
- name: dev
hostPath:
path: /dev
- name: sys
hostPath:
path: /sys
- name: rootfs
hostPath:
path: /node-exporter.yaml 文件说明:
- hostPID:指定是否允许Node Exporter进程绑定到主机的PID命名空间。若值为true,则可以访问宿主机中的PID信息。
- hostIPC:指定是否允许Node Exporter进程绑定到主机的IPC命名空间。若值为true,则可以访问宿主机中的IPC信息。
- hostNetwork:指定是否允许Node Exporter进程绑定到主机的网络命名空间。若值为true,则可以访问宿主机中的网络信息。
验证:
[root@master-1-230 7.2]# kubectl apply -f node-exporter.yaml
daemonset.apps/node-exporter created
[root@master-1-230 7.2]# kubectl get pod -n monitor -o wide |grep node-exporter
node-exporter-2mtrj 1/1 Running 0 3m42s 192.168.1.233 node-1-233 <none> <none>
node-exporter-r64mt 1/1 Running 0 3m42s 192.168.1.231 node-1-231 <none> <none>
node-exporter-rbzzq 1/1 Running 0 3m42s 192.168.1.232 node-1-232 <none> <none>
[root@node-1-231 ~]# curl localhost:9100/metrics |grep cpu
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
0 0 0 0 0 0 0 0 --:--:-- --:--:-- --:--:-- 0# HELP node_cpu_guest_seconds_total Seconds the CPUs spent in guests (VMs) for each mode.
# TYPE node_cpu_guest_seconds_total counter
node_cpu_guest_seconds_total{cpu="0",mode="nice"} 0
node_cpu_guest_seconds_total{cpu="0",mode="user"} 0
node_cpu_guest_seconds_total{cpu="1",mode="nice"} 0
node_cpu_guest_seconds_total{cpu="1",mode="user"} 0
node_cpu_guest_seconds_total{cpu="2",mode="nice"} 0
node_cpu_guest_seconds_total{cpu="2",mode="user"} 04.1 新增k8s-node监控
在prometheus-config.yaml 中新增job:k8s-nodes
node_exporter是每个node节点都在运行,因此role使用node即可,默认address端口为10250,替换为9100即可
- job_name: k8s-nodes
kubernetes_sd_configs:
- role: node
relabel_configs:
- source_labels: [__address__]
regex: '(.*):10250'
replacement: '${1}:9100'
target_label: __address__
action: replace
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
- source_labels: [__meta_kubernetes_endpoints_name]
action: replace
target_label: endpoint
- source_labels: [__meta_kubernetes_pod_name]
action: replace
target_label: pod
- source_labels: [__meta_kubernetes_namespace]
action: replace
target_label: namespace热加载prometheus,使configmap配置文件生效:
curl -XPOST http://prometheus.ikubernetes.cloud/-/reload5、总结:
- kube-state-metrics:将 Kubernetes API 中的各种对象状态信息转化为Prometheus 可以使用的监控指标数据。
- cAdvisor:用于监视容器资源使用和性能的工具,它可以收集 CPU、内存、磁盘、网络和文件系统等方面的指标数据。
- node-exporter:用于监控主机指标数据的收集器,它可以收集 CPU 负载、内存使用情况、磁盘空间、网络流量等各种指标数据。
这三种工具可以协同工作,为用户提供一个全面的 Kubernetes 监控方案,帮助用户更好地了解其 Kubernetes 集群和容器化应用程序的运行情况。